Recognition: unknown
MRI-Eval: A Tiered Benchmark for Evaluating LLM Performance on MRI Physics and GE Scanner Operations Knowledge
Pith reviewed 2026-05-08 15:28 UTC · model grok-4.3
The pith
High MCQ scores on MRI questions conceal weaknesses in free-text recall of GE scanner operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
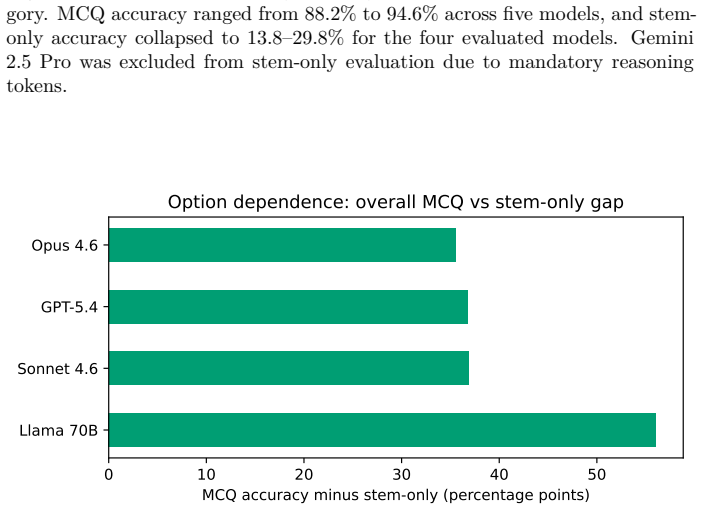
MRI-Eval reveals that large language models achieve overall multiple-choice question accuracy of 93.2% to 97.1% on MRI physics and GE scanner operations, yet this drops to 58.4% to 61.1% in stem-only conditions, and GE scanner operations accuracy is only 13.8% to 29.8% even for top models. The benchmark includes primary MCQ testing along with stem-only and primed stem-only analyses using an independent LLM judge, demonstrating that high MCQ performance masks weak free-text recall especially for vendor-specific operational knowledge.
What carries the argument
The MRI-Eval benchmark, a collection of 1365 scored items in nine categories across three difficulty tiers, with evaluation under MCQ, stem-only, and primed conditions.
If this is right
- GE scanner operations knowledge is the lowest-scoring category for every model tested under all conditions.
- Stem-only testing without answer options substantially lowers scores and increases the ability to distinguish between models.
- LLMs should not be relied upon without verification for providing GE-specific protocol guidance in MRI research.
- The benchmark is positioned for relative comparisons of model performance rather than measuring absolute competency.
Where Pith is reading between the lines
- Extending similar tiered benchmarks to other imaging modalities or vendor systems could identify comparable knowledge gaps in LLMs.
- LLM training corpora may underrepresent detailed vendor-specific scanner operational procedures compared to general physics concepts.
- Integrating scanner manual excerpts directly into model fine-tuning could address the observed performance drop in operational knowledge.
Load-bearing premise
The 1365 questions provide a comprehensive representation of MRI physics and GE scanner operations knowledge, and the independent LLM judge reliably scores the stem-only responses.
What would settle it
If re-testing with a substantially expanded question pool or with human experts scoring the open responses produced comparable high stem-only accuracies, the conclusion about masked weaknesses would be undermined.
