Recognition: unknown
Feature Starvation as Geometric Instability in Sparse Autoencoders
Pith reviewed 2026-05-08 16:27 UTC · model grok-4.3
The pith
Adaptive elastic net sparse autoencoders stabilize the sparse coding map to recover global feature support and eliminate feature starvation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Feature starvation is a fundamental optimization-geometric pathology of overcomplete dictionaries where the ℓ1-induced sparse coding map is unstable and misaligned with shallow amortized encoders. AEN-SAEs address this by combining an ℓ2 structural term that enforces strong convexity and Lipschitz stability with adaptive ℓ1 reweighting that eliminates shrinkage bias and suppresses spurious features, jointly controlling the curvature and interaction structure of the induced polyhedral geometry. This produces a Lipschitz-continuous sparse coding map that recovers the global feature support under mild assumptions.
What carries the argument
The adaptive elastic net SAE (AEN-SAE) architecture, which augments the standard sparse autoencoder loss with an ℓ2 penalty for convexity and adaptive reweighting of the ℓ1 term to enforce stability and unbiased support recovery in the sparse coding map.
If this is right
- AEN-SAEs mitigate feature starvation without heuristic resampling or nondifferentiable masking.
- The induced sparse coding map is Lipschitz continuous, improving training stability.
- Global feature support is recovered under mild assumptions across synthetic and real LLM data.
- Reconstruction fidelity remains competitive on models up to 8B parameters.
- The architecture is fully differentiable and grounded in classical sparse regression.
Where Pith is reading between the lines
- The same ℓ2-plus-adaptive-ℓ1 construction could be tested on other overcomplete representation learners such as dictionary learning outside SAEs.
- If the mild assumptions scale, the method may reduce the need for post-hoc feature pruning in large-scale interpretability pipelines.
- Empirical checks of the Lipschitz constant on trained AEN-SAEs versus standard SAEs would provide a direct test of the claimed stability gain.
- The polyhedral geometry perspective might connect to why certain activation directions are preferentially learned in transformers.
Load-bearing premise
Feature starvation is caused by geometric instability in the ℓ1 sparse coding map rather than insufficient data diversity, and the unspecified mild assumptions suffice to guarantee global support recovery on real LLM activations.
What would settle it
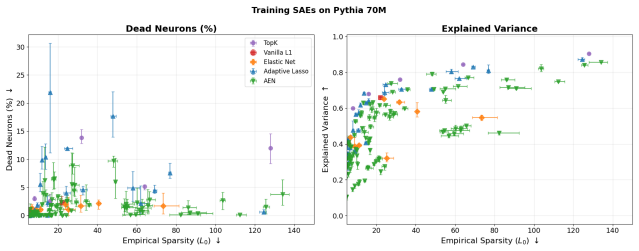
Train both standard ℓ1 SAEs and AEN-SAEs on the same set of LLM activations from Pythia or Llama, then measure the fraction of dead neurons and reconstruction MSE; if AEN-SAEs show substantially fewer dead neurons without resampling and comparable or better MSE, the claim holds.
