Recognition: unknown
What Matters in Practical Learned Image Compression
Pith reviewed 2026-05-08 16:57 UTC · model grok-4.3
The pith
By studying modeling choices and running performance-aware architecture search, a learned image codec reaches 2.3-3x bitrate savings over traditional standards while encoding 12-megapixel images in 230 ms on a phone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Joint optimization of perceptual metrics and runtime constraints, achieved by exhaustive ablations followed by performance-aware neural architecture search over backbone variants, produces a practical codec that delivers 2.3-3 times lower bitrates than AV1, AV2, VVC, ECM, and JPEG-AI at equal subjective quality and 20-40 percent savings versus the strongest prior learned codecs, with 230 ms encoding and 150 ms decoding for 12 MP images on an iPhone 17 Pro Max.
What carries the argument
Performance-aware neural architecture search over millions of backbone configurations that simultaneously maximizes perceptual metric scores and meets explicit on-device runtime targets.
If this is right
- Learned codecs can now meet the speed and quality requirements for on-device capture and transmission of high-resolution photographs.
- Bandwidth usage in image-centric mobile applications can be cut by more than half without visible quality loss.
- Architecture search guided by both perceptual scores and latency becomes a repeatable method for producing practical learned codecs.
- Traditional hand-crafted codecs face direct competition from optimized learned systems on consumer hardware.
Where Pith is reading between the lines
- The same search-and-ablation workflow could be applied to video to close similar gaps between learned and conventional codecs.
- Hardware-specific runtime targets in the search loop make it likely that the resulting models generalize poorly to very different accelerators without retuning.
- If perceptual metrics continue to improve, future iterations of this codec family could widen the bitrate advantage still further.
Load-bearing premise
Subjective user studies and the selected perceptual metrics accurately reflect human visual preference across varied real-world image content and that the architecture search did not overfit to the test sets.
What would settle it
An independent subjective test on a fresh, diverse image collection that finds no bitrate reduction relative to VVC or AV1 at matched quality, or that measures encode times above 230 ms on the same phone hardware, would falsify the performance claims.
Figures


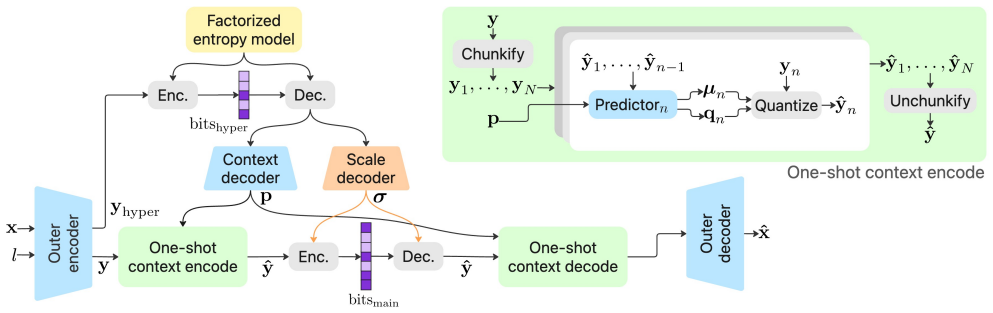


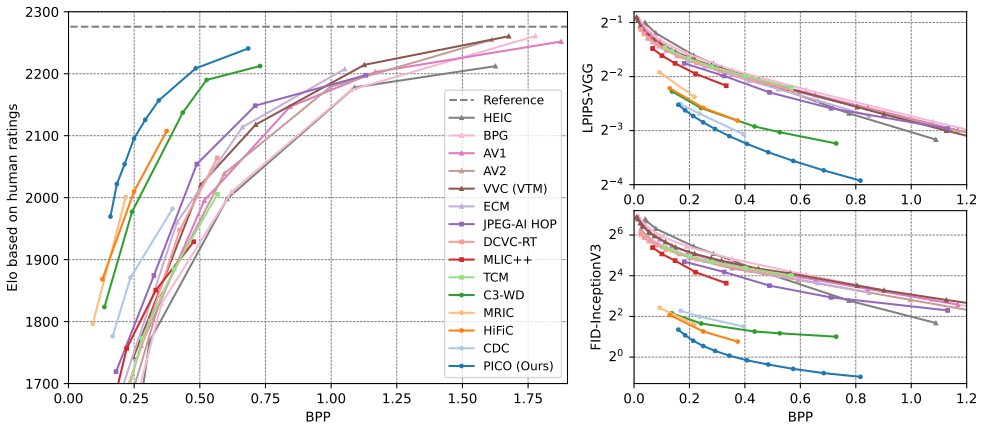






read the original abstract
One of the major differentiators unlocked by learned codecs relative to their hard-coded traditional counterparts is their ability to be optimized directly to appeal to the human visual system. Despite this potential, a perceptual yet practical image codec is yet to be proposed. In this work, we aim to close this gap. We conduct a comprehensive study of the key modeling choices that govern the design of a practical learned image codec, jointly optimized for perceptual quality and runtime -- including within the ablations several novel techniques. We then perform performance-aware neural architecture search over millions of backbone configurations to identify models that achieve the target on-device runtime while maximizing compression performance as captured by perceptual metrics. We combine the various optimizations to construct a new codec that achieves a significantly improved tradeoff between speed and perceptual quality. Based on rigorous subjective user studies, it