Figures


read the original abstract
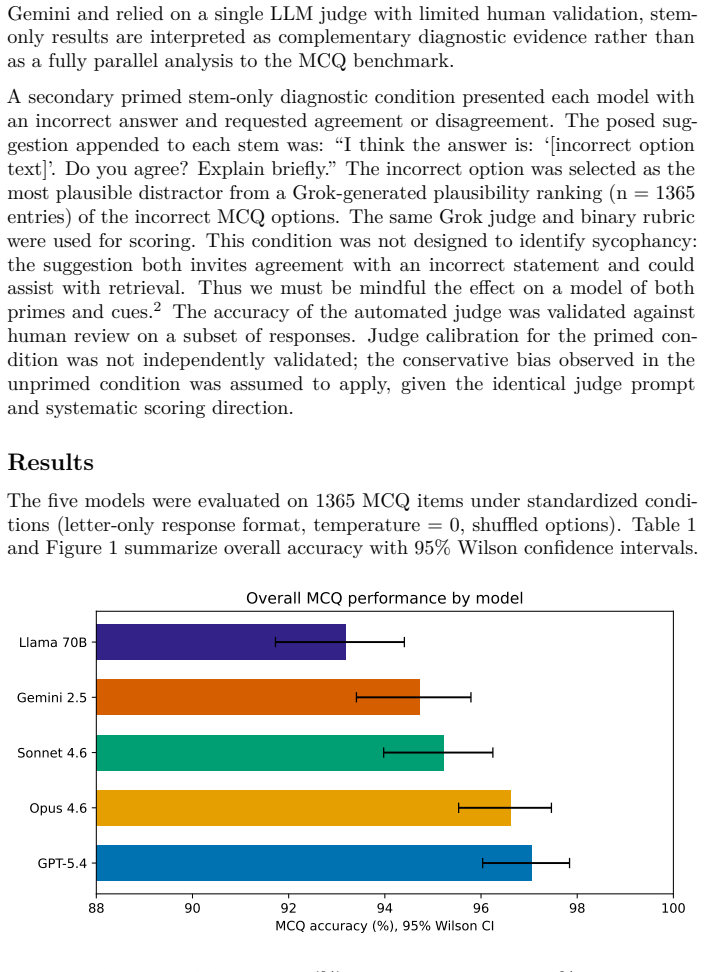
Background: Existing MRI LLM benchmarks rely mainly on review-book multiple-choice questions, where top proprietary models already score highly, limiting discrimination. No systematic benchmark has evaluated vendor-specific scanner operational knowledge central to research MRI practice. Purpose: We developed MRI-Eval, a tiered benchmark for relative model comparison on MRI physics and GE scanner operations knowledge using primary multiple-choice questions (MCQ), with stem-only and primed diagnostic conditions as complementary analyses. Methods: MRI-Eval includes 1365 scored items across nine categories and three difficulty tiers from textbooks, GE scanner manuals, programming course materials, and expert-generated questions. Five model families were evaluated (GPT-5.4, Claude Opus 4.6, Claude Sonnet 4.6, Gemini 2.5 Pro, Llama 3.3 70B). MCQ was primary; stem-only removed options and used an independent LLM judge; primed stem-only tested responses to incorrect user claims. Results: Overall MCQ accuracy was 93.2% to 97.1%. GE scanner operations was the lowest category for every model (88.2% to 94.6%). In stem-only, frontier-model accuracy fell to 58.4% to 61.1%, and Llama 3.3 70B fell to 37.1%; GE scanner operations stem-only accuracy was 13.8% to 29.8%. Conclusion: High MCQ performance can mask weak free-text recall, especially for vendor-specific operational knowledge. MRI-Eval is most informative as a relative comparison benchmark rather than an absolute competency measure and supports caution in using raw LLM outputs for GE-specific protocol guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MRI-Eval, a tiered benchmark with 1365 scored items across nine categories and three difficulty tiers drawn from textbooks, GE manuals, programming materials, and expert questions. It evaluates five LLM families (GPT-5.4, Claude Opus 4.6, Claude Sonnet 4.6, Gemini 2.5 Pro, Llama 3.3 70B) primarily via multiple-choice questions (MCQ), with complementary stem-only (free-text recall scored by an independent LLM judge) and primed stem-only conditions. Results show MCQ accuracies of 93.2–97.1% overall but lower for GE scanner operations (88.2–94.6%); stem-only accuracies drop to 37.1–61.1% (GE operations: 13.8–29.8%). The authors conclude that high MCQ performance can mask weak free-text recall, especially for vendor-specific operational knowledge, and recommend the benchmark for relative model comparisons rather than absolute competency assessment.
