Recognition: unknown
LaTA: A Drop-in, FERPA-Compliant Local-LLM Autograder for Upper-Division STEM Coursework
Pith reviewed 2026-05-08 16:52 UTC · model grok-4.3
The pith
LaTA provides a fully local LLM pipeline that grades LaTeX-based STEM assignments with error rates of 0.02 to 0.04 percent per rubric item while raising exam performance and student confidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LaTA runs an entirely on-premises pipeline that ingests LaTeX files, segments them into rubric-aligned pieces, grades each piece with a local chain-of-thought LLM against an instructor-supplied reference solution using binary YAML rubric items, and produces detailed reports, achieving confirmed error rates of 0.02–0.04 percent per line item, 11 percent higher midterm scores, 8 percent higher final scores, and confidence gains of at least 1.49 Likert points on every objective compared with the instructor's previous traditionally graded cohort.
What carries the argument
The four-stage pipeline (ingest, segment, grade, report) that routes student LaTeX submissions through a local open-weight chain-of-thought LLM for direct comparison against an instructor-authored reference solution under a YAML binary rubric.
If this is right
- Corrected submissions can be regraded in minutes at no added cost, allowing iterative student improvement.
- Time previously spent on routine grading can be redirected to expanded office hours and individualized support.
- Institutions satisfy FERPA constraints without custom assignment redesign or third-party data sharing.
- The open-source release permits direct adoption or adaptation in any LaTeX-using engineering or physics course.
- Single-machine operation on standard hardware removes per-assignment marginal costs even at class sizes of several hundred.
Where Pith is reading between the lines
- The same pipeline could be adapted to non-LaTeX formats by replacing the segmentation stage with format-specific parsers.
- Rapid, consistent feedback may itself be the active ingredient behind the performance lift, suggesting future experiments that isolate feedback timing from grading method.
- Because the system stores full grading traces, instructors could mine those traces to identify recurring misconceptions across an entire cohort.
