Recognition: no theorem link
LineRides: Line-Guided Reinforcement Learning for Bicycle Robot Stunts
Pith reviewed 2026-05-11 02:11 UTC · model grok-4.3
The pith
A line-guided reinforcement learning method trains a bicycle robot to execute five distinct stunts on command using only a spatial guideline and sparse key orientations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
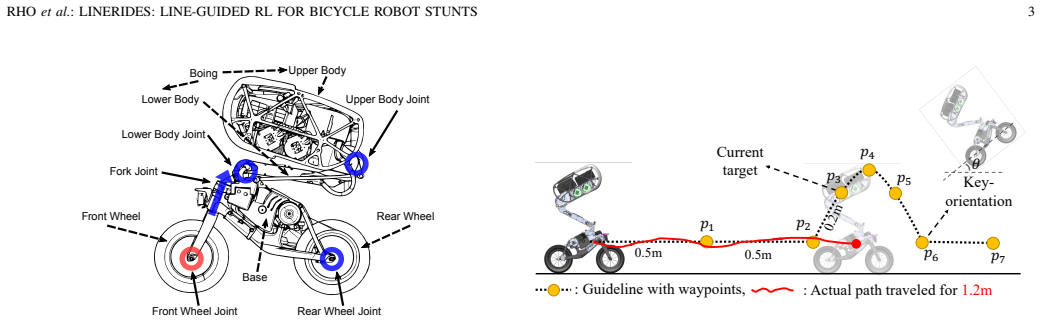
LineRides is a line-guided learning framework that enables a bicycle robot to acquire diverse, commandable stunt behaviors from a user-provided spatial guideline and sparse key-orientations, without demonstrations or explicit timing. It handles physically infeasible guidelines via a tracking margin that permits controlled deviation, resolves temporal ambiguity by measuring progress via traveled distance along the guideline, and disambiguates motion details through position- and sequence-based key-orientations.
What carries the argument
The line-guided reinforcement learning framework that supplies a spatial guideline, applies a tracking margin for deviation, measures progress by distance along the line, and uses position- and sequence-based key-orientations to specify stunt details.
If this is right
- The trained policy supports seamless transitions between normal driving and stunt execution.
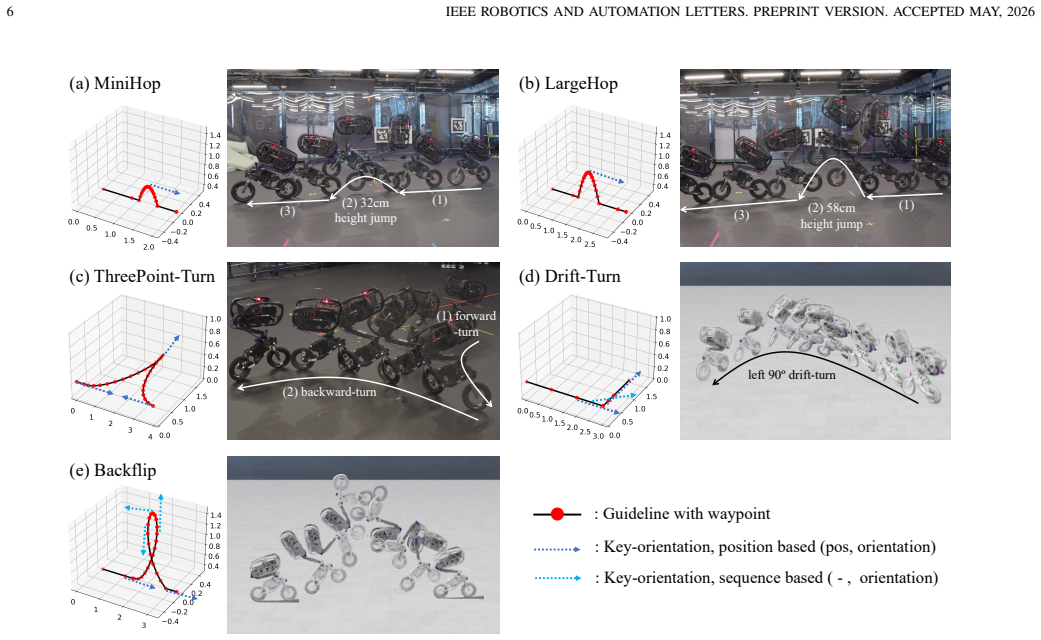
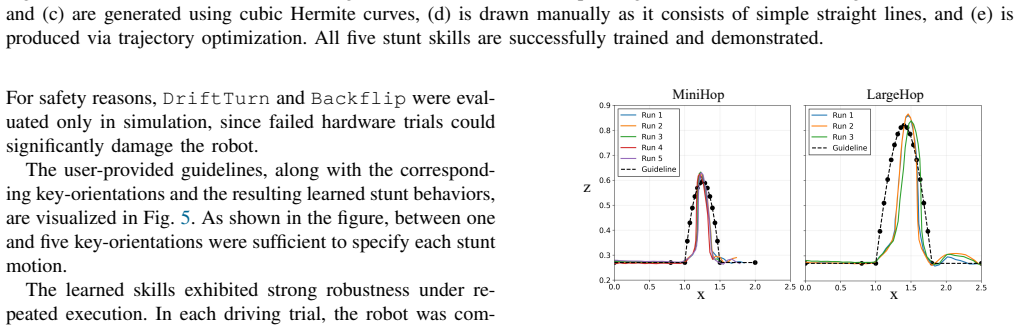
- Five specific stunts become available on command: MiniHop, LargeHop, ThreePointTurn, Backflip, and DriftTurn.
- The approach works for a custom bicycle robot without requiring reference motion data.
- Training succeeds using only geometric guidelines and minimal orientation cues rather than full trajectories.
Where Pith is reading between the lines
- This guideline approach could reduce dependence on motion-capture systems when training other agile robots for maneuvers in unstructured settings.
- Similar distance-based progress and margin techniques might apply to navigation or manipulation tasks where exact timing is hard to specify.
- Real-world hardware tests on varying surfaces would reveal how well the learned policies transfer beyond simulation.
Load-bearing premise
That a user-provided spatial guideline plus sparse key-orientations, combined with a tracking margin and distance-based progress, are sufficient to disambiguate and learn physically valid stunt behaviors without demonstrations or explicit timing.