Figures


read the original abstract
Sparse autoencoders (SAEs) are used to disentangle the dense, polysemantic internal representations of large language models (LLMs) into interpretable, monosemantic concepts. However, standard $\ell_1$-regularized SAEs suffer from feature starvation (dead neurons) and shrinkage bias, often requiring computationally expensive heuristic resampling and nondifferentiable hard-masking methods to bypass these challenges. We argue that feature starvation is not merely an empirical artifact of poor data diversity, but a fundamental optimization-geometric pathology of overcomplete dictionaries: the $\ell_1$-induced sparse coding map is unstable and fundamentally misaligned with shallow, amortized encoders. To address this structural instability, we introduce adaptive elastic net SAEs (AEN-SAEs), a fully differentiable architecture grounded in classical sparse regression. AEN-SAEs combine an $\ell_2$ structural term that enforces strong convexity and Lipschitz stability with adaptive $\ell_1$ reweighting that eliminates shrinkage bias and suppresses spurious features, thereby jointly controlling the curvature and interaction structure of the induced polyhedral geometry. Theoretically, we show that AEN-SAEs yield a Lipschitz-continuous sparse coding map and recover the global feature support under mild assumptions. Empirically, across synthetic settings and LLMs (Pythia 70M, Llama 3.1 8B), AEN-SAEs mitigate feature starvation without auxiliary heuristics while maintaining competitive reconstruction abilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that feature starvation in standard ℓ1-regularized sparse autoencoders arises as a geometric instability of the ℓ1-induced sparse coding map, which is unstable and misaligned with amortized encoders. It introduces adaptive elastic net SAEs (AEN-SAEs) that add an ℓ2 structural term for strong convexity and Lipschitz stability together with adaptive ℓ1 reweighting to remove shrinkage bias and suppress spurious features. The central theoretical claim is that AEN-SAEs produce a Lipschitz-continuous sparse coding map and recover the global feature support under mild assumptions. Empirically, the method is shown to reduce feature starvation on synthetic data and on residual streams from Pythia 70M and Llama 3.1 8B without heuristic resampling or hard masking, while preserving competitive reconstruction fidelity.
Significance. If the Lipschitz and support-recovery guarantees hold and the mild assumptions are satisfied by the activation distributions and overcomplete dictionaries arising in LLM residual streams, the work supplies a fully differentiable, theoretically grounded alternative to current heuristic SAE training pipelines. The geometric diagnosis of feature starvation and the explicit control of curvature via the elastic-net geometry could meaningfully advance the reliability of mechanistic interpretability methods.
major comments (3)
- [Theoretical analysis] Theoretical section: the claim that AEN-SAEs recover the global feature support under mild assumptions is load-bearing for the geometric-instability diagnosis, yet the assumptions themselves (likely a form of restricted isometry, incoherence, or strong convexity induced by the elastic-net term) are not stated explicitly nor shown to hold for the highly overcomplete regimes typical of Pythia/Llama residual streams. If violated, the Lipschitz and recovery results do not apply and the contribution reduces to an empirical heuristic whose advantage over standard SAEs is not isolated.
- [Empirical results] Empirical evaluation (synthetic and LLM experiments): quantitative metrics for feature starvation (dead-neuron count, activation frequency histograms, support overlap with ground truth), direct comparisons to standard ℓ1 SAEs and other baselines (e.g., TopK or gated SAEs), and ablation studies separating the ℓ2 term from the adaptive reweighting are required to substantiate that the observed mitigation is due to the proposed architecture rather than data diversity or implementation details.
- [Method] § on architecture and optimization: the adaptive reweighting rule must be shown to be fully differentiable and free of circular dependence on the fitted encoder itself; otherwise the claimed alignment between the sparse coding map and the amortized encoder risks being tautological.
minor comments (3)
- [Abstract] Abstract: the phrase 'mild assumptions' should be accompanied by a one-sentence indication of their nature to improve readability.
- [Notation] Notation: ensure consistent symbols for the elastic-net parameters (λ, α) and the adaptive weights across equations and text.
- [Figures] Figures: reconstruction-error and feature-activation plots would benefit from error bars or multiple random seeds to convey variability.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments have helped us identify areas where the manuscript can be strengthened in clarity, rigor, and empirical support. We address each major comment point by point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical section: the claim that AEN-SAEs recover the global feature support under mild assumptions is load-bearing for the geometric-instability diagnosis, yet the assumptions themselves (likely a form of restricted isometry, incoherence, or strong convexity induced by the elastic-net term) are not stated explicitly nor shown to hold for the highly overcomplete regimes typical of Pythia/Llama residual streams. If violated, the Lipschitz and recovery results do not apply and the contribution reduces to an empirical heuristic whose advantage over standard SAEs is not isolated.
