Recognition: unknown
Geometry-Aware State Space Model: A New Paradigm for Whole-Slide Image Representation
Pith reviewed 2026-05-08 16:25 UTC · model grok-4.3
The pith
A hybrid hyperbolic-Euclidean embedding with state space modeling and chunked expert routing improves whole-slide image classification over standard MIL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
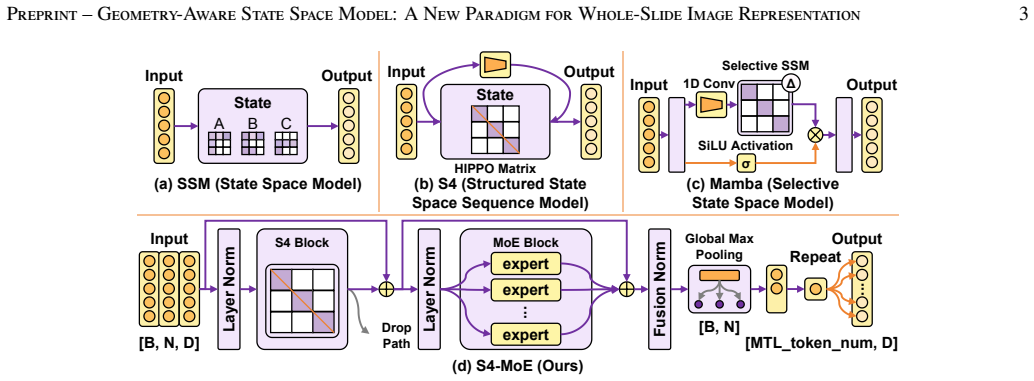
BatMIL embeds WSI patch features in complementary hyperbolic and Euclidean spaces to represent hierarchical tissue organization and fine-grained cellular morphology, applies a structured state space sequence model to capture long-range dependencies among thousands of patches at linear cost, and uses a chunk-level mixture-of-experts module to group patches by region and route them dynamically to specialized subnetworks.
What carries the argument
Hybrid hyperbolic-Euclidean representation that separates hierarchical structure modeling from local detail modeling, paired with an S4 backbone for linear-complexity sequence encoding and a chunk-level mixture-of-experts router for regional specialization.
If this is right
- Long sequences of thousands of patches can be processed without quadratic cost.
- Regional heterogeneity is addressed by dynamic expert assignment rather than uniform aggregation.
- Slide-level classification accuracy improves across multiple cancer types.
- Both global tissue architecture and local morphology are modeled within the same framework.
- The approach extends the two-stage MIL paradigm without increasing inference complexity.
Where Pith is reading between the lines
- The same dual-space plus chunked routing pattern could be tested on other large-scale hierarchical image tasks such as remote sensing or digital histopathology variants.
- If the performance lift disappears when hyperbolic space is replaced by another non-Euclidean geometry, the specific choice of hyperbolic distance would need re-examination.
- Combining the geometry-aware backbone with multi-modal inputs like genomics could be explored as a direct next step.
- The linear-complexity S4 backbone may allow scaling to even higher-resolution WSIs than current MIL methods support.
Load-bearing premise
Pathological tissues exhibit hierarchical organization and regional heterogeneity that cannot be adequately represented by Euclidean embeddings alone.
What would settle it
Removing the hyperbolic embedding component from BatMIL and re-running the seven-dataset experiments yields performance equal to or lower than standard Euclidean MIL baselines.