- Extending the rubric language to include partial-credit or multi-point items would broaden applicability beyond the binary scoring used here.
Load-bearing premise
The observed gains in exam scores and student confidence are produced by the LaTA grading process itself rather than by differences in student cohorts, teaching style, or other unmeasured changes between the two terms.
What would settle it
A within-term or matched-cohort comparison in which identical assignments are graded both traditionally and by LaTA while holding all other course elements fixed, then measuring exam performance and confidence scores.
Figures

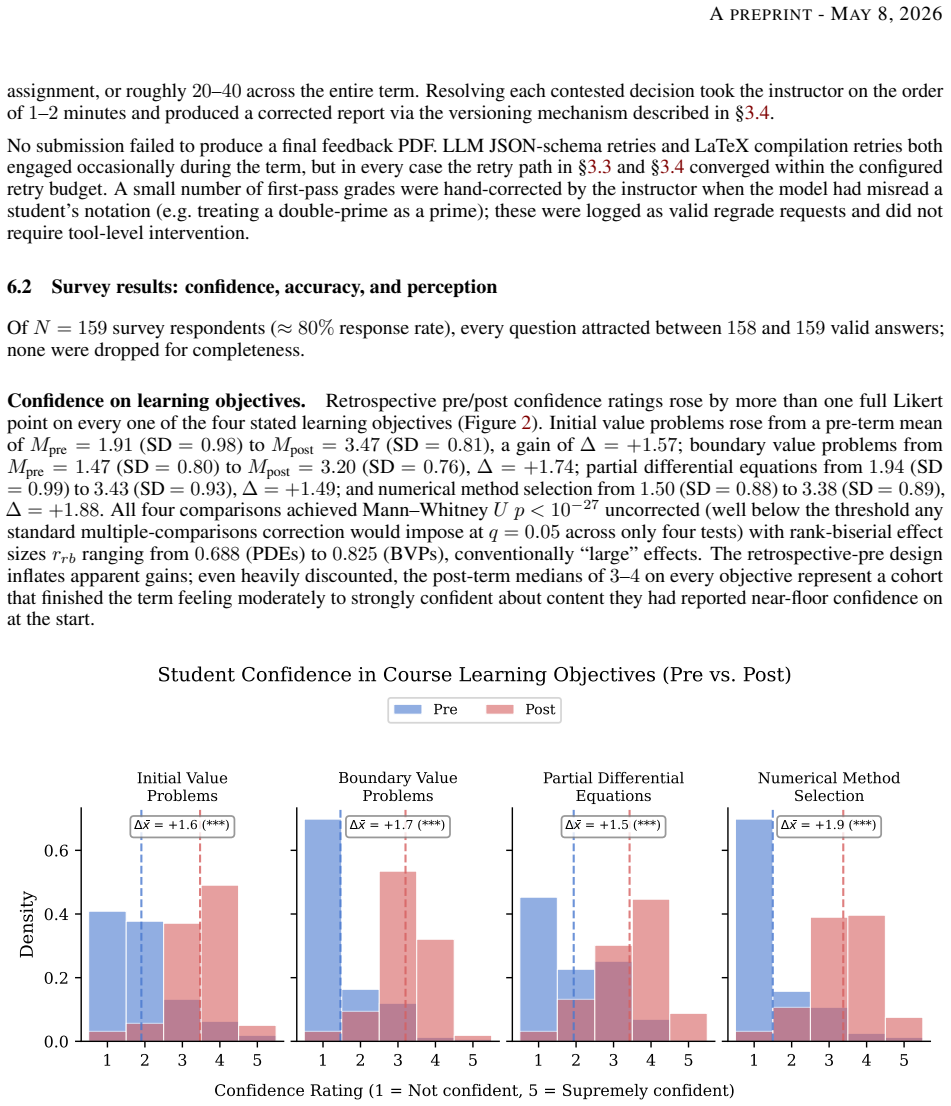
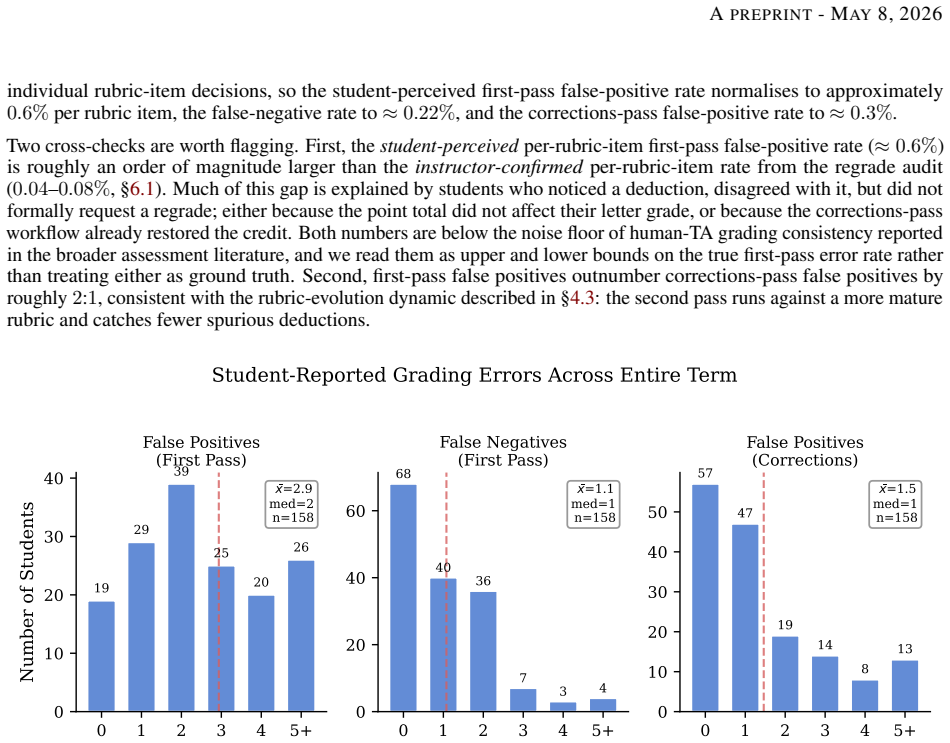
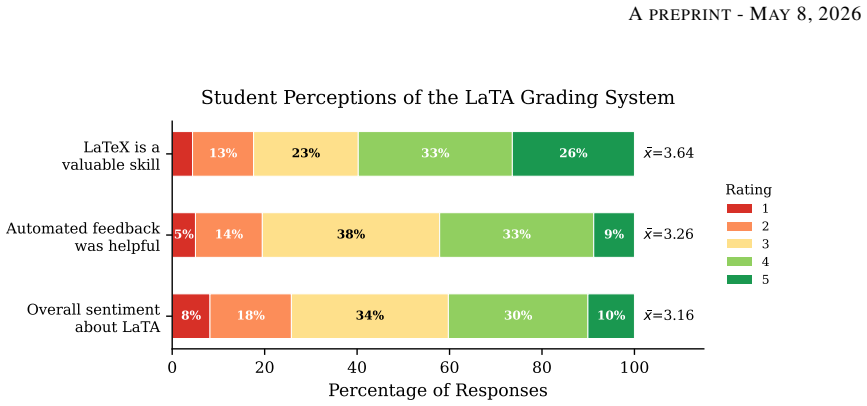
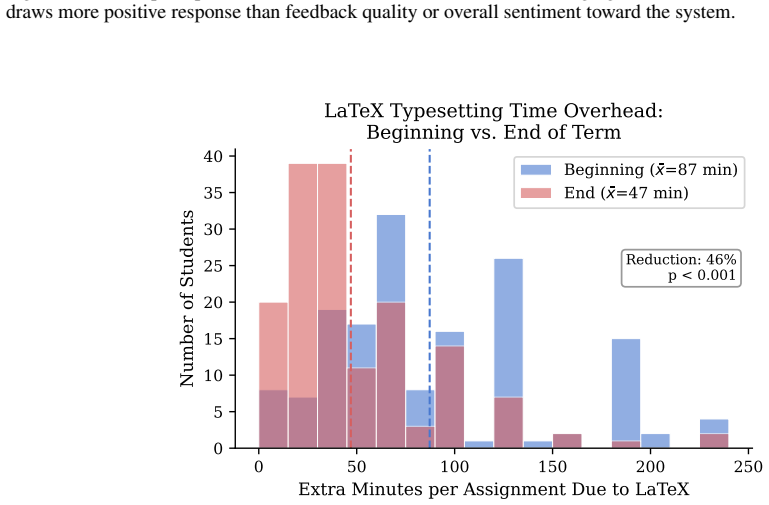


read the original abstract
Large-language-model (LLM) graders promise to relieve the grading burden of upper-division STEM courses, but most deployments to date send student work to third-party APIs, violating FERPA and exposing institutions to data risk while requiring substantial assignment modification. We present $\textbf{LaTA}\ (\textit{LaTeX Teaching Assistant})$, a drop-in, open-source autograder that runs entirely on commodity on-premises hardware and assumes a LaTeX-native workflow already adopted by many engineering and physics courses. LaTA implements a four-stage pipeline (ingest, segment, grade, report) using a locally hosted open-weight chain-of-thought LLM grader (gpt-oss:120b) that compares student work to an instructor-authored reference solution and applies a YAML rubric with binary per-item scoring. We deployed LaTA in Winter~2026 in ME 373 (Mechanical Engineering Methods) at Oregon State University, grading every weekly assignment for approximately 200 students on a single Mac Studio at \$0 marginal cost per assignment and 1--3 minutes of wall-clock time per submission, enabling regrading of corrected assignments and greatly expanded TA office hour offerings. The instructor-confirmed grading-error rate held at roughly $0.02$--$0.04\%$ per rubric line item across the term. Relative to the same instructor's previous traditionally-graded cohort, the LaTA-graded cohort outperformed by approximately $11\%$ on the midterm exam