Recognition: unknown
Bridging Generation and Training: A Systematic Review of Quality Issues in LLMs for Code
Pith reviewed 2026-05-08 17:33 UTC · model grok-4.3
The pith
Training data flaws propagate into LLM-generated code defects through 18 specific causal paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
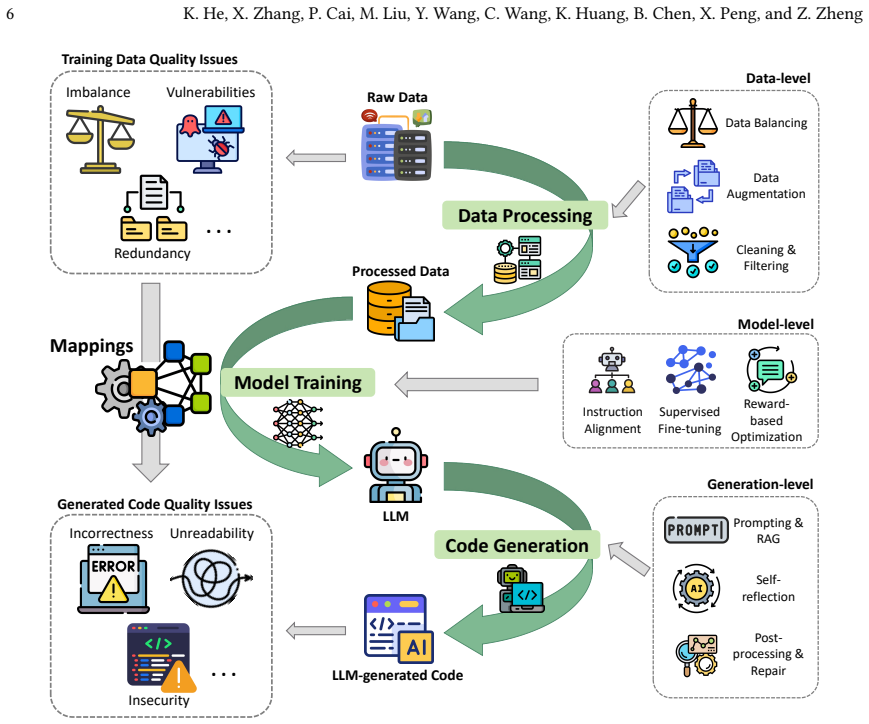
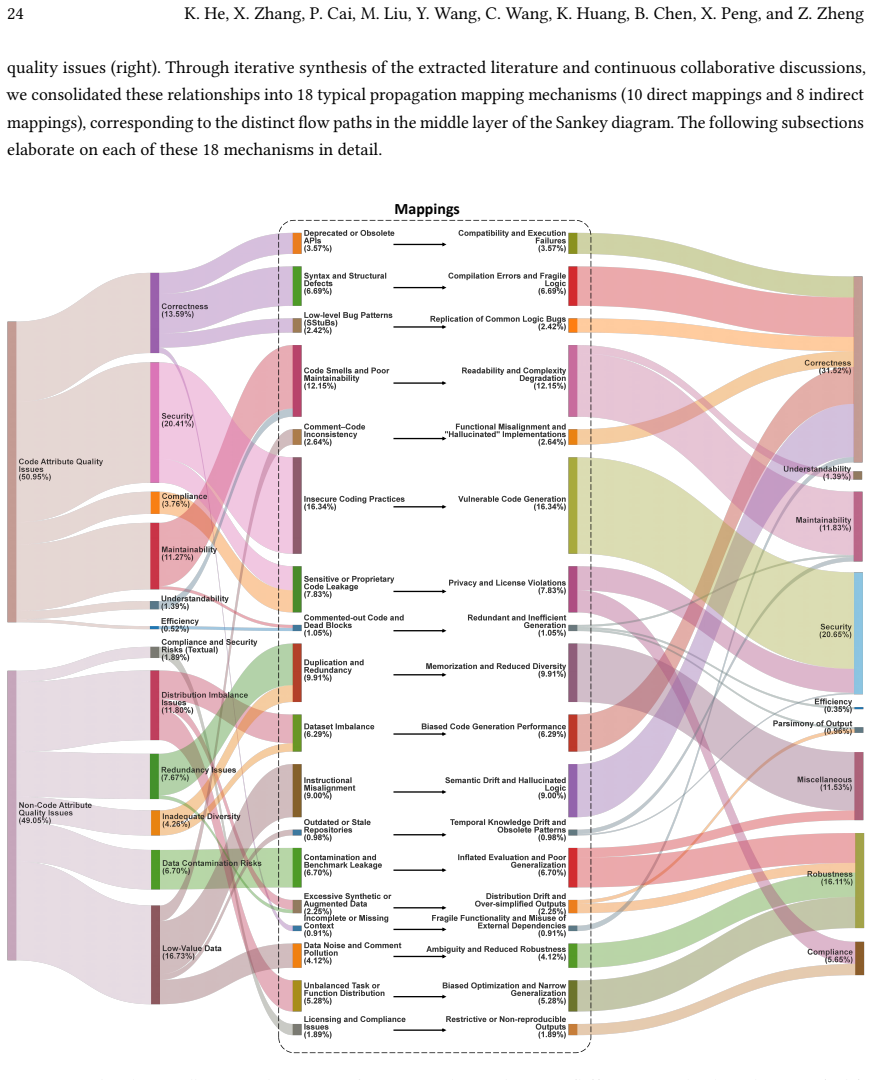
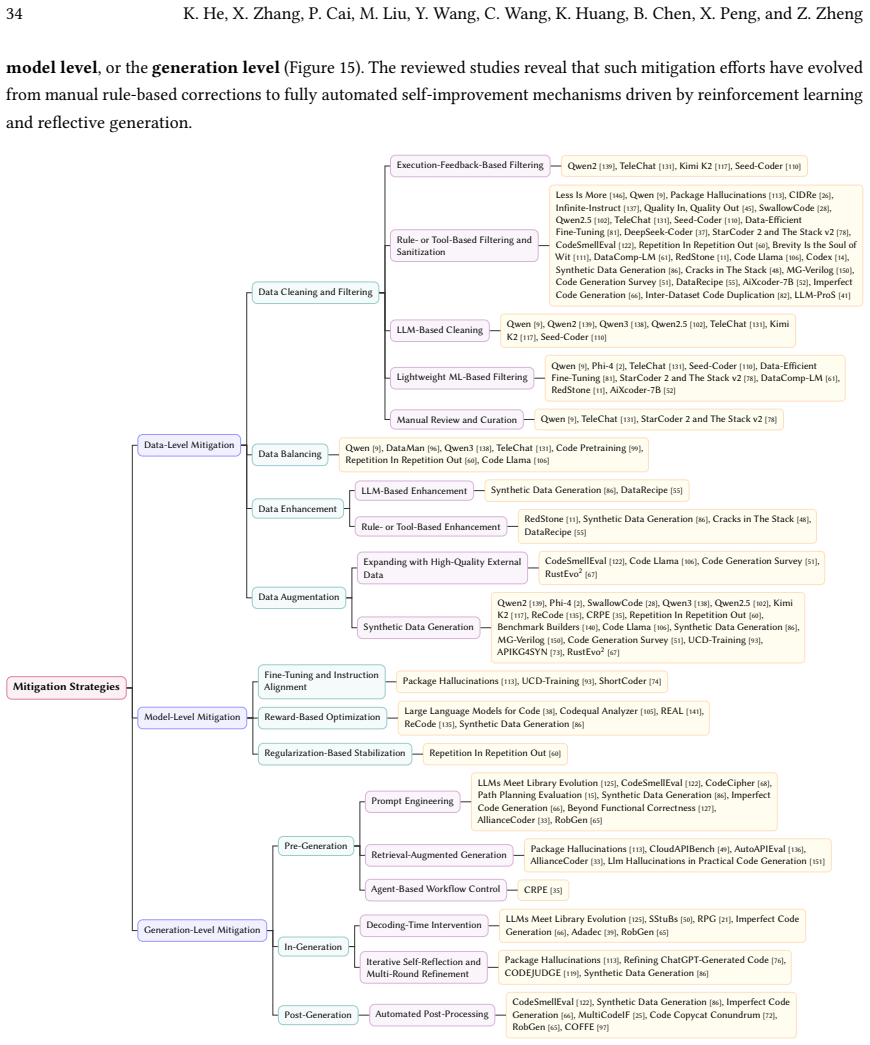
We establish a unified taxonomy that categorizes generated code quality issues across nine dimensions and training data quality issues into code and non-code attributes. Based on this taxonomy, we formalize a causal framework detailing 18 typical propagation mapping mechanisms. The reviewed literature reveals a clear methodological shift: quality assurance is transitioning from reactive, heuristic-based post-generation filtering toward proactive, data-centric governance and closed-loop repair.