provides 2.3-3x bitrate savings against AV1, AV2, VVC, ECM and JPEG-AI, and 20-40% bitrate savings against the best learned codec alternatives. At the same time, on an iPhone 17 Pro Max, it encodes 12MP images as fast as 230ms, and decodes them in 150ms -- faster than most top ML-based codecs run on a V100 GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a comprehensive empirical study of modeling choices for practical learned image codecs jointly optimized for perceptual quality and runtime. It includes ablations of several novel techniques, followed by performance-aware neural architecture search (NAS) over millions of backbone configurations to identify models that meet on-device runtime targets while maximizing perceptual metrics. The resulting codec is claimed to deliver 2.3-3x bitrate savings versus AV1, AV2, VVC, ECM and JPEG-AI, and 20-40% savings versus prior learned codecs, according to subjective user studies, while achieving 230 ms encode / 150 ms decode for 12 MP images on an iPhone 17 Pro Max.
Significance. If the reported gains are reproducible and generalizable, the work would be significant for the learned compression community by demonstrating a deployable perceptual codec that substantially outperforms both traditional standards and existing learned methods in bitrate efficiency while satisfying strict mobile runtime constraints. The scale of the ablations and NAS could provide reusable insights for future architecture design under perceptual and efficiency objectives.
major comments (3)
- [Architecture search / NAS] The performance-aware NAS procedure (described in the architecture search section) provides no details on safeguards against overfitting, such as held-out validation sets distinct from the final evaluation content, cross-validation across domains, or regularization of the search objective. Because the search optimizes directly over perceptual metrics across millions of configurations, this omission is load-bearing for the claimed 20-40% bitrate savings versus other learned codecs.
- [Subjective evaluation] The subjective user studies section lacks specification of key experimental controls: number of observers, content selection and diversity, exact comparison protocol (e.g., double-stimulus or forced-choice), and statistical testing for significance. These details are required to substantiate the central 2.3-3x bitrate savings claims against traditional codecs.
- [Ablations and evaluation metrics] Exact definitions and implementations of the perceptual metrics used both in the ablations and as the NAS objective are not provided, nor are the training/validation/test data splits. Without these, the support for the reported performance trade-offs cannot be fully assessed.
minor comments (1)
- [Abstract] The abstract and runtime claims reference an 'iPhone 17 Pro Max'; if this is a future or hypothetical device, a clarifying footnote would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where details were omitted for brevity, we will expand the manuscript to include them, ensuring the claims are fully supported and reproducible.
read point-by-point responses
-
Referee: [Architecture search / NAS] The performance-aware NAS procedure (described in the architecture search section) provides no details on safeguards against overfitting, such as held-out validation sets distinct from the final evaluation content, cross-validation across domains, or regularization of the search objective. Because the search optimizes directly over perceptual metrics across millions of configurations, this omission is load-bearing for the claimed 20-40% bitrate savings versus other learned codecs.