and $8\%$ on the final exam, and reported large gains in self-assessed confidence on every stated learning objective ($N = 159$ survey responses, $\Delta \geq +1.49$ Likert points, $p < 10^{-27}$ on every comparison). We release the code under AGPLv3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LaTA, a drop-in open-source autograder for LaTeX-based upper-division STEM assignments that runs entirely locally on commodity hardware using a chain-of-thought LLM (gpt-oss:120b). It implements a four-stage pipeline (ingest, segment, grade, report) that compares student work to an instructor reference solution against a YAML rubric with binary scoring. In a real deployment grading all weekly assignments for ~200 students in ME 373 at Oregon State University, the system ran at $0 marginal cost and 1-3 minutes per submission. The manuscript reports an instructor-confirmed grading error rate of 0.02-0.04% per rubric item, 11% higher midterm and 8% higher final exam scores, and large self-reported confidence gains (N=159, Δ≥+1.49 Likert points, p<10^{-27}) relative to the instructor's prior traditionally graded cohort. Code is released under AGPLv3.
Significance. If the accuracy and outcome claims hold after addressing controls, this work provides a concrete, reproducible example of a FERPA-compliant local LLM autograder that integrates with existing LaTeX workflows common in engineering and physics without requiring assignment redesign or third-party APIs. The real-course deployment at scale, zero marginal cost, support for regrading, and open-source release are notable strengths that could lower barriers to adoption of automated grading tools.
major comments (2)
- [Abstract] Abstract: The manuscript attributes 11% midterm and 8% final exam gains plus large confidence improvements (N=159, Δ≥+1.49, p<10^{-27}) to the LaTA-graded cohort relative to the prior traditionally graded cohort, yet provides no information on student demographics, incoming GPA, prior preparation, assignment difficulty, lecture content, or other instructor practices across terms. This simple before-after design without controls prevents causal attribution of the deltas to LaTA.
