Recognition: unknown
A meta-analysis of the effect of generative AI on productivity and learning in programming
Pith reviewed 2026-05-08 17:17 UTC · model grok-4.3
The pith
Generative AI coding assistants produce moderate productivity gains but no detectable improvement in learning outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
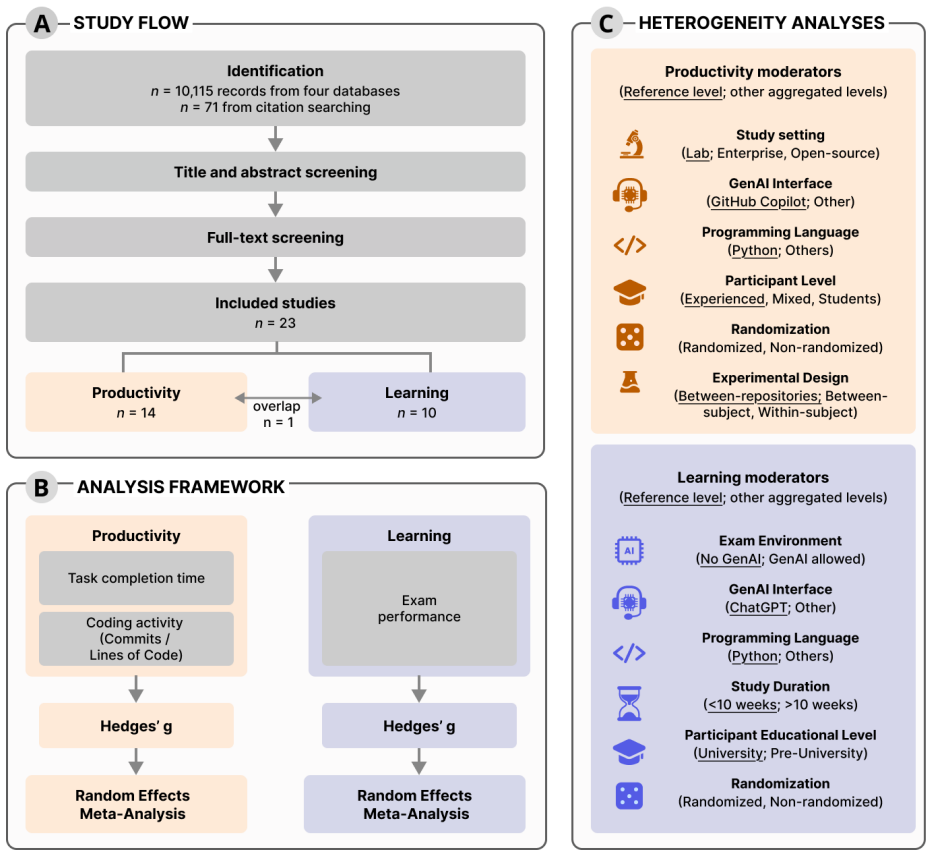
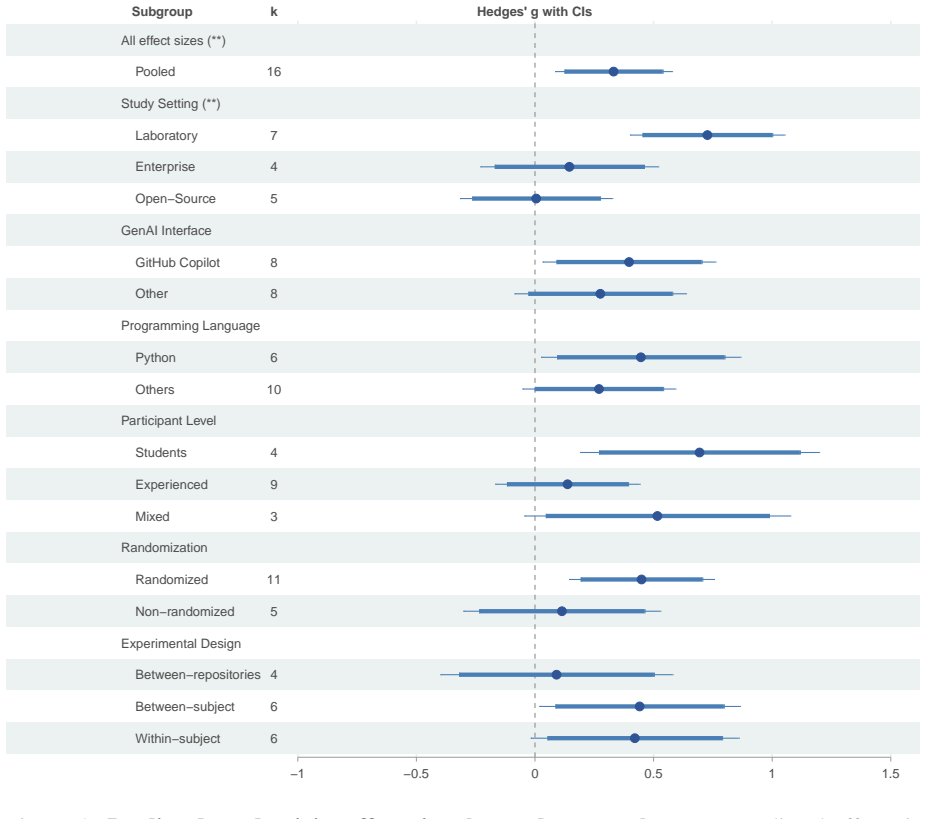
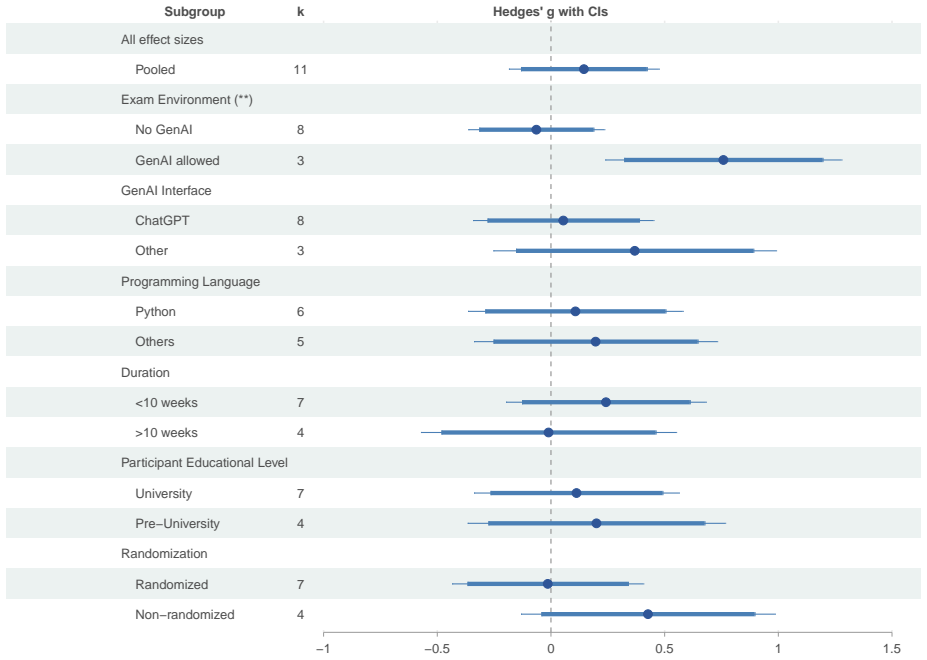
A random-effects meta-analysis of 27 effect sizes drawn from studies published between 2019 and 2025 finds a statistically significant Hedges' g of 0.33 for productivity, indicating moderate gains that are larger in controlled settings than in field settings, while the corresponding pooled effect on learning outcomes is a non-significant Hedges' g of 0.14.
What carries the argument
Pooled Hedges' g standardized effect sizes calculated separately for productivity metrics (task time, commits, lines of code) and learning metrics (exam performance), including subgroup comparisons by study setting.
If this is right
- Productivity gains from GenAI are larger in controlled experimental settings than in open-source or enterprise environments.
- GenAI use in educational contexts does not produce consistent improvements in learning or skill development.
- Context strongly moderates the size of productivity benefits, requiring case-by-case evaluation rather than blanket adoption.
- Careful integration strategies are needed when introducing GenAI into computer science education to avoid missing skill gains.
Where Pith is reading between the lines
- Interfaces that require users to explain or modify generated code could convert the current null learning result into positive skill effects.
- Long-term tracking of the same developers over months could show whether initial productivity gains persist or diminish as habits change.
- The large heterogeneity across studies suggests that programmer experience and task complexity determine when GenAI helps, supporting targeted rather than universal deployment policies.
- Organizations could pair GenAI rollout with mandatory code-review training to capture speed benefits while protecting long-term capability.
Load-bearing premise
The 23 studies are similar enough in how they define GenAI assistance, measure productivity and learning, and select participants that their results can be averaged into a single meaningful number.
What would settle it
A new randomized trial inside a large software company that measures actual task completion time and code volume with and without GenAI over several weeks and finds no productivity difference.