Authors: We agree that explicit safeguards must be documented. The NAS was conducted with a held-out validation set of 150 images drawn from the same sources as training data but with no overlap to either training or final test content; the search objective included an explicit runtime regularization term and used early stopping on validation perceptual scores. We also performed the search across multiple random seeds and two domain subsets (natural scenes and high-frequency textures) to assess stability. We will add a dedicated subsection (or appendix) fully describing the NAS protocol, data partitioning, and regularization to make these safeguards transparent. revision: yes
-
Referee: [Subjective evaluation] The subjective user studies section lacks specification of key experimental controls: number of observers, content selection and diversity, exact comparison protocol (e.g., double-stimulus or forced-choice), and statistical testing for significance. These details are required to substantiate the central 2.3-3x bitrate savings claims against traditional codecs.
Authors: We will revise the subjective evaluation section to supply all requested controls. The studies used 28 observers screened for normal vision, a double-stimulus continuous quality scale (DSCQS) protocol with randomized side-by-side presentation on calibrated 4K displays, and 45 diverse 12 MP test images spanning natural scenes, portraits, textures, and low-light conditions (none overlapping training data). Statistical significance was assessed via paired t-tests and Wilcoxon signed-rank tests (p < 0.01 for the reported savings). These elements were part of the experimental design; we omitted them for space and will restore them with full protocol description. revision: yes
-
Referee: [Ablations and evaluation metrics] Exact definitions and implementations of the perceptual metrics used both in the ablations and as the NAS objective are not provided, nor are the training/validation/test data splits. Without these, the support for the reported performance trade-offs cannot be fully assessed.
Authors: We acknowledge the need for precise metric definitions and splits. LPIPS (AlexNet backbone) and DISTS were used exactly as released by their authors; the NAS objective was a weighted combination of these plus a differentiable runtime proxy. Training used ~2800 images from DIV2K + Flickr2K + internal mobile captures, validation used 120 held-out images from the same pool, and testing used Kodak, CLIC professional, and a separate 50-image 12 MP mobile set. We will insert a concise “Experimental Setup” subsection (or appendix) listing exact metric implementations (with code references), loss weights, and the full data partitioning to enable direct assessment of the ablations and NAS results. revision: yes
Circularity Check
No significant circularity in empirical architecture search and evaluations
full rationale
The paper is an empirical study focused on ablations of modeling choices, performance-aware neural architecture search over millions of backbone configurations to optimize perceptual metrics under runtime constraints, and final validation via subjective user studies. No mathematical derivations, first-principles predictions, or results are claimed that reduce to inputs by construction (e.g., no self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations). The bitrate savings claims rest on independent subjective evaluations rather than being tautological with the NAS objective. This is a standard non-circular empirical finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to-end optimized image compression.arXiv preprint arXiv:1611.01704, 2016
J. Ballé, V . Laparra, and E. P. Simoncelli, “End-to- end optimized image compression,”arXiv preprint arXiv:1611.01704, 2016
-
[2]
Real-time adaptive image compression,
