Recognition: unknown
VocalParse: Towards Unified and Scalable Singing Voice Transcription with Large Audio Language Models
Pith reviewed 2026-05-08 16:55 UTC · model grok-4.3
The pith
A large audio language model with interleaved prompting transcribes singing audio into lyrics, melody, and word-note alignments as one structured sequence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VocalParse is a unified singing voice transcription model built on a Large Audio Language Model. Its central contribution is an interleaved prompting formulation that jointly models lyrics, melody, and word-note correspondence, producing a generated sequence that directly maps to a structured musical score. The model further applies a Chain-of-Thought style prompting strategy that decodes lyrics first to serve as a semantic scaffold, which reduces context disruption while retaining the structural benefits of interleaved generation. Experiments show state-of-the-art performance on multiple singing datasets.
What carries the argument
Interleaved prompting formulation in a Large Audio Language Model that produces a single sequence jointly encoding lyrics, melody, and alignments, augmented by Chain-of-Thought lyrics-first decoding to maintain context.
Load-bearing premise
The interleaved prompting formulation and CoT strategy will jointly model lyrics, melody, and word-note correspondence without context disruption on out-of-distribution singing data.
What would settle it
A measurable drop in word-note alignment accuracy below prior multi-stage systems when tested on a held-out dataset containing unusual vocal styles, tempos, or languages would falsify the claim.
Figures






read the original abstract
High-quality singing annotations are fundamental to modern Singing Voice Synthesis (SVS) systems. However, obtaining these annotations at scale through manual labeling is unrealistic due to the substantial labor and musical expertise required, making automatic annotation highly necessary. Despite their utility, current automatic transcription systems face significant challenges: they often rely on complex multi-stage pipelines, struggle to recover text-note alignments, and exhibit poor generalization to out-of-distribution (OOD) singing data. To alleviate these issues, we present VocalParse, a unified singing voice transcription (SVT) model built upon a Large Audio Language Model (LALM). Specifically, our novel contribution is to introduce an interleaved prompting formulation that jointly models lyrics, melody, and word-note correspondence, yielding a generated sequence that directly maps to a structured musical score. Furthermore, we propose a Chain-of-Thought (CoT) style prompting strategy, which decodes lyrics first as a semantic scaffold, significantly mitigating the context disruption problem while preserving the structural benefits of interleaved generation. Experiments demonstrate that VocalParse achieves state-of-the-art SVT performance on multiple singing datasets. The source code and checkpoint are available at https://github.com/pymaster17/VocalParse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VocalParse, a unified singing voice transcription (SVT) model built on a Large Audio Language Model. It proposes an interleaved prompting formulation that jointly models lyrics, melody, and word-note correspondence to produce a structured musical score output, along with a Chain-of-Thought (CoT) prompting strategy that decodes lyrics first as a semantic scaffold to reduce context disruption. The paper claims that experiments demonstrate state-of-the-art SVT performance on multiple singing datasets and releases the source code and checkpoint.
Significance. If the performance claims hold with proper validation, VocalParse could meaningfully advance scalable automatic annotation for singing voice synthesis by replacing multi-stage pipelines with a single unified LALM-based approach, potentially improving generalization to out-of-distribution singing data and reducing reliance on manual labeling.
major comments (1)
- Abstract: the central claim that 'Experiments demonstrate that VocalParse achieves state-of-the-art SVT performance on multiple singing datasets' is unsupported, as the manuscript provides no dataset names or splits, baseline methods, evaluation metrics (e.g., word/note F1, alignment error), quantitative results, error bars, ablation studies on the interleaved prompting or CoT components, or OOD test conditions. This absence is load-bearing for the empirical contribution and leaves the modeling assumptions about context preservation unverified.
minor comments (1)
- Abstract: the term 'context disruption problem' is referenced without a definition or citation to prior work, which may reduce clarity for readers unfamiliar with the specific challenge in interleaved generation.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim that 'Experiments demonstrate that VocalParse achieves state-of-the-art SVT performance on multiple singing datasets' is unsupported, as the manuscript provides no dataset names or splits, baseline methods, evaluation metrics (e.g., word/note F1, alignment error), quantitative results, error bars, ablation studies on the interleaved prompting or CoT components, or OOD test conditions. This absence is load-bearing for the empirical contribution and leaves the modeling assumptions about context preservation unverified.
