Recognition: unknown
Piper: Efficient Large-Scale MoE Training via Resource Modeling and Pipelined Hybrid Parallelism
Pith reviewed 2026-05-08 16:59 UTC · model grok-4.3
The pith
Piper uses a mathematical resource model to select pipelined hybrid parallelism strategies that raise training efficiency for large Mixture-of-Experts models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a verified mathematical model of resource demands lets Piper identify and apply efficient pipelined hybrid parallelization for MoE training on HPC platforms, producing concrete gains in model FLOPS utilization and communication performance over prior methods.
What carries the argument
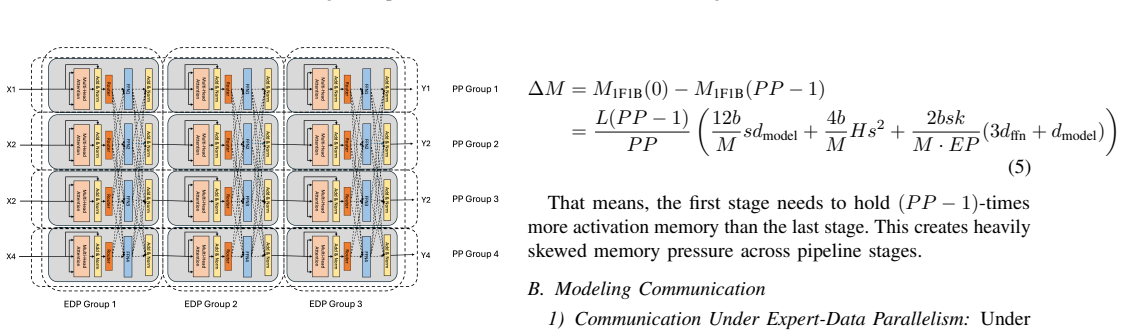
The mathematical resource model that calculates memory, compute, and communication needs for each MoE configuration and parallel scheme, then guides the choice of pipeline schedules and a custom all-to-all primitive.
If this is right
- Larger MoE models can be trained on the same number of GPUs without proportional increases in wall-clock time.
- Training runs finish with less idle GPU time because compute and communication stages overlap more effectively.
- HPC operators can allocate fewer nodes for equivalent model scale by following the model's recommendations.
- The same modeling step applies to other sparse architectures that rely on expert routing and all-to-all traffic.
Where Pith is reading between the lines
- The resource-modeling step could be turned into an online tuner that adjusts parallelism mid-training when network conditions change.
- The custom all-to-all routine may speed up other collective patterns that appear in non-MoE large-scale training.
- Extending the model to include power and memory-bandwidth limits would let it optimize for energy cost as well as speed.
Load-bearing premise
The mathematical model accurately predicts the real performance bottlenecks that appear when MoE models run on the target HPC hardware.
What would settle it
Measure actual MFU, communication bandwidth, and training time for the same MoE model and hardware setup once with Piper's chosen schedule and once without it; the gap should match the model's predicted improvement.