O. Rippel and L. Bourdev, “Real-time adaptive image compression,” inProceedings of the 34th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, D. Precup and Y . W. Teh, Eds., vol. 70. International Convention Centre, Sydney, Australia: PMLR, 06–11 Aug 2017, pp. 2922– 2930
2017
-
[3]
Variational image compression with a scale hyperprior,
J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inInternational Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=rkcQFMZRb
2018
-
[4]
Integer net- works for data compression with latent-variable mod- els,
J. Ballé, N. Johnston, and D. Minnen, “Integer net- works for data compression with latent-variable mod- els,” inInternational Conference on Learning Repre- sentations, 2018
2018
-
[5]
Elf-vc: Efficient learned flexible-rate video coding,
O. Rippel, A. G. Anderson, K. Tatwawadi, S. Nair, C. Lytle, and L. Bourdev, “Elf-vc: Efficient learned flexible-rate video coding,” inProceedings of the IEEE/CVF International Conference on Computer Vi- sion, 2021, pp. 14 479–14 488
2021
-
[6]
Towards real-time neural video codec for cross-platform application using calibration informa- tion,
K. Tian, Y . Guan, J. Xiang, J. Zhang, X. Han, and W. Yang, “Towards real-time neural video codec for cross-platform application using calibration informa- tion,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 7961–7970
2023
-
[7]
Towards reproducible learning-based compression,
J. Pang, M. A. Lodhi, J. Ahn, Y . Huang, and D. Tian, “Towards reproducible learning-based compression,” in 2024 IEEE 26th International Workshop on Multimedia Signal Processing (MMSP). IEEE, 2024, pp. 1–6
2024
-
[8]
Towards practical real-time neural video compression,
Z. Jia, B. Li, J. Li, W. Xie, L. Qi, H. Li, and Y . Lu, “Towards practical real-time neural video compression,” inIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 2025, Nashville, TN, USA, June 11-25, 2025
2025
-
[9]
JPEG AI Reference Software,
“JPEG AI Reference Software,” https://gitlab.com/ wg1/jpeg-ai/jpeg-ai-reference-software, 2025
2025
-
[10]
High-fidelity generative image com- pression,
F. Mentzer, G. D. Toderici, M. Tschannen, and E. Agustsson, “High-fidelity generative image com- pression,”Advances in neural information processing systems, vol. 33, pp. 11 913–11 924, 2020
2020
-
[11]
Lossy image compression with conditional diffusion models,
R. Yang and S. Mandt, “Lossy image compression with conditional diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 64 971– 64 995, 2023
2023
-
[12]
Good, cheap, and fast: Overfitted image compression with wasserstein distortion,
J. Ballé, L. Versari, E. Dupont, H. Kim, and M. Bauer, “Good, cheap, and fast: Overfitted image compression with wasserstein distortion,” inProceedings of the Com- puter Vision and Pattern Recognition Conference, 2025, pp. 23 259–23 268
2025
-
[13]
Po-elic: Perception- oriented efficient learned image coding,
D. He, Z. Yang, H. Yu, T. Xu, J. Luo, Y . Chen, C. Gao, X. Shi, H. Qin, and Y . Wang, “Po-elic: Perception- oriented efficient learned image coding,” 2022. [Online]. Available: https://arxiv.org/abs/2205.14501
-
[14]
libbpg: BPG (Better Portable Graphics) image library,
F. Bellard, “libbpg: BPG (Better Portable Graphics) image library,” http://bellard.org/bpg/libbpg-0.9.5.tar. gz, 2015, version 0.9.5, released 2015-01-11
2015
-
[15]
VVCSoft- ware_VTM: VVC VTM Reference Software,
Joint Video Experts Team (JVET), “VVCSoft- ware_VTM: VVC VTM Reference Software,” https: //vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM/- /releases/VTM-23.11, 2025, version 23.11, released 2025-07-03
2025
-
[16]
AOM: A V1 codec library, version 3.12.1,
Alliance for Open Media, “AOM: A V1 codec library, version 3.12.1,” Alliance for Open Media, Git repository, April 2025, tag: v3.12.1, commit 10aece4, tagged fc5cf6a. [Online]. Available: https://aomedia.googlesource.com/aom/+/refs/tags/ v3.12.1
2025
-
[17]
Enhanced Compression Model (ECM) Reference Software,