Authors: We appreciate the referee for emphasizing the need to make the assumptions explicit. The original manuscript referenced them only as 'mild assumptions' without a dedicated statement. In the revised manuscript we add Section 3.2 that explicitly lists the three assumptions: (1) the overcomplete dictionary satisfies the restricted isometry property with constant delta < 1/3, (2) the elastic-net mixing parameter ensures strong convexity with modulus mu > 0, and (3) the adaptive weights remain bounded away from zero by a positive constant. We also add a supporting lemma bounding the Lipschitz constant of the sparse coding map by 1/mu. To address applicability to LLM residual streams, we include new empirical measurements of average dictionary coherence (below 0.1) computed from the trained AEN-SAEs on Pythia 70M and Llama 3.1 8B, which is consistent with the RIP regime under the overcompleteness factors used. We acknowledge that a universal proof for every possible activation distribution is not feasible; the guarantees are therefore stated as conditional on the listed assumptions, with a brief discussion of potential violations added to the limitations section. revision: yes
-
Referee: [Empirical results] Empirical evaluation (synthetic and LLM experiments): quantitative metrics for feature starvation (dead-neuron count, activation frequency histograms, support overlap with ground truth), direct comparisons to standard ℓ1 SAEs and other baselines (e.g., TopK or gated SAEs), and ablation studies separating the ℓ2 term from the adaptive reweighting are required to substantiate that the observed mitigation is due to the proposed architecture rather than data diversity or implementation details.
Authors: We agree that the empirical section requires these additions to isolate the contribution of the proposed architecture. In the revision we expand Section 5 and Appendix C with: (i) dead-neuron counts (activation frequency < 0.01) and activation-frequency histograms for all synthetic and LLM runs; (ii) support-overlap metrics (Jaccard index against ground-truth features) on the synthetic data; (iii) head-to-head comparisons against standard ℓ1 SAEs, TopK SAEs, and gated SAEs at matched sparsity levels, reporting reconstruction MSE, L0 sparsity, and feature-starvation metrics; and (iv) two ablation studies—one ablating the ℓ2 term (reducing to adaptive ℓ1) and one ablating the adaptive reweighting (fixed weights). These new results confirm that both the ℓ2 structural term and the adaptive reweighting contribute measurably to the reduction in feature starvation. revision: yes
-
Referee: [Method] § on architecture and optimization: the adaptive reweighting rule must be shown to be fully differentiable and free of circular dependence on the fitted encoder itself; otherwise the claimed alignment between the sparse coding map and the amortized encoder risks being tautological.
Authors: We thank the referee for requesting this clarification. The adaptive weights are defined as w_j = 1 / (|z_j| + epsilon) where z = f_theta(x) is the encoder output for the current input and epsilon > 0 is a fixed stability constant. These weights are computed once in the forward pass immediately after the encoder and before the loss evaluation; the entire objective (encoder -> reweighted elastic-net loss -> decoder) is therefore end-to-end differentiable by standard automatic differentiation. There is no circular dependence on any post-training fitted encoder because the weights depend only on the instantaneous encoder activations for that minibatch. The claimed alignment follows from the fact that the training loss directly penalizes deviation between the encoder and the (reweighted) sparse coding map. In the revision we add an explicit gradient derivation and a short differentiability proof in Section 4.2 and Appendix A. revision: yes
Circularity Check
No circularity: theoretical claims derive from classical elastic-net properties without reduction to inputs or self-citations.