Figures






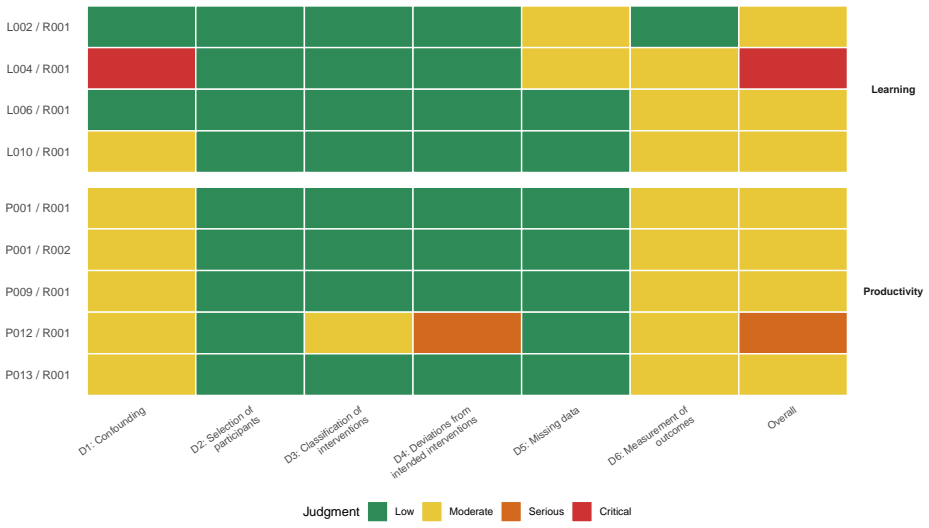
read the original abstract
Generative artificial intelligence (GenAI) is increasingly used for programming, yet it remains unclear when and where GenAI tools lead to productivity gains. Evidence on the effects of GenAI on the long-term development of programming skills is similarly mixed. Here, we present a meta-analysis of $n = 23$ studies reporting $k = 27$ effect sizes to quantify the effect of GenAI-powered coding assistants on productivity and learning. We systematically searched (i) ACM, (ii) arXiv, (iii) Scopus, and (iv) Web of Science for studies published between 2019 and 2025. Studies were required to compare GenAI-assisted with unassisted programming using quantitative measures of (1) productivity (i.e., task completion time, commits, and lines of code) and (2) learning (i.e., exam performance). We assessed the risk of bias using RoB2 and ROBINS-I and compared standardized effect sizes using Hedges' $g$. We find a statistically significant, but moderate positive effect of GenAI assistance on developer productivity ($g = 0.33$, $95\%$ CI: $[0.09, 0.58]$), yet with substantial heterogeneity across settings. Notably, productivity gains tend to be larger in controlled experimental settings, while effects are smaller in open-source and enterprise contexts. In contrast, we find no statistically significant effect of GenAI assistance on learning outcomes ($g = 0.14$, $95\%$ CI: $[-0.18, 0.47]$). Overall, these results highlight that GenAI coding assistants can increase developer productivity, although these gains depend strongly on context. In educational settings, however, the use of GenAI does not consistently translate into improved learning or skill development, which highlights the need for careful integration of GenAI into computer science education.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
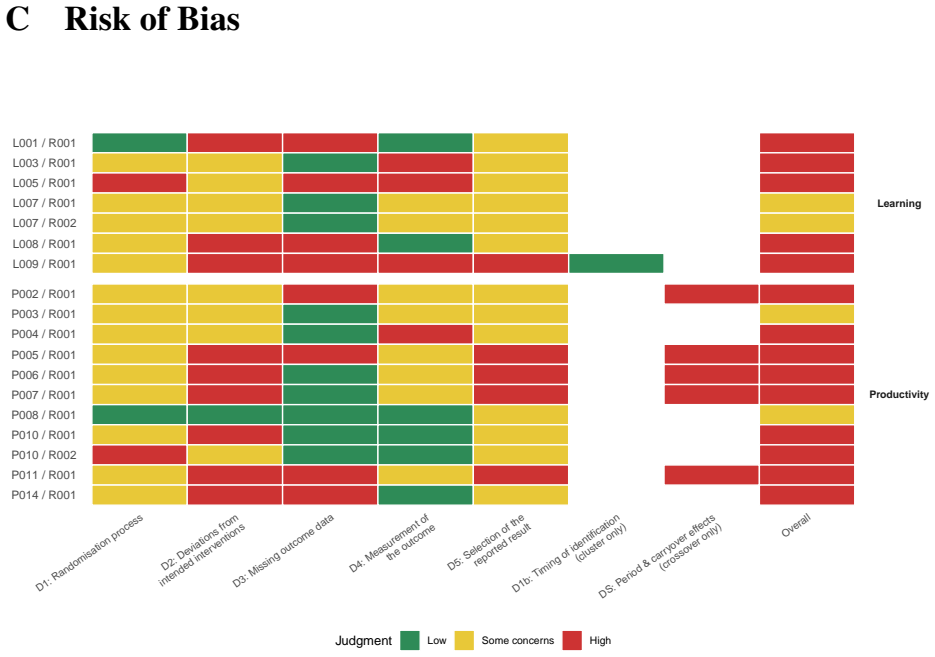
Summary. The manuscript presents a meta-analysis of n=23 studies (k=27 effect sizes) on the impact of generative AI coding assistants on programmer productivity and learning. Using Hedges' g and standard bias tools (RoB2, ROBINS-I), it reports a statistically significant moderate positive effect on productivity (g=0.33, 95% CI [0.09, 0.58]) with substantial heterogeneity (larger in controlled vs. real-world settings) and no significant effect on learning (g=0.14, 95% CI [-0.18, 0.47]).