Joint Video Experts Team (JVET), “Enhanced Compression Model (ECM) Reference Software,” Fraunhofer HHI, GitLab repository, September 2025, branch: master, commit dcc311af, accessed 2025-09-25. [Online]. Available: https: //vcgit.hhi.fraunhofer.de/ecm/ECM
2025
-
[18]
A VM: A V2 codec research anchor, version research-v11.0.0,
Alliance for Open Media, “A VM: A V2 codec research anchor, version research-v11.0.0,” Alliance for Open Media, GitLab repository, September 2025, tag: research-v11.0.0, commit 3a5da21a. [On- line]. Available: https://gitlab.com/AOMediaCodec/ avm/-/tags/research-v11.0.0
2025
- [19]
-
[20]
Multi-realism image compression with a conditional generator,
E. Agustsson, D. Minnen, G. Toderici, and F. Mentzer, “Multi-realism image compression with a conditional generator,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2023, pp. 22 324–22 333
2023
-
[21]
Generative la- tent coding for ultra-low bitrate image compression,
Z. Jia, J. Li, B. Li, H. Li, and Y . Lu, “Generative la- tent coding for ultra-low bitrate image compression,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 26 088– 26 098
2024
-
[22]
Bridging the gap between diffusion mod- els and universal quantization for image compression,
L. Relic, R. Azevedo, Y . Zhang, M. Gross, and C. Schroers, “Bridging the gap between diffusion mod- els and universal quantization for image compression,” inMachine Learning and Compression Workshop@ NeurIPS 2024. OpenReview, 2024
2024
-
[23]
Available: https://orange-opensource.github
[Online]. Available: https://orange-opensource.github. io/Cool-Chic/
-
[24]
Joint Autoregressive and Hierarchical Priors for Learned Image Compression
D. Minnen, J. Ballé, and G. Toderici, “Joint autoregres- sive and hierarchical priors for learned image compres- sion,”arXiv preprint arXiv:1809.02736, 2018
work page Pith review arXiv 2018
-
[25]
Checkerboard context model for efficient learned im- age compression,
D. He, Y . Zheng, B. Sun, Y . Wang, and H. Qin, “Checkerboard context model for efficient learned im- age compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2021, pp. 14 771–14 780
2021
-
[26]
Elic: Efficient learned image compression with un- evenly grouped space-channel contextual adaptive cod- ing,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “Elic: Efficient learned image compression with un- evenly grouped space-channel contextual adaptive cod- ing,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5718–5727
2022
-
[27]
Neural video compression with feature modulation,
J. Li, B. Li, and Y . Lu, “Neural video compression with feature modulation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 17-21, 2024, 2024
2024
-
[28]
C3: High-performance and low- complexity neural compression from a single image or video,
H. Kim, M. Bauer, L. Theis, J. R. Schwarz, and E. Dupont, “C3: High-performance and low- complexity neural compression from a single image or video,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9347–9358
2024
-
[29]
Learning a deep vector quantization network for im- age compression,
X. Lu, H. Wang, W. Dong, F. Wu, Z. Zheng, and G. Shi, “Learning a deep vector quantization network for im- age compression,”IEEE Access, vol. 7, pp. 118 815– 118 825, 2019
2019
-
[30]
Ntire 2017 challenge on single image super-resolution: Dataset and study,
E. Agustsson and R. Timofte, “Ntire 2017 challenge on single image super-resolution: Dataset and study,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, July 2017
2017
-
[31]
Available: https://clic2025.compression.cc/ tasks/#image
[Online]. Available: https://clic2025.compression.cc/ tasks/#image
-
[32]
Ntire 2017 challenge on single image super-resolution: Methods and results,
R. Timofte, E. Agustsson, L. V . Gool, M.-H. Yang, L. Zhang, B. Lim, S. Son, H. Kim, S. Nah, K. M. Lee, X. Wang, Y . Tian, K. Yu, Y . Zhang, S. Wu, C. Dong, L. Lin, Y . Qiao, C. C. Loy, W. Bae, J. Yoo, Y . Han, J. C. Ye, J.-S. Choi, M. Kim, Y . Fan, J. Yu, W. Han, D. Liu, H. Yu, Z. Wang, H. Shi, X. Wang, T. S. Huang, Y . Chen, K. Zhang, W. Zuo, Z. Tang, L...
