Recognition: no theorem link
GraphRAG-Router: Learning Cost-Efficient Routing over GraphRAGs and LLMs with Reinforcement Learning
Pith reviewed 2026-05-13 23:47 UTC · model grok-4.3
The pith
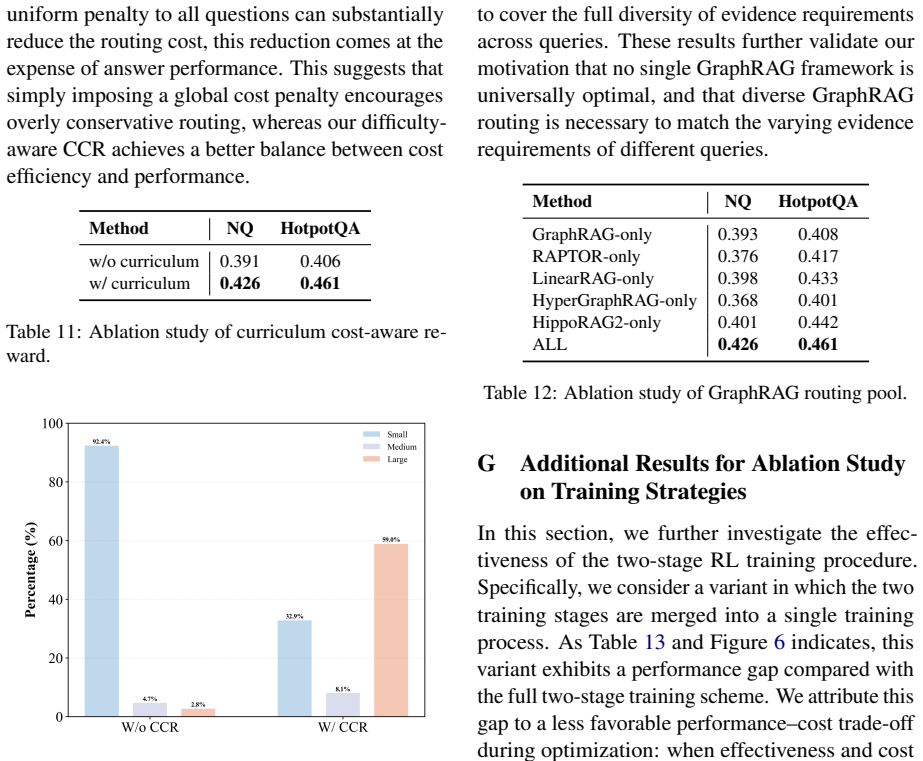
A two-stage RL router learns to match queries to cheaper GraphRAG and LLM combinations, cutting large-model overuse by nearly 30 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GraphRAG-Router is a hierarchical routing framework that coordinates heterogeneous GraphRAG variants and generator LLMs. It is first warmed up by supervised fine-tuning and then refined by a two-stage reinforcement-learning procedure whose second stage uses a curriculum cost-aware reward to encourage difficulty-aware, economical allocation. On six QA benchmarks the resulting policy consistently outperforms state-of-the-art baselines while reducing overuse of large LLMs by nearly 30 percent and retaining strong generalization.
What carries the argument
The hierarchical router whose policy is optimized by two-stage reinforcement learning that incorporates a curriculum cost-aware reward to select among heterogeneous GraphRAGs and generator LLMs according to estimated query difficulty.
If this is right
- Outperforms state-of-the-art routing baselines on six general-domain and multi-hop QA benchmarks.
- Reduces overuse of large LLMs by nearly 30 percent while preserving answer quality.
- Maintains strong generalization to unseen queries.
- Coordinates multiple GraphRAG frameworks and generator LLMs through a single learned policy.
- Encourages economical allocation that scales with query difficulty.
Where Pith is reading between the lines
- The same routing logic could be applied to other retrieval-augmented systems that mix retrievers of different cost and capability.
- Production deployments handling high query volumes would see larger absolute savings than the reported benchmark numbers.
- The router could be extended to additional axes such as latency targets or domain-specific model preferences.
Load-bearing premise
The curriculum cost-aware reward in the second reinforcement-learning stage teaches the router to estimate query difficulty accurately enough to allocate smaller models without overfitting to the training distribution.
What would settle it
If a new test set of queries with controlled difficulty levels shows either no reduction in large-LLM usage or a clear drop in answer accuracy relative to always using the largest model, the central performance claim would be falsified.
Figures












read the original abstract
Graph-based retrieval-augmented generation (GraphRAG) has recently emerged as a powerful paradigm for knowledge-intensive question answering, especially for tasks that require structured evidence organization and multi-hop reasoning. However, existing GraphRAG systems are typically built in a one-size-fits-all manner, relying on a fixed retrieval framework and a single, often large and costly, generator LLM for all queries. This static design limits their ability to adapt to the complexity of varying questions and often incurs unnecessary computational cost. To fill in the gap, we propose GraphRAG-Router, a cost-efficient framework that adopts a hierarchical routing strategy to coordinate heterogeneous GraphRAGs and generator LLMs. Specifically, GraphRAG-Router is first warmed up through supervised fine-tuning and then optimized with a two-stage reinforcement learning procedure, whose second stage introduces a curriculum cost-aware reward to encourage difficulty-aware and economical generator allocation. Extensive experiments on six general-domain and multi-hop QA benchmarks show that GraphRAG-Router consistently outperforms state-of-the-art baselines, reducing the overuse of large LLMs by nearly 30% while maintaining strong generalization capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GraphRAG-Router, a hierarchical routing framework that coordinates heterogeneous GraphRAG systems and generator LLMs. It first applies supervised fine-tuning for warm-up, then optimizes via a two-stage reinforcement learning procedure whose second stage uses a curriculum cost-aware reward to promote difficulty-aware and economical allocation of generators. Experiments across six general-domain and multi-hop QA benchmarks are reported to show consistent outperformance over state-of-the-art baselines together with a nearly 30% reduction in large-LLM usage while preserving generalization.
