Recognition: unknown
Agentic Retrieval-Augmented Generation for Financial Document Question Answering
Pith reviewed 2026-05-08 16:58 UTC · model grok-4.3
The pith
An agentic RAG framework with iterative loops, contrastive retrieval, and code-based reasoning lifts accuracy on financial document question answering by 5 to 9 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
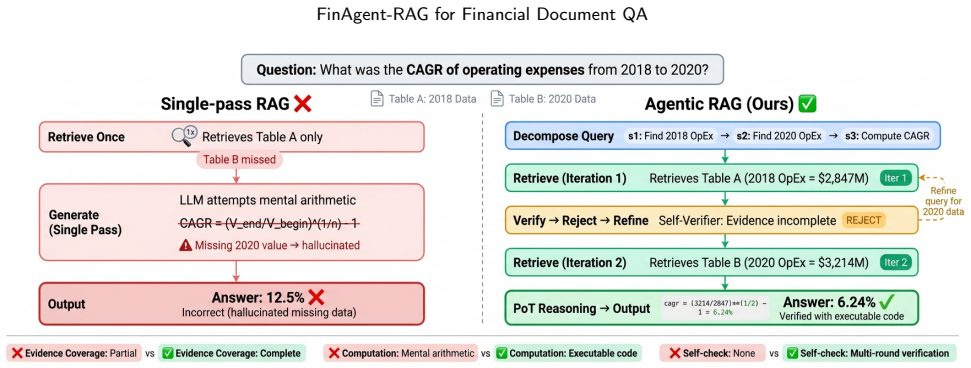
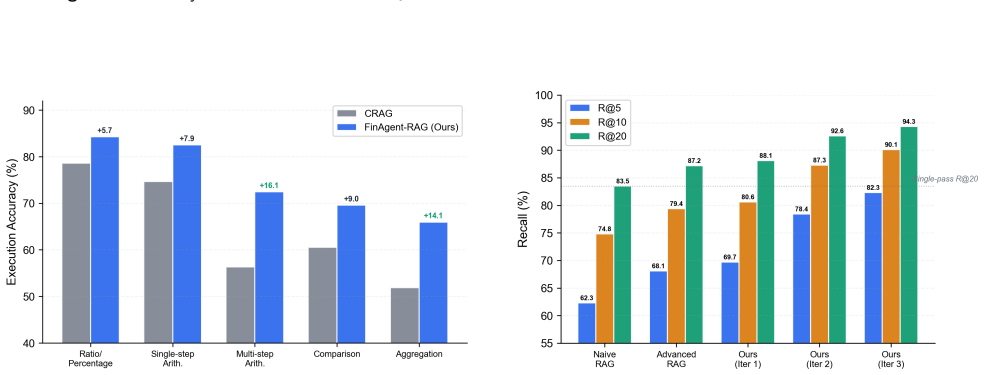
FinAgent-RAG is an agentic RAG framework that orchestrates iterative retrieval-reasoning loops with self-verification for financial document QA. It adds a Contrastive Financial Retriever trained with hard negative mining, a Program-of-Thought module that emits executable Python code rather than relying on mental arithmetic, and an Adaptive Strategy Router that assigns resources according to question complexity. Across FinQA, ConvFinQA, and TAT-QA the system records execution accuracies of 76.81 percent, 78.46 percent, and 74.96 percent, exceeding the strongest prior baseline by 5.62 to 9.32 points while cutting API costs by 41.3 percent on FinQA and showing stability across four different LL
What carries the argument
The central mechanism is the orchestration of iterative retrieval-reasoning loops with self-verification, supported by a contrastive financial retriever, Program-of-Thought code generation for exact arithmetic, and an adaptive strategy router that allocates effort based on question complexity.
Load-bearing premise
That the iterative self-verification loops and Program-of-Thought code generation reliably produce correct multi-step numerical answers without introducing new errors from incorrect code or flawed retrieval, and that the reported gains generalize beyond the three benchmarks.
What would settle it
A new test collection of financial questions that require multi-table and footnote reasoning where the generated code or retrieved passages produce wrong arithmetic results and overall accuracy falls to or below the strongest baseline.