full rationale
The paper defines AEN-SAEs via adaptive elastic-net regularization (ℓ2 for strong convexity plus adaptive ℓ1 reweighting), then states that this yields a Lipschitz-continuous sparse coding map and global support recovery under mild assumptions. These properties follow from standard convex optimization results on elastic nets rather than being defined in terms of the fitted SAE outputs or recovered features. No quoted step equates a prediction to a fitted parameter by construction, and the geometric-instability diagnosis is an interpretive framing that motivates the architecture without presupposing its empirical outcomes. The derivation chain remains self-contained against external sparse-regression benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild assumptions under which the global feature support is recovered
invented entities (1)
-
AEN-SAEs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
K. Ayonrinde. Adaptive sparse allocation with mutual choice & feature choice sparse autoen- coders, 2024. URLhttps://doi.org/10.48550/arXiv.2411.02124
-
[2]
P. Bartlett, D. J. Foster, and M. Telgarsky. Spectrally-normalized margin bounds for neural networks, 2017. URLhttps://doi.org/10.48550/arXiv.1706.08498
-
[3]
S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. van der Wal. Pythia: A suite for analyzing large language models across training and scaling, 2023. URL https: //doi.org/10.48550/arXiv.2304.01373
-
[4]
Bricken, A
T. Bricken, A. Templeton, J. Batson, B. Chen, A. Jermyn, T. Conerly, N. L. Turner, C. Anil, C. Denison, A. Askell, R. Lasenby, Y . Wu, S. Kravec, N. Schiefer, T. Maxwell, N. Joseph, A. Tamkin, K. Nguyen, B. McLean, J. E. Burke, T. Hume, S. Carter, T. Henighan, and C. Olah. Towards monosemanticity: Decomposing language models with dictionary learning, 2023...
2023
-
[5]
arXiv preprint arXiv:2412.06410 , year=
B. Bussmann, P. Leask, and N. Nanda. BatchTopK sparse autoencoders, 2024. URL https: //doi.org/10.48550/arXiv.2412.06410
-
[6]
Hilbert’s sixth problem: derivation of fluid equations via Boltzmann’s kinetic theory,
B. Bussmann, N. Nabeshima, A. Karvonen, and N. Nanda. Learning multi-level features with matryoshka sparse autoencoders, 2025. URL https://doi.org/10.48550/arXiv.2503. 17547
-
[7]
D. Chanin, J. Wilken-Smith, T. Dulka, H. Bhatnagar, S. Golechha, and J. Bloom. A is for absorption: Studying feature splitting and absorption in sparse autoencoders, 2025. URL https://doi.org/10.48550/arXiv.2409.14507
-
[8]
X. Chen, J. Liu, Z. Wang, and W. Yin. Hyperparameter tuning is all you need for LISTA, 2021. URLhttps://doi.org/10.48550/arXiv.2110.15900
-
[11]
J. Fan and J. Lv. Sure independence screening for ultra-high dimensional feature space, 2008. URLhttps://doi.org/10.48550/arXiv.math/0612857
-
[12]
Foucart and H
S. Foucart and H. Rauhut.A Mathematical Introduction to Compressive Sensing. Applied and Numerical Harmonic Analysis. Birkhäuser, New York, 2013. URL https://doi.org/10. 1007/978-0-8176-4948-7
2013
-
[13]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, and C. Leahy. The Pile: An 800gb dataset of diverse text for language modeling, 2020. URLhttps://doi.org/10.48550/arXiv.2101.00027
work page internal anchor Pith review doi:10.48550/arxiv.2101.00027 2020
-
[14]
L. Gao, T. D. la Tour, H. Tillman, G. Goh, R. Troll, A. Radford, I. Sutskever, J. Leike, and J. Wu. Scaling and evaluating sparse autoencoders, 2024. URLhttps://doi.org/10.48550/ arXiv.2406.04093
work page internal anchor Pith review arXiv 2024
-
[15]
M. Geva, A. Caciularu, K. R. Wang, and Y . Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space, 2022. URL https://doi.org/ 10.48550/arXiv.2203.14680
-
[16]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, A. Yang, A. Fan, A. Goyal, A. Hartshorn, A. Yang, A. Mitra, A. Sravankumar, A. Korenev, A. Hinsvark, A. Rao, A. Zhang, A. Rodriguez, A. Gregerson, A. Spataru, B. Roziere, B. Biron, B. Tang, B. Chern, C. Caucheteux, C. Nayak, C. Bi, C. Mar...