Figures





read the original abstract
Accurate analysis of histopathological images is critical for disease diagnosis and treatment planning. Whole-slide images (WSIs), which digitize tissue specimens at gigapixel resolution, are fundamental to this process but require aggregating thousands of patches for slide-level predictions. Multiple Instance Learning (MIL) tackles this challenge with a two-stage paradigm, decoupling tile-level embedding and slide-level prediction. However, most existing methods implicitly embed patch representations in homogeneous Euclidean spaces, overlooking the hierarchical organization and regional heterogeneity of pathological tissues. This limits current models' ability to capture global tissue architecture and fine-grained cellular morphology. To address this limitation, we introduce a hybrid hyperbolic-Euclidean representation that embeds WSI features in dual geometric spaces, enabling complementary modeling of hierarchical tissue structures and local morphological details. Building on this formulation, we develop BatMIL, a WSI classification framework that leverages both geometric spaces. To model long-range dependencies among thousands of patches, we employ a structured state space sequence model (S4) backbone that encodes patch sequences with linear computational complexity. Furthermore, to account for regional heterogeneity, we introduce a chunk-level mixture-of-experts (MoE) module that groups patches into regions and dynamically routes them to specialized subnetworks, improving representational capacity while reducing redundant computation. Extensive experiments on seven WSI datasets spanning six cancer types demonstrate that BatMIL consistently outperforms state-of-the-art MIL approaches in slide-level classification tasks. These results indicate that geometry-aware representation learning offers a promising direction for next-generation computational pathology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BatMIL, a geometry-aware framework for whole-slide image (WSI) classification under the multiple instance learning (MIL) paradigm. It introduces a hybrid hyperbolic-Euclidean embedding to capture both hierarchical tissue organization and local morphological details, employs a structured state space sequence model (S4) backbone for linear-complexity modeling of long-range patch dependencies, and adds a chunk-level mixture-of-experts (MoE) module to address regional heterogeneity. The central claim is that this combination yields consistent outperformance over state-of-the-art MIL methods across seven WSI datasets spanning six cancer types.
Significance. If the reported gains prove robust, the work could meaningfully advance computational pathology by demonstrating the utility of non-Euclidean geometry for modeling the intrinsic hierarchical and heterogeneous structure of histopathological tissue. The integration of S4 for scalability and chunk-level MoE for specialization directly targets the computational and representational challenges of gigapixel WSIs. The broad multi-cancer evaluation is a positive feature.
major comments (2)
- [Abstract] Abstract: the claim of consistent outperformance on seven datasets is presented without any quantitative metrics, error bars, ablation results, or statistical tests, preventing assessment of effect size and reliability.
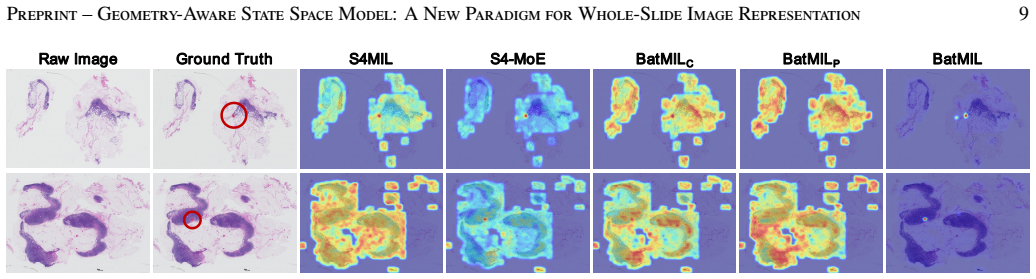
- [Experiments] Experiments section: no ablation studies isolate the contribution of the hybrid hyperbolic-Euclidean embedding from the S4 backbone or chunk-level MoE. Without such controls it remains unclear whether the geometry-aware component is necessary for the claimed gains or whether an Euclidean S4+MoE variant would suffice.
minor comments (1)
- [Methods] The precise formulation of the hybrid embedding (how hyperbolic and Euclidean features are combined and projected) should be stated with explicit equations in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our results. We address each major point below and revise the manuscript where appropriate to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent outperformance on seven datasets is presented without any quantitative metrics, error bars, ablation results, or statistical tests, preventing assessment of effect size and reliability.
