Recognition: unknown
Scalable inference of spatial regions and temporal signatures from time series
Pith reviewed 2026-05-08 16:35 UTC · model grok-4.3
The pith
A minimum description length approach jointly infers contiguous spatial regions and their driving time series archetypes from spatiotemporal data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By minimizing the combined description length of a spatial partition together with a set of archetype time series and the assignments of each location to an archetype, the method automatically determines both the number and boundaries of contiguous regions and the temporal signatures that best compress the observed spatiotemporal dataset.
What carries the argument
Minimum description length objective that trades off the bits required to encode a contiguous spatial partition, the archetype time series, and the data given those archetypes, optimized jointly under contiguity.
If this is right
- The method recovers planted regional structure and drivers accurately in synthetic spatiotemporal time series.
- It identifies meaningful structural regularities in large empirical air quality and vegetation index records.
- Runtime scales log-linearly with the number of time series, supporting application to datasets too large for prior approaches.
- Both the spatial partition and temporal patterns emerge directly from the data without requiring users to preset the number of regions.
Where Pith is reading between the lines
- The same compression principle could be tested on other spatiotemporal records such as economic indicators or disease incidence to see whether it yields policy-relevant regions.
- Extending the model to allow time-varying archetypes might reveal how region boundaries themselves shift with seasonal or event-driven drivers.
- Because the approach is fully nonparametric, it could serve as a baseline for comparing against methods that impose stronger parametric assumptions on temporal shapes.
Load-bearing premise
That minimizing total description length subject to spatial contiguity will recover the underlying planted or real-world regional structure without strong dependence on optimization details or post-processing choices.
What would settle it
Applying the method to synthetic datasets with explicitly planted contiguous regions and known archetype drivers, then checking whether the inferred partition and archetypes match the planted ones to high accuracy.
Figures







read the original abstract
