Recognition: 2 theorem links
· Lean TheoremAdaGATE: Adaptive Gap-Aware Token-Efficient Evidence Assembly for Multi-Hop Retrieval-Augmented Generation
Pith reviewed 2026-05-08 19:04 UTC · model grok-4.3
The pith
AdaGATE improves multi-hop RAG by treating evidence assembly as a gap-repair task that tracks missing bridge facts and selects tokens-efficiently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
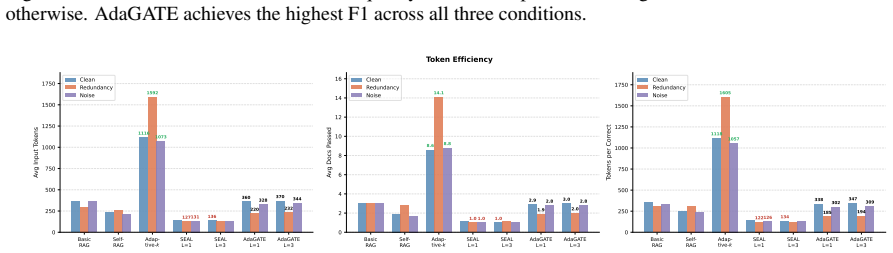
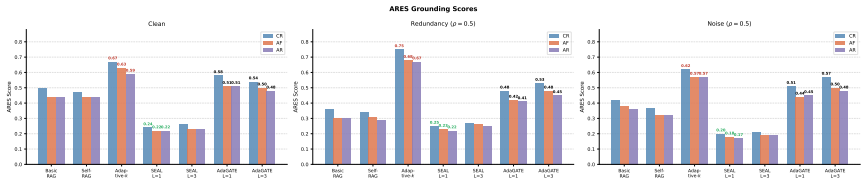
AdaGATE frames evidence selection as a token-constrained repair problem that combines entity-centric gap tracking, targeted micro-query generation, and a utility-based selection mechanism balancing gap coverage, corroboration, novelty, redundancy, and direct question relevance. On HotpotQA it achieves the best evidence F1 of 62.3 percent on clean data and 71.2 percent under redundancy injection while using 2.6 times fewer input tokens than Adaptive-k.
What carries the argument
Entity-centric gap tracking paired with utility-based selection that scores candidate passages for how well they close identified missing facts without adding redundancy or exceeding the token budget.
If this is right
- Multi-hop RAG can maintain high evidence quality even when retrievers return many overlapping documents.
- Token budgets can be tightened substantially without losing performance on bridge-fact questions.
- Training-free controllers that explicitly repair gaps outperform additive or fixed top-k selection under imperfect retrieval.
- Explicit gap tracking allows the system to focus new retrieval on precisely the missing facts rather than re-querying the whole question.
Where Pith is reading between the lines
- The same gap-repair logic could be applied to other chain-of-thought or reasoning pipelines where intermediate facts are missing.
- If entity tracking proves robust, future systems might reduce the size or frequency of full-document retrievals.
- The utility balancing approach might transfer to other constrained selection tasks such as summarization or dialogue response generation.
Load-bearing premise
That a single utility function can reliably weigh gap coverage against redundancy, novelty, and relevance without task-specific tuning or perfectly accurate entity identification in noisy text.
What would settle it
On a held-out multi-hop dataset with heavy redundancy or entity noise, run AdaGATE and the strongest baseline; if AdaGATE's evidence F1 falls below the baseline or its token savings disappear while gap-tracking components are ablated, the repair framing does not hold.
Figures


read the original abstract
Retrieval-augmented generation (RAG) remains brittle on multi-hop questions in realistic deployment settings, where retrieved evidence may be noisy or redundant and only limited context can be passed to the generator. Existing controllers address parts of this problem, but typically either expand context additively, select from a fixed top-k set, or optimize relevance without explicitly repairing missing bridge facts. We propose AdaGATE, a training-free evidence controller for multi-hop RAG that frames evidence selection as a token-constrained repair problem. AdaGATE combines entity centric gap tracking, targeted micro-query generation, and a utility based selection mechanism that balances gap coverage, corroboration, novelty, redundancy, and direct question relevance. We evaluate AdaGATE on HotpotQA under clean, redundancy, and noise injected retrieval conditions. Across all three settings, AdaGATE achieves the best evidence F1 among the compared controllers, reaching 62.3% on clean data and 71.2% under redundancy injection, while using 2.6x fewer input tokens than Adaptive-k. These results suggest that explicit gap-aware repair, combined with token-efficient evidence selection, improves robustness in multi-hop RAG under imperfect retrieval. Our code and evaluation pipeline are available at https://github.com/eliguo/AdaGATE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaGATE, a training-free evidence controller for multi-hop RAG that frames selection as a token-constrained repair problem. It combines entity-centric gap tracking, targeted micro-query generation, and a utility-based selection mechanism balancing gap coverage, corroboration, novelty, redundancy, and relevance. On HotpotQA under clean, redundancy-injected, and noise-injected retrieval, AdaGATE reports the highest evidence F1 (62.3% clean, 71.2% redundancy) and 2.6x fewer tokens than Adaptive-k, claiming improved robustness under imperfect retrieval. Code is released.