Authors: We acknowledge that the abstract, as currently written, states the outperformance claim at a high level without supporting numbers. In the revised manuscript we will update the abstract to include concise quantitative results (e.g., average accuracy gains across the seven datasets and reference to statistical significance), while preserving brevity. All detailed tables, standard deviations, and statistical tests already appear in the Experiments section. revision: yes
-
Referee: [Experiments] Experiments section: no ablation studies isolate the contribution of the hybrid hyperbolic-Euclidean embedding from the S4 backbone or chunk-level MoE. Without such controls it remains unclear whether the geometry-aware component is necessary for the claimed gains or whether an Euclidean S4+MoE variant would suffice.
Authors: The referee is correct that the current manuscript lacks explicit ablations isolating the hybrid geometry. We will add these experiments in the revised version. Specifically, we will report results for (i) the full BatMIL model, (ii) an Euclidean-only S4+MoE variant, and (iii) additional variants ablating the hyperbolic component or the chunk-level MoE. These controls will directly address whether the geometry-aware representation is necessary for the observed gains. revision: yes
Circularity Check
No circularity in derivation chain; claims rest on external experiments
full rationale
The paper introduces a hybrid hyperbolic-Euclidean embedding combined with an S4 backbone and chunk-level MoE for WSI classification, with the central claim being consistent outperformance over SOTA MIL methods on seven datasets across six cancer types. No equations, derivations, or self-referential definitions are present in the abstract or described framework that reduce any prediction or result to fitted inputs or prior self-citations by construction. The geometry-aware representation is motivated by limitations of Euclidean spaces but validated through independent empirical comparisons rather than by ansatz smuggling, uniqueness theorems, or renaming of known results. This is the common case of a self-contained experimental paper whose load-bearing support is external benchmarks, yielding no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Whole slide imaging: technology and appli- cations.Advances in Anatomic Pathology, 27(4):251–259, 2020
Matthew G Hanna, Anil Parwani, and Sahussapont Joseph Sirintrapun. Whole slide imaging: technology and appli- cations.Advances in Anatomic Pathology, 27(4):251–259, 2020
2020
-
[2]
Cod-mil: chain-of-diagnosis prompting multi- ple instance learning for whole slide image classification
Jiangbo Shi, Chen Li, Tieliang Gong, Chunbao Wang, and Huazhu Fu. Cod-mil: chain-of-diagnosis prompting multi- ple instance learning for whole slide image classification. IEEE Transactions on Medical Imaging, 44(3):1218–1229, 2024
2024
-
[3]
Towards a general-purpose foundation model for computational pathology.Nature Medicine, 2024
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Bowen Chen, Andrew Zhang, Daniel Shao, Andrew H Song, Muhammad Shaban, et al. Towards a general-purpose foundation model for computational pathology.Nature Medicine, 2024
2024
-
[4]
Eric Zimmermann, Eugene V orontsov, Julian Viret, Adam Casson, Michal Zelechowski, George Shaikovski, Neil Tenenholtz, James Hall, David Klimstra, Razik Yousfi, et al. Virchow2: Scaling self-supervised mixed magnification models in pathology.arXiv preprint arXiv:2408.00738, 2024
-
[5]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. InIn- ternational conference on machine learning, pages 2127–
-
[6]
Transmil: Transformer based correlated multiple instance learning for whole slide image classification.Advances in neural information processing systems, 34:2136–2147, 2021
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, et al. Transmil: Transformer based correlated multiple instance learning for whole slide image classification.Advances in neural information processing systems, 34:2136–2147, 2021
2021
-
[7]
Hyperpath: Knowledge-guided hyperbolic semantic hierarchy modeling for wsi analysis