What would settle it
Commanding the robot to perform all five stunts in sequence and observing whether it completes each without falling, excessive deviation, or loss of control would directly test the claim.
Figures






read the original abstract
Designing reward functions for agile robotic maneuvers in reinforcement learning remains difficult, and demonstration-based approaches often require reference motions that are unavailable for novel platforms or extreme stunts. We present LineRides, a line-guided learning framework that enables a custom bicycle robot to acquire diverse, commandable stunt behaviors from a user-provided spatial guideline and sparse key-orientations, without demonstrations or explicit timing. LineRides handles physically infeasible guidelines using a tracking margin that permits controlled deviation, resolves temporal ambiguity by measuring progress via traveled distance along the guideline, and disambiguates motion details through position- and sequence-based key-orientations. We evaluate LineRides on the Ultra Mobility Vehicle (UMV) and show that the policy trained with our methods supports seamless transitions between normal driving and stunt execution, enabling five distinct stunts on command: MiniHop, LargeHop, ThreePointTurn, Backflip, and DriftTurn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LineRides, a line-guided RL framework for a custom bicycle robot (UMV) that learns five commandable stunts (MiniHop, LargeHop, ThreePointTurn, Backflip, DriftTurn) from a user-provided spatial guideline plus sparse key-orientations. It uses a tracking margin to handle infeasible lines and distance-based progress along the line to resolve temporal ambiguity, claiming this enables seamless transitions between normal driving and stunts without demonstrations or explicit timing.
Significance. If the empirical claims are substantiated, the framework would offer a practical way to specify and learn agile maneuvers on novel platforms with minimal prior data, potentially reducing the demonstration burden in RL for robotics.
major comments (2)
- [Evaluation] Evaluation section: the abstract and results claim successful execution of five distinct stunts with seamless transitions, yet no quantitative metrics (success rates, episode returns, timing statistics), baselines, or ablation studies are reported. This is load-bearing for the central empirical claim.