- [Abstract] Abstract: The central accuracy claim of an instructor-confirmed grading-error rate of 0.02–0.04% per rubric line item lacks any description of the verification process, number of items or submissions sampled, criteria for identifying errors, or controls used to compute the percentage. This detail is necessary to evaluate the reliability of the low-error-rate result.
minor comments (2)
- [Abstract] Abstract: The model name 'gpt-oss:120b' is used without a citation or brief description of its training or capabilities; adding this would help readers assess the grader's suitability.
- [Abstract] Abstract: The survey results report N=159 responses and p<10^{-27} on every comparison; clarifying whether the p-values account for multiple testing across learning objectives would strengthen the statistical presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript attributes 11% midterm and 8% final exam gains plus large confidence improvements (N=159, Δ≥+1.49, p<10^{-27}) to the LaTA-graded cohort relative to the prior traditionally graded cohort, yet provides no information on student demographics, incoming GPA, prior preparation, assignment difficulty, lecture content, or other instructor practices across terms. This simple before-after design without controls prevents causal attribution of the deltas to LaTA.
Authors: We agree that the before-after comparison cannot support causal claims, as differences in unobserved cohort characteristics or other term-specific factors could contribute to the observed exam and confidence differences. The manuscript already notes that the same instructor taught both cohorts with similar assignments and content, but we will revise the abstract, results, and add a limitations section to explicitly frame the 11% and 8% exam differences and confidence gains as observed associations between the LaTA-deployed cohort and the prior traditionally graded cohort, without attributing them causally to LaTA. revision: yes
-
Referee: [Abstract] Abstract: The central accuracy claim of an instructor-confirmed grading-error rate of 0.02–0.04% per rubric line item lacks any description of the verification process, number of items or submissions sampled, criteria for identifying errors, or controls used to compute the percentage. This detail is necessary to evaluate the reliability of the low-error-rate result.