What carries the argument
The causal framework that details 18 propagation mapping mechanisms linking training data quality issues to generated code quality issues.
If this is right
- Detection and mitigation of quality issues can occur at the data curation stage, the model training stage, or during generation rather than only after output.
- Quality assurance practices move from reactive filtering of bad outputs to proactive governance of training data and closed-loop repair systems.
- Integrated approaches combining data curation with continuous evaluation support the development of more reliable LLMs for code.
- Open challenges remain in fully addressing all identified propagation paths and in scaling the taxonomy to new model architectures.
Where Pith is reading between the lines
- The taxonomy offers a checklist that practitioners could apply when auditing existing training datasets to flag risks before model training begins.
- The 18 mechanisms provide a basis for building predictive tools that estimate the likelihood of specific code defects given measurable properties of the training data.
- The framework could generalize beyond code to other structured generation tasks where data quality directly affects output correctness.
Load-bearing premise
The 114 primary studies selected for the review comprehensively and without significant bias represent the mechanisms by which training data quality issues propagate to generated code quality issues.
What would settle it
A controlled study that produces LLM-generated code defects whose root causes cannot be mapped to any of the 18 propagation mechanisms or to the defined categories of training data quality issues.
Figures












read the original abstract
Large language models (LLMs) frequently generate defective outputs in code generation tasks, ranging from logical bugs to security vulnerabilities. While these generation failures are often treated as model-level limitations, empirical evidence increasingly traces their root causes to imperfections within the training corpora. Yet, the specific mechanisms linking training data quality issues to generated code quality issues remain largely unmapped. This paper presents a systematic literature review of 114 primary studies to investigate how training data quality issues propagate into code generation. We establish a unified taxonomy that categorizes generated code quality issues across nine dimensions and training data quality issues into code and non-code attributes. Based on this taxonomy, we formalize a causal framework detailing 18 typical propagation mapping mechanisms. Furthermore, we synthesize state-of-the-art detection and mitigation techniques across the data, model, and generation lifecycles. The reviewed literature reveals a clear methodological shift: quality assurance is transitioning from reactive, heuristic-based post-generation filtering toward proactive, data-centric governance and closed-loop repair. Finally, we identify open challenges and outline research directions for developing reliable LLMs for code through integrated data curation and continuous evaluation. Our repository is available at https://github.com/SYSUSELab/From-Data-to-Code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper conducts a systematic literature review of 114 primary studies to examine how training data quality issues propagate into code generation quality issues in large language models. It constructs a unified taxonomy that organizes generated code quality issues along nine dimensions and training data quality issues into code and non-code attributes, then derives a causal framework consisting of 18 typical propagation mapping mechanisms. The review also synthesizes detection and mitigation techniques across the data, model, and generation stages, documents a shift toward proactive data-centric quality assurance, and identifies open challenges and research directions, with an accompanying public repository.