Peixiang Huang, Yanyan Huang, Weiqin Zhao, Junjun He, and Lequan Yu. Hyperpath: Knowledge-guided hyperbolic semantic hierarchy modeling for wsi analysis. InInter- national Conference on Medical Image Computing and Computer-Assisted Intervention, pages 262–272. Springer, 2025
2025
-
[8]
Stanford University, 2023
Albert Gu.Modeling sequences with structured state spaces. Stanford University, 2023
2023
-
[10]
Data-efficient and weakly supervised computational pathol- ogy on whole-slide images.Nature biomedical engineer- ing, 5(6):555–570, 2021
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathol- ogy on whole-slide images.Nature biomedical engineer- ing, 5(6):555–570, 2021
2021
-
[11]
Dual-stream multiple instance learning network for whole slide image classifica- tion with self-supervised contrastive learning
Bin Li, Yin Li, and Kevin W Eliceiri. Dual-stream multiple instance learning network for whole slide image classifica- tion with self-supervised contrastive learning. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2021
2021
-
[12]
Dtfd- mil: Double-tier feature distillation multiple instance learn- ing for histopathology whole slide image classification
Hongrun Zhang, Yanda Meng, Yitian Zhao, Yihong Qiao, Xiaoyun Yang, Sarah E Coupland, and Yalin Zheng. Dtfd- mil: Double-tier feature distillation multiple instance learn- ing for histopathology whole slide image classification. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18802–18812, 2022
2022
-
[13]
Whole slide images are 2d point clouds: Context-aware survival prediction using patch- based graph convolutional networks
Richard J Chen, Ming Y Lu, Muhammad Shaban, Chengkuan Chen, Tiffany Y Chen, Drew FK Williamson, and Faisal Mahmood. Whole slide images are 2d point clouds: Context-aware survival prediction using patch- based graph convolutional networks. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 339–349. Springer, 2021
2021
-
[14]
Differentiable zooming for multiple instance learn- ing on whole-slide images
Kevin Thandiackal, Boqi Chen, Pushpak Pati, Guillaume Jaume, Drew FK Williamson, Maria Gabrani, and Orcun Goksel. Differentiable zooming for multiple instance learn- ing on whole-slide images. InEuropean Conference on Computer Vision, pages 699–715. Springer, 2022
2022
-
[15]
Higt: Hierarchical interaction graph-transformer for whole slide image analysis
Ziyu Guo, Weiqin Zhao, Shujun Wang, and Lequan Yu. Higt: Hierarchical interaction graph-transformer for whole slide image analysis. InInternational Conference on Medi- cal Image Computing and Computer-Assisted Intervention, pages 755–764. Springer, 2023. Preprint– Geometry-Aw areStateSpaceModel: A NewParadigm forWhole-SlideImageRepresentation11
2023
-
[16]
A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):22, 2024
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, CliffWong, Ze- lalem Gero, Javier González, and Yu Gu. A whole-slide foundation model for digital pathology from real-world data.Nature, 630(8015):22, 2024
2024
-
[17]
Structured state space models for multiple instance learning in digital pathology
Leo Fillioux, Joseph Boyd, Maria Vakalopoulou, Paul- Henry Cournède, and Stergios Christodoulidis. Structured state space models for multiple instance learning in digital pathology. InInternational Conference on Medical Im- age Computing and Computer-Assisted Intervention, pages 594–604. Springer, 2023
2023
-
[18]
Mambamil: En- hancing long sequence modeling with sequence reordering in computational pathology
Shu Yang, Yihui Wang, and Hao Chen. Mambamil: En- hancing long sequence modeling with sequence reordering in computational pathology. InInternational conference on medical image computing and computer-assisted inter- vention, pages 296–306. Springer, 2024
2024
-
[19]
Mammil: Multi- ple instance learning for whole slide images with state space models
Zijie Fang, Yifeng Wang, Ye Zhang, Zhi Wang, Jian Zhang, Xiangyang Ji, and Yongbing Zhang. Mammil: Multi- ple instance learning for whole slide images with state space models. In2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 3200–
-
[20]
PathRWKV: Enhancing Whole Slide Image Inference with Asymmetric Recurrent Modeling
Sicheng Chen, Tianyi Zhang, Dankai Liao, Dandan Li, Low Chang Han, Yanqin Jiang, Yueming Jin, and Shangqing Lyu. Pathrwkv: Enabling whole slide prediction with recurrent-transformer.arXiv preprint arXiv:2503.03199, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Stainexpert: A unified multi-expert diffusion framework for multi-target pathological stain translation
