Recognition: 3 theorem links
· Lean TheoremUno-Orchestra: Parsimonious Agent Routing via Selective Delegation
Pith reviewed 2026-05-08 18:00 UTC · model grok-4.3
The pith
A learned policy for selective task decomposition and model routing in LLM agents reaches 77% accuracy while cutting per-query cost by an order of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
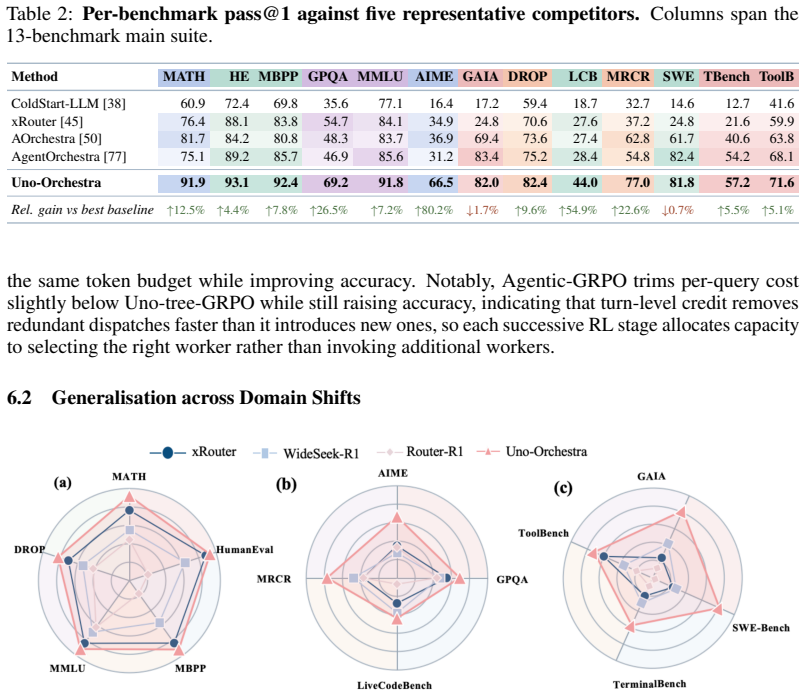
Uno-Orchestra is a unified orchestration policy that selectively decomposes a task and dispatches each subtask to an admissible (model, primitive) pair, with both decisions learned together from curated RL trajectories grounded in real worker interactions. Against 22 baselines on a 13-benchmark suite spanning math, code, knowledge, long-context, and agentic tool-use, Uno-Orchestra reaches 77.0% macro pass@1, roughly 16% above the strongest workflow baseline, at roughly an order of magnitude lower per-query cost.
What carries the argument
The central mechanism is a single learned policy that jointly selects decomposition depth and worker assignment by choosing from admissible (model, primitive) pairs, trained end-to-end on interaction trajectories rather than through separate hand-crafted rules.
If this is right
- Decomposition depth and model choice become dynamic per query instead of fixed in advance.
- The system can reserve deeper or stronger workers only for tasks where they measurably improve outcomes.
- Overall compute per query drops because unnecessary subtasks and overpowered models are skipped.
- The same policy applies without redesign across math, code, knowledge, long-context, and tool-use domains.
Where Pith is reading between the lines
- If interaction data can be collected at scale, many existing agent frameworks could replace their static routers with a learned one trained on their own logs.
- The approach suggests that data-driven routing may matter more for efficiency than simply scaling model size or adding more agents.
- One could test whether the policy remains effective when the set of available models changes over time, by retraining only on new trajectories.
- Extending the method to online adaptation might let the system refine its routing decisions as it encounters novel task distributions.
Load-bearing premise
The curated RL trajectories from past worker interactions are representative of future tasks and the policy will generalize without introducing systematic decomposition errors or hidden costs.
What would settle it
Evaluating the same policy on a new suite of tasks outside the original 13 benchmarks that require decomposition patterns or tool combinations absent from the training trajectories, and measuring whether the accuracy and cost advantages persist or collapse.