- [Method] Method section (reward formulation): the combination of a tracking margin, distance-based progress, and sparse position/sequence key-orientations is asserted to disambiguate high-dynamic behaviors such as Backflip versus DriftTurn, but no analysis or sensitivity study shows that orientation cues alone suffice to resolve timing, contact forces, and velocity profiles under the permitted deviation.
minor comments (1)
- [Abstract] The abstract refers to 'Ultra Mobility Vehicle (UMV)' without an early reference or figure showing the platform kinematics or sensor suite.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important gaps in empirical support and methodological justification. We address each point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the abstract and results claim successful execution of five distinct stunts with seamless transitions, yet no quantitative metrics (success rates, episode returns, timing statistics), baselines, or ablation studies are reported. This is load-bearing for the central empirical claim.
Authors: We agree that the absence of quantitative metrics, baselines, and ablations weakens the central empirical claim. The original submission relied primarily on qualitative video demonstrations. In the revised manuscript we will add success rates (percentage of successful stunt executions over 50 independent trials per stunt), mean episode returns, timing statistics (duration from command to completion), and comparisons against two baselines: (i) a standard sparse-reward RL formulation without line guidance and (ii) an ablation that removes the tracking margin. These results will be reported in a new quantitative evaluation subsection. revision: yes
-
Referee: [Method] Method section (reward formulation): the combination of a tracking margin, distance-based progress, and sparse position/sequence key-orientations is asserted to disambiguate high-dynamic behaviors such as Backflip versus DriftTurn, but no analysis or sensitivity study shows that orientation cues alone suffice to resolve timing, contact forces, and velocity profiles under the permitted deviation.
Authors: The referee correctly notes that we provide no sensitivity analysis or ablation demonstrating that the sparse key-orientations are sufficient to resolve timing and contact dynamics. We will add a short analysis subsection that (a) shows failure modes when key-orientations are removed (e.g., policy collapses to a single behavior) and (b) provides qualitative trajectory comparisons illustrating how the combination of distance-based progress and orientation cues produces distinct velocity and contact profiles for Backflip versus DriftTurn. A full quantitative sensitivity study on contact forces would require additional instrumentation that is not currently available; we will therefore limit the added material to the feasible analysis described above. revision: partial
Circularity Check
No circularity: empirical RL framework with no self-referential derivations
full rationale
The paper describes an empirical line-guided RL method for bicycle stunts, relying on user-provided spatial guidelines, sparse key-orientations, a tracking margin, and distance-based progress to shape rewards. No equations, predictions, or uniqueness theorems are presented that reduce to their own inputs by construction. The approach is evaluated through physical experiments on the UMV platform, with claims of five distinct stunts supported by observed policy behavior rather than fitted parameters or self-citations. The derivation chain consists of design choices for reward shaping and training, which remain independent of the target results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A user-provided spatial guideline combined with sparse key-orientations can disambiguate and enable learning of diverse stunt behaviors.
Reference graph
Works this paper leans on
-
[1]
Z. Zhuang, Z. Fu, J. Wang, C. G. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao, “Robot parkour learning,” inConference on Robot Learning. PMLR, 2023, pp. 73–92
work page 2023
-
[2]
Robust and versatile bipedal jumping control through reinforcement learning,
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Robust and versatile bipedal jumping control through reinforcement learning,” inRobotics science and systems. RSS, 2023
work page 2023
-
[3]
Extreme parkour with legged robots,