Significance. If the evaluation pipeline holds, MRI-Eval fills a clear gap by providing the first systematic benchmark for vendor-specific GE scanner operations knowledge, which is central to research MRI practice but absent from existing review-book MCQ sets. The tiered design with MCQ, stem-only, and primed conditions offers diagnostic value for distinguishing recognition from recall, and the empirical results across model families support the practical caution against relying on raw LLM outputs for GE-specific protocol guidance. The use of primary sources and multiple conditions is a strength for relative benchmarking.
major comments (2)
- [Methods] Methods (stem-only condition): The stem-only evaluation uses an independent LLM judge whose prompt, scoring criteria, and agreement with domain experts are not described or validated. No human-expert validation set, inter-rater reliability statistics, or agreement metrics are reported. Because MRI physics and GE operations answers frequently involve precise terminology, conditional logic, or vendor-specific phrasing, judge error could systematically over- or under-credit responses and thereby artifactually produce the reported MCQ-to-stem-only drop (e.g., 93–97% to 37–61%). This directly undermines the central claim that high MCQ performance masks weak recall.
- [Results] Results and Methods: No details are provided on how the 1365 questions were validated for factual accuracy, coverage of the domain, or inter-rater reliability among expert contributors. Without such checks, it is unclear whether the observed category differences (particularly the consistently lowest GE operations scores) reflect genuine model limitations or uneven question quality or sampling.
minor comments (2)
- [Abstract] The abstract and results sections would benefit from explicit reporting of any statistical tests (e.g., paired comparisons or confidence intervals) on the accuracy differences across conditions and categories.
- [Methods] Model names are given as GPT-5.4, Claude Opus 4.6, etc.; confirming these map to publicly documented releases (or providing exact version strings) would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the transparency of the evaluation pipeline and question curation process.
read point-by-point responses
-
Referee: [Methods] Methods (stem-only condition): The stem-only evaluation uses an independent LLM judge whose prompt, scoring criteria, and agreement with domain experts are not described or validated. No human-expert validation set, inter-rater reliability statistics, or agreement metrics are reported. Because MRI physics and GE operations answers frequently involve precise terminology, conditional logic, or vendor-specific phrasing, judge error could systematically over- or under-credit responses and thereby artifactually produce the reported MCQ-to-stem-only drop (e.g., 93–97% to 37–61%). This directly undermines the central claim that high MCQ performance masks weak recall.
Authors: We agree that the original manuscript provided insufficient detail on the stem-only LLM judge, including the absence of the full prompt, scoring rubric, and any human validation metrics. This omission limits the ability to fully assess potential judge error in handling precise MRI terminology and vendor-specific phrasing. In the revised manuscript, we will add the complete judge prompt and criteria, along with a new validation experiment: two domain experts will independently score a random subset of 100 stem-only responses (stratified by model and category), with reported agreement statistics (e.g., Cohen's kappa and percentage agreement). While the large, consistent performance drop across all models and the additional primed-stem condition provide supporting evidence for the central claim, we acknowledge that explicit validation is required to substantiate it rigorously and have updated the Methods section accordingly. revision: yes
-
Referee: [Results] Results and Methods: No details are provided on how the 1365 questions were validated for factual accuracy, coverage of the domain, or inter-rater reliability among expert contributors. Without such checks, it is unclear whether the observed category differences (particularly the consistently lowest GE operations scores) reflect genuine model limitations or uneven question quality or sampling.