Significance. If the synthesized taxonomy and mappings accurately reflect the literature, the paper offers a useful organizational contribution that consolidates disparate findings on LLM code quality into a single framework. This can help researchers trace root causes from training data to generation failures and prioritize data governance over post-hoc fixes. The public repository supports reproducibility and further extension of the review.
major comments (1)
- [§3] §3 (Methodology): The review reports selecting 114 primary studies but provides only a high-level summary of the search strategy, inclusion criteria, and screening process. Explicit details on database queries, exact inclusion/exclusion rules, and any inter-rater reliability statistics are needed to evaluate selection bias and confirm that the taxonomy and 18 mappings comprehensively represent the literature without significant omissions.
minor comments (4)
- [§4.1] §4.1 and Figure 2: The nine dimensions of the generated code quality taxonomy are described narratively; an explicit summary table listing each dimension with a concise definition and one or two representative examples from the reviewed studies would improve clarity and usability.
- [§5] §5 (Causal framework): The 18 propagation mappings are labeled as 'causal' yet derived from observational literature; adding a short discussion of the correlational versus causal nature of the evidence and any noted confounding factors would strengthen the framework's interpretation.
- [§6] Repository and §6: The GitHub link is provided, but the paper should state precisely which artifacts (full study list, taxonomy codes, mapping details) are included and confirm they remain accessible.
- Throughout: Terminology is generally consistent, but ensure 'causal framework' is used uniformly with the qualifier 'typical propagation mapping mechanisms' to avoid implying primary causal inference.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our systematic review and for the constructive suggestion to strengthen the methodological transparency. We agree that additional details will improve the paper's reproducibility and allow better evaluation of the taxonomy and mappings. We will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Methodology): The review reports selecting 114 primary studies but provides only a high-level summary of the search strategy, inclusion criteria, and screening process. Explicit details on database queries, exact inclusion/exclusion rules, and any inter-rater reliability statistics are needed to evaluate selection bias and confirm that the taxonomy and 18 mappings comprehensively represent the literature without significant omissions.
Authors: We thank the referee for this observation. While §3 currently summarizes the overall search strategy, inclusion criteria, and screening process at a high level to preserve readability, we acknowledge that explicit details are required for rigorous assessment of selection bias and coverage. In the revised version, we will expand §3 to include: (1) the exact search strings and queries executed across each database (e.g., IEEE Xplore, ACM Digital Library, arXiv, Scopus); (2) the complete, itemized inclusion and exclusion criteria with justifications; (3) a detailed PRISMA-style flow diagram showing the number of papers at each screening stage; and (4) inter-rater reliability statistics (Cohen's kappa or equivalent) for the independent screening and data extraction phases performed by the authors. These additions will be placed in §3 and, where appropriate, referenced in the repository. We believe this will fully address the concern while maintaining the paper's focus on the synthesized taxonomies and propagation mechanisms. revision: yes
Circularity Check
No significant circularity
full rationale
This paper is a systematic literature review that synthesizes external primary studies (114 papers) to construct a taxonomy of code quality issues and a causal framework of propagation mappings. No internal equations, fitted parameters, self-definitional loops, or load-bearing self-citations exist; the taxonomy and 18 mappings are presented as observed patterns from the reviewed literature rather than derived by construction from the paper's own inputs. The methodology is standard for reviews and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 114 primary studies form a representative sample of research on training data and generated code quality issues in LLMs
Reference graph
Works this paper leans on
- [1]
-
[2]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J. Hewett, Mojan Javaheripi, Piero Kauffmann, James R. Lee, Yin Tat Lee, Yuanzhi Li, Weishung Liu, Caio C. T. Mendes, Anh Nguyen, Eric Price, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Xin Wang, Rachel Ward, Yue Wu, Dingli Yu,...