work page internal anchor Pith review doi:10.48550/arxiv.2407.21783 2024
-
[17]
Gregor and Y
K. Gregor and Y . LeCun. Learning fast approximations of sparse coding. InProceedings of the 27th International Conference on Machine Learning, ICML, 2010. URL https://icml.cc/ Conferences/2010/papers/449.pdf
2010
-
[18]
G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, 2006. URLhttps://doi.org/10.1126/science.1127647
-
[19]
S. Hochreiter and J. Schmidhuber. Flat minima.Neural Computation, 9(1):1–42, 1997. URL https://doi.org/10.1162/neco.1997.9.1.1
-
[20]
A. J. Hoffman. On approximate solutions of systems of linear inequalities.Journal of Research of the National Bureau of Standards, 49(4):263–265, 1952. URL https://nvlpubs.nist. gov/nistpubs/jres/049/4/v49.n04.a05.pdf
1952
-
[21]
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima, 2017. URL https://doi. org/10.48550/arXiv.1609.04836
work page internal anchor Pith review doi:10.48550/arxiv.1609.04836 2017
- [22]
- [23]
-
[24]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
T. Lieberum, S. Rajamanoharan, A. Conmy, L. Smith, N. Sonnerat, V . Varma, J. Kramár, A. Dragan, R. Shah, and N. Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024. URLhttps://doi.org/10.48550/arXiv.2408.05147
work page internal anchor Pith review doi:10.48550/arxiv.2408.05147 2024
-
[25]
J. Liu, T. Blanton, Y . Elazar, S. Min, Y . Chen, A. Chheda-Kothary, H. Tran, B. Bischoff, E. Marsh, M. Schmitz, C. Trier, A. Sarnat, J. James, J. Borchardt, B. Kuehl, E. Cheng, K. Far- ley, S. Sreeram, T. Anderson, D. Albright, C. Schoenick, L. Soldaini, D. Groeneveld, R. Y . Pang, P. W. Koh, N. A. Smith, S. Lebrecht, Y . Choi, H. Hajishirzi, A. Farhadi,...
-
[26]
Mairal, F
J. Mairal, F. Bach, J. Ponce, and G. Sapiro. Online learning for matrix factorization and sparse coding.Journal of Machine Learning Research, 11(1), 2010. URL http://jmlr.org/ papers/v11/mairal10a.html
2010
-
[27]
C. P. Martin-Linares and J. P. Ling. Attribution-guided distillation of matryoshka sparse autoencoders, 2025. URLhttps://doi.org/10.48550/arXiv.2512.24975
-
[28]
N. Nanda. A comprehensive mechanistic interpretability explainer & glossary, 2022. URL https://www.neelnanda.io/mechanistic-interpretability/glossary
2022
-
[29]
B. Neyshabur, S. Bhojanapalli, D. McAllester, and N. Srebro. Exploring generalization in deep learning, 2017. URLhttps://doi.org/10.48550/arXiv.1706.08947
-
[30]
S. T. Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions.Psychonomic Bulletin & Review, 21(5):1112–1130, 2014. URL https://doi. org/10.3758/s13423-014-0585-6
-
[31]
N. Pochinkov, B. Pasero, and S. Shibayama. Investigating neuron ablation in attention heads: The case for peak activation centering, 2024. URL https://doi.org/10.48550/arXiv. 2408.17322
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[32]
arXiv preprint arXiv:2404.16014 , year=
S. Rajamanoharan, A. Conmy, L. Smith, T. Lieberum, V . Varma, J. Kramár, R. Shah, and N. Nanda. Improving dictionary learning with gated sparse autoencoders, 2024. URL https: //doi.org/10.48550/arXiv.2404.16014
-
[33]
Tang, T., Luo, W., Huang, H., Zhang, D., Wang, X., Zhao, W
S. Rajamanoharan, T. Lieberum, N. Sonnerat, A. Conmy, V . Varma, J. Kramár, and N. Nanda. Jumping ahead: Improving reconstruction fidelity with jumprelu sparse autoencoders, 2024. URLhttps://doi.org/10.48550/arXiv.2407.14435
-
[34]
S. M. Robinson. Some continuity properties of polyhedral multifunctions.Mathemati- cal Programming at Oberwolfach, 14:206–214, 1981. URL https://doi.org/10.1007/ BFb0120929