Regionalization aims to partition a spatial domain into contiguous regions that share similar characteristics, enabling more effective spatial analysis, policy making, and resource management. Existing approaches for spatial regionalization typically rely on static spatial snapshots rather than evolving time series. Meanwhile, most time series clustering methods ignore spatial structure or enforce spatial continuity through ad hoc regularization, constraining the number of inferred regions a priori either explicitly or implicitly. Utilizing the minimum description length principle from information theory, here we propose an efficient and fully nonparametric framework for the regionalization of spatial time series. Our method jointly infers a spatial partition along with a set of representative time series archetypes ("drivers") that best compress a spatiotemporal dataset, with a runtime log-linear in the number of time series. We demonstrate that this method can accurately recover planted regional structure and drivers in synthetic time series, and can extract meaningful structural regularities in large-scale empirical air quality and vegetation index records. Our method provides a principled and scalable framework for spatially contiguous partitioning, allowing interpretable temporal patterns and homogeneous regions to emerge directly from the data itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
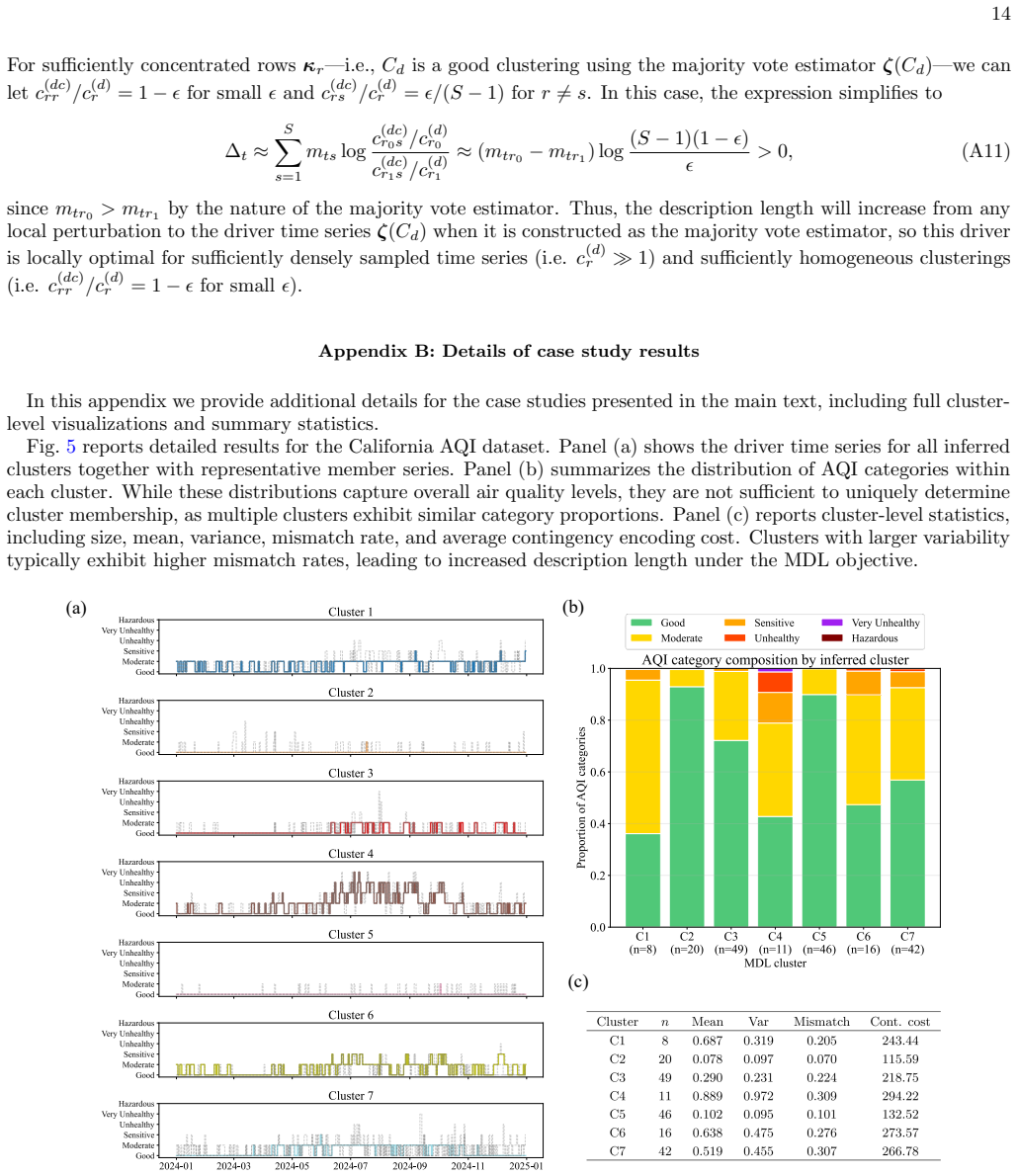
Summary. The manuscript proposes a minimum description length (MDL) based, fully nonparametric framework for regionalizing spatial time series. It jointly infers a contiguous spatial partition and a set of representative temporal archetypes (drivers) that together minimize the total description length of the data, with claimed log-linear runtime scaling in the number of time series. The approach is demonstrated to recover planted regional structure and drivers on synthetic data and to extract interpretable patterns from large-scale air quality and vegetation index records.
Significance. If the central claims hold, the work supplies a principled, compression-driven alternative to existing spatial regionalization and time-series clustering methods that typically require pre-specifying the number of regions or impose ad-hoc spatial penalties. The joint MDL objective and nonparametric character could yield more stable, interpretable partitions directly from data, with clear utility for environmental monitoring and large-scale spatiotemporal analysis.
major comments (2)
- [Methods / Optimization procedure] The abstract asserts accurate recovery of planted structure on synthetic data, yet the optimization procedure used to minimize the joint MDL objective under spatial contiguity constraints is not specified. Because exact minimization over contiguous partitions is NP-hard, any practical algorithm must rely on heuristics (greedy merging, local search, or pruned dynamic programming). Without an explicit description of the search algorithm, initialization strategy, and convergence criteria (presumably in the Methods section), it is impossible to determine whether the reported synthetic recoveries are robust properties of the MDL criterion or artifacts of favorable planted cases and search details.