Figures





read the original abstract
Large language model (LLM) multi-agent systems typically rely on rigid orchestration, committing either to flat per-query routing or to hand-engineered task decomposition, so decomposition depth, worker choice, and inference budget are not jointly optimized under one objective. We introduce Uno-Orchestra, a unified orchestration policy that selectively decomposes a task and dispatches each subtask to an admissible (model, primitive) pair, with both decisions learned together from curated RL trajectories grounded in real worker interactions. Against 22 baselines on a 13-benchmark suite spanning math, code, knowledge, long-context, and agentic tool-use, Uno-Orchestra reaches 77.0% macro pass@1, roughly 16% above the strongest workflow baseline, at roughly an order of magnitude lower per-query cost, advancing the accuracy-efficiency frontier of selective delegation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Uno-Orchestra, a unified orchestration policy for LLM multi-agent systems that jointly learns selective task decomposition and dispatch to admissible (model, primitive) pairs from curated RL trajectories grounded in real worker interactions. It evaluates the approach against 22 baselines across a 13-benchmark suite covering math, code, knowledge, long-context, and agentic tool-use tasks, reporting 77.0% macro pass@1 (roughly 16% above the strongest workflow baseline) at an order of magnitude lower per-query cost.
Significance. If the performance and cost claims hold under rigorous validation, the work would meaningfully advance the accuracy-efficiency frontier for selective delegation in multi-agent LLM systems by replacing rigid or hand-engineered orchestration with a single learned policy. The grounding in real interaction trajectories and joint optimization of decomposition depth and routing are notable strengths that could influence future agent routing designs.
major comments (3)
- [§4] §4 (Experiments) and Table 2: the headline 77.0% macro pass@1 and +16% lift over the strongest baseline are presented without reported statistical tests, variance across runs, or explicit definitions of the 22 baselines and their configurations; this makes it impossible to assess whether the gains are robust or attributable to the learned policy rather than implementation details.
- [§3.2] §3.2 (RL Training) and §5 (Ablations): the claim that the policy generalizes from curated trajectories to the full 13-benchmark diversity (math, code, long-context, tool-use) lacks evidence on trajectory coverage, decomposition pattern distribution, or out-of-distribution performance; if the training distribution is narrower, the reported cost reduction and accuracy lift could be overstated.
- [Table 3] Table 3 (Cost Analysis): the order-of-magnitude per-query cost reduction is reported as a key result, but without breakdown of hidden orchestration overhead, token usage for decomposition decisions, or sensitivity to model choice, the efficiency claim cannot be fully evaluated against the accuracy gains.
minor comments (2)
- [Abstract] The abstract and introduction use 'macro pass@1' without an early definition or reference to how it aggregates across the heterogeneous benchmarks.
- [Figure 1] Figure 1 (system diagram) would benefit from explicit annotation of the learned policy components (decomposition decision and dispatch) to match the textual description in §2.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the clarity and rigor of our experimental claims. We address each major comment below and commit to revisions that will strengthen the manuscript without misrepresenting our results.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and Table 2: the headline 77.0% macro pass@1 and +16% lift over the strongest baseline are presented without reported statistical tests, variance across runs, or explicit definitions of the 22 baselines and their configurations; this makes it impossible to assess whether the gains are robust or attributable to the learned policy rather than implementation details.
Authors: We agree that statistical tests, variance reporting, and explicit baseline definitions are necessary for assessing robustness. In the revised manuscript, we will add standard deviations computed over multiple independent runs (minimum 5 seeds), include paired statistical significance tests (e.g., Wilcoxon signed-rank) for the reported lifts, and expand §4 plus the appendix with precise configurations, hyperparameters, and implementation details for all 22 baselines. These additions will make it possible to attribute gains more clearly to the learned policy. revision: yes
-
Referee: [§3.2] §3.2 (RL Training) and §5 (Ablations): the claim that the policy generalizes from curated trajectories to the full 13-benchmark diversity (math, code, long-context, tool-use) lacks evidence on trajectory coverage, decomposition pattern distribution, or out-of-distribution performance; if the training distribution is narrower, the reported cost reduction and accuracy lift could be overstated.