Significance. If the results hold, AdaGATE offers a practical training-free approach to evidence assembly that could reduce context length while improving coverage in multi-hop RAG. The explicit gap-repair framing and token-efficiency focus address real deployment constraints. Releasing code and the evaluation pipeline strengthens potential impact and reproducibility.
major comments (3)
- [Abstract] Abstract and Experiments section: the central claim that AdaGATE 'improves robustness in multi-hop RAG under imperfect retrieval' rests on evidence F1 and token counts alone. No downstream QA metrics (answer EM, answer F1, or generation quality) are reported, so it remains untested whether the higher evidence F1 actually produces better multi-hop answers from the generator.
- [Experiments] Experiments section: baseline implementations (Adaptive-k and other controllers) lack details on exact retrieval protocols, hyperparameter settings, statistical tests, or whether post-hoc choices were made in evaluation. This makes the reported 2.6x token savings and F1 gains difficult to interpret or reproduce.
- [Method] Method section: the utility-based selection is presented as reliably balancing five factors without task-specific tuning, yet no ablation studies, sensitivity analysis, or failure-case analysis are provided to substantiate that the entity-centric gap tracking works under noisy or redundant retrieval.
minor comments (1)
- [Abstract] The abstract states results 'across all three settings' but does not define the exact noise-injection or redundancy-injection procedures; these should be specified in the main text or appendix for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript would be strengthened by including downstream QA metrics, expanded experimental details for reproducibility, and ablation studies. We address each major comment point by point below and will incorporate the suggested revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the central claim that AdaGATE 'improves robustness in multi-hop RAG under imperfect retrieval' rests on evidence F1 and token counts alone. No downstream QA metrics (answer EM, answer F1, or generation quality) are reported, so it remains untested whether the higher evidence F1 actually produces better multi-hop answers from the generator.
Authors: We agree that downstream QA metrics would provide stronger validation of the end-to-end benefit. The current evaluation centers on evidence F1 because AdaGATE is an evidence controller whose direct output is the selected evidence set, and F1 measures coverage of the bridge facts required for multi-hop questions. To address the gap, we will add experiments in the revised manuscript that feed the evidence selected by each controller into a fixed generator (e.g., GPT-3.5-turbo) and report answer EM and answer F1 under the clean, redundancy-injected, and noise-injected conditions. This will test whether the observed evidence F1 gains translate to improved answer quality. revision: yes
-
Referee: [Experiments] Experiments section: baseline implementations (Adaptive-k and other controllers) lack details on exact retrieval protocols, hyperparameter settings, statistical tests, or whether post-hoc choices were made in evaluation. This makes the reported 2.6x token savings and F1 gains difficult to interpret or reproduce.
Authors: The referee correctly identifies that the original Experiments section omitted several implementation details. In the revision we will expand this section to specify: (1) the exact retrieval protocol, including the retriever (e.g., DPR or BM25) and how the initial candidate pool is constructed for each condition; (2) all hyperparameter values used for AdaGATE and every baseline, including Adaptive-k; (3) the number of runs, standard deviations, and statistical tests (paired t-tests with p-values); and (4) an explicit statement that all evaluation decisions were fixed before running the experiments with no post-hoc selection. The released code and evaluation pipeline will be updated to allow exact reproduction of the reported token counts and F1 scores. revision: yes
-
Referee: [Method] Method section: the utility-based selection is presented as reliably balancing five factors without task-specific tuning, yet no ablation studies, sensitivity analysis, or failure-case analysis are provided to substantiate that the entity-centric gap tracking works under noisy or redundant retrieval.