Authors: We agree that the abstract's claim of state-of-the-art performance must be directly supported by explicit experimental details to substantiate the contribution. The current manuscript version does not provide the requested specifics (dataset names and splits, baseline methods, metrics such as word/note F1 and alignment error, quantitative results with error bars, ablations on interleaved prompting and CoT, or OOD evaluations). In the revised manuscript we will update the abstract to reference these elements and expand the experimental section to report them in full, including cross-references that verify the context-preservation assumptions of the prompting strategies. These changes will make the empirical claims verifiable and address the load-bearing nature of the results. revision: yes
Circularity Check
No circularity: empirical SOTA claim with no derivations or self-referential reductions
full rationale
The paper introduces VocalParse as a LALM-based model using interleaved prompting and CoT for unified SVT. Its central claim rests on experimental demonstration of SOTA performance across datasets, with no equations, parameter fittings, uniqueness theorems, or ansatzes presented. No load-bearing steps reduce by construction to inputs, self-citations, or prior author work. The contribution is self-contained as an empirical modeling proposal without any derivation chain that could exhibit circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large Audio Language Models can be effectively prompted to produce structured interleaved outputs for lyrics, melody and alignments.
Reference graph
Works this paper leans on
-
[1]
Keyu An, Qian Chen, Chong Deng, Zhihao Du, Changfeng Gao, Zhifu Gao, Yue Gu, Ting He, Hangrui Hu, Kai Hu, Shengpeng Ji, Y abin Li, Zerui Li, Heng Lu, Haoneng Luo, Xiang 9 Lv, Bin Ma, Ziyang Ma, Chongjia Ni, Changhe Song, Jiaqi Shi, Xian Shi, Hao Wang, Wen Wang, Yuxuan Wang, Zhangyu Xiao, Zhijie Y an, Y exin Y ang, Bin Zhang, Qinglin Zhang, Shil- iang Zhan...
-
[2]
Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition
Y e Bai, Jingping Chen, Jitong Chen, Wei Chen, Zhuo Chen, Chuang Ding, Linhao Dong, Qian- qian Dong, Yujiao Du, Kepan Gao, et al. Seed-asr: Understanding diverse speech and contexts with llm-based speech recognition. arXiv preprint arXiv:2407.04675, 2024
-
[3]
Yunfei Chu, Jin Xu, Qian Y ang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuan- jun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report. arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue. CoRR, abs/2410.00037, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-audio technical report. arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
Self-transriber: Few-shot lyrics transcription with self-training
Xiaoxue Gao, Xianghu Yue, and Haizhou Li. Self-transriber: Few-shot lyrics transcription with self-training. In ICASSP, pages 1–5. IEEE, 2023
2023
-
[7]
Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition
Zhifu Gao, Shiliang Zhang, Ian McLoughlin, and Zhijie Y an. Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition. In INTERSPEECH, pages 2063–2067. ISCA, 2022
2063
-
[8]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models
Sreyan Ghosh, Arushi Goel, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang gil Lee, Chao- Han Huck Y ang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL h...
2025
-
[9]
Music flamingo: Scaling music understanding in audio language models
Sreyan Ghosh, Arushi Goel, Lasha Koroshinadze, Sang-gil Lee, Zhifeng Kong, Joao Fe- lipe Santos, Ramani Duraiswami, Dinesh Manocha, Wei Ping, Mohammad Shoeybi, et al. Music flamingo: Scaling music understanding in audio language models. arXiv preprint arXiv:2511.10289, 2025
-
[10]
Techsinger: Technique controllable multilingual singing voice synthesis via flow matching