Authors: The trajectories were curated from real worker interactions spanning the benchmark categories, but we acknowledge the need for explicit coverage analysis. We will revise §3.2 to include quantitative statistics on trajectory task-type distribution and decomposition-depth patterns, and extend §5 with additional held-out task evaluations to probe out-of-distribution behavior. This will either further support the generalization claims or allow us to qualify them appropriately. revision: yes
-
Referee: [Table 3] Table 3 (Cost Analysis): the order-of-magnitude per-query cost reduction is reported as a key result, but without breakdown of hidden orchestration overhead, token usage for decomposition decisions, or sensitivity to model choice, the efficiency claim cannot be fully evaluated against the accuracy gains.
Authors: We concur that a finer-grained cost breakdown is required to substantiate the efficiency results. In the revision we will expand Table 3 and its discussion to report orchestration overhead (policy inference tokens), token counts specifically for decomposition decisions, sensitivity sweeps over orchestrator model choices, and per-benchmark cost-accuracy pairs. These details will enable a more transparent comparison of net gains. revision: yes
Circularity Check
No circularity: empirical RL policy evaluated on independent benchmarks
full rationale
The paper presents an RL-trained orchestration policy whose decisions are learned from curated trajectories of real worker interactions and then evaluated on a 13-benchmark suite. No equations, fitted parameters, or self-citations are shown that would make the reported 77% pass@1 or cost reduction equivalent to the training data by construction. The derivation chain is therefore self-contained: training data and test benchmarks remain distinct, and performance gains are measured rather than defined.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Foundation/AlphaCoordinateFixation, Cost/FunctionalEquation (J-cost)J_uniquely_calibrated_via_higher_derivative unclearPPO clipping ϵ=0.2, KL against a frozen router reference β=10⁻³, terminal cost blending α=0.1 ... at most T_max=8 orchestrator turns
Reference graph
Works this paper leans on
-
[1]
The orchestration of multi-agent systems: Architectures, protocols, and enterprise adoption
Apoorva Adimulam, Rajesh Gupta, and Sumit Kumar. The orchestration of multi-agent systems: Architectures, protocols, and enterprise adoption.arXiv preprint arXiv:2601.13671, 2026
-
[2]
Automix: Automatically mixing language models
Pranjal Aggarwal, Aman Madaan, Ankit Anand, Srividya Pranavi Potharaju, Swaroop Mishra, Pei Zhou, Aditya Gupta, Dheeraj Rajagopal, Karthik Kappaganthu, Yiming Yang, et al. Automix: Automatically mixing language models.arXiv preprint arXiv:2310.12963, 2023
-
[3]
Ai-mo/aimo-validation-aime
AI-MO. Ai-mo/aimo-validation-aime. https://huggingface.co/datasets/AI-MO/ aimo-validation-aime, 2024
2024
-
[4]
Claude code: Create custom subagents
Anthropic. Claude code: Create custom subagents. Anthropic Documentation, 2026. URL https://docs.anthropic.com/en/docs/claude-code/sub-agents
2026
-
[5]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page Pith review arXiv 2021
-
[6]
Semantic parsing on freebase from question-answer pairs
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. Semantic parsing on freebase from question-answer pairs. InProceedings of the 2013 conference on empirical methods in natural language processing, pages 1533–1544, 2013
2013
-
[7]
Piqa: Reasoning about phys- ical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[8]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review arXiv 2021
-
[9]
Routerdc: Query-based router by dual contrastive learning for assembling large language models.Advances in Neural Information Processing Systems, 37:66305–66328, 2024
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. Routerdc: Query-based router by dual contrastive learning for assembling large language models.Advances in Neural Information Processing Systems, 37:66305–66328, 2024
2024
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page Pith review arXiv 2018
-
[11]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page Pith review arXiv 2025
-
[13]
Multi-agent collaboration via evolving orchestration, arXiv preprint arXiv:2505.19591, 2025
Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, et al. Multi-agent collaboration via evolving orchestration.arXiv preprint arXiv:2505.19591, 2025. 10
-
[14]
Zheng Ding and Weirui Ye. Treegrpo: Tree-advantage grpo for online rl post-training of diffusion models.arXiv preprint arXiv:2512.08153, 2025
-
[15]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gard- ner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Paper...