Authors: The reported error rate reflects the instructor's manual verification by cross-checking a sample of LLM outputs against the reference solution and rubric across the term. We acknowledge that the manuscript omits the sampling details, number of items reviewed, and exact error criteria. In revision we will expand the methods section to describe the verification process, including the approximate scale of sampling and criteria used to flag discrepancies. revision: yes
Circularity Check
No circularity; empirical claims rest on external verification
full rationale
The manuscript describes a deployed system (LaTA) and reports observational results: instructor-confirmed per-item error rates of 0.02–0.04% and before-after cohort differences in exam scores and survey responses. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims are grounded in external instructor verification and student survey data rather than any reduction to the paper's own inputs or definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A locally hosted open-weight LLM can reliably apply a YAML rubric and compare student LaTeX work to an instructor reference solution with low systematic bias
Reference graph
Works this paper leans on
-
[1]
Rujun Gao, Hillary E. M. Merzdorf, Saira Anwar, M. Cynthia Hipwell, and Arun R. Srinivasa. Automatic assessment of text-based responses in post-secondary education: A systematic review.Computers and Education: Artificial Intelligence, 6:100206, 2024. doi: 10.1016/j.caeai.2024.100206. URL https://doi.org/10.1016/j. caeai.2024.100206
-
[2]
Advances in auto-grading with large language models: A cross-disciplinary survey
Fredrick Eneye Tania-Amanda Nkoyo, Chukwuebuka Fortunate Ijezue, Maaz Amjad, Ahmad Imam Amjad, Sabur Butt, and Gerardo Castañeda-Garza. Advances in auto-grading with large language models: A cross-disciplinary survey. InProceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA), 2025. URLhttps://aclanthology.org/...
2025
-
[3]
S, Naveeduddin Mohammed, and Gautam Biswas
Clayton Cohn, Ashwin T. S, Naveeduddin Mohammed, and Gautam Biswas. CoTAL: Human-in-the-loop prompt engineering, chain-of-thought reasoning, and active learning for generalizable formative assessment scoring.arXiv preprint arXiv:2504.02323, 2025. URLhttps://arxiv.org/abs/2504.02323
-
[4]
Le Ying Tan, Shiyu Hu, Darren J. Yeo, and Kang Hao Cheong. A comprehensive review on automated grading systems in STEM using AI techniques.Mathematics, 13(17):2828, 2025. doi: 10.3390/math13172828. URL https://www.mdpi.com/2227-7390/13/17/2828
-
[5]
Ehsan Latif and Xiaoming Zhai. Fine-tuning ChatGPT for automatic scoring.Computers and Education: Artificial Intelligence, 6:100210, 2024. doi: 10.1016/j.caeai.2024.100210. URL https://doi.org/10.1016/j.caeai. 2024.100210
-
[6]
Applying large language models and chain-of-thought for automatic scoring.Computers and Education: Artificial Intelligence, 6:100213,
Gyeong-Geon Lee, Ehsan Latif, Xuansheng Wu, Ninghao Liu, and Xiaoming Zhai. Applying large language models and chain-of-thought for automatic scoring.Computers and Education: Artificial Intelligence, 6:100213,
-
[7]
URLhttps://doi.org/10.1016/j.caeai.2024.100213
doi: 10.1016/j.caeai.2024.100213. URLhttps://doi.org/10.1016/j.caeai.2024.100213
-
[8]
Avalon: a human-in-the-loop llm grading system with instructor calibration and student self-assessment
Derek Armfield, Eason Chen, Asilbek Omonkulov, Xinyi Tang, Jionghao Lin, Erik Thiessen, and Kenneth Koedinger. Avalon: a human-in-the-loop llm grading system with instructor calibration and student self-assessment. InInternational Conference on Artificial Intelligence in Education, pages 111–118. Springer, 2025. URL https://avalonlearn.com/AIED_2025_paper...