2017
-
[33]
Adam: A Method for Stochastic Optimization
D. Kingma and J. Ba, “Adam: A method for stochastic optimization,”arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review arXiv 2014
-
[34]
Mobilenetv2: Inverted residuals and linear bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.- C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520
2018
-
[35]
Channel-wise autoregres- sive entropy models for learned image compression,
D. Minnen and S. Singh, “Channel-wise autoregres- sive entropy models for learned image compression,” in2020 IEEE International Conference on Image Pro- cessing (ICIP). IEEE, 2020, pp. 3339–3343
2020
-
[36]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA: N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, D. Dworakowski, J. Fan, M. Fenzi, F. Ferroni, S. Fidler, D. Fox, S. Ge, Y . Ge, J. Gu, S. Gururani, E. He, J. Huang, J. Huffman, P. Jannaty, J. Jin, S. W. Kim, G. Klár, G. Lam, S. Lan, L. Leal-Taixe, A. Li, Z. Li, C.-H. Lin, T.-Y . Lin, H. Li...
work page internal anchor Pith review arXiv 2025
-
[37]
The unreasonable effectiveness of deep fea- tures as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep fea- tures as a perceptual metric,” inProceedings of the IEEE conference on computer vision and pattern recog- nition, 2018, pp. 586–595
2018
-
[38]
Multi- scale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multi- scale structural similarity for image quality assessment,” inSignals, Systems and Computers, 2004., vol. 2. Ieee, 2003, pp. 1398–1402
2004
-
[39]
Charac- ter region awareness for text detection,
Y . Baek, B. Lee, D. Han, S. Yun, and H. Lee, “Charac- ter region awareness for text detection,” inProceedings of the IEEE Conference on Computer Vision and Pat- tern Recognition, 2019, pp. 9365–9374
2019
-
[40]
Image- to-image translation with conditional adversarial net- works,
P. Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros, “Image- to-image translation with conditional adversarial net- works,” inProceedings of the IEEE conference on com- puter vision and pattern recognition, 2017, pp. 1125– 1134
2017
-
[41]
Mlic++: Linear complexity multi-reference entropy modeling for learned image compression,
W. Jiang, J. Yang, Y . Zhai, F. Gao, and R. Wang, “Mlic++: Linear complexity multi-reference entropy modeling for learned image compression,”arXiv preprint arXiv:2307.15421, 2023
-
[42]
Learned image compres- sion with mixed transformer-cnn architectures,
J. Liu, H. Sun, and J. Katto, “Learned image compres- sion with mixed transformer-cnn architectures,” inPro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2023, pp. 14 388–14 397
2023
-
[43]
Rethinking fid: To- wards a better evaluation metric for image generation,
S. Jayasumana, S. Ramalingam, A. Veit, D. Glasner, A. Chakrabarti, and S. Kumar, “Rethinking fid: To- wards a better evaluation metric for image generation,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024, pp. 9307– 9315
2024
-
[44]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[45]
Available: https://www.mabyduck.com
[Online]. Available: https://www.mabyduck.com
-
[46]
A crowdsourcing approach to video quality assessment,
B. Naderi and R. Cutler, “A crowdsourcing approach to video quality assessment,” 2023. [Online]. Available: https://arxiv.org/abs/2204.06784
-
[47]
Efficient bayesian inference for generalized bradley-terry models,
F. Caron and A. Doucet, “Efficient bayesian inference for generalized bradley-terry models,” 2010. [Online]. Available: https://arxiv.org/abs/1011.1761
-
[48]
Available: https://docs.mabyduck.com/ experiments/metrics/elo
[Online]. Available: https://docs.mabyduck.com/ experiments/metrics/elo
-
[49]
Available: https://docs.mabyduck.com/ experiments/strategies
[Online]. Available: https://docs.mabyduck.com/ experiments/strategies
-
[50]
<src>" <pad_option>’-pix_fmt yuv420p
S. Ishihara,Tests for color-blindness. Tokyo, Hongo Harukicho: Handaya, 1917. A. Additional evaluations Figure 8 presents curves for additional metrics. Although the perceptual codecs PICO, HiFiC, C3-WD and CDC sub- stantially outperform the non-perceptual codecs based on human ratings and the perceptually-oriented objective met- rics, they do not perform...
1917
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.