2019
-
[16]
GraphRAG-Router: Learning Cost-Efficient Routing over GraphRAGs and LLMs with Reinforcement Learning
Dongzhe Fan, Chuanhao Ji, Zimu Wang, Tong Chen, and Qiaoyu Tan. Graphrag-router: Learning cost-efficient routing over graphrags and llms with reinforcement learning.arXiv preprint arXiv:2604.16401, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Jinyuan Fang, Yanwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, et al. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025
-
[18]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
A., Tihanyi, N., and Debbah, M
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review.arXiv preprint arXiv:2504.19678, 2025
-
[20]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361, 2021
2021
-
[21]
Gemini 3 Pro model card
Google DeepMind. Gemini 3 Pro model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf, 2025
2025
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Folio: Natural language reasoning with first-order logic
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, et al. Folio: Natural language reasoning with first-order logic. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 22017–22031, 2024
2024
-
[24]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review arXiv 2009
-
[25]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review arXiv 2021
-
[26]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pages 6609–6625, 2020
2020
-
[27]
open-r1/codeforces-cots
Hugging Face Open-R1. open-r1/codeforces-cots. https://huggingface.co/datasets/ open-r1/codeforces-cots, 2025
2025
-
[28]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
Tree search for llm agent reinforcement learning, 2026
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for llm agent reinforcement learning.arXiv preprint arXiv:2509.21240, 2025
-
[30]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023. 11
work page internal anchor Pith review arXiv 2023
-
[31]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017
2017
-
[32]
Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
2019
-
[33]
LLMRouterBench: A Massive Benchmark and Unified Framework for LLM Routing
Hao Li, Yiqun Zhang, Zhaoyan Guo, Chenxu Wang, Shengji Tang, Qiaosheng Zhang, Yang Chen, Biqing Qi, Peng Ye, Lei Bai, et al. Llmrouterbench: A massive benchmark and unified framework for llm routing.arXiv preprint arXiv:2601.07206, 2026
-
[34]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
2024
-
[35]
TACO: Topics in algorithmic code generation dataset.arXiv preprint arXiv:2312.14852, 2023
Rongao Li, Jie Fu, Bo-Wen Zhang, Tao Huang, Zhihong Sun, Chen Lyu, Guang Liu, Zhi Jin, and Ge Li. Taco: Topics in algorithmic code generation dataset.arXiv preprint arXiv:2312.14852, 2023
-
[36]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[37]
Logiqa 2.0–an improved dataset for logical reasoning in natural language understanding
Hanmeng Liu, Jian Liu, Leyang Cui, Zhiyang Teng, Nan Duan, Ming Zhou, and Yue Zhang. Logiqa 2.0–an improved dataset for logical reasoning in natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2947–2962, 2023
2023
-
[38]
Task-Aware LLM Routing with Multi-Level Task-Profile-Guided Data Synthesis for Cold-Start Scenarios
Hui Liu, Bin Zou, Kecheng Chen, Jie Liu, Wenya Wang, and Haoliang Li. Task-aware llm routing with multi-level task-profile-guided data synthesis for cold-start scenarios.arXiv preprint arXiv:2604.09377, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
arXiv preprint arXiv:2409.00920
Weiwen Liu, Xu Huang, Xingshan Zeng, Xinlong Hao, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Zhengying Liu, Yuanqing Yu, et al. Toolace: Winning the points of llm function calling.arXiv preprint arXiv:2409.00920, 2024
-
[40]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[41]
Tianyi Niu, Justin Chih-Yao Chen, Genta Indra Winata, Shi-Xiong Zhang, Supriyo Chakraborty, Sambit Sahu, Yue Zhang, Elias Stengel-Eskin, and Mohit Bansal. Routing with generated data: Annotation-free llm skill estimation and expert selection.arXiv preprint arXiv:2601.09692, 2026
-
[42]
Explainable Model Routing for Agentic Workflows
Mika Okamoto, Ansel Kaplan Erol, and Mark Riedl. Explainable model routing for agentic workflows.arXiv preprint arXiv:2604.03527, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, 2022
2022
-
[44]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, et al. Quality: Question answering with long input texts, yes! InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, ...