Significance. If the pooled estimates prove robust, this provides a timely quantitative synthesis of early evidence on GenAI in software engineering, with explicit attention to heterogeneity and context as strengths. The application of standardized meta-analytic procedures (Hedges' g, bias assessment) and reporting of confidence intervals add value for guiding adoption and education policy, though the small study count limits definitiveness.
major comments (3)
- [Abstract / Results] Abstract and Results: The headline productivity claim rests on a single pooled Hedges' g = 0.33 from k=27 effect sizes across n=23 studies that the paper itself describes as having substantial heterogeneity, with systematically larger effects in controlled experiments than in open-source/enterprise settings. Without moderator analyses demonstrating that key variables (setting, task type, GenAI definition) fully explain the variance, this average is at risk of being uninterpretable and not representative of any real population, directly weakening the central conclusion.
- [Methods] Methods: The manuscript does not provide full details on data extraction procedures, effect-size calculation from primary studies, or inter-rater reliability metrics. Given the small n=23 and acknowledged heterogeneity, these omissions hinder assessment of the reliability and reproducibility of the included effect sizes.
- [Results] Results (learning outcomes): The non-significant learning result (g=0.14, CI crossing zero) is particularly sensitive to the same heterogeneity and likely smaller contributing k; the conclusion of 'no effect' requires explicit power discussion and subgroup reporting to be load-bearing.
minor comments (2)
- [Abstract] Abstract: Clarify the exact search cutoff date within 2019-2025 and how preprints were handled, as the inclusion of very recent or unpublished work affects the meta-analysis scope.
- [Abstract] Abstract: Explicitly state how many studies contributed to the productivity versus learning pools, as this is not clear from the reported k=27 total.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful feedback on our meta-analysis of generative AI's impact on programming productivity and learning. We address each of the major comments in detail below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] The headline productivity claim rests on a single pooled Hedges' g = 0.33 from k=27 effect sizes across n=23 studies that the paper itself describes as having substantial heterogeneity, with systematically larger effects in controlled experiments than in open-source/enterprise settings. Without moderator analyses demonstrating that key variables (setting, task type, GenAI definition) fully explain the variance, this average is at risk of being uninterpretable and not representative of any real population, directly weakening the central conclusion.
Authors: We agree that the substantial heterogeneity warrants careful interpretation of the pooled estimate. Our original manuscript already notes larger effects in controlled settings compared to real-world contexts and emphasizes that gains depend strongly on context. To address this, we will perform and report subgroup analyses by study setting (controlled experiments vs. field studies) in the revised version. We will also expand the discussion to explicitly caution that the average effect size should not be generalized without considering contextual factors, and acknowledge that with the current sample size, comprehensive meta-regression may have limited power. This will strengthen the presentation of our central conclusion. revision: partial
-
Referee: [Methods] The manuscript does not provide full details on data extraction procedures, effect-size calculation from primary studies, or inter-rater reliability metrics. Given the small n=23 and acknowledged heterogeneity, these omissions hinder assessment of the reliability and reproducibility of the included effect sizes.
Authors: This is a valid point, and we will revise the Methods section to include comprehensive details. Specifically, we will describe the data extraction process, including how effect sizes were calculated from reported statistics in primary studies (e.g., using means and standard deviations or other available data to compute Hedges' g), and report inter-rater reliability for study selection and data extraction (such as percentage agreement or Cohen's kappa). These additions will enhance the reproducibility and allow better evaluation of the effect sizes' reliability. revision: yes
-
Referee: [Results] The non-significant learning result (g=0.14, CI crossing zero) is particularly sensitive to the same heterogeneity and likely smaller contributing k; the conclusion of 'no effect' requires explicit power discussion and subgroup reporting to be load-bearing.