Significance. If the empirical claims hold under rigorous verification, the work would offer a concrete, deployable method for reducing the computational cost of GraphRAG pipelines without sacrificing accuracy. The two-stage RL design with curriculum cost-aware reward constitutes a novel application of reinforcement learning to the routing problem in retrieval-augmented generation, addressing the static one-size-fits-all limitation of existing GraphRAG systems and potentially enabling more scalable knowledge-intensive QA.
major comments (2)
- [Method (RL procedure)] Method section (RL procedure and reward definition): the curriculum cost-aware reward is described as encouraging difficulty-aware allocation, yet no independent, query-intrinsic difficulty signal (e.g., explicit multi-hop count, entity-graph density, or pre-computed complexity label) is introduced. Because the reward is derived from observed performance/cost on the training distribution, the policy may overfit to dataset-specific cost patterns rather than learning transferable difficulty estimation, directly threatening the reported 30% reduction and cross-benchmark generalization claim.
- [Experiments] Experiments section: the abstract asserts consistent outperformance and a nearly 30% cost reduction across six benchmarks, but the provided text supplies neither per-benchmark metrics, baseline configurations, statistical significance tests, nor ablation results isolating the contribution of the two-stage RL and curriculum reward. Without these, the central performance claims remain unverifiable and the generalization statement cannot be assessed.
minor comments (1)
- [Abstract] Abstract: a single sentence listing the six benchmarks and the precise cost-reduction figure would improve clarity and allow readers to gauge the scope immediately.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below and commit to revisions that will strengthen the clarity and verifiability of the work.
read point-by-point responses
-
Referee: [Method (RL procedure)] Method section (RL procedure and reward definition): the curriculum cost-aware reward is described as encouraging difficulty-aware allocation, yet no independent, query-intrinsic difficulty signal (e.g., explicit multi-hop count, entity-graph density, or pre-computed complexity label) is introduced. Because the reward is derived from observed performance/cost on the training distribution, the policy may overfit to dataset-specific cost patterns rather than learning transferable difficulty estimation, directly threatening the reported 30% reduction and cross-benchmark generalization claim.
Authors: We agree that the manuscript does not introduce an explicit, query-intrinsic difficulty label or feature. The curriculum cost-aware reward is intentionally computed from the agent's observed accuracy-cost trade-off during training episodes, enabling the policy to infer difficulty implicitly through reinforcement signals. The two-stage procedure (supervised warm-up followed by curriculum RL) is designed to stabilize learning and promote transfer by progressively exposing the policy to higher-cost or lower-accuracy queries. We acknowledge the risk of dataset-specific overfitting and will add a dedicated paragraph in the revised Method section explaining this implicit mechanism, together with new cross-dataset transfer experiments to empirically support generalization. revision: partial
-
Referee: [Experiments] Experiments section: the abstract asserts consistent outperformance and a nearly 30% cost reduction across six benchmarks, but the provided text supplies neither per-benchmark metrics, baseline configurations, statistical significance tests, nor ablation results isolating the contribution of the two-stage RL and curriculum reward. Without these, the central performance claims remain unverifiable and the generalization statement cannot be assessed.
Authors: We apologize that the submitted version did not present these details with sufficient granularity. The revised manuscript will include: (i) a new table with per-benchmark accuracy and cost metrics (including standard deviations over multiple seeds), (ii) explicit hyper-parameter and baseline configurations, (iii) statistical significance results (paired t-tests with p-values), and (iv) ablation studies that isolate the contribution of the two-stage RL schedule and the curriculum cost-aware reward. These additions will make all central claims directly verifiable. revision: yes
Circularity Check
No significant circularity: empirical RL framework validated on external benchmarks
full rationale
The paper describes a hierarchical routing system trained via supervised fine-tuning followed by two-stage RL with a curriculum cost-aware reward. No equations, derivations, or first-principles claims are presented that reduce by construction to fitted parameters or self-referential definitions. Performance metrics (e.g., ~30% reduction in large-LLM usage) are reported as outcomes of optimization against six independent QA benchmarks rather than as predictions forced by the reward formulation itself. No self-citation chains, uniqueness theorems, or ansatz smuggling are invoked as load-bearing steps. The central claims rest on empirical generalization rather than internal redefinition of inputs as outputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Uno-Orchestra: Parsimonious Agent Routing via Selective Delegation
A learned orchestration policy for LLM agents that jointly optimizes task decomposition and selective routing to (model, primitive) pairs, delivering 77% macro pass@1 at 10x lower cost than strong baselines across 13 ...
Reference graph
Works this paper leans on
-
[1]
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang
Curriculum reinforcement learning from easy to hard tasks improves llm reasoning.Preprint, arXiv:2506.06632. Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Zhang, and Siliang Tang. 2025. Graph retrieval-augmented generation: A survey.ACM Transactions on Information Systems, 44(2):1–52. Qwen, :, An Yang, Baosong Yang, Beichen Z...
-
[2]
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval,
Raptor: Recursive abstractive processing for tree-organized retrieval.Preprint, arXiv:2401.18059. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.Preprint, arXiv:2402.03300. Aadit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.