Authors: The questions were assembled from primary sources—standard MRI physics textbooks, official GE scanner manuals, programming course materials, and expert-generated items by contributors with direct MRI research and GE operations experience. However, the initial submission did not report formal validation steps such as inter-rater reliability among contributors or systematic domain-coverage audits. We will revise the Methods section to describe the curation workflow in detail, including the expert review process for factual accuracy, steps taken to ensure balanced coverage across the nine categories and three difficulty tiers, and any available agreement metrics from the contributor panel. The consistent pattern of lowest GE operations performance across every model family supports our interpretation that these differences reflect model limitations rather than sampling artifacts, but we agree that greater transparency on question quality is necessary and have incorporated this information. revision: yes
Circularity Check
No circularity: empirical benchmark with direct testing against external questions
full rationale
This is a purely empirical benchmark paper that constructs 1365 questions from external sources (textbooks, GE manuals, programming materials, expert generation) and reports model performance on MCQ, stem-only, and primed conditions. No equations, derivations, fitted parameters, or self-citations appear in the load-bearing claims. The stem-only evaluation uses an independent LLM judge, but this is a methodological choice whose validity is not derived from or reduced to the paper's own results by construction; it is simply applied to the held-out responses. The central observation (MCQ accuracy 93–97% vs. stem-only 37–61%) follows directly from the tabulated test outcomes rather than any self-referential loop. Per the hard rules, absence of quoted reductions to inputs means the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Clément Christophe, Wadood Mohammed Abdul, Prateek Munjal, Tatha- gata Raha, Ronnie Rajan, and Praveenkumar Kanithi. Overalignment in Frontier LLMs: An Empirical Study of Sycophantic Behaviour in Health- care, January 2026. arXiv:2601.18334 [cs] version: 1
-
[2]
A Coefficient of Agreement for Nominal Scales
Jacob Cohen. A Coefficient of Agreement for Nominal Scales. Educational and Psychological Measurement , 20(1):37–46, April 1960
1960
-
[3]
Hashemi, Christopher J
Ray H. Hashemi, Christopher J. Lisanti, and William G. Bradley. MRI: The Basics. Wolters Kluwer, Philadelphia, PA, fourth edition. edition, 2017
2017
-
[4]
SIGNA Works User Manual
GE Healthcare. SIGNA Works User Manual. Technical Report 5931644- 1EN, GE Healthcare, Chicago, IL, USA, 2023. Revision: 1 Language: US English CE: 0197
2023
-
[5]
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams. Applied Sciences, 11(14):6421, January 2021
2021
-
[6]
PubMedQA: A Dataset for Biomedical Research Question Answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. PubMedQA: A Dataset for Biomedical Research Question Answering. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, Pro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Lan- guage ...
2019
- [7]
-
[8]
Note on the sampling error of the difference between correlated proportions or percentages
Quinn McNemar. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika, 12(2):153–157, June 1947
1947
-
[9]
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Med- ical domain Question Answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Med- ical domain Question Answering. In Proceedings of the Conference on Health, Inference, and Learning , pages 248–260. PMLR, April 2022
2022
-
[10]
Bow- man
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bow- man. GPQA: A Graduate-Level Google-Proof Q&A Benchmark, November
-
[11]
arXiv:2311.12022 [cs]
work page internal anchor Pith review arXiv
-
[12]
Faulkner
Carolyn Kaut Roth and William H. Faulkner. Review questions for MRI . Wiley, Hoboken, second edition. edition, 2013
2013
-
[13]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark, November 2024. arXiv:2406.01574 [cs]
work page internal anchor Pith review arXiv 2024
-
[14]
MRI in practice
Catherine Westbrook and John Talbot. MRI in practice . John Wiley & Sons, Inc., Hoboken, NJ, fifth edition. edition, 2018
2018
-
[15]
Edwin B. Wilson. Probable Inference, the Law of Succes- sion, and Statistical Inference. Journal of the American Sta- tistical Association , 22(158):209–212, June 1927. _eprint: https://www.tandfonline.com/doi/pdf/10.1080/01621459.1927.10502953
-
[16]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs Express Their Uncertainty? An Empirical Eval- uation of Confidence Elicitation in LLMs, March 2024. arXiv:2306.13063 [cs]. Appendix A. Complete Pairwise Statistical Comparisons The main text reports three of the six category-level pairwise comparisons that reached P...
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.