Authors: We acknowledge that the absence of ablations leaves the robustness claims less substantiated. The utility function was designed to balance gap coverage, corroboration, novelty, redundancy, and relevance in a single scoring step without per-task retuning, but we did not include component-wise ablations in the submitted version. In the revised manuscript we will add a dedicated subsection with: (1) ablation results for each utility term under all three retrieval conditions, (2) sensitivity analysis varying the relative weights of the five factors, and (3) qualitative failure-case analysis highlighting examples where entity-centric gap tracking succeeds or breaks under noise. These additions will directly address the referee's concern about substantiating the method's behavior. revision: yes
Circularity Check
No circularity: training-free method with direct empirical measurements
full rationale
The paper introduces AdaGATE as a training-free controller using entity-centric gap tracking, micro-query generation, and utility-based selection to balance coverage, novelty, and relevance. All reported results consist of direct evidence F1 measurements and token counts on HotpotQA under clean, redundant, and noisy retrieval settings, compared against external baselines. No equations define outputs in terms of the method's own fitted parameters, no predictions are constructed from self-derived inputs, and no load-bearing self-citations or uniqueness theorems are invoked. The derivation chain is self-contained as an algorithmic proposal validated by external benchmarks rather than reducing to its own definitions or fits.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
St(c) = λ1 GapCov(c, Gt) + λ2 Corr(c, Ut) + λ3 Nov(c, Ut) − λ4 Red(c, Et) + λ5 RelQ(c, q)
-
IndisputableMonolith.Foundation.AlphaCoordinateFixationJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The utility weights (λ1, . . . , λ5) were set heuristically and could be learned from supervision.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
2023 , eprint =
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author =. 2023 , eprint =
2023
-
[2]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
Florin Cuconasu and Giovanni Trappolini and Federico Siciliano and Simone Filice and Cesare Campagnano and Yoelle Maarek and Nicola Tonellotto and Fabrizio Silvestri , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , year =
-
[3]
2024 , address =
Shahul Es and Jithin James and Luis Espinosa Anke and Steven Schockaert , booktitle =. 2024 , address =
2024
-
[4]
A Survey on
Wenqi Fan and Yujuan Ding and Liangbo Ning and Shijie Wang and Hengyun Li and Dawei Yin and Tat. A Survey on. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , year =
-
[5]
2024 , eprint =
LightRAG: Simple and Fast Retrieval-Augmented Generation , author =. 2024 , eprint =
2024
-
[6]
2024 , eprint =
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity , author =. 2024 , eprint =
2024
-
[7]
2025 , eprint =
Replace, Don't Expand: Mitigating Context Dilution in Multi-Hop RAG via Fixed-Budget Evidence Assembly , author =. 2025 , eprint =
2025
-
[8]
Retrieval-Augmented Generation or Long-Context
Zhuowan Li and others , booktitle =. Retrieval-Augmented Generation or Long-Context. 2024 , note =
2024
-
[9]
2023 , eprint =
Lost in the Middle: How Language Models Use Long Contexts , author =. 2023 , eprint =
2023
-
[10]
2025 , eprint =
AdaGReS: Adaptive Greedy Context Selection via Redundancy-Aware Scoring for Token-Budgeted RAG , author =. 2025 , eprint =
2025
-
[11]
2023 , eprint =
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems , author =. 2023 , eprint =
2023
-
[12]
2025 , eprint =
Efficient Context Selection for Long-Context QA: No Tuning, No Iteration, Just Adaptive-k , author =. 2025 , eprint =
2025
-
[13]
2025 , eprint =
Knowing When to Stop: Dynamic Context Cutoff for Large Language Models , author =. 2025 , eprint =
2025
-
[14]
2024 , eprint =
Corrective Retrieval Augmented Generation , author =. 2024 , eprint =
2024
-
[15]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
2018
-
[16]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
Constructing Datasets for Multi-hop Reading Comprehension Across Documents , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
2018
-
[17]
Instruct
Zhepei Wei and Wei. Instruct. The Thirteenth International Conference on Learning Representations , year =
-
[18]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. https://arxiv.org/abs/2310.11511 Self-rag: Learning to retrieve, generate, and critique through self-reflection
work page internal anchor Pith review arXiv 2023
-
[19]
Florin Cuconasu, Giovanni Trappolini, Federico Siciliano, Simone Filice, Cesare Campagnano, Yoelle Maarek, Nicola Tonellotto, and Fabrizio Silvestri. 2024. https://doi.org/10.1145/3626772.3657834 The power of noise: Redefining retrieval for rag systems . In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Informati...
-
[20]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat - Seng Chua, and Qing Li. 2024. https://doi.org/10.1145/3637528.3671470 A survey on RAG meeting LLMs : Towards retrieval-augmented large language models . In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6491--6501, New York, NY, USA...
- [21]
- [22]
-
[23]
Lost in the Middle: How Language Models Use Long Contexts
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. https://arxiv.org/abs/2307.03172 Lost in the middle: How language models use long contexts
work page internal anchor Pith review arXiv 2023
- [24]
- [25]
- [26]
-
[27]
Johannes Welbl, Pontus Stenetorp, and Sebastian Riedel. 2018. Constructing datasets for multi-hop reading comprehension across documents. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1933--1943
2018
-
[28]
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. 2024. https://arxiv.org/abs/2401.15884 Corrective retrieval augmented generation
work page internal anchor Pith review arXiv 2024
-
[29]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.