work page internal anchor Pith review arXiv 2024
- [3]
-
[4]
Barr, Premkumar Devanbu, and Charles Sut- ton
Miltiadis Allamanis, Earl T. Barr, Premkumar Devanbu, and Charles Sutton. 2018. A Survey of Machine Learning for Big Code and Naturalness. arXiv:1709.06182 [cs.SE] https://arxiv.org/abs/1709.06182
- [5]
- [6]
- [7]
-
[8]
Abdul Awal, Mrigank Rochan, and Chanchal K
Md. Abdul Awal, Mrigank Rochan, and Chanchal K. Roy. 2025. Large Language Models as Robust Data Generators in Software Analytics: Are We There Yet? arXiv:2411.10565 [cs.SE] https://arxiv.org/abs/2411.10565
-
[9]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review arXiv 2023
-
[10]
Manish Bhatt, Sahana Chennabasappa, Cyrus Nikolaidis, Shengye Wan, Ivan Evtimov, Dominik Gabi, Daniel Song, Faizan Ahmad, Cornelius Aschermann, Lorenzo Fontana, Sasha Frolov, Ravi Prakash Giri, Dhaval Kapil, Yiannis Kozyrakis, David LeBlanc, James Milazzo, Aleksandar Straumann, Gabriel Synnaeve, Varun Vontimitta, Spencer Whitman, and Joshua Saxe. 2023. Pu...
-
[11]
Yaoyao Chang, Lei Cui, Li Dong, Shaohan Huang, Yangyu Huang, Yupan Huang, Scarlett Li, Tengchao Lv, Shuming Ma, Qinzheng Sun, Wenhui Wang, Furu Wei, Ying Xin, Mao Yang, Qiufeng Yin, and Xingxing Zhang. 2024. RedStone: Curating General, Code, Math, and QA Data for Large Language Models. arXiv:2412.03398 [cs.CL] https://arxiv.org/abs/2412.03398
-
[12]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. 2024. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology15, 3 (2024), 1–45
2024
- [13]
-
[14]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
- [15]
-
[16]
Zhengyu Chen, Siqi Wang, Teng Xiao, Yudong Wang, Shiqi Chen, Xunliang Cai, Junxian He, and Jingang Wang. 2025. Revisiting Scaling Laws for Language Models: The Role of Data Quality and Training Strategies. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekateri...
- [17]
- [18]
-
[19]
Codefuse, Ling Team, :, Wenting Cai, Yuchen Cao, Chaoyu Chen, Chen Chen, Siba Chen, Qing Cui, Peng Di, Junpeng Fang, Zi Gong, Ting Guo, Zhengyu He, Yang Huang, Cong Li, Jianguo Li, Zheng Li, Shijie Lian, BingChang Liu, Songshan Luo, Shuo Mao, Min Shen, Jian Wu, Jiaolong Yang, Wenjie Yang, Tong Ye, Hang Yu, Wei Zhang, Zhenduo Zhang, Hailin Zhao, Xunjin Zhe...
- [20]
- [21]
- [22]
-
[23]
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2024. Evaluating Large Language Models in Class-Level Code Generation. In2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). 982–994. https://doi.org/10.1145/3597503.3639219
- [24]
- [25]
- [26]
-
[27]
Zhiyu Fan, Xiang Gao, Martin Mirchev, Abhik Roychoudhury, and Shin Hwei Tan. 2023. Automated repair of programs from large language models. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 1469–1481
2023
-
[28]
Kazuki Fujii, Yukito Tajima, Sakae Mizuki, Hinari Shimada, Taihei Shiotani, Koshiro Saito, Masanari Ohi, Masaki Kawamura, Taishi Nakamura, Takumi Okamoto, Shigeki Ishida, Kakeru Hattori, Youmi Ma, Hiroya Takamura, Rio Yokota, and Naoaki Okazaki. 2025. Rewriting Pre-Training Data Boosts LLM Performance in Math and Code. arXiv:2505.02881 [cs.LG] https://arx...