Wenxiang Guo, Yu Zhang, Changhao Pan, Rongjie Huang, Li Tang, Ruiqi Li, Zhiqing Hong, Y ongqi Wang, and Zhou Zhao. Techsinger: Technique controllable multilingual singing voice synthesis via flow matching. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 39, pages 23978–23986, 2025
2025
-
[11]
Stars: A unified framework for singing transcription, alignment, and refined style annotation
Wenxiang Guo, Yu Zhang, Changhao Pan, Zhiyuan Zhu, Ruiqi Li, Zhetao Chen, Wenhao Xu, Fei Wu, and Zhou Zhao. Stars: A unified framework for singing transcription, alignment, and refined style annotation. In Findings of the Association for Computational Linguistics: ACL 2025, pages 15081–15093, 2025
2025
-
[12]
SongFormer: Scaling Music Structure Analysis with Heterogeneous Supervision
Chunbo Hao, Ruibin Yuan, Jixun Y ao, Qixin Deng, Xinyi Bai, Wei Xue, and Lei Xie. Song- former: Scaling music structure analysis with heterogeneous supervision. arXiv preprint arXiv:2510.02797, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Y ang, Jiaqi Li, Peiyang Shi, Yuancheng Wang, Kai Chen, Pengyuan Zhang, and Zhizheng Wu. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation. In Proc. of SLT, 2024
2024
-
[14]
Multi-singer: Fast multi-singer singing voice vocoder with a large-scale corpus
Rongjie Huang, Feiyang Chen, Yi Ren, Jinglin Liu, Chenye Cui, and Zhou Zhao. Multi-singer: Fast multi-singer singing voice vocoder with a large-scale corpus. In Proceedings of the 29th ACM International Conference on Multimedia, pages 3945–3954, 2021. 10
2021
-
[15]
Wavchat: A survey of spoken dialogue models
Shengpeng Ji, Yifu Chen, Minghui Fang, Jialong Zuo, Jingyu Lu, Hanting Wang, Ziyue Jiang, Long Zhou, Shujie Liu, Xize Cheng, Xiaoda Y ang, Zehan Wang, Qian Y ang, Jian Li, Yidi Jiang, Jingzhen He, Yunfei Chu, Jin Xu, and Zhou Zhao. Wavchat: A survey of spoken dialogue models. CoRR, abs/2411.13577, 2024
-
[16]
Note-level singing melody transcription for time-aligned musical score generation
Leekyung Kim, Sungwook Jeon, Wan Heo, and Jonghun Park. Note-level singing melody transcription for time-aligned musical score generation. IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[17]
Robust singing voice transcription serves synthesis
Ruiqi Li, Yu Zhang, Y ongqi Wang, Zhiqing Hong, Rongjie Huang, and Zhou Zhao. Robust singing voice transcription serves synthesis. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 9751–9766, 2024
2024
-
[18]
Diffsinger: Singing voice synthesis via shallow diffusion mechanism
Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, and Zhou Zhao. Diffsinger: Singing voice synthesis via shallow diffusion mechanism. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pages 11020–11028, 2022
2022
-
[19]
Foun- dation models for music: A survey
Yinghao Ma, Anders Øland, Anton Ragni, Bleiz MacSen Del Sette, Charalampos Saitis, Chris Donahue, Chenghua Lin, Christos Plachouras, Emmanouil Benetos, Elona Shatri, et al. Foun- dation models for music: A survey. arXiv preprint arXiv:2408.14340, 2024
-
[20]
Audio-cot: Exploring chain-of-thought reasoning in large audio language model,
Ziyang Ma, Zhuo Chen, Yuping Wang, Eng Siong Chng, and Xie Chen. Audio-cot: Exploring chain-of-thought reasoning in large audio language model. arXiv preprint arXiv:2501.07246 , 2025
-
[21]
Montreal forced aligner: Trainable text-speech alignment using kaldi
Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sondereg- ger. Montreal forced aligner: Trainable text-speech alignment using kaldi. In Interspeech, volume 2017, pages 498–502, 2017
2017
-
[22]
Transfer learning of wav2vec 2.0 for automatic lyric transcription
Longshen Ou, Xiangming Gu, and Y e Wang. Transfer learning of wav2vec 2.0 for automatic lyric transcription. In ISMIR, pages 891–899, 2022
2022
-
[23]
Synthetic singers: A review of deep-learning-based singing voice synthesis approaches
Changhao Pan, Dongyu Y ao, Yu Zhang, Wenxiang Guo, Jingyu Lu, Zhiyuan Zhu, and Zhou Zhao. Synthetic singers: A review of deep-learning-based singing voice synthesis approaches. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Lin...