Figures







read the original abstract
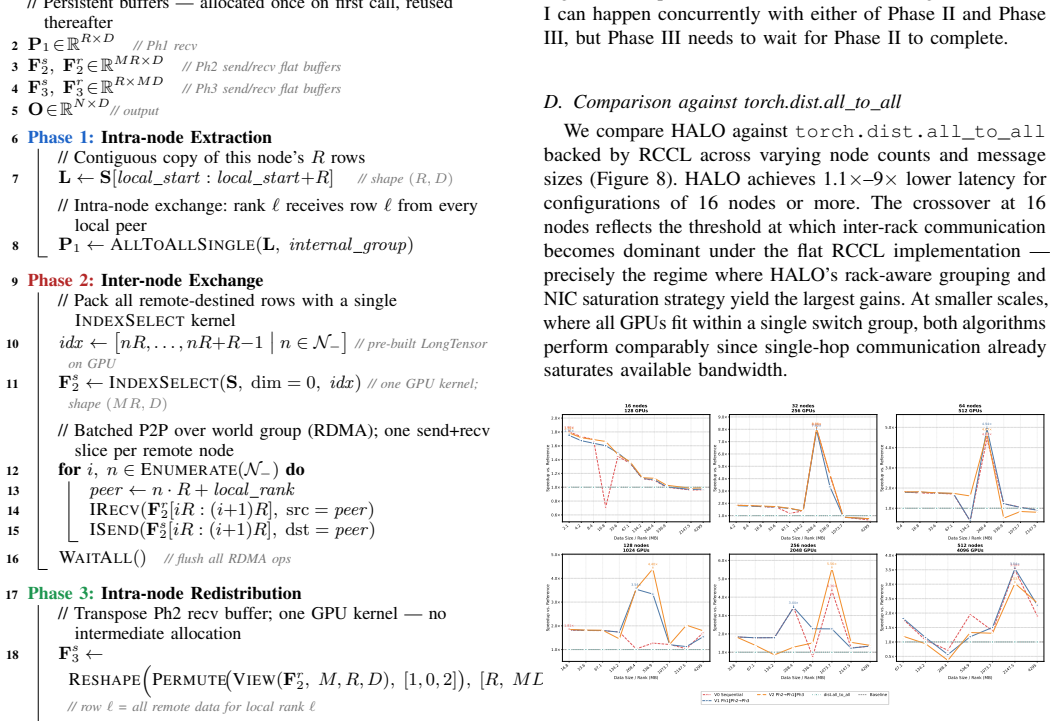
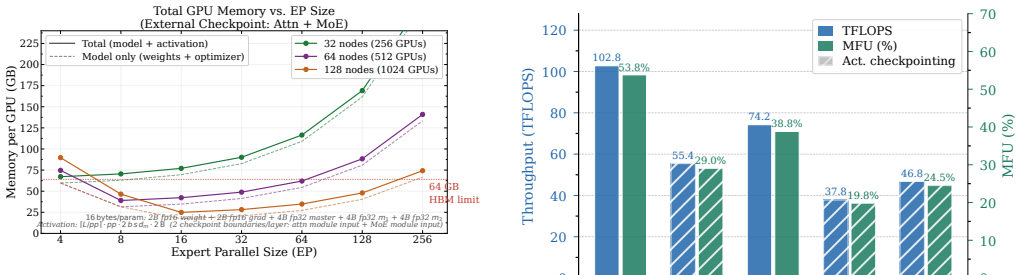
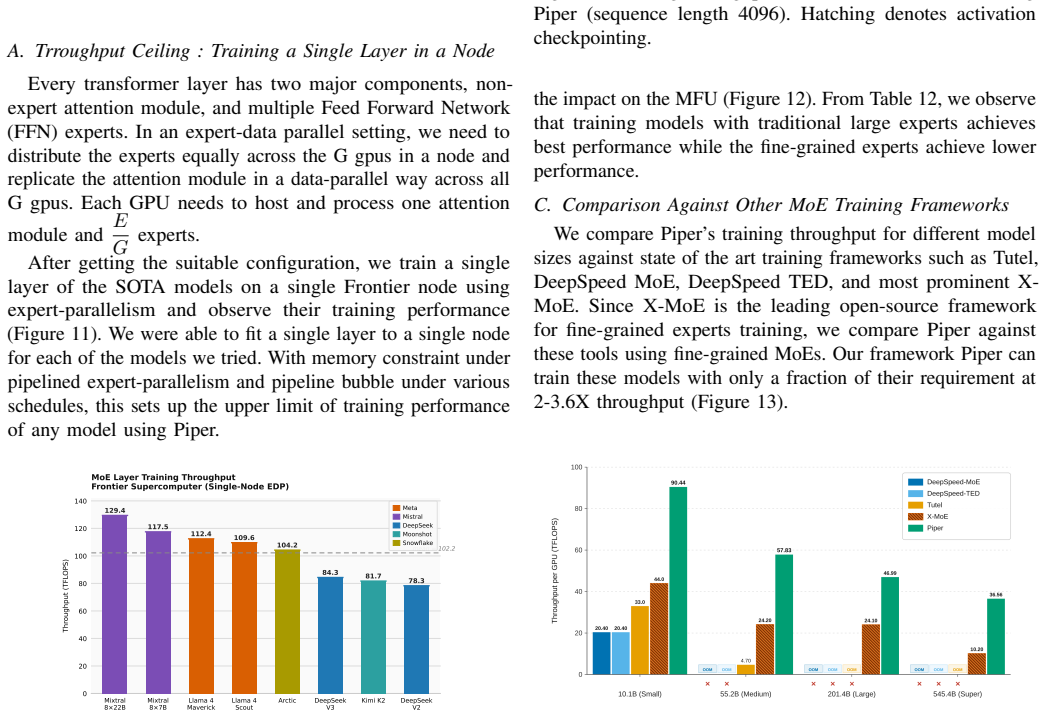
Frontier models increasingly adopt Mixture-of-Experts (MoE) architectures to achieve large-model performance at reduced cost. However, training MoE models on HPC platforms is hindered by large memory footprints, frequent large-scale communication across heterogeneous networks, and severe workload imbalance. To characterize these challenges, we develop a mathematical model that quantifies memory, compute, and communication requirements for MoE configurations under various parallelization schemes, verified through micro-benchmarking, code instrumentation, and hardware profiling. Our analysis identifies performance bottlenecks: all-to-all latency at scale from expert parallelism, insufficient compute-communication overlap, low GPU utilization from imbalanced skinny GEMMs, and the absence of platform-aware hybrid parallelization strategies. To address these, we introduce Piper, a framework that leverages resource modeling to identify efficient training strategies for MoE models on target HPC platforms, applying pipeline parallelism with optimized schedules. Piper achieves 2-3.5X higher MFU than state-of-the-art frameworks such as X-MoE, and a novel all-to-all algorithm delivers 1.2-9X bandwidth over vendor implementation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a mathematical model quantifying memory, compute, and communication requirements for MoE configurations under various parallelization schemes, verified through micro-benchmarking, code instrumentation, and hardware profiling. Analysis identifies bottlenecks including all-to-all latency from expert parallelism, insufficient compute-communication overlap, imbalanced skinny GEMMs, and lack of platform-aware strategies. The authors introduce Piper, a framework that uses the model to select efficient pipelined hybrid parallelism schedules, claiming 2-3.5X higher MFU than X-MoE and a novel all-to-all algorithm delivering 1.2-9X bandwidth over vendor implementations.