Figures







read the original abstract
Financial document question answering (QA) demands complex multi-step numerical reasoning over heterogeneous evidence--structured tables, textual narratives, and footnotes--scattered across corporate filings. Existing retrieval-augmented generation (RAG) approaches adopt a single-pass retrieve-then-generate paradigm that struggles with the compositional reasoning chains prevalent in financial analysis. We propose FinAgent-RAG, an agentic RAG framework that orchestrates iterative retrieval-reasoning loops with self-verification, specifically engineered for the precision requirements of financial numerical reasoning. The framework integrates three domain-specific innovations: (1) a Contrastive Financial Retriever trained with hard negative mining to distinguish semantically similar but numerically distinct financial passages, (2) a Program-of-Thought reasoning module that generates executable Python code for precise arithmetic rather than relying on error-prone LLM-based mental computation, and (3) an Adaptive Strategy Router that dynamically allocates computational resources based on question complexity, reducing API costs by 41.3% on FinQA while preserving accuracy. Extensive experiments on three benchmark datasets--FinQA, ConvFinQA, and TAT-QA--demonstrate that FinAgent-RAG achieves 76.81%, 78.46%, and 74.96% execution accuracy respectively, outperforming the strongest baseline by 5.62--9.32 percentage points. Ablation studies, cross-backbone evaluation with four LLMs, and deployment cost analysis confirm the framework's robustness and practical viability for financial institutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce FinAgent-RAG, an agentic RAG framework for financial document question answering that employs iterative retrieval-reasoning loops with self-verification. It incorporates a Contrastive Financial Retriever using hard negative mining, a Program-of-Thought module for generating executable Python code to handle precise arithmetic, and an Adaptive Strategy Router to optimize computational costs. Experiments on FinQA, ConvFinQA, and TAT-QA benchmarks yield execution accuracies of 76.81%, 78.46%, and 74.96%, respectively, exceeding the strongest baselines by 5.62 to 9.32 percentage points, with a reported 41.3% reduction in API costs on FinQA. Ablation studies and evaluations across multiple LLMs are mentioned to support robustness.
Significance. If the results are confirmed with rigorous controls, this approach could significantly improve the reliability of LLM-based systems for complex financial QA tasks involving numerical reasoning over heterogeneous documents. The cost savings and domain-specific adaptations make it particularly valuable for real-world applications in financial institutions, potentially setting a new standard for agentic systems in specialized domains.
major comments (2)
- [Abstract and Results] The headline performance numbers (76.81% on FinQA, etc.) and improvements (5.62-9.32 pp) are stated without reference to specific baseline models, their scores, data split details, or statistical measures such as standard deviations from multiple runs. This information is essential to evaluate whether the gains are attributable to the proposed innovations rather than experimental artifacts.
- [Methods section on Program-of-Thought and self-verification] The claim that the PoT code generation combined with iterative self-verification reliably avoids introducing new errors in multi-step financial calculations (such as table joins or ratio computations) is central to the performance gains. However, the manuscript does not provide a dedicated error analysis or examples of how the verification step identifies and corrects logic flaws in the generated code, leaving open the possibility that high execution accuracy masks underlying reasoning issues.
minor comments (2)
- [Related Work] The discussion of existing RAG approaches could be expanded to include more recent agent-based methods for comparison.
- [Tables and figures] Ensure all tables reporting accuracies include the full set of baselines and metrics for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to improve the clarity and evidentiary support in our manuscript. We address each major comment below and will incorporate revisions to strengthen the presentation of results and the analysis of the Program-of-Thought module.
read point-by-point responses
-
Referee: [Abstract and Results] The headline performance numbers (76.81% on FinQA, etc.) and improvements (5.62-9.32 pp) are stated without reference to specific baseline models, their scores, data split details, or statistical measures such as standard deviations from multiple runs. This information is essential to evaluate whether the gains are attributable to the proposed innovations rather than experimental artifacts.