Authors: We acknowledge the sensitivity of the learning outcomes analysis due to potential smaller number of contributing effect sizes and heterogeneity. In the revision, we will add a discussion of statistical power for the learning meta-analysis, noting the implications for detecting small effects. We will also attempt subgroup analyses where data permit and revise the conclusions to state that the evidence is inconclusive rather than definitively 'no effect,' highlighting the need for more research. This will make the interpretation more nuanced and robust. revision: partial
Circularity Check
Meta-analysis pools independent primary-study effect sizes with no self-referential derivation
full rationale
The paper conducts a standard systematic review and meta-analysis: it searches databases, applies inclusion criteria to select 23 studies, extracts k=27 effect sizes, assesses bias with RoB2/ROBINS-I, and computes pooled Hedges' g values. No equations, fitted parameters, or uniqueness claims are defined in terms of the final pooled results; the central statistics are direct aggregations of externally reported data from independent sources. Self-citations, if present, are not load-bearing for the pooled estimates. The reported heterogeneity is an output of the analysis rather than an input that forces the result by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 23 studies provide unbiased and sufficiently comparable estimates of GenAI effects on productivity and learning.
Reference graph
Works this paper leans on
-
[1]
URL https://github.com/features/copilot
GitHub Copilot - Your AI pair programmer (2025). URL https://github.com/features/copilot
2025
-
[2]
URL https://cursor.com
Cursor: The best way to code with AI (2025). URL https://cursor.com
2025
-
[3]
& Strobel, G
Banh, L., Holldack, F. & Strobel, G. Copiloting the future: How generative AI transforms software engineering.Information and Software Technology183, 107751 (2025)
2025
-
[4]
Russo, D.et al.Generative AI in software engineering must be human-centered: The Copen- hagen manifesto.Journal of Systems and Software216, 112115 (2024)
2024
-
[5]
& Zschech, P
Feuerriegel, S., Hartmann, J., Janiesch, C. & Zschech, P. Generative AI.Business & infor- mation systems engineering66, 111–126 (2024)
2024
-
[6]
& Neffke, F
Daniotti, S., Wachs, J., Feng, X. & Neffke, F. Who is using AI to code? Global diffusion and impact of generative AI.Science391, 831–835 (2026)
2026
-
[7]
Stack Overflow developer survey 2025 (2025)
Stack Overflow. Stack Overflow developer survey 2025 (2025). URL https://survey. stackoverflow.co/2025/
2025
-
[8]
Qiu, K., Puccinelli, N., Ciniselli, M. & Di Grazia, L. From today’s code to tomorrow’s symphony: The AI transformation of developer’s routine by 2030 (2024). URL https://arxiv. org/abs/2405.12731
-
[9]
Ulfsnes, R., Moe, N. B., Stray, V . & Skarpen, M. Transforming software development with generative AI: Empirical insights on collaboration and workflow (2024). URL https://arxiv. org/abs/2405.01543
-
[10]
Otten, D., Stalnaker, T., Wintersgill, N., Chaparro, O. & Poshyvanyk, D. Prompting in practice: Investigating software developers’ use of generative AI tools (2025). URL https://arxiv.org/abs/2510.06000. 36
-
[11]
Jain, N.et al.Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review arXiv 2024
-
[12]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AIet al.DeepSeek-V3.2: pushing the frontier of open large language models (2025). URL http://arxiv.org/abs/2512.02556
work page internal anchor Pith review arXiv 2025
-
[13]
URL https://blog
Gemini 3: Introducing the latest Gemini AI model from Google (2025). URL https://blog. google/products/gemini/gemini-3/#gemini-3
2025
- [14]
-
[15]
Chen, M.et al.Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review arXiv 2021
-
[16]
arXiv preprint arXiv:2510.12399 , year=
Ge, Y .et al.A survey of vibe Coding with large language models (2025). URL https: //arxiv.org/abs/2510.12399
-
[17]
Pimenova, V ., Fakhoury, S., Bird, C., Storey, M.-A. & Endres, M. Good vibrations? A qualitative study of co-creation, communication, flow, and trust in Vibe Coding (2025). URL https://arxiv.org/abs/2509.12491
-
[18]
Vibe coding in practice: Moti- vations, challenges, and a future outlook – a grey literature review,
Fawzy, A., Tahir, A. & Blincoe, K. Vibe Coding in practice: motivations, challenges, and a future outlook - A grey literature review (2025). URL https://arxiv.org/abs/2510.00328
-
[19]
Navigating the complexity of generative AI adoption in software engineering
Russo, D. Navigating the complexity of generative AI adoption in software engineering. ACM Transactions on Software Engineering and Methodology33, 1–50 (2024)