- [Empirical results] For the empirical air-quality and vegetation examples, the manuscript claims extraction of 'meaningful structural regularities' but provides no quantitative validation (e.g., held-out compression scores, comparison against baseline regionalizations, or stability across random restarts). Because the weakest modeling assumption is that MDL minimization under contiguity will automatically yield stable, interpretable regions, the absence of such checks leaves the real-data claims unsupported.
minor comments (2)
- [Abstract] The runtime claim 'log-linear in the number of time series' should be accompanied by the precise big-O expression and any dependence on spatial grid size or number of candidate archetypes.
- [Methods] The encoding scheme used for the archetypes and the partition in the MDL objective should be stated explicitly so that readers can verify the 'fully nonparametric' claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. We respond to each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Methods / Optimization procedure] The abstract asserts accurate recovery of planted structure on synthetic data, yet the optimization procedure used to minimize the joint MDL objective under spatial contiguity constraints is not specified. Because exact minimization over contiguous partitions is NP-hard, any practical algorithm must rely on heuristics (greedy merging, local search, or pruned dynamic programming). Without an explicit description of the search algorithm, initialization strategy, and convergence criteria (presumably in the Methods section), it is impossible to determine whether the reported synthetic recoveries are robust properties of the MDL criterion or artifacts of favorable planted cases and search details.
Authors: We agree that the optimization procedure requires more explicit description to evaluate robustness. The current manuscript provides only a high-level outline in the Methods section. In the revision we will expand this section with a complete specification of the algorithm, including initialization (each time series begins as its own region), the search strategy used to enforce contiguity while achieving log-linear scaling, and the precise convergence criterion based on MDL improvement. We will also add a sensitivity study on the synthetic data that varies random seeds and noise levels to demonstrate that the reported recoveries are not artifacts of particular search paths. revision: yes
-
Referee: [Empirical results] For the empirical air-quality and vegetation examples, the manuscript claims extraction of 'meaningful structural regularities' but provides no quantitative validation (e.g., held-out compression scores, comparison against baseline regionalizations, or stability across random restarts). Because the weakest modeling assumption is that MDL minimization under contiguity will automatically yield stable, interpretable regions, the absence of such checks leaves the real-data claims unsupported.
Authors: The referee correctly notes the lack of quantitative checks on the real-data examples. While the manuscript prioritizes interpretability, we will add the requested validations in the revised Results section: held-out compression scores on withheld portions of the air-quality and vegetation records, direct comparisons against standard baselines that either pre-specify the number of regions or use ad-hoc spatial penalties, and stability metrics across multiple random restarts. These additions will directly test whether MDL minimization produces stable, compressible partitions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper anchors its core method in the external minimum description length (MDL) principle from information theory, presenting a fully nonparametric framework that jointly infers contiguous spatial partitions and representative time series archetypes to compress the data. No load-bearing steps reduce by construction to self-defined quantities, fitted inputs renamed as predictions, or chains of self-citations; the derivation relies on standard MDL encoding costs and contiguity constraints without importing uniqueness theorems or ansatzes from the authors' prior work. Synthetic recovery and empirical results are offered as validation rather than definitional tautologies, keeping the central claim independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The minimum description length principle identifies the optimal spatial partition and temporal archetypes for compressing spatiotemporal data.
- domain assumption Spatial regions must be contiguous.
invented entities (1)
-
temporal archetypes (drivers)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In practice, the appropriate number of regions is rarely known in advance and may vary with temporal resolution, noise level, and time series length
or the spatial correlation parameter in CorClustST [32]. In practice, the appropriate number of regions is rarely known in advance and may vary with temporal resolution, noise level, and time series length. Fixing the number of regions a priori may therefore result in spurious mesoscopic structure in noisy data or obscure heterogeneity at small spatial sc...