2022
-
[45]
Cheng Qian, Zuxin Liu, Shirley Kokane, Akshara Prabhakar, Jielin Qiu, Haolin Chen, Zhi- wei Liu, Heng Ji, Weiran Yao, Shelby Heinecke, et al. xrouter: Training cost-aware llms orchestration system via reinforcement learning.arXiv preprint arXiv:2510.08439, 2025
-
[46]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis.arXiv preprint arXiv:2307.16789, 2023
work page internal anchor Pith review arXiv 2023
-
[47]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[48]
Zero: Memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimiza- tions toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[49]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review arXiv 2023
-
[50]
Jianhao Ruan, Zhihao Xu, Yiran Peng, Fashen Ren, Zhaoyang Yu, Xinbing Liang, Jinyu Xiang, Yongru Chen, Bang Liu, Chenglin Wu, et al. Aorchestra: Automating sub-agent creation for agentic orchestration.arXiv preprint arXiv:2602.03786, 2026
-
[51]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[52]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473, 2019
2019
-
[53]
Thread: Thinking deeper with recursive spawning
Philip Schroeder, Nathaniel W Morgan, Hongyin Luo, and James Glass. Thread: Thinking deeper with recursive spawning. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8418–8442, 2025
2025
-
[54]
Proximal policy optimization algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. 2017
2017
-
[55]
Chenyang Shao, Xinyang Liu, Yutang Lin, Fengli Xu, and Yong Li. Route-and-reason: Scaling large language model reasoning with reinforced model router.arXiv preprint arXiv:2506.05901, 2025
-
[56]
Route-and-reason: Energy- efficient scaling of llm reasoning via reinforced model routing
Chenyang Shao, Xinyang Liu, Yutang Lin, Fengli Xu, and Yong Li. Route-and-reason: Energy- efficient scaling of llm reasoning via reinforced model routing. InProceedings of the ACM Web Conference 2026, pages 9551–9562, 2026
2026
-
[57]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[58]
arXiv preprint arXiv:2511.21689 , year=
Hongjin Su, Shizhe Diao, Ximing Lu, Mingjie Liu, Jiacheng Xu, Xin Dong, Yonggan Fu, Peter Belcak, Hanrong Ye, Hongxu Yin, et al. Toolorchestra: Elevating intelligence via efficient model and tool orchestration.arXiv preprint arXiv:2511.21689, 2025
-
[59]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Compu- tational Linguistics: ACL 2023, pages 13003–13051, 2023. 13
2023
-
[60]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, 2019
2019
-
[61]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review arXiv 2024
-
[62]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review arXiv 2026
-
[63]
Terminal-bench: A benchmark for ai agents in terminal environments, 2025
TTB Team. Terminal-bench: A benchmark for ai agents in terminal environments, 2025
2025
-
[64]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[65]
Icl-router: In-context learned model representations for llm routing
Chenxu Wang, Hao Li, Yiqun Zhang, Linyao Chen, Jianhao Chen, Ping Jian, Qiaosheng Zhang, and Shuyue Hu. Icl-router: In-context learned model representations for llm routing. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33413–33421, 2026
2026
-
[66]
arXiv preprint arXiv:2602.19672 , year=
Jiayu Wang, Yifei Ming, Zixuan Ke, Shafiq Joty, Aws Albarghouthi, and Frederic Sala. Skil- lorchestra: Learning to route agents via skill transfer.arXiv preprint arXiv:2602.19672, 2026