2024
-
[20]
D.et al.Examining the use and impact of an AI code assistant on developer productivity and experience in the enterprise
Weisz, J. D.et al.Examining the use and impact of an AI code assistant on developer productivity and experience in the enterprise. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 1–13 (ACM, Yokohama Japan, 2025). 37
2025
-
[21]
my productivity is boosted, but
Lyu, Y .et al."my productivity is boosted, but ...": Demystifying users’ perception on AI coding assistants (2025). URL https://arxiv.org/abs/2508.12285
-
[22]
T., Barbala, A
Wivestad, V . T., Barbala, A. & Stray, V . Copilot’s island of joy: Balancing individual satisfac- tion with team interaction in agile development. In Marchesi, L.et al.(eds.)Agile Processes in Software Engineering and Extreme Programming – Workshops, 524, 123–129 (Springer Nature Switzerland, Cham, 2025)
2025
-
[23]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
Peng, S., Kalliamvakou, E., Cihon, P. & Demirer, M. The impact of AI on developer produc- tivity: Evidence from GitHub Copilot (2023). URL https://arxiv.org/abs/2302.06590
work page internal anchor Pith review arXiv 2023
-
[24]
InProceedings of the 2024 ACM Conference on International Computing Education Research - Volume 1, 469–486 (ACM, Melbourne VIC Australia, 2024)
Prather, J.et al.The widening gap: The benefits and harms of generative AI for novice programmers. InProceedings of the 2024 ACM Conference on International Computing Education Research - Volume 1, 469–486 (ACM, Melbourne VIC Australia, 2024)
2024
-
[25]
& Myers, B
Nam, D., Macvean, A., Hellendoorn, V ., Vasilescu, B. & Myers, B. Using an LLM to help with code understanding. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering, 1–13 (ACM, Lisbon Portugal, 2024)
2024
-
[26]
Barke, S., James, M. B. & Polikarpova, N. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proceedings of the ACM on Programming Languages7, 85– 111 (2023)
2023
-
[27]
Xu, F., Medappa, P. K., Tunc, M. M., Vroegindeweij, M. & Fransoo, J. C. AI-assisted programming may decrease the productivity of experienced developers by increasing main- tenance burden (2025). URL https://arxiv.org/abs/2510.10165
-
[28]
Becker, J., Rush, N., Barnes, E. & Rein, D. Measuring the impact of early-2025 AI on expe- rienced open-source developer productivity (2025). URL http://arxiv.org/abs/2507.09089v2. 38
-
[29]
T., Yang, C
Liang, J. T., Yang, C. & Myers, B. A. A large-scale survey on the usability of AI programming assistants: Successes and challenges. InProceedings of the IEEE/ACM 46th international conference on software engineering, Icse ’24 (Association for Computing Machinery, Lisbon, Portugal, 2024)
2024
-
[30]
& Boneh, D
Perry, N., Srivastava, M., Kumar, D. & Boneh, D. Do users write more insecure code with ai assistants? InProceedings of the 2023 ACM SIGSAC conference on computer and commu- nications security, 2785–2799 (2023)
2023
-
[31]
& Karri, R
Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B. & Karri, R. Asleep at the keyboard? assessing the security of github copilot’s code contributions.Communications of the ACM 68, 96–105 (2025)
2025
-
[32]
& Tuzun, E
Yetistiren, B., Ozsoy, I. & Tuzun, E. Assessing the quality of GitHub Copilot’s code gener- ation. InProceedings of the 18th International Conference on Predictive Models and Data Analytics in Software Engineering, 62–71 (ACM, Singapore Singapore, 2022)
2022
-
[33]
D., Ku, C
Kirova, V . D., Ku, C. S., Laracy, J. R. & Marlowe, T. J. Software engineering education must adapt and evolve for an LLM environment. InProceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1, 666–672 (ACM, Portland OR USA, 2024)
2024
-
[34]
ban it till we understand it
Lau, S. & Guo, P. From "ban it till we understand it" to "resistance is futile": How uni- versity programming instructors plan to adapt as more students use AI code generation and explanation tools such as ChatGPT and GitHub Copilot. InProceedings of the 2023 ACM Conference on International Computing Education Research V.1, 106–121 (ACM, Chicago IL USA, 2023)
2023
-
[35]
& Shani, Y
Aviv, I., Leiba, M., Rika, H. & Shani, Y . The impact of ChatGPT on students’ learning programming languages. In Zaphiris, P. & Ioannou, A. (eds.)Learning and Collaboration Technologies, 14724, 207–219 (Springer Nature Switzerland, Cham, 2024). 39
2024
-
[36]
InProceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V
Leinonen, J.et al.Comparing code explanations created by students and large language models. InProceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1, 124–130 (ACM, Turku Finland, 2023)
2023
-
[37]
& Björne, J