2024
-
[2]
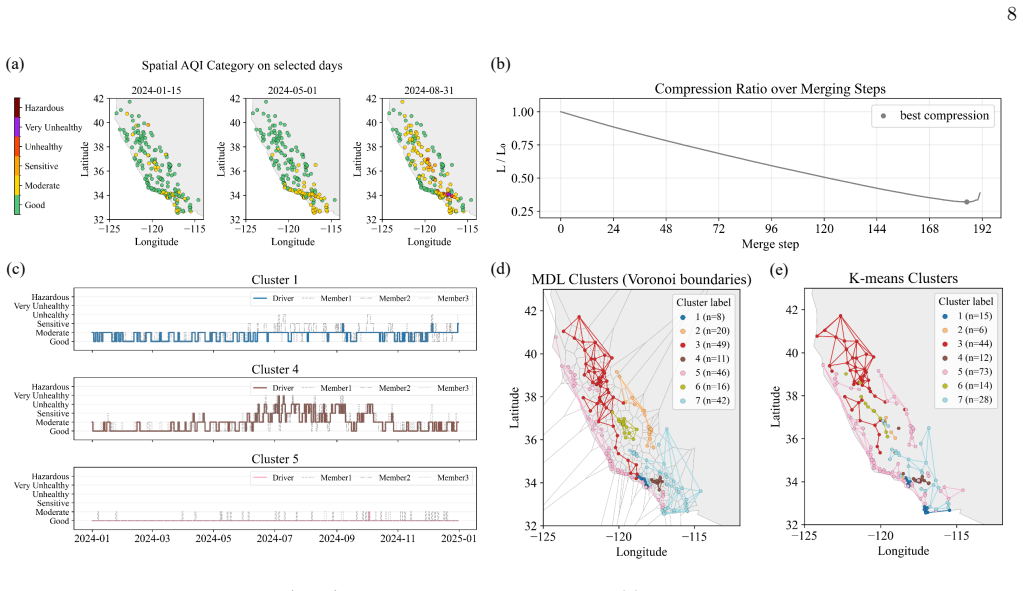
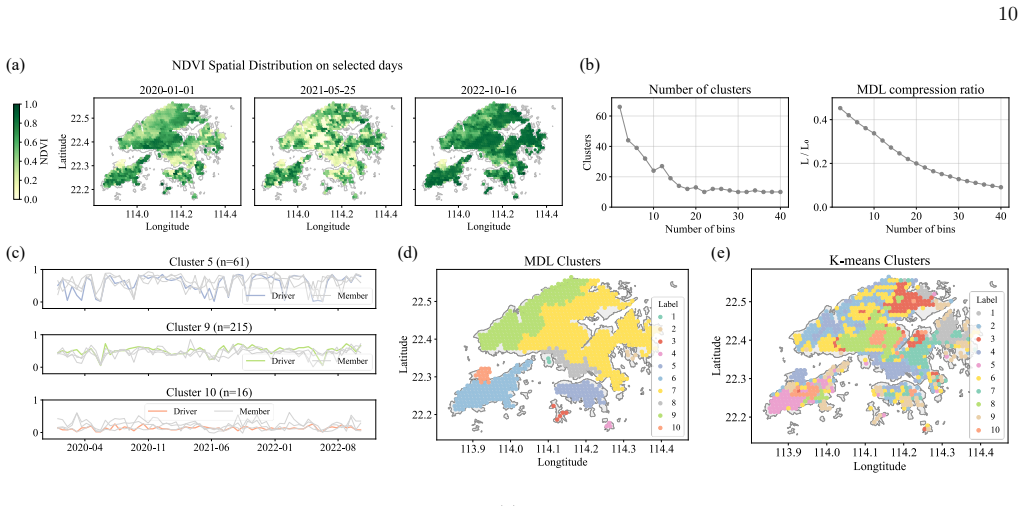
Together with the AQI example, these results demon- strate that the framework can extract interpretable spa- tial structure from both discrete and continuous environ- mental time series. IV. CONCLUSION In this work, we introduce an efficient nonparamet- ric framework for regionalizing spatial time series based on the minimum description length (MDL) princ...