2025
-
[24]
Soulx- singer: Towards high-quality zero-shot singing voice synthesis,
Jiale Qian, Hao Meng, Tian Zheng, Pengcheng Zhu, Haopeng Lin, Yuhang Dai, Hanke Xie, Wenxiao Cao, Ruixuan Shang, Jun Wu, et al. Soulx-singer: Towards high-quality zero-shot singing voice synthesis. arXiv preprint arXiv:2602.07803, 2026
-
[25]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International con- ference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[26]
Singing voice data scaling-up: An introduction to ace-opencpop and ace-kising
Jiatong Shi, Yueqian Lin, Xinyi Bai, Keyi Zhang, Yuning Wu, Yuxun Tang, Yifeng Yu, Qin Jin, and Shinji Watanabe. Singing voice data scaling-up: An introduction to ace-opencpop and ace-kising. arXiv preprint arXiv:2401.17619, 2024
-
[27]
Xian Shi, Xiong Wang, Zhifang Guo, Y ongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Y ang, et al. Qwen3-asr technical report. arXiv preprint arXiv:2601.21337, 2026
work page internal anchor Pith review arXiv 2026
-
[28]
Wei Tan, Shun Lei, Huaicheng Zhang, Guangzheng Li, Yixuan Zhang, Hangting Chen, Jianwei Yu, Rongzhi Gu, and Dong Yu. Songprep: A preprocessing framework and end-to-end model for full-song structure parsing and lyrics transcription. arXiv preprint arXiv:2509.17404, 2025
-
[29]
Singmos-pro: An comprehensive benchmark for singing quality assessment
Yuxun Tang, Lan Liu, Wenhao Feng, Yiwen Zhao, Jionghao Han, Yifeng Yu, Jiatong Shi, and Qin Jin. Singmos-pro: An comprehensive benchmark for singing quality assessment. arXiv preprint arXiv:2510.01812, 2025
-
[30]
Moss-music technical report
OpenMOSS Team. Moss-music technical report. https://github.com/OpenMOSS/ MOSS-Music, 2026. GitHub repository. 11
2026
-
[31]
Step-audio-r1 technical report, 2025
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Y ayue Deng, Donghang Wu, Jun Chen, Liang Zhao, et al. Step-audio-r1 technical report. arXiv preprint arXiv:2511.15848, 2025
-
[32]
Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound,
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, et al. Meta audiobox aesthetics: Unified automatic quality assessment for speech, music, and sound. arXiv preprint arXiv:2502.05139, 2025
-
[33]
Adapting pre- trained speech model for mandarin lyrics transcription and alignment
Jun- Y ou Wang, Chon-In Leong, Yu-Chen Lin, Li Su, and Jyh-Shing Roger Jang. Adapting pre- trained speech model for mandarin lyrics transcription and alignment. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–8. IEEE, 2023
2023
-
[34]
Musicyolo: A vision-based framework for automatic singing transcription
Xianke Wang, Bowen Tian, Weiming Y ang, Wei Xu, and Wenqing Cheng. Musicyolo: A vision-based framework for automatic singing transcription. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:229–241, 2022
2022
-
[35]
Opencpop: A high-quality open source chinese popular song corpus for singing voice synthesis
Yu Wang, Xinsheng Wang, Pengcheng Zhu, Jie Wu, Hanzhao Li, Heyang Xue, Y ongmao Zhang, Lei Xie, and Mengxiao Bi. Opencpop: A high-quality open source chinese popular song corpus for singing voice synthesis. In Proc. Interspeech 2022, pages 4242–4246, 2022
2022
-
[36]
Muchin: A chinese colloquial description benchmark for evaluating language models in the field of music
Zihao Wang, Shuyu Li, Tao Zhang, Qi Wang, Pengfei Yu, Jinyang Luo, Y an Liu, Ming Xi, and Kejun Zhang. Muchin: A chinese colloquial description benchmark for evaluating language models in the field of music. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, pages 7771–7779, 8 2024
2024
-
[37]
Step-audio 2 technical report, 2025