Laato, S., Morschheuser, B., Hamari, J. & Björne, J. AI-assisted learning with ChatGPT and large language models: Implications for higher education. In2023 IEEE International Conference on Advanced Learning Technologies (ICALT), 226–230 (IEEE, Orem, UT, USA, 2023)
2023
-
[38]
A.et al.Programming is hard - or at least it used to be: Educational opportunities and challenges of AI code generation
Becker, B. A.et al.Programming is hard - or at least it used to be: Educational opportunities and challenges of AI code generation. InProceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1, 500–506 (ACM, Toronto ON Canada, 2023)
2023
-
[39]
Güner, H. & Er, E. AI in the classroom: Exploring students’ interaction with ChatGPT in programming learning.Education and Information Technologies30, 12681–12707 (2025)
2025
-
[40]
H.et al.The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers
Lee, H.-P. H.et al.The impact of generative AI on critical thinking: Self-reported reductions in cognitive effort and confidence effects from a survey of knowledge workers. InProceed- ings of the 2025 CHI Conference on Human Factors in Computing Systems, 1–22 (ACM, Yokohama Japan, 2025)
2025
-
[41]
Coding with ChatGPT: empirical Evidence of cognitive offloading in computer science education.Clareus Scientific Science and Engineering2, 10–19 (2025)
Vivian, R. Coding with ChatGPT: empirical Evidence of cognitive offloading in computer science education.Clareus Scientific Science and Engineering2, 10–19 (2025)
2025
-
[42]
Frontiers in Psychology16, 1550621 (2025)
Jose, B.et al.The cognitive paradox of AI in education: Between enhancement and erosion. Frontiers in Psychology16, 1550621 (2025)
2025
-
[43]
& Maalej, W
Rahe, C. & Maalej, W. How do programming students use generative AI?Proceedings of the ACM on Software Engineering2, 978–1000 (2025). 40
2025
-
[44]
Bastani, H.et al.Generative AI without guardrails can harm learning: Evidence from high school mathematics.Proceedings of the National Academy of Sciences122, e2422633122 (2025)
2025
-
[45]
Wiles, E.et al.GenAI as an Exoskeleton: Experimental evidence on knowledge workers using GenAI on new skills.Available at SSRN 4944588(2024)
2024
- [46]
-
[47]
URL https://www.ssrn.com/abstract=4945566
Cui, Z.et al.The effects of generative AI on high skilled work: Evidence from three field experiments with software developers (2024). URL https://www.ssrn.com/abstract=4945566
2024
-
[48]
URL https://arxiv.org/abs/2410.12944
Paradis, E.et al.How much does AI impact development speed? An enterprise-based ran- domized controlled trial (2024). URL https://arxiv.org/abs/2410.12944
-
[49]
& Mayer, S
Weber, T., Brandmaier, M., Schmidt, A. & Mayer, S. Significant productivity gains through programming with large language models.Proceedings of the ACM on Human-Computer Interaction8, 1–29 (2024)
2024
-
[50]
InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 1–23 (ACM, Hamburg Germany, 2023)
Kazemitabaar, M.et al.Studying the effect of AI code generators on supporting novice learners in introductory programming. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, 1–23 (ACM, Hamburg Germany, 2023)
2023
-
[51]
D., Schneider, M
Egger, M., Smith, G. D., Schneider, M. & Minder, C. Bias in meta-analysis detected by a simple, graphical test.BMJ (Clinical research ed.)315, 629–634 (1997)
1997
-
[52]
& Tweedie, R
Duval, S. & Tweedie, R. Trim and Fill: A simple funnel-plot–based method of testing and adjusting for publication bias in meta-analysis.Biometrics. Journal of the International Bio- metric Society56, 455–463 (2000). 41
2000
-
[53]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Jimenez, C. E.et al.Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review arXiv 2023
-
[54]
Shihab, M. I. H.et al.The effects of GitHub copilot on computing students’ programming effectiveness, efficiency, and processes in brownfield coding tasks. InProceedings of the 2025 ACM Conference on International Computing Education Research V.1, ICER ’25, 407–420 (Association for Computing Machinery, New York, NY , USA, 2025)
2025
-
[55]
URL https://arxiv.org/abs/2402.11364
Simkute, A.et al.Ironies of generative AI: Understanding and mitigating productivity loss in human-AI interactions (2024). URL https://arxiv.org/abs/2402.11364
-
[56]
Jin, K., Wang, C.-Y ., Pham, H. V . & Hemmati, H. Can ChatGPT support developers? An empirical evaluation of large language models for code generation (2024)
2024
-
[57]
Bird, C.et al.Taking flight with Copilot.Communications of the ACM66, 56–62 (2023)
2023
-
[58]
M.et al.Building machines that learn and think with people.Nature Human Behaviour8, 1851–1863 (2024)