2020
-
[3]
J. C. Duque, R. Ramos, and J. Suri˜ nach, Supervised re- gionalization methods: A survey.International Regional Science Review30(3), 195–220 (2007)
2007
-
[4]
Aydin, M
O. Aydin, M. V. Janikas, R. M. Assun¸ c˜ ao, and T.-H. Lee, A quantitative comparison of regionalization meth- ods.International Journal of Geographical Information Science35(11), 2287–2315 (2021)
2021
-
[5]
P. Qiu, L. Zhang, X. Wang, Y. Liu, S. Wang, S. Gong, and Y. Zhang, A new approach of air pollution region- alization based on geographically weighted variations for multi-pollutants in China.Science of the Total Environ- ment873, 162431 (2023)
2023
-
[6]
R. G. Fovell and M.-Y. C. Fovell, Climate zones of the conterminous United States defined using cluster analy- sis.Journal of Climate6(11), 2103–2135 (1993)
1993
-
[7]
Carvalho, P
M. Carvalho, P. Melo-Gon¸ calves, J. Teixeira, and A. Rocha, Regionalization of Europe based on ak-means cluster analysis of climate-change temperatures and pre- 11 cipitation.Physics and Chemistry of the Earth, Parts A/B/C94, 22–28 (2016)
2016
-
[8]
L. Mu, F. Wang, V. W. Chen, and X.-C. Wu, A place- oriented, mixed-level regionalization method for con- structing geographic areas in health data dissemination and analysis.Annals of the Association of American Ge- ographers105(1), 48–66 (2015)
2015
-
[9]
S. E. Spielman and D. C. Folch, Reducing uncertainty in the American Community Survey through data-driven regionalization.PLoS ONE10(2), e0115626 (2015)
2015
-
[10]
Morel-Balbi and A
S. Morel-Balbi and A. Kirkley, Bayesian regionalization of urban mobility networks.Physical Review Research6, 033307 (2024)
2024
-
[11]
R. M. Assun¸ c˜ ao, M. C. Neves, G. Cˆ amara, and C. da Costa Freitas, Efficient regionalization techniques for socio-economic geographical units using minimum spanning trees.International Journal of Geographical In- formation Science20(7), 797–811 (2006)
2006
-
[12]
W. Li, R. L. Church, and M. F. Goodchild, The p- compact-regions problem.Geographical Analysis46(3), 250–273 (2014)
2014
-
[13]
Zhang, X
H. Zhang, X. Zhou, G. Tang, L. Xiong, and K. Dong, Mining spatial patterns of food culture in China using restaurant POI data.Transactions in GIS25(2), 579– 601 (2021)
2021
-
[14]
Legendre and M
P. Legendre and M. J. Fortin, Spatial pattern and eco- logical analysis.Vegetatio80(2), 107–138 (1989)
1989
-
[15]
L. J. Wolf, Spatially–encouraged spectral clustering: a technique for blending map typologies and regionaliza- tion.International Journal of Geographical Information Science35(11), 2356–2373 (2021)
2021
-
[16]
A. Poorthuis, How to draw a neighborhood? The po- tential of big data, regionalization, and community de- tection for understanding the heterogeneous nature of urban neighborhoods.Geographical Analysis50(2), 182– 203 (2018)
2018
-
[17]
R. Wei, S. Rey, and E. Knaap, Efficient regionaliza- tion for spatially explicit neighborhood delineation.In- ternational Journal of Geographical Information Science 35(1), 135–151 (2021)
2021
-
[18]
Zhang, X
H. Zhang, X. Zhou, Y. Yang, H. Wang, X. Ye, and G. Tang, Advancing process-oriented geographical re- gionalization model.Annals of the American Association of Geographers114(10), 2388–2413 (2024)
2024
-
[19]
J. C. Duque, R. L. Church, and R. S. Middleton, The p- regions problem.Geographical Analysis43(1), 104–126 (2011)
2011
-
[20]