Zeyu Liu, Yufang He, Tianyi Zhang, Chenbin Ma, Fan Song, Huijie Wu, Ruxin Cai, Haoran Guo, Haonan Zhang, Bo Wen, et al. Stainexpert: A unified multi-expert diffusion framework for multi-target pathological stain translation. IEEE Transactions on Medical Imaging, 2025
2025
-
[22]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, De- hao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling gi- ant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668, 2020
work page internal anchor Pith review arXiv 2006
-
[23]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[24]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
Scaling vision with sparse mixture of experts.Advances in Neural Information Pro- cessing Systems, 34:8583–8595, 2021
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts.Advances in Neural Information Pro- cessing Systems, 34:8583–8595, 2021
2021
-
[26]
Improving visual recognition with hyperbolical visual hierarchy mapping
Hyeongjun Kwon, Jinhyun Jang, Jin Kim, Kwonyoung Kim, and Kwanghoon Sohn. Improving visual recognition with hyperbolical visual hierarchy mapping. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17364–17374, 2024
2024
-
[27]
Accept the modality gap: An exploration in the hyperbolic space
Sameera Ramasinghe, Violetta Shevchenko, Gil Avraham, and Ajanthan Thalaiyasingam. Accept the modality gap: An exploration in the hyperbolic space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27263–27272, 2024
2024
-
[28]
Hyperbolic vision transformers: Combining improvements in metric learning
Aleksandr Ermolov, Leyla Mirvakhabova, Valentin Khrulkov, Nicu Sebe, and Ivan Oseledets. Hyperbolic vision transformers: Combining improvements in metric learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7409–7419, 2022
2022
-
[29]
Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama, 318(22):2199–2210, 2017
Babak Ehteshami Bejnordi, Mitko Veta, Paul Johannes Van Diest, Bram Van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen AWM Van Der Laak, Meyke Hermsen, Quirine F Manson, Maschenka Balkenhol, et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer.Jama, 318(22):2199–2210, 2017
2017
-
[30]
Peter Bandi, Oscar Geessink, Quirine Manson, Mar- cory Van Dijk, Maschenka Balkenhol, Meyke Hermsen, Babak Ehteshami Bejnordi, Byungjae Lee, Kyunghyun Paeng, Aoxiao Zhong, et al. From detection of individual metastases to classification of lymph node status at the pa- tient level: the camelyon17 challenge.IEEE transactions on medical imaging, 38(2):550–560, 2018
2018
-
[31]
Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
Wouter Bulten, Kimmo Kartasalo, Po-Hsuan Cameron Chen, Peter Ström, Hans Pinckaers, Kunal Nagpal, Yuan- nan Cai, David F Steiner, Hester Van Boven, Robert Vink, et al. Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
2022
-
[32]
Tcgabiolinks: an r/bioconductor package for integrative analysis of tcga data.Nucleic acids research, 44(8):e71–e71, 2016
Antonio Colaprico, Tiago C Silva, Catharina Olsen, Lu- ciano Garofano, Claudia Cava, Davide Garolini, Thais S Sabedot, Tathiane M Malta, Stefano M Pagnotta, Isabella Castiglioni, et al. Tcgabiolinks: an r/bioconductor package for integrative analysis of tcga data.Nucleic acids research, 44(8):e71–e71, 2016
2016
-
[33]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review arXiv 2017
-
[34]
Unpuzzle: A unified framework for pathol- ogy image analysis.arXiv preprint arXiv:2503.03152, 2025
Dankai Liao, Sicheng Chen, Nuwa Xi, Qiaochu Xue, Jieyu Li, Lingxuan Hou, Zeyu Liu, Chang Han Low, Yufeng Wu, Yiling Liu, et al. Unpuzzle: A unified framework for pathol- ogy image analysis.arXiv preprint arXiv:2503.03152, 2025
-
[35]
Grad-cam: visual explanations from deep networks via gradient-based localization.International journal of computer vision, 128(2):336–359, 2020
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra. Grad-cam: visual explanations from deep networks via gradient-based localization.International journal of computer vision, 128(2):336–359, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.