- [29]
-
[30]
Jiahui Geng, Fengyu Cai, Shaobo Cui, Qing Li, Liangwei Chen, Chenyang Lyu, Haonan Li, Derui Zhu, Walter Pretschner, Heinz Koeppl, and Fakhri Karray. 2025. CoQuIR: A Comprehensive Benchmark for Code Quality-Aware Information Retrieval. arXiv:2506.11066 [cs.SE] https: //arxiv.org/abs/2506.11066
-
[31]
Mingyang Geng, Shangwen Wang, Dezun Dong, Haotian Wang, Ge Li, Zhi Jin, Xiaoguang Mao, and Xiangke Liao. 2024. Large language models are few-shot summarizers: Multi-intent comment generation via in-context learning. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering. 1–13
2024
-
[32]
Olausson, Celine Lee, Koushik Sen, and Armando Solar-Lezama
Alex Gu, Wen-Ding Li, Naman Jain, Theo X. Olausson, Celine Lee, Koushik Sen, and Armando Solar-Lezama. 2024. The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations? arXiv:2402.19475 [cs.SE] https://arxiv.org/abs/2402.19475
- [33]
- [34]
- [35]
-
[36]
Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuanzhi Li. 2023. Textbooks Are All You Need. arXiv:2306.11644 [...
work page internal anchor Pith review arXiv 2023
-
[37]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wen- feng Liang. 2024. DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence. arXiv:2401.14196 [cs.SE] https://arxiv.org/abs/2401.14196
work page internal anchor Pith review arXiv 2024
-
[38]
Jingxuan He and Martin Vechev. 2023. Large Language Models for Code: Security Hardening and Adversarial Testing. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security(Copenhagen, Denmark)(CCS ’23). Association for Computing Machinery, New York, NY, USA, 1865–1879. https://doi.org/10.1145/3576915.3623175
-
[39]
Kaifeng He, Mingwei Liu, Chong Wang, Zike Li, Yanlin Wang, Xin Peng, and Zibin Zheng. 2026. Towards Better Code Generation: Adaptive Decoding with Uncertainty Guidance. arXiv:2506.08980 [cs.SE] https://arxiv.org/abs/2506.08980 Manuscript submitted to ACM 44 K. He, X. Zhang, P. Cai, M. Liu, Y. Wang, C. Wang, K. Huang, B. Chen, X. Peng, and Z. Zheng
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [40]
-
[41]
Fahim Arefin, and Tarannum Shaila Zaman
Md Sifat Hossain, Anika Tabassum, Md. Fahim Arefin, and Tarannum Shaila Zaman. 2025. LLM-ProS: Analyzing Large Language Models’ Performance in Competitive Problem Solving. In2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 80–87. https://doi.org/10.1109/llm4code66737.2025.00015
-
[42]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
- [43]
- [44]
- [45]
-
[46]
International Organization for Standardization. 2023. Systems and software engineering — Systems and software Quality Requirements and Evaluation (SQuaRE) — Product quality model. ISO/IEC 25010:2023
2023
-
[47]
Maliheh Izadi, Jonathan Katzy, Tim Van Dam, Marc Otten, Razvan Mihai Popescu, and Arie Van Deursen. 2024. Language models for code completion: A practical evaluation. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[48]
Mahmoud Jahanshahi and Audris Mockus. 2025. Cracks in The Stack: Hidden Vulnerabilities and Licensing Risks in LLM Pre-Training Datasets. In 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code). IEEE, 104–111. https://doi.org/10.1109/llm4code66737. 2025.00018
- [49]
-
[50]
Kevin Jesse, Toufique Ahmed, Premkumar T. Devanbu, and Emily Morgan. 2023. Large Language Models and Simple, Stupid Bugs. arXiv:2303.11455 [cs.SE] https://arxiv.org/abs/2303.11455
-
[51]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A Survey on Large Language Models for Code Generation.ACM Transactions on Software Engineering and Methodology35, 2 (Jan. 2026), 1–72. https://doi.org/10.1145/3747588
-
[52]
Siyuan Jiang, Jia Li, He Zong, Huanyu Liu, Hao Zhu, Shukai Hu, Erlu Li, Jiazheng Ding, Yu Han, Wei Ning, Gen Wang, Yihong Dong, Kechi Zhang, and Ge Li. 2025. aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Processing. arXiv:2410.13187 [cs.CL] https://arxiv.org/abs/2410.13187
- [53]
- [54]
-
[55]
Kisub Kim, Jounghoon Kim, Byeongjo Park, Dongsun Kim, Chun Yong Chong, Yuan Wang, Tiezhu Sun, Daniel Tang, Jacques Klein, and Tegawende F. Bissyande. 2024. DataRecipe — How to Cook the Data for CodeLLM?. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Ma...