S. Openshaw, A geographical solution to scale and ag- gregation problems in region-building, partitioning and spatial modelling.Transactions of the Institute of British Geographers2(4), 459–472 (1977)
1977
-
[21]
Guo, Regionalization with dynamically constrained agglomerative clustering and partitioning (REDCAP)
D. Guo, Regionalization with dynamically constrained agglomerative clustering and partitioning (REDCAP). International Journal of Geographical Information Sci- ence22(7), 801–823 (2008)
2008
-
[22]
Shekhar, Z
S. Shekhar, Z. Jiang, R. Y. Ali, E. Eftelioglu, X. Tang, V. M. Gunturi, and X. Zhou, Spatiotemporal data min- ing: A computational perspective.ISPRS International Journal of Geo-Information4(4), 2306–2338 (2015)
2015
-
[23]
Aghabozorgi, A
S. Aghabozorgi, A. S. Shirkhorshidi, and T. Y. Wah, Time-series clustering–A decade review.Information Systems53, 16–38 (2015)
2015
-
[24]
Fortunato, Community detection in graphs.Physics Reports486(3-5), 75–174 (2010)
S. Fortunato, Community detection in graphs.Physics Reports486(3-5), 75–174 (2010)
2010
-
[25]
A. Ng, M. Jordan, and Y. Weiss, On spectral cluster- ing: Analysis and an algorithm. InAdvances in Neural Information Processing Systems, volume 14 (2001)
2001
-
[26]
G. Gan, C. Ma, and J. Wu,Data clustering: theory, al- gorithms, and applications. SIAM (2020)
2020
-
[27]
Shen and M
Y. Shen and M. Batty, Delineating the perceived func- tional regions of london from commuting flows.Environ- ment and Planning A: Economy and Space51(3), 547– 550 (2019)
2019
-
[28]
Kirkley, Information theoretic network approach to so- cioeconomic correlations.Physical Review Research2(4), 043212 (2020)
A. Kirkley, Information theoretic network approach to so- cioeconomic correlations.Physical Review Research2(4), 043212 (2020)
2020
-
[29]
Coppi, P
R. Coppi, P. D’Urso, and P. Giordani, A fuzzy cluster- ing model for multivariate spatial time series.Journal of Classification27(1), 54–88 (2010)
2010
-
[30]
Yuan, P.-N
S. Yuan, P.-N. Tan, K. S. Cheruvelil, S. M. Collins, and P. A. Soranno, Constrained spectral clustering for region- alization: Exploring the trade-off between spatial conti- guity and landscape homogeneity. In2015 IEEE Inter- national Conference on Data Science and Advanced An- alytics (DSAA), pp. 1–10, IEEE (2015)
2015
-
[31]
Birant and A
D. Birant and A. Kut, ST-DBSCAN: An algorithm for clustering spatial–temporal data.Data & Knowledge En- gineering60(1), 208–221 (2007)
2007
-
[32]
Shi and L
Z. Shi and L. S. Pun-Cheng, Spatiotemporal data cluster- ing: A survey of methods.ISPRS International Journal of Geo-Information8(3), 112 (2019)
2019
-
[33]
M. Y. Ansari, A. Ahmad, S. S. Khan, G. Bhushan, and Mainuddin, Spatiotemporal clustering: a review.Artifi- cial Intelligence Review53(4), 2381–2423 (2020)
2020
-
[34]
H¨ usch, B
M. H¨ usch, B. U. Schyska, and L. Von Bremen, Corclustst—Correlation-based clustering of big spatio- temporal datasets.Future Generation Computer Systems 110, 610–619 (2020)
2020
-
[35]
H. Wang, H. Zhang, H. Zhu, F. Zhao, S. Jiang, G. Tang, and L. Xiong, A multivariate hierarchical regionaliza- tion method to discovering spatiotemporal patterns.GI- Science & Remote Sensing60(1), 2176704 (2023)
2023
-
[36]
D. C. Folch and S. E. Spielman, Identifying regions based on flexible user-defined constraints.International Jour- nal of Geographical Information Science28(1), 164–184 (2014)