Significance. If the resource model correctly predicts end-to-end bottlenecks and the hybrid schedules generalize, the work would advance practical large-scale MoE training on HPC platforms by improving utilization and communication efficiency. The analytical modeling approach combined with a concrete framework is a strength, as is the focus on verifiable performance factors rather than purely empirical tuning.
major comments (1)
- [Abstract] Abstract: The verification of the mathematical model is limited to micro-benchmarking, code instrumentation, and hardware profiling of isolated components. This does not directly validate predictive accuracy for dynamic interactions (e.g., network contention under concurrent expert parallelism plus pipeline stages or evolving load imbalance) that are central to selecting the hybrid schedules claimed to deliver 2-3.5X MFU gains over X-MoE. Full-scale end-to-end training runs with error analysis are needed to confirm the model identifies real bottlenecks.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's significance and for the constructive major comment. We address it point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The verification of the mathematical model is limited to micro-benchmarking, code instrumentation, and hardware profiling of isolated components. This does not directly validate predictive accuracy for dynamic interactions (e.g., network contention under concurrent expert parallelism plus pipeline stages or evolving load imbalance) that are central to selecting the hybrid schedules claimed to deliver 2-3.5X MFU gains over X-MoE. Full-scale end-to-end training runs with error analysis are needed to confirm the model identifies real bottlenecks.
Authors: We agree that direct validation of the model's predictive accuracy under concurrent dynamic conditions (network contention, load imbalance across pipeline stages) would strengthen the claims. Section 4 presents verification of the individual resource components via micro-benchmarks, instrumentation, and profiling, while Section 6 reports that the model-selected hybrid schedules produce the observed 2-3.5X MFU gains over X-MoE. This provides indirect evidence of the model's utility for schedule selection. To address the concern directly, we will add full-scale end-to-end training runs with quantitative error analysis (predicted vs. measured memory, compute, and communication metrics) in the revised manuscript. revision: yes
Circularity Check
No significant circularity; model verified independently and gains measured empirically
full rationale
The paper first derives a mathematical model quantifying memory, compute, and communication for MoE under parallel schemes, then verifies that model via separate micro-benchmarking, code instrumentation, and hardware profiling. Bottleneck analysis and Piper's hybrid-parallelism schedules follow from the verified model. Reported 2-3.5X MFU and 1.2-9X bandwidth improvements are direct empirical measurements against baselines, not model outputs or fitted parameters. No self-definitional equations, renamed fits, or load-bearing self-citations appear; the chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” arXiv preprint arXiv:2001.08361, 2020. [Online]. Available: https://doi.org/10.48550/arXiv.2001.08361
-
[2]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in Neural Information Processing Systems, vol. 30, 2017. [Online]. Available: https://doi.org/10.48550/arXiv.1706.03762
work page internal anchor Pith review doi:10.48550/arxiv.1706.03762 2017
-
[3]
Efficient large-scale language model training on GPU clusters using Megatron-LM,
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on GPU clusters using Megatron-LM,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC),
-
[4]
Available: https://doi.org/10.1145/3458817.3476209
[Online]. Available: https://doi.org/10.1145/3458817.3476209
-
[5]
Generalized Slow Roll for Tensors
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “ZeRO: Memory optimizations toward training trillion parameter models,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2020. [Online]. Available: https://doi.org/10.1109/SC41405.2020.00024
-
[6]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely- gated mixture-of-experts layer,” in International Conference on Learning Representations (ICLR), 2017. [Online]. Available: https: //doi.org/10.48550/arXiv.1701.06538