1981
-
[35]
T. Rockafellar and R. Wets.Variational analysis. Springer, 1998. URL https://doi.org/ 10.1007/978-3-642-02431-3
-
[36]
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, and Y . Liu. RoFormer: Enhanced transformer with rotary position embedding, 2023. URLhttps://doi.org/10.48550/arXiv.2104.09864
work page internal anchor Pith review doi:10.48550/arxiv.2104.09864 2023
-
[37]
Journal of the Royal Statistical Society Series B: Statistical Methodology , author =
R. Tibshirani. Regression shrinkage and selection via the Lasso.Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996. URL https://doi.org/10.1111/ j.2517-6161.1996.tb02080.x
-
[38]
M. J. Wainwright.High-Dimensional Statistics: A Non-Asymptotic Viewpoint. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 2019. URL https://doi.org/10.1017/9781108627771
-
[39]
G. Yang, E. J. Hu, I. Babuschkin, S. Sidor, X. Liu, D. Farhi, N. Ryder, J. Pachocki, W. Chen, and J. Gao. Tensor programs v: Tuning large neural networks via zero-shot hyperparameter transfer, 2022. URLhttps://doi.org/10.48550/arXiv.2203.03466
-
[40]
Zhao and B
P. Zhao and B. Yu. On model selection consistency of Lasso.Journal of Machine Learning Research, 7(90):2541–2563, 2006. URLhttp://jmlr.org/papers/v7/zhao06a.html
2006
-
[41]
H. Zou. The adaptive Lasso and its oracle properties.Journal of the American Statistical Associa- tion, 101(476):1418–1429, 2006. URL https://doi.org/10.1198/016214506000000735
-
[42]
H. Zou and T. Hastie. Regularization and variable selection via the elastic net.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 67(2):301–320, 2005. URL https://doi.org/10.1111/j.1467-9868.2005.00503.x
-
[43]
H. Zou and H. H. Zhang. On the adaptive elastic-net with a diverging number of parameters.The Annals of Statistics, 37(4):1733–1751, 2009. URL https://doi.org/10.1214/08-AOS625. 13 A Theoretical Guarantees: Polyhedral Stability and Oracle Consistency In this section, we formalize the statistical and stability guarantees of the AEN-SAE. For notational simp...
-
[44]
Scale invariance from reference features.The idealized weight ˜wi = (¯hi)−γ is highly sensitive to the raw magnitude of the LLM residual stream, which varies drastically across different models and intermediate layers. To make the architecture transferable without exhaustive hyperparameter retuning, we introduce a scale-invariant reference ¯h(t) ref , def...
-
[45]
In 16-bit (BF16) or 32-bit floating-point hardware, this unbounded growth causes numerical instability and gradient explosion
Numerical bounds ( wmin and wmax).In theory, we rely on the idealized limit ˜wi → ∞ . In 16-bit (BF16) or 32-bit floating-point hardware, this unbounded growth causes numerical instability and gradient explosion. We therefore clamp the maximum penalty to wmax. As long as λ1wmax is sufficiently larger than the local gradient residual, the KKT inequality ho...
-
[46]
However, during the initial steps of neural network training, feature activations are driven by random initialization noise
The cold-start warmup schedule.The asymptotic proof naturally assumes the system has already reached the steady-state expectation E[|h∗ i |]. However, during the initial steps of neural network training, feature activations are driven by random initialization noise. If an ultimately useful feature initializes poorly, its EMA drops, its weight spikes to wm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.