2014
-
[37]
Rissanen, Modeling by shortest data description.Au- tomatica14(5), 465–471 (1978)
J. Rissanen, Modeling by shortest data description.Au- tomatica14(5), 465–471 (1978)
1978
-
[38]
P. D. Gr¨ unwald,The minimum description length prin- ciple. MIT press (2007)
2007
-
[39]
T. Li, S. Ma, and M. Ogihara, Entropy-based criterion in categorical clustering. InProceedings of the Twenty-First International Conference on Machine Learning, p. 68 (2004)
2004
-
[40]
Georgieva, K
O. Georgieva, K. Tschumitschew, and F. Klawonn, Clus- ter validity measures based on the minimum descrip- tion length principle. InInternational Conference on Knowledge-Based and Intelligent Information and Engi- neering Systems, pp. 82–89, Springer (2011)
2011
-
[41]
Q. Lu, R. Lund, and T. C. M. Lee, An MDL approach to the climate segmentation problem.The Annals of Applied Statistics4(1), 299–319 (2010)
2010
-
[42]
Rakthanmanon, E
T. Rakthanmanon, E. J. Keogh, S. Lonardi, and S. Evans, MDL-based time series clustering.Knowledge and Information Systems33(2), 371–399 (2012)
2012
-
[43]
Papadimitriou, A
S. Papadimitriou, A. Gionis, P. Tsaparas, R. A. Vaisa- nen, H. Mannila, and C. Faloutsos, Parameter-free spa- tial data mining using MDL. InFifth IEEE International 12 Conference on Data Mining (ICDM’05), pp. 8–pp, IEEE (2005)
2005
-
[44]
L. Yang, M. Baratchi, and M. van Leeuwen, Unsuper- vised discretization by two-dimensional MDL-based his- togram.Machine Learning112(7), 2397–2431 (2023)
2023
-
[45]
L. V. Lakshmanan, R. T. Ng, C. X. Wang, X. Zhou, and T. J. Johnson, The generalized MDL approach for sum- marization. InVLDB’02: Proceedings of the 28th Inter- national Conference on Very Large Databases, pp. 766– 777, Elsevier (2002)
2002
-
[46]
T. P. Peixoto, Bayesian stochastic blockmodeling.Ad- vances in Network Clustering and Blockmodelingpp. 289–332 (2019)
2019
-
[47]
R. J. Gallagher, J.-G. Young, and B. F. Welles, A clar- ified typology of core-periphery structure in networks. Science Advances7(12), eabc9800 (2021)
2021
-
[48]
Kirkley, Identifying hubs in directed networks.Phys- ical Review E109(3), 034310 (2024)
A. Kirkley, Identifying hubs in directed networks.Phys- ical Review E109(3), 034310 (2024)
2024
-
[49]
T. P. Peixoto, Ordered community detection in directed networks.Physical Review E106(2), 024305 (2022)
2022
-
[50]
Morel-Balbi and A
S. Morel-Balbi and A. Kirkley, Estimation of partial rankings from sparse, noisy comparisons.Communica- tions Physics9, 30 (2026)
2026
-
[51]
Kirkley, Fast nonparametric inference of network backbones for weighted graph sparsification.Physical Re- view X15(3), 031013 (2025)
A. Kirkley, Fast nonparametric inference of network backbones for weighted graph sparsification.Physical Re- view X15(3), 031013 (2025)
2025
-
[52]
Kirkley, Spatial regionalization based on optimal in- formation compression.Communications Physics5(1), 249 (2022)
A. Kirkley, Spatial regionalization based on optimal in- formation compression.Communications Physics5(1), 249 (2022)
2022
-
[53]
Coupette, S
C. Coupette, S. Dalleiger, and J. Vreeken, Differen- tially describing groups of graphs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 3959–3967 (2022)
2022
-
[54]
Kirkley, A
A. Kirkley, A. Rojas, M. Rosvall, and J.-G. Young, Com- pressing network populations with modal networks reveal structural diversity.Communications Physics6(1), 148 (2023)