-
[67]
Crowdsourcing multiple choice science questions
Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. InProceedings of the 3rd Workshop on Noisy User-generated Text, pages 94–106, 2017
2017
-
[68]
Jinyang Wu, Guocheng Zhai, Ruihan Jin, Jiahao Yuan, Yuhao Shen, Shuai Zhang, Zhengqi Wen, and Jianhua Tao. Atlas: Orchestrating heterogeneous models and tools for multi-domain complex reasoning.arXiv preprint arXiv:2601.03872, 2026
-
[69]
Zelai Xu, Zhexuan Xu, Ruize Zhang, Chunyang Zhu, Shi Yu, Weilin Liu, Quanlu Zhang, Wenbo Ding, Chao Yu, and Yu Wang. Wideseek-r1: Exploring width scaling for broad information seeking via multi-agent reinforcement learning.arXiv preprint arXiv:2602.04634, 2026
-
[70]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018
2018
-
[71]
Survey on Evaluation of LLM-based Agents
Asaf Yehudai, Lilach Eden, Alan Li, Guy Uziel, Yilun Zhao, Roy Bar-Haim, Arman Cohan, and Michal Shmueli-Scheuer. Survey on evaluation of llm-based agents.arXiv preprint arXiv:2503.16416, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Jiahao Yuan, Yike Xu, Jinyong Wen, Baokun Wang, Yang Chen, Xiaotong Lin, Wuliang Huang, Ziyi Gao, Xing Fu, Yu Cheng, et al. How do decoder-only llms perceive users? rethinking attention masking for user representation learning.arXiv preprint arXiv:2602.10622, 2026
-
[73]
Masrouter: Learning to route llms for multi-agent systems
Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. Masrouter: Learning to route llms for multi-agent systems. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15549–15572, 2025
2025
-
[74]
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment
Siliang Zeng, Quan Wei, William Brown, Oana Frunza, Yuriy Nevmyvaka, Yang Katie Zhao, and Mingyi Hong. Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment. InICML 2025 Workshop on Computer Use Agents, 2025
2025
-
[75]
Evoroute: Experience-driven self-routing llm agent systems.arXiv preprint arXiv:2601.02695, 2026
Guibin Zhang, Haiyang Yu, Kaiming Yang, Bingli Wu, Fei Huang, Yongbin Li, and Shuicheng Yan. Evoroute: Experience-driven self-routing llm agent systems.arXiv preprint arXiv:2601.02695, 2026. 14
-
[76]
Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning
Haozhen Zhang, Tao Feng, and Jiaxuan You. Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[77]
Agentorchestra: A hierarchical multi-agent framework for general-purpose task solving.arXiv e-prints, pages arXiv–2506, 2025
Wentao Zhang, Ce Cui, Yilei Zhao, Rui Hu, Yang Liu, Yahui Zhou, and Bo An. Agentorchestra: A hierarchical multi-agent framework for general-purpose task solving.arXiv e-prints, pages arXiv–2506, 2025
2025
-
[78]
same task and same turn
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. InForty-first International Conference on Machine Learning, 2024. A Experimental Details A.1 Evaluation reporting conventions The main suite comprises the thirteen public benchmarks enumerated in §5. LLMR...
2024
-
[79]
If not, emit <final_answer> directly
Decide whether the task warrants decomposition. If not, emit <final_answer> directly
-
[80]
Otherwise, write a <plan> that exposes parallel substructure where it exists; encode strict ordering only viadepends_on
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.