Authors: We agree that explicit references to baselines and statistical details would aid evaluation. The results section (Section 4) contains Tables 1-3 that report exact scores for all baselines (including ReAct, CoT, and domain-adapted RAG variants) on the standard benchmark splits. However, standard deviations from multiple runs were omitted. In the revised manuscript we will add a footnote in the abstract referencing the primary baselines and their scores, and we will augment the results tables with standard deviations computed over three independent runs with different random seeds. revision: yes
-
Referee: [Methods section on Program-of-Thought and self-verification] The claim that the PoT code generation combined with iterative self-verification reliably avoids introducing new errors in multi-step financial calculations (such as table joins or ratio computations) is central to the performance gains. However, the manuscript does not provide a dedicated error analysis or examples of how the verification step identifies and corrects logic flaws in the generated code, leaving open the possibility that high execution accuracy masks underlying reasoning issues.
Authors: We recognize that a dedicated error analysis with concrete examples would more directly substantiate the self-verification mechanism. The current manuscript supports the contribution of this component via ablation studies (Section 5.2) that quantify accuracy drops when self-verification is removed. To address the referee's concern, we will add a qualitative analysis subsection (or appendix) containing specific examples of logic errors in generated Python code (e.g., incorrect joins or ratio formulas) and illustrate how the iterative verification loop detects execution failures and triggers corrective re-generation. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation of agentic RAG framework
full rationale
The paper proposes FinAgent-RAG with three components (Contrastive Financial Retriever, Program-of-Thought module, Adaptive Strategy Router) and reports execution accuracies on FinQA (76.81%), ConvFinQA (78.46%), and TAT-QA (74.96%). No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or described framework. Central claims rest on external benchmark comparisons rather than quantities derived by construction from the paper's own inputs or prior self-referential results. The derivation chain is self-contained as an empirical proposal and evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative retrieval-reasoning loops with self-verification improve accuracy on compositional financial questions
Reference graph
Works this paper leans on
-
[1]
author Araci, D. , year 2019 . title FinBERT : Financial sentiment analysis with pre-trained language models . journal arXiv preprint arXiv:1908.10063
-
[2]
, author Wu, Z
author Asai, A. , author Wu, Z. , author Wang, Y. , author Sil, A. , author Hajishirzi, H. , year 2024 . title Self- RAG : Learning to retrieve, generate, and critique through self-reflection , in: booktitle International Conference on Learning Representations (ICLR) , pp. pages 1--21
2024
-
[3]
, author Mensch, A
author Borgeaud, S. , author Mensch, A. , author Hoffmann, J. , author Cai, T. , author Rutherford, E. , author Millican, K. , author van den Driessche, G. , author Lespiau, J.B. , author Damoc, B. , author Clark, A. , et al., year 2022 . title Improving language models by retrieving from trillions of tokens , in: booktitle International Conference on Mac...
2022
-
[4]
, author Zhou, P
author Chen, J. , author Zhou, P. , author Hua, Y. , author Xin, L. , author Chen, K. , author Li, Z. , author Zhu, B. , author Liang, J. , year 2024 . title FinTextQA : A dataset for long-form financial question answering , in: booktitle Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , pp. pages 6025--6047
2024
-
[5]
, author Ma, X
author Chen, W. , author Ma, X. , author Wang, X. , author Cohen, W.W. , year 2023 . title Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks . journal Transactions on Machine Learning Research
2023
-
[6]
, author Chen, W
author Chen, Z. , author Chen, W. , author Smiley, C. , author Shah, S. , author Borber, I. , author Mouber, W. , author Wang, W.Y. , year 2021 . title FinQA : A dataset of numerical reasoning over financial data , in: booktitle Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 7199--7210
2021
-
[7]
, author Li, S