work page internal anchor Pith review doi:10.48550/arxiv.1701.06538 2017
-
[7]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity,” Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2101.03961
work page internal anchor Pith review doi:10.48550/arxiv.2101.03961 2022
-
[8]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, D. S. Chaplot, D. de las Casas, E. B. Hanna, F. Bressand et al., “Mixtral of experts,” arXiv preprint arXiv:2401.04088, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2401.04088
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning,” arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
[Online]. Available: https://doi.org/10.48550/arXiv.2501.12948
-
[11]
Qwen1.5-MoE: Matching 7B model performance with 1/3 activated parameters,
Qwen Team, “Qwen1.5-MoE: Matching 7B model performance with 1/3 activated parameters,” 2024. [Online]. Available: https: //qwenlm.github.io/blog/qwen-moe/
2024
-
[12]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, “Kimi k1.5: Scaling reinforcement learning with LLMs,” arXiv preprint arXiv:2501.12599, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2501.12599
work page internal anchor Pith review doi:10.48550/arxiv.2501.12599 2025
-
[13]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
D. Lepikhin, H. Lee, Y . Xu, D. Chen, O. Firat, Y . Huang, M. Krikun, N. Shazeer, and Z. Chen, “GShard: Scaling giant models with conditional computation and automatic sharding,” arXiv preprint arXiv:2006.16668,
work page internal anchor Pith review arXiv 2006
-
[14]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
[Online]. Available: https://doi.org/10.48550/arXiv.2006.16668
work page internal anchor Pith review doi:10.48550/arxiv.2006.16668 2006
-
[15]
DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale,
S. Rajbhandari, C. Li, Z. Yao, M. Zhang, R. Y . Aminabadi, A. A. Awan, J. Rasley, and Y . He, “DeepSpeed-MoE: Advancing mixture-of-experts inference and training to power next-generation AI scale,” in Proceedings of the 39th International Conference on Machine Learning (ICML),
-
[16]
[Online]. Available: https://doi.org/10.48550/arXiv.2201.05596
-
[17]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
D. Dai, C. Deng, C. Zhao, R. X. Xu, H. Gao, D. Chen, J. Li, W. Zeng, X. Yu, Y . Wu et al., “DeepSeekMoE: Towards ultimate expert specialization in mixture-of-experts language models,” arXiv preprint arXiv:2401.06066, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2401.06066
work page internal anchor Pith review doi:10.48550/arxiv.2401.06066 2024
-
[18]
X-MoE: Scalable and finetunable sparse mixture-of-experts transformer for on-device inference,
Z. Chi, L. Dong, S. Ma, R. Pang, S. Huang, X.-L. Mao, and F. Wei, “X-MoE: Scalable and finetunable sparse mixture-of-experts transformer for on-device inference,” arXiv preprint arXiv:???, 2024, wARNING: original arXiv ID 2405.13089 is incorrect and belongs to an unrelated paper. Correct ID needs to be verified
-
[19]
DeepSpeed tensor, expert, and data parallelism,
Microsoft DeepSpeed Team, “DeepSpeed tensor, expert, and data parallelism,” Microsoft, Tech. Rep., 2022. [Online]. Available: https://www.deepspeed.ai/tutorials/mixture-of-experts-inference/
2022
-
[20]
Frontier: Exploring exascale,
S. Atchley, C. Zimmer, J. Lange, B. Grodowitz, S. Oral et al., “Frontier: Exploring exascale,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC),
-
[21]
Available: https://doi.org/10.1145/3581784.3607089
[Online]. Available: https://doi.org/10.1145/3581784.3607089
-
[22]
Qwen Team, “Qwen3 technical report,”arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[23]
[Online]. Available: https://doi.org/10.48550/arXiv.2505.09388
-
[24]
Kimi K2: Open Agentic Intelligence
Kimi Team, “Kimi k2: Open agentic intelligence,” arXiv preprint arXiv:2507.20534, 2025. [Online]. Available: https://doi.org/10.48550/ arXiv.2507.20534
work page internal anchor Pith review arXiv 2025
-
[25]
Efficient large-scale language model training on GPU clusters using Megatron-LM,
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikantiet al., “Efficient large-scale language model training on GPU clusters using Megatron-LM,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2021. [Online]. Available: https://doi.org/10.1145/ 3458817.3476209
-
[26]
PipeDream: Generalized pipeline parallelism for DNN training,