Collins, K. M.et al.Building machines that learn and think with people.Nature Human Behaviour8, 1851–1863 (2024)
2024
-
[59]
Z.et al.Position: Humans are missing from AI coding agent research
Wang, Z. Z.et al.Position: Humans are missing from AI coding agent research
-
[60]
& Fuccella, V
Piscitelli, A., Costagliola, G., De Rosa, M. & Fuccella, V . Influence of large language models on programming assignments – A user study. InProceedings of the 2024 16th International Conference on Education Technology and Computers, 33–38 (ACM, Porto Vlaams-Brabant Portugal, 2024)
2024
-
[61]
InProceedings of the 2023 Working Group Reports on Innovation and Technology in Computer Science Education, 108–159 (ACM, Turku Finland, 2023)
Prather, J.et al.The robots are here: Navigating the generative AI revolution in computing education. InProceedings of the 2023 Working Group Reports on Innovation and Technology in Computer Science Education, 108–159 (ACM, Turku Finland, 2023)
2023
-
[62]
Generative AI and the transformation of software development practices (2025)
Acharya, V . Generative AI and the transformation of software development practices (2025). URL https://arxiv.org/abs/2510.10819. 42
-
[63]
Bardach, A. & Murrah, H. Bridging the skills gap: A course model for modern generative AI education (2025). URL https://arxiv.org/abs/2511.11757
-
[64]
Computer science education in the age of generative AI (2025)
Beale, R. Computer science education in the age of generative AI (2025). URL https://arxiv. org/abs/2507.02183
-
[65]
& Drucker, S
Gu, K., Shang, R., Althoff, T., Wang, C. & Drucker, S. M. How Do Analysts Understand and Verify AI-Assisted Data Analyses? InProceedings of the CHI Conference on Human Factors in Computing Systems, 1–22 (ACM, Honolulu HI USA, 2024)
2024
-
[66]
Hoffmann, M., Boysel, S., Nagle, F., Peng, S. & Xu, K. Generative AI and the nature of work.Harvard Business School Strategy Unit Working Paper25–021 (2025)
2025
-
[67]
URL https://arxiv.org/abs/2511.04144
Ma, B.et al.Scaffolding metacognition in programming education: Understanding student- AI interactions and design implications (2025). URL https://arxiv.org/abs/2511.04144
-
[68]
Denny, P.et al.Computing education in the era of generative AI.Communications of the ACM67, 56–67 (2024)
2024
-
[69]
N., Fritz, T., Murphy, G
Meyer, A. N., Fritz, T., Murphy, G. C. & Zimmermann, T. Software developers’ perceptions of productivity. InProceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, 19–29 (ACM, Hong Kong China, 2014)
2014
-
[70]
V ., Higgins, J
Borenstein, M., Hedges, L. V ., Higgins, J. P. T. & Rothstein, H. R.Introduction to meta- analysis(Wiley, 2009), 1 edn
2009
-
[71]
& Rees, D
Gambacorta, L., Qiu, H., Shan, S. & Rees, D. M.Generative AI and labour productivity: a field experiment on coding, 1208 (Bank for International Settlements, Monetary and Eco- nomic Department, 2024)
2024
-
[72]
J.et al.The PRISMA 2020 statement: an updated guideline for reporting systematic reviews.BMJ (Clinical research ed.)n71 (2021)
Page, M. J.et al.The PRISMA 2020 statement: an updated guideline for reporting systematic reviews.BMJ (Clinical research ed.)n71 (2021). 43
2020
-
[73]
InProceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, 21–29 (ACM, San Diego CA USA, 2022)
Ziegler, A.et al.Productivity assessment of neural code completion. InProceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, 21–29 (ACM, San Diego CA USA, 2022)
2022
-
[74]
& Kim, H
Choi, S. & Kim, H. The impact of a large language model-based programming learning environment on students’ motivation and programming ability.Education and Information Technologies30, 8109–8138 (2025)
2025
-
[75]
& Feuerriegel, S
Hölbling, L., Maier, S. & Feuerriegel, S. A meta-analysis of the persuasive power of large language models.Scientific Reports15, 43818 (2025)
2025
-
[76]
Holzner, N., Maier, S. & Feuerriegel, S. Generative AI and creativity: a systematic literature review and meta-analysis (2025). URL https://arxiv.org/abs/2505.17241
-
[77]
Morris, S. B. Estimating Effect Sizes From Pretest-Posttest-Control Group Designs.Orga- nizational Research Methods11, 364–386 (2008)
2008
-
[78]
Morris, S. B. & DeShon, R. P. Combining effect size estimates in meta-analysis with repeated measures and independent-groups designs.Psychological Methods7, 105–125 (2002)
2002
-
[79]
Hedges, L. V . Distribution theory for Glass’s estimator of effect size and related estimators. Journal of Educational Statistics6, 107–128 (1981)
1981
-
[80]
Higgins, J. P.et al. Cochrane handbook for systematic reviews of interventions(Cochrane, 2024), version 6.5 (updated august 2024) edn
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.