X. Cheng, K. Shi, A. Agarwal, and D. Pathak, “Extreme parkour with legged robots,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 11 443–11 450
work page 2024
-
[4]
Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne, “Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,”ACM Transactions On Graphics (TOG), vol. 37, no. 4, pp. 1–14, 2018
work page 2018
-
[5]
Learning Agile Robotic Locomotion Skills by Imitating Animals
X. B. Peng, E. Coumans, T. Zhang, T.-W. E. Lee, J. Tan, and S. Levine, “Learning agile robotic locomotion skills by im- itating animals,” inRobotics: Science and Systems, 07 2020, DOI:10.15607/RSS.2020.XVI.064
-
[6]
Learning agile skills via adversarial imitation of rough partial demonstrations,
C. Li, M. Vlastelica, S. Blaes, J. Frey, F. Grimminger, and G. Mar- tius, “Learning agile skills via adversarial imitation of rough partial demonstrations,” inConference on Robot Learning. PMLR, 2023, pp. 342–352
work page 2023
-
[7]
Masked- mimic: Unified physics-based character control through masked motion inpainting,
C. Tessler, Y . Guo, O. Nabati, G. Chechik, and X. B. Peng, “Masked- mimic: Unified physics-based character control through masked motion inpainting,”ACM Transactions on Graphics (TOG), vol. 43, no. 6, pp. 1–21, 2024
work page 2024
-
[8]
Reference grounded skill discovery,
S. Rho, A. Trinh, D. Xu, and S. Ha, “Reference grounded skill discovery,”arXiv preprint arXiv:2510.06203, 2025
-
[9]
Learning steerable imitation controllers from unstructured animal motions,
D. Kang, J. Cheng, F. Zargarbashi, T. Yoon, S. Choi, and S. Coros, “Learning steerable imitation controllers from unstructured animal mo- tions,”arXiv preprint arXiv:2507.00677, 2025
-
[10]
Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,
X. B. Peng, Y . Guo, L. Halper, S. Levine, and S. Fidler, “Ase: Large- scale reusable adversarial skill embeddings for physically simulated characters,”ACM Transactions On Graphics (TOG), vol. 41, no. 4, pp. 1–17, 2022
work page 2022
-
[11]
Calm: Conditional adversarial latent models for directable virtual characters,
C. Tessler, Y . Kasten, Y . Guo, S. Mannor, G. Chechik, and X. B. Peng, “Calm: Conditional adversarial latent models for directable virtual characters,” inACM SIGGRAPH 2023 Conference Proceedings, 2023, pp. 1–9
work page 2023
-
[12]
Unsupervised skill discovery as exploration for learning agile locomotion,
S. Rho, K. Garg, M. Byrd, and S. Ha, “Unsupervised skill discovery as exploration for learning agile locomotion,” in9th Annual Conference on Robot Learning
-
[13]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, no. 88, p. eadi7566, 2024
work page 2024
-
[14]
Continuous reinforcement learning based ramp jump control for single-track two- wheeled robots,
Q. Zheng, D. Wang, Z. Chen, Y . Sun, and B. Liang, “Continuous reinforcement learning based ramp jump control for single-track two- wheeled robots,”Transactions of the Institute of Measurement and Control, vol. 44, no. 4, pp. 892–904, 2022
work page 2022
-
[15]
A deep reinforcement learning algorithm to control a two-wheeled scooter with a humanoid robot,
J. Baltes, G. Christmann, and S. Saeedvand, “A deep reinforcement learning algorithm to control a two-wheeled scooter with a humanoid robot,”Engineering Applications of Artificial Intelligence, vol. 126, p. 106941, 2023
work page 2023
-
[16]
B. Wang, F. Jing, Y . Deng, Z. Chen, and B. Liang, “Bayesian optimization-based ideal landing planning for ramp jump of single- track two-wheeled robots,” in2024 IEEE International Conference on Robotics and Biomimetics (ROBIO). IEEE, 2024, pp. 396–401
work page 2024
-
[17]
A survey of wheeled- legged robots,
M. Bjelonic, V . Klemm, J. Lee, and M. Hutter, “A survey of wheeled- legged robots,” inClimbing and walking robots conference. Springer, 2022, pp. 83–94
work page 2022
-
[18]
Flip stunts on bicycle robots using iterative motion imitation,
J. Kim, S. Fahmi, S. Rho, S. Ha, and G. Nelson, “Flip stunts on bicycle robots using iterative motion imitation,”arXiv preprint arXiv:2603.27944, 2026
-
[19]
Attention-based map encoding for learning generalized legged locomo- tion,
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter, “Attention-based map encoding for learning generalized legged locomo- tion,”Science Robotics, vol. 10, no. 105, p. eadv3604, 2025
work page 2025
-
[20]
High-speed control and navigation for quadrupedal robots on complex and discrete terrain,
H. Kim, H. Oh, J. Park, Y . Kim, D. Youm, M. Jung, M. Lee, and J. Hwangbo, “High-speed control and navigation for quadrupedal robots on complex and discrete terrain,”Science Robotics, vol. 10, no. 102, p. eads6192, 2025