author Chen, Z. , author Li, S. , author Smiley, C. , author Ma, Z. , author Shah, S. , author Wang, W.Y. , year 2022 . title ConvFinQA : Exploring the chain of numerical reasoning in conversational finance question answering , in: booktitle Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 6279--6292
2022
-
[8]
, author Madaan, A
author Gao, L. , author Madaan, A. , author Zhou, S. , author Alon, U. , author Liu, P. , author Yang, Y. , author Callan, J. , author Neubig, G. , year 2023 . title PAL : Program-aided language models , in: booktitle International Conference on Machine Learning (ICML) , pp. pages 10764--10799
2023
-
[9]
Retrieval-Augmented Generation for Large Language Models: A Survey
author Gao, Y. , author Xiong, Y. , author Gao, X. , author Jia, K. , author Pan, J. , author Bi, Y. , author Dai, Y. , author Sun, J. , author Wang, H. , year 2024 . title Retrieval-augmented generation for large language models: A survey . journal arXiv preprint arXiv:2312.10997
work page internal anchor Pith review arXiv 2024
-
[10]
, author Rossiello, G
author Glass, M. , author Rossiello, G. , author Chowdhury, M.F.M. , author Naber, A. , author Nishi, R. , author Gliozzo, A. , year 2022 . title Re2 G : Retrieve, rerank, generate , in: booktitle Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL) , pp. pages 2701--2715
2022
-
[11]
, author Lee, K
author Guu, K. , author Lee, K. , author Tung, Z. , author Pasupat, P. , author Chang, M.W. , year 2020 . title REALM : Retrieval-augmented language model pre-training , in: booktitle International Conference on Machine Learning (ICML) , pp. pages 3929--3938
2020
-
[12]
, author Nowak, P.K
author Herzig, J. , author Nowak, P.K. , author M \"u ller, T. , author Piccinno, F. , author Eisenschlos, J.M. , year 2020 . title TaPas : Weakly supervised table parsing via pre-training , in: booktitle Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pp. pages 4320--4333
2020
-
[13]
, author Yu, W
author Huang, L. , author Yu, W. , author Ma, W. , author Zhong, W. , author Feng, Z. , author Wang, H. , author Chen, Q. , author Peng, W. , author Feng, X. , author Qin, B. , author Liu, T. , year 2025 . title A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions . journal ACM Computing Surveys volume 5...
2025
-
[14]
Mathprompter: Mathematical reasoning using large language models
author Imani, S. , author Du, L. , author Shrivastava, H. , year 2023 . title MathPrompter : Mathematical reasoning using large language models . journal arXiv preprint arXiv:2303.05398
-
[15]
, author Grave, E
author Izacard, G. , author Grave, E. , year 2021 . title Leveraging passage retrieval with generative models for open domain question answering , in: booktitle Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , pp. pages 874--880
2021
-
[16]
, author Xu, F.F
author Jiang, Z. , author Xu, F.F. , author Gao, L. , author Sun, Z. , author Liu, Q. , author Dwivedi-Yu, J. , author Yang, Y. , author Callan, J. , author Neubig, G. , year 2023 . title Active retrieval augmented generation , in: booktitle Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 7969--7992
2023
-
[17]
, author Douze, M
author Johnson, J. , author Douze, M. , author J \'e gou, H. , year 2019 . title Billion-scale similarity search with GPUs . journal IEEE Transactions on Big Data volume 7 , pages 535--547
2019
-
[18]
Language Models (Mostly) Know What They Know
author Kadavath, S. , author Conerly, T. , author Askell, A. , author Henighan, T. , author Drain, D. , author Perez, E. , author Schiefer, N. , author Hatfield-Dodds, Z. , author DasSarma, N. , author Tran-Johnson, E. , et al., year 2022 . title Language models (mostly) know what they know . journal arXiv preprint arXiv:2207.05221
work page internal anchor Pith review arXiv 2022
-
[19]
, author Oguz, B
author Karpukhin, V. , author Oguz, B. , author Min, S. , author Lewis, P. , author Wu, L. , author Edunov, S. , author Chen, D. , author Yih, W.t. , year 2020 . title Dense passage retrieval for open-domain question answering , in: booktitle Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 6769--6781
2020
-
[20]
u ttler, H. , author Lewis, M. , author Yih, W.t. , author Rockt \
author Lewis, P. , author Perez, E. , author Piktus, A. , author Petroni, F. , author Karpukhin, V. , author Goyal, N. , author K \"u ttler, H. , author Lewis, M. , author Yih, W.t. , author Rockt \"a schel, T. , author Riedel, S. , author Kiela, D. , year 2020 . title Retrieval-augmented generation for knowledge-intensive NLP tasks , in: booktitle Advanc...