Boyong Wu, Chao Y an, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, et al. Step-audio 2 technical report. arXiv preprint arXiv:2507.16632, 2025
-
[38]
Songtrans: An unified song transcription and alignment method for lyrics and notes
Siwei Wu, Jinzheng He, Ruibin Yuan, Haojie Wei, Xipin Wei, Chenghua Lin, Jin Xu, and Junyang Lin. Songtrans: An unified song transcription and alignment method for lyrics and notes. arXiv preprint arXiv:2409.14619, 2024
-
[39]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report. arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Kai-T uo Xu, Feng-Long Xie, Xu Tang, and Y ao Hu. Fireredasr: Open-source industrial-grade mandarin speech recognition models from encoder-decoder to llm integration. arXiv preprint arXiv:2501.14350, 2025
-
[41]
Canxiang Y an, Chunxiang Jin, Dawei Huang, Haibing Yu, Han Peng, Hui Zhan, Jie Gao, Jing Peng, Jingdong Chen, Jun Zhou, et al. Ming-uniaudio: Speech llm for joint understanding, generation and editing with unified representation. arXiv preprint arXiv:2511.05516, 2025
-
[42]
Yue: Scaling open foundation models for long- form music generation
Ruibin Yuan, Hanfeng Lin, Shuyue Guo, Ge Zhang, Jiahao Pan, Y ongyi Zang, Haohe Liu, Yiming Liang, Wenye Ma, Xingjian Du, et al. Yue: Scaling open foundation models for long- form music generation. arXiv preprint arXiv:2503.08638, 2025
-
[43]
M4singer: A multi-style, multi-singer and musical score provided mandarin singing corpus
Lichao Zhang, Ruiqi Li, Shoutong Wang, Liqun Deng, Jinglin Liu, Yi Ren, Jinzheng He, Rongjie Huang, Jieming Zhu, Xiao Chen, et al. M4singer: A multi-style, multi-singer and musical score provided mandarin singing corpus. Advances in Neural Information Processing Systems, 35:6914–6926, 2022
2022
-
[44]
Visinger2: High-fidelity end-to-end singing voice synthesis enhanced by digital signal processing synthesizer
Y ongmao Zhang, Heyang Xue, Hanzhao Li, Lei Xie, Tingwei Guo, Ruixiong Zhang, and Caixia Gong. Visinger2: High-fidelity end-to-end singing voice synthesis enhanced by digital signal processing synthesizer. In INTERSPEECH, pages 4444–4448. ISCA, 2023
2023
-
[45]
Gtsinger: A global multi-technique singing cor- pus with realistic music scores for all singing tasks
Yu Zhang, Changhao Pan, Wenxiang Guo, Ruiqi Li, Zhiyuan Zhu, Jialei Wang, Wenhao Xu, Jingyu Lu, Zhiqing Hong, Chuxin Wang, et al. Gtsinger: A global multi-technique singing cor- pus with realistic music scores for all singing tasks. Advances in Neural Information Processing Systems, 37:1117–1140, 2024. 12
2024
-
[46]
Tcsinger 2: Customizable multilingual zero-shot singing voice synthesis
Yu Zhang, Wenxiang Guo, Changhao Pan, Dongyu Y ao, Zhiyuan Zhu, Ziyue Jiang, Yuhan Wang, Tao Jin, and Zhou Zhao. Tcsinger 2: Customizable multilingual zero-shot singing voice synthesis. In Findings of the Association for Computational Linguistics: ACL 2025 , pages 13280–13294, 2025
2025
-
[47]
Yingmusic-singer: Zero-shot singing voice synthesis and editing with annotation-free melody guidance
Junjie Zheng, Chunbo Hao, Guobin Ma, Xiaoyu Zhang, Gongyu Chen, Chaofan Ding, Zihao Chen, and Lei Xie. Yingmusic-singer: Zero-shot singing voice synthesis and editing with annotation-free melody guidance. arXiv preprint arXiv:2512.04779, 2025
-
[48]
Note Value
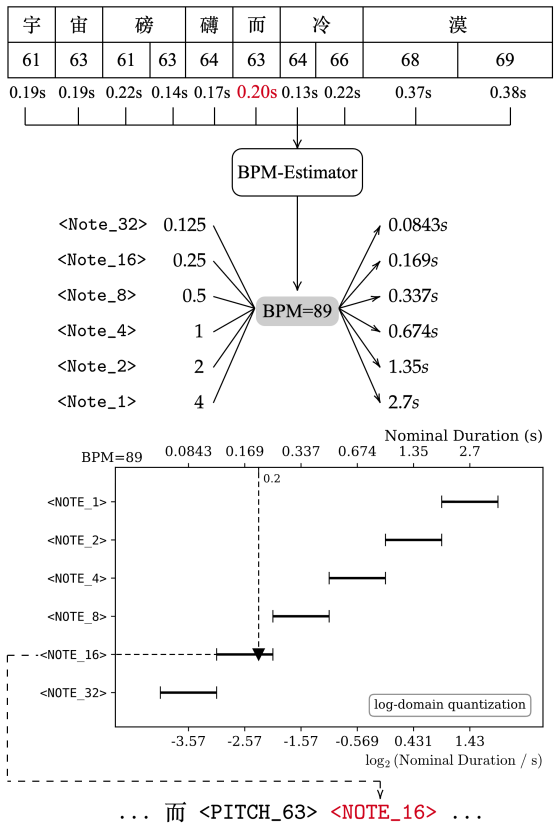
Le Zhuo, Ruibin Yuan, Jiahao Pan, Yinghao Ma, Yizhi Li, Ge Zhang, Si Liu, Roger B. Dan- nenberg, Jie Fu, Chenghua Lin, Emmanouil Benetos, Wenhu Chen, Wei Xue, and Yike Guo. Lyricwhiz: Robust multilingual zero-shot lyrics transcription by whispering to chatgpt. In IS- MIR, pages 343–351, 2023. A Implementation Details of SingCrawl Figure 4: End-to-end data...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.