work page 2025
-
[21]
A. Miller, F. Yu, M. Brauckmann, and F. Farshidian, “High-performance reinforcement learning on spot: Optimizing simulation parameters with distributional measures,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 9981–9988
work page 2025
-
[22]
Rapid locomotion via reinforcement learning,
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal, “Rapid locomotion via reinforcement learning,”The International Journal of Robotics Research, vol. 43, no. 4, pp. 572–587, 2024
work page 2024
-
[23]
Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li, “Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills,”arXiv preprint arXiv:2506.12851, 2025
-
[24]
Omnih2o: Universal and dexterous human-to- humanoid whole-body teleoperation and learning,
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. M. Kitani, C. Liu, and G. Shi, “Omnih2o: Universal and dexterous human-to- humanoid whole-body teleoperation and learning,” inConference on Robot Learning. PMLR, 2025, pp. 1516–1540
work page 2025
-
[25]
Gmt: General motion tracking for humanoid whole-body control,
Z. Chen, M. Ji, X. Cheng, X. Peng, X. B. Peng, and X. Wang, “Gmt: General motion tracking for humanoid whole-body control,”arXiv preprint arXiv:2506.14770, 2025
-
[26]
Available: https://arxiv.org/abs/2502.01143
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbab, C. Panet al., “Asap: Aligning simulation and real-world physics for learning agile humanoid whole-body skills,”arXiv preprint arXiv:2502.01143, 2025
-
[27]
Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath, “Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,”The International Journal of Robotics Research, vol. 44, no. 5, pp. 840–888, 2025
work page 2025
-
[28]
Rt-trajectory: Robotic task generalization via hindsight trajectory sketches,
J. Gu, S. Kirmani, P. Wohlhart, Y . Lu, M. G. Arenas, K. Rao, W. Yu, C. Fu, K. Gopalakrishnan, Z. Xuet al., “Rt-trajectory: Robotic task generalization via hindsight trajectory sketches,” inThe Twelfth Inter- national Conference on Learning Representations
-
[29]
W. Zhi, T. Zhang, and M. Johnson-Roberson, “Instructing robots by sketching: Learning from demonstration via probabilistic diagrammatic teaching,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 15 047–15 053
work page 2024
-
[30]
Sketch- to-skill: Bootstrapping robot learning with human drawn trajectory sketches,
P. Yu, A. Bhaskar, A. Singh, Z. Mahammad, and P. Tokekar, “Sketch- to-skill: Bootstrapping robot learning with human drawn trajectory sketches,”arXiv preprint arXiv:2503.11918, 2025
-
[31]
Waypoint-based rein- forcement learning for robot manipulation tasks,
S. A. Mehta, S. Habibian, and D. P. Losey, “Waypoint-based rein- forcement learning for robot manipulation tasks,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 541–548
work page 2024
-
[32]
L2d2: Robot learning from 2d drawings,
S. A. Mehta, H. Nemlekar, H. Sumant, and D. P. Losey, “L2d2: Robot learning from 2d drawings,”Autonomous Robots, vol. 49, no. 3, p. 25, 2025
work page 2025
-
[33]
Guided reinforcement learning for omnidirectional 3d jumping in quadruped robots,
R. Bussola, M. Focchi, G. Turrisi, C. Semini, and L. Palopoli, “Guided reinforcement learning for omnidirectional 3d jumping in quadruped robots,”arXiv preprint arXiv:2507.16481, 2025
-
[34]
F. Zargarbashi, J. Cheng, D. Kang, R. Sumner, and S. Coros, “Robotkeyframing: Learning locomotion with high-level objectives via mixture of dense and sparse rewards,” inConference on Robot Learning. PMLR, 2025, pp. 916–932
work page 2025
-
[35]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Prox- imal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” in2017 IEEE/RSJ international conference on intelligent robots and systems (IROS). IEEE, 2017, pp. 23–30
work page 2017
-
[37]
Sim-to-real transfer of robotic control with dynamics randomization,
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to-real transfer of robotic control with dynamics randomization,” in2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 3803–3810
work page 2018
-
[38]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano- Mu˜noz, X. Yao, R. Zurbr ¨ugg, N. Rudinet al., “Isaac lab: A gpu- accelerated simulation framework for multi-modal robot learning,”arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627–635
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.