2020
-
[21]
, author Lin, K
author Liu, N.F. , author Lin, K. , author Hewitt, J. , author Paranjape, A. , author Bevilacqua, M. , author Petroni, F. , author Liang, P. , year 2024 . title Lost in the middle: How language models use long contexts . journal Transactions of the Association for Computational Linguistics volume 12 , pages 157--173
2024
-
[22]
, author Gong, Y
author Ma, X. , author Gong, Y. , author He, P. , author Zhao, H. , author Duan, N. , year 2023 . title Query rewriting in retrieval-augmented large language models , in: booktitle Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 5303--5315
2023
-
[23]
, author Luo, L
author Pan, S. , author Luo, L. , author Wang, Y. , author Chen, C. , author Wang, J. , author Wu, X. , year 2024 . title Unifying large language models and knowledge graphs: A roadmap . journal IEEE Transactions on Knowledge and Data Engineering volume 36 , pages 3580--3599
2024
-
[24]
, author Liang, S
author Qin, Y. , author Liang, S. , author Ye, Y. , author Zhu, K. , author Yan, L. , author Lu, Y. , author Lin, Y. , author Cong, X. , author Tang, X. , author Qian, B. , et al., year 2024 . title ToolLLM : Facilitating large language models to master 16000+ real-world APIs , in: booktitle International Conference on Learning Representations (ICLR) , pp...
2024
-
[25]
, author Dwivedi-Yu, J
author Schick, T. , author Dwivedi-Yu, J. , author Dess \`i , R. , author Raileanu, R. , author Lomeli, M. , author Hambro, E. , author Zettlemoyer, L. , author Cancedda, N. , author Scialom, T. , year 2023 . title Toolformer: Language models can teach themselves to use tools , in: booktitle Advances in Neural Information Processing Systems (NeurIPS) , pp...
2023
-
[26]
, author Kuber, K
author Shah, R.S. , author Kuber, K. , author Lee, M. , author Nishi, R. , author Vig, J. , year 2022 . title When FLUE meets FLANG : Benchmarks and large pre-trained language model for financial domain , in: booktitle Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 2322--2335
2022
-
[27]
, author Gong, Y
author Shao, Z. , author Gong, Y. , author Shen, Y. , author Huang, M. , author Duan, N. , author Chen, W. , year 2023 . title Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy , in: booktitle Findings of the Association for Computational Linguistics: EMNLP 2023 , pp. pages 9248--9274
2023
-
[28]
, author Cassano, F
author Shinn, N. , author Cassano, F. , author Gopinath, A. , author Narasimhan, K. , author Yao, S. , year 2023 . title Reflexion: Language agents with verbal reinforcement learning , in: booktitle Advances in Neural Information Processing Systems (NeurIPS) , pp. pages 8634--8652
2023
-
[29]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
author Singh, A. , author Ehtesham, A. , author Kumar, S. , author Khoei, T.T. , author Vasilakos, A.V. , year 2025 . title Agentic retrieval-augmented generation: A survey on agentic RAG . journal arXiv preprint arXiv:2501.09136
work page internal anchor Pith review arXiv 2025
-
[30]
, author Yao, S
author Sumers, T.R. , author Yao, S. , author Narasimhan, K. , author Griffiths, T.L. , year 2024 . title Cognitive architectures for language agents . journal Transactions on Machine Learning Research
2024
-
[31]
, author Ma, C
author Wang, L. , author Ma, C. , author Feng, X. , author Zhang, Z. , author Yang, H. , author Zhang, J. , author Chen, Z. , author Tang, J. , author Chen, X. , author Lin, Y. , author Zhao, W.X. , author Wei, Z. , author Wen, J.R. , year 2024 . title A survey on large language model based autonomous agents . journal Frontiers of Computer Science volume ...