-
[56]
2007.Guidelines for performing systematic literature reviews in software engineering
Barbara Kitchenham and Stuart Charters. 2007.Guidelines for performing systematic literature reviews in software engineering. Technical Report. Keele University and Durham University Joint Report, EBSE 2007-001
2007
- [57]
-
[58]
Triet HM Le, Hao Chen, and Muhammad Ali Babar. 2020. Deep learning for source code modeling and generation: Models, applications, and challenges.ACM Computing Surveys (CSUR)53, 3 (2020), 1–38
2020
- [59]
- [60]
-
[61]
Datacomp- LM : In search of the next generation of training sets for language models
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardn...
- [62]
-
[63]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Loge...
work page internal anchor Pith review arXiv 2023
- [64]
- [65]
-
[66]
Xiaoli Lian, Shuaisong Wang, Jieping Ma, Xin Tan, Fang Liu, Lin Shi, Cuiyun Gao, and Li Zhang. 2024. Imperfect Code Generation: Uncovering Weaknesses in Automatic Code Generation by Large Language Models. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings(Lisbon, Portugal)(ICSE-Companion ’24). A...
- [67]
- [68]
- [69]
- [70]
-
[71]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. arXiv:2305.01210 [cs.SE] https://arxiv.org/abs/2305.01210
work page internal anchor Pith review arXiv 2023
-
[72]
Mingwei Liu, Juntao Li, Ying Wang, Xueying Du, Zuoyu Ou, Qiuyuan Chen, Bingxu An, Zhao Wei, Yong Xu, Fangming Zou, Xin Peng, and Yiling Lou
-
[73]
Code Copycat Conundrum: Demystifying Repetition in LLM-based Code Generation. arXiv:2504.12608 [cs.SE] https://arxiv.org/abs/2504.12608
-
[74]
Mingwei Liu, Zheng Pei, Yanlin Wang, Zihao Wang, Zikang Li, Enci Lin, Xin Peng, and Zibin Zheng. 2025. Framework-Aware Code Generation with API Knowledge Graph-Constructed Data: A Study on HarmonyOS. arXiv:2512.00380 [cs.SE] https://arxiv.org/abs/2512.00380
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [75]
- [76]
-
[77]
Refining ChatGPT- Generated Code: Characterizing and Mitigating Code Quality Issues
Yue Liu, Thanh Le-Cong, Ratnadira Widyasari, Chakkrit Tantithamthavorn, Li Li, Xuan-Bach D. Le, and David Lo. 2023. Refining ChatGPT-Generated Code: Characterizing and Mitigating Code Quality Issues. arXiv:2307.12596 [cs.SE] https://arxiv.org/abs/2307.12596
- [78]
-
[79]
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Z...
work page internal anchor Pith review arXiv 2024
-
[80]
Junyu Luo, Bohan Wu, Xiao Luo, Zhiping Xiao, Yiqiao Jin, Rong-Cheng Tu, Nan Yin, Yifan Wang, Jingyang Yuan, Wei Ju, and Ming Zhang. 2025. A Survey on Efficient Large Language Model Training: From Data-centric Perspectives. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Com...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.