D. Narayanan, A. Harlap, A. Phanishayee, V . Seshadri, N. R. Devanur, G. R. Ganger, P. B. Gibbons, and M. Zaharia, “PipeDream: Generalized pipeline parallelism for DNN training,” in Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP), 2019. [Online]. Available: https://doi.org/10.1145/3341301.3359646
-
[27]
Memory-efficient pipeline-parallel DNN training,
D. Narayanan, A. Phanishayee, K. Shi, X. Chen, and M. Zaharia, “Memory-efficient pipeline-parallel DNN training,” in Proceedings of the 38th International Conference on Machine Learning (ICML), 2021. [Online]. Available: https://doi.org/10.48550/arXiv.2006.09503
-
[28]
Tu- tel: Adaptive mixture-of-experts at scale
C. Hwang, W. Cui, Y . Xiong, Z. Yang, Z. Liu, H. Hu, Z. Wang, R. Salas, J. Jose, P. Ram et al., “Tutel: Adaptive mixture-of-experts at scale,” in Proceedings of Machine Learning and Systems (MLSys), vol. 5, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2206.03382
-
[29]
Y . Huang, Y . Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wu, and Z. Chen, “GPipe: Efficient training of giant neural networks using pipeline parallelism,” in Advances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019. [Online]. Available: https://doi.org/10.48550/arXiv.1811.06965
-
[30]
Zero bubble pipeline parallelism.arXiv preprint arXiv:2401.10241, 2023
P. Qi, X. Wan, G. Huang, and M. Lin, “Zero bubble pipeline parallelism,” arXiv preprint arXiv:2401.10241, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2401.10241
-
[31]
Mixture-of-experts with expert choice routing,
Y . Zhou, T. Lei, H. Liu, N. Du, Y . Huang, V . Zhao, A. M. Dai, Z. Chen, Q. V . Le, and J. Laudon, “Mixture-of-experts with expert choice routing,” in Advances in Neural Information Processing Systems (NeurIPS),
-
[32]
arXiv preprint arXiv:2202.09368 , year=
[Online]. Available: https://doi.org/10.48550/arXiv.2202.09368
-
[33]
NVIDIA Collective Communications Library (NCCL),
NVIDIA Corporation, “NVIDIA Collective Communications Library (NCCL),” 2023. [Online]. Available: https://developer.nvidia.com/nccl
2023
-
[34]
ROCm Collective Communications Library (RCCL),
AMD Inc., “ROCm Collective Communications Library (RCCL),” 2023. [Online]. Available: https://github.com/ROCm/rccl
2023
-
[35]
FasterMoE: Modeling and optimizing training of large-scale dynamic pre- trained models,
J. He, J. Zhai, T. Antunes, H. Wang, F. Luo, S. Shi, and Q. Li, “FasterMoE: Modeling and optimizing training of large-scale dynamic pre- trained models,” in Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2022. [Online]. Available: https://doi.org/10.1145/3503221.3508418
-
[36]
arXiv preprint arXiv:2203.14685 , year=
X. Nie, P. Zhao, X. Miao, T. Zhao, and B. Cui, “HetuMoE: An efficient trillion-scale mixture-of-expert distributed training system,” arXiv preprint arXiv:2203.14685, 2022. [Online]. Available: https: //doi.org/10.48550/arXiv.2203.14685
-
[37]
Technology-driven, highly-scalable dragonfly topology,
J. Kim, W. J. Dally, S. Scott, and D. Abts, “Technology-driven, highly-scalable dragonfly topology,” in Proceedings of the 35th Annual International Symposium on Computer Architecture (ISCA), 2008. [Online]. Available: https://doi.org/10.1109/ISCA.2008.19
-
[38]
Roofline: an in- sightful visual performance model for multicore architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: An insightful visual performance model for multicore architectures,” Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009. [Online]. Available: https://doi.org/10.1145/1498765.1498785
-
[39]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e, “FlashAttention: Fast and memory-efficient exact attention with IO-awareness,” in Advances in Neural Information Processing Systems (NeurIPS), 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2205.14135
work page internal anchor Pith review doi:10.48550/arxiv.2205.14135 2022
-
[40]
Reducing activation recomputation in large transformer models, 2022
V . A. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,” in Proceedings of Machine Learning and Systems (MLSys), 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2205.05198
-
[41]
PaLM: Scaling Language Modeling with Pathways
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts et al., “PaLM: Scaling language modeling with pathways,” Journal of Machine Learning Research, vol. 24, no. 240, pp. 1–113, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2204.02311
work page internal anchor Pith review doi:10.48550/arxiv.2204.02311 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.