2024
-
[32]
, author Wang, X
author Wei, J. , author Wang, X. , author Schuurmans, D. , author Bosma, M. , author Ichter, B. , author Xia, F. , author Chi, E. , author Le, Q. , author Zhou, D. , year 2022 . title Chain-of-thought prompting elicits reasoning in large language models , in: booktitle Advances in Neural Information Processing Systems (NeurIPS) , pp. pages 24824--24837
2022
-
[33]
BloombergGPT: A Large Language Model for Finance
author Wu, S. , author Irsoy, O. , author Lu, S. , author Daber, V. , author Dredze, M. , author Gehrmann, S. , author Kambadur, P. , author Rosenberg, D. , author Mann, G. , year 2023 . title BloombergGPT : A large language model for finance . journal arXiv preprint arXiv:2303.17564
work page internal anchor Pith review arXiv 2023
-
[34]
The Rise and Potential of Large Language Model Based Agents: A Survey
author Xi, Z. , author Chen, W. , author Guo, X. , author He, W. , author Ding, Y. , author Hong, B. , author Zhang, M. , author Wang, J. , author Jin, S. , author Zhou, E. , et al., year 2023 . title The rise and potential of large language model based agents: A survey . journal arXiv preprint arXiv:2309.07864
work page internal anchor Pith review arXiv 2023
-
[35]
C-Pack: Packed Resources For General Chinese Embeddings
author Xiao, S. , author Liu, Z. , author Zhang, P. , author Muennighoff, N. , year 2023 . title C-Pack : Packaged resources to advance general Chinese embedding . journal arXiv preprint arXiv:2309.07597
work page internal anchor Pith review arXiv 2023
-
[36]
arXiv preprint arXiv:2412.20138 , year =
author Xiao, Y. , author Sun, E. , author Luo, D. , author Wang, W. , year 2024 . title TradingAgents : Multi-agents LLM financial trading framework . journal arXiv preprint arXiv:2412.20138
-
[37]
, author Han, W
author Xie, Q. , author Han, W. , author Zhang, X. , author Lai, Y. , author Peng, M. , author Lopez-Lira, A. , author Huang, J. , year 2023 . title PIXIU : A large language model, instruction data and evaluation benchmark for finance , in: booktitle Advances in Neural Information Processing Systems (NeurIPS): Datasets and Benchmarks Track
2023
-
[38]
author Xie, Q. , author Han, W. , author Zhang, X. , author Lai, Y. , author Peng, M. , author Lopez-Lira, A. , author Huang, J. , year 2024 . title FinBen : A holistic financial benchmark for large language models . journal arXiv preprint arXiv:2402.12659
-
[39]
Mitigating Hallucination on Hallucination in RAG via Ensemble Voting
author Xie, Z. , author Sun, Z. , year 2026 . title Mitigating hallucination on hallucination in RAG via ensemble voting . journal arXiv preprint arXiv:2603.27253
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
, author Wang, C
author Xie, Z. , author Wang, C. , author Wang, Y. , author Cai, S. , author Wang, S. , author Jin, T. , year 2025 . title Chat-driven text generation and interaction for person retrieval , in: booktitle Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pp. pages 5259--5270
2025
-
[41]
Corrective Retrieval Augmented Generation
author Yan, S.Q. , author Gu, J.C. , author Zhu, Y. , author Ling, Z.H. , year 2024 . title Corrective retrieval augmented generation . journal arXiv preprint arXiv:2401.15884
work page internal anchor Pith review arXiv 2024
-
[42]
author Yang, Y. , author Uy, M.C.S. , author Huang, A. , year 2020 . title FinBERT : A pretrained language model for financial communications . journal arXiv preprint arXiv:2006.08097
-
[43]
, author Zhao, J
author Yao, S. , author Zhao, J. , author Yu, D. , author Du, N. , author Shafran, I. , author Narasimhan, K. , author Cao, Y. , year 2023 . title ReAct : Synergizing reasoning and acting in language models , in: booktitle International Conference on Learning Representations (ICLR) , pp. pages 1--25
2023
-
[44]
, author Neubig, G
author Yin, P. , author Neubig, G. , author Yih, W.t. , author Riedel, S. , year 2020 . title TaBERT : Pretraining for joint understanding of textual and tabular data , in: booktitle Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , pp. pages 8413--8426
2020
-
[45]
, author Li, H
author Yu, Y. , author Li, H. , author Chen, Z. , author Jiang, Y. , author Li, Y. , author Zhang, D. , author Liu, R. , author Suchow, J.W. , author Khaldoun, K. , year 2024 . title FinMem : A performance-enhanced LLM trading agent with layered memory and character design , in: booktitle AAAI Spring Symposium Series (SSS)
2024
-
[46]
, author Lei, W
author Zhu, F. , author Lei, W. , author Huang, Y. , author Wang, C. , author Zhang, S. , author Lv, J. , author Feng, F. , author Chua, T.S. , year 2021 . title TAT-QA : A question answering benchmark on a hybrid of tabular and textual content in finance , in: booktitle Proceedings of the 59th Annual Meeting of the Association for Computational Linguisti...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.