2023
-
[55]
Kirkley and M
A. Kirkley and M. E. Newman, Representative commu- nity divisions of networks.Communications Physics5(1), 40 (2022)
2022
-
[56]
T. P. Peixoto, Revealing consensus and dissensus between network partitions.Physical Review X11(2), 021003 (2021)
2021
-
[57]
D. J. MacKay,Information theory, inference and learning algorithms. Cambridge University Press (2003)
2003
-
[58]
T. P. Peixoto, Nonparametric Bayesian inference of the microcanonical stochastic block model.Physical Review E95(1), 012317 (2017)
2017
-
[59]
Kirkley, Transfer entropy for finite data.Physical Re- view E112, L052304 (2025)
A. Kirkley, Transfer entropy for finite data.Physical Re- view E112, L052304 (2025)
2025
-
[60]
Cˆ ome, Bayesian contiguity constrained clustering: spanning trees and dendrograms.Statistics and Comput- ing34(2), 64 (2024)
E. Cˆ ome, Bayesian contiguity constrained clustering: spanning trees and dendrograms.Statistics and Comput- ing34(2), 64 (2024)
2024
-
[61]
Jerdee, A
M. Jerdee, A. Kirkley, and M. Newman, Mutual infor- mation and the encoding of contingency tables.Physical Review E110(6), 064306 (2024)
2024
-
[62]
N. X. Vinh, J. Epps, and J. Bailey, Information theoretic measures for clusterings comparison: Variants, proper- ties, normalization and correction for chance.Journal of Machine Learning Research11(95), 2837–2854 (2010)
2010
-
[63]
De Loera, J
J. De Loera, J. Rambau, and F. Santos,Triangulations: Structures for Algorithms and Applications. Springer Sci- ence & Business Media (2010)
2010
-
[64]
S. A. Horn and P. K. Dasgupta, The Air Quality Index (AQI) in historical and analytical perspective a tutorial review.Talanta267, 125260 (2024)
2024
-
[65]
Kanchan, A. K. Gorai, and P. Goyal, A review on air quality indexing system.Asian Journal of Atmospheric Environment9(2), 101–113 (2015)
2015
-
[66]
Lepot, J.-B
M. Lepot, J.-B. Aubin, and F. H. Clemens, Interpola- tion in time series: An introductive overview of existing methods, their performance criteria and uncertainty as- sessment.Water9(10), 796 (2017)
2017
-
[67]
Bedsworth, Air quality planning in California’s chang- ing climate.Climatic Change111(1), 101–118 (2012)
L. Bedsworth, Air quality planning in California’s chang- ing climate.Climatic Change111(1), 101–118 (2012)
2012
-
[68]
Otero, H
N. Otero, H. W. Rust, and T. Butler, Temperature de- pendence of tropospheric ozone under NO x reductions over Germany.Atmospheric Environment253, 118334 (2021)
2021
-
[69]
Pettorelli, J
N. Pettorelli, J. O. Vik, A. Mysterud, J.-M. Gaillard, C. J. Tucker, and N. C. Stenseth, Using the satellite- derived NDVI to assess ecological responses to environ- mental change.Trends in Ecology & Evolution20(9), 503–510 (2005)
2005
-
[70]
Fung and W.-L
T. Fung and W.-L. Siu, A study of green space and its changes in Hong Kong using NDVI.Geographical and En- vironmental Modelling5(2), 111–122 (2001)
2001
-
[71]
Belhadi, Y
A. Belhadi, Y. Djenouri, K. Nørv˚ ag, H. Ramampiaro, F. Masseglia, and J. C.-W. Lin, Space–time series clus- tering: Algorithms, taxonomy, and case study on urban smart cities.Engineering Applications of Artificial Intel- ligence95, 103857 (2020). 13 Appendix A: Local optimality of majority vote drivers We want to prove that the majority vote estimator ζt...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.