2025
-
[9]
Towards reliable llm grading through self-consistency and selective human review: Higher accuracy, less work.Machine Learning and Knowledge Extraction, 8(3):74, 2026
Luke Korthals, Emma Akrong, Gali Geller, Hannes Rosenbusch, Raoul Grasman, and Ingmar Visser. Towards reliable llm grading through self-consistency and selective human review: Higher accuracy, less work.Machine Learning and Knowledge Extraction, 8(3):74, 2026. URLhttps://www.mdpi.com/2504-4990/8/3/74
2026
-
[10]
An ai-based system for formative and summative assessment in data science courses.International Journal of Artificial Intelligence in Education, 31(2):159–185, 2021
Pierpaolo Vittorini, Stefano Menini, and Sara Tonelli. An ai-based system for formative and summative assessment in data science courses.International Journal of Artificial Intelligence in Education, 31(2):159–185, 2021
2021
-
[11]
Teachers in the loop? an analysis of automatic assessment systems under article 22 gdpr
Liane Colonna. Teachers in the loop? an analysis of automatic assessment systems under article 22 gdpr. International Data Privacy Law, 14(1):3–18, 2024
2024
-
[12]
Nifu Dan. Auditing student–AI collaboration: A case study of online graduate CS students.arXiv preprint arXiv:2601.08697, 2026. URLhttps://arxiv.org/abs/2601.08697
-
[13]
Human-in-the-loop assessment with ai: implications for teacher education in ibero-american universities
Diana Carolina Fajardo-Ramos, Andrés Chiappe, and Javier Mella-Norambuena. Human-in-the-loop assessment with ai: implications for teacher education in ibero-american universities. 10:1710992, 2025
2025
-
[14]
Pydantic.Zenodo, 2024
Samuel Colvin, Eric Jolibois, Hasan Ramezani, Adrian Garcia Badaracco, Terrence Dorsey, David Montague, Serge Matveenko, Marcelo Trylesinski, Sydney Runkle, David Hewitt, et al. Pydantic.Zenodo, 2024
2024
-
[15]
Scaffolding probabilistic reasoning in civil engineering education: Integrating ai tutoring with simulation-based learning.Education Sciences, 16(1):103, 2026
Jize Zhang. Scaffolding probabilistic reasoning in civil engineering education: Integrating ai tutoring with simulation-based learning.Education Sciences, 16(1):103, 2026. URL https://www.mdpi.com/2227-7102/ 16/1/103
2026
-
[16]
Reflective prompt engineering: a new strategy for automated short answer scoring in biology.International Journal of Science Education, pages 1–23, 2025
Moriah Ariely, Asaf Salman, Anat Yarden, and Giora Alexandron. Reflective prompt engineering: a new strategy for automated short answer scoring in biology.International Journal of Science Education, pages 1–23, 2025
2025
-
[17]
Human-in-the-loop systems for adaptive learning using generative ai
Bhavishya Tarun, Haoze Du, Dinesh Kannan, and Edward F Gehringer. Human-in-the-loop systems for adaptive learning using generative ai. In2025 IEEE Frontiers in Education Conference (FIE), pages 1–7. IEEE, 2025
2025
-
[18]
Automatic item generation in various stem subjects using large language model prompting.Computers and Education: Artificial Intelligence, 8:100344, 2025
Kuang Wen Chan, Farhan Ali, Joonhyeong Park, Kah Shen Brandon Sham, Erdalyn Yeh Thong Tan, Francis Woon Chien Chong, Kun Qian, and Guan Kheng Sze. Automatic item generation in various stem subjects using large language model prompting.Computers and Education: Artificial Intelligence, 8:100344, 2025. 20 APREPRINT- MAY8, 2026
2025
-
[19]
Ai leads, humans lead, or collaborate? empirical findings and the sage roadmap for embedding genai in systems analysis and design education.STEM Education, 6(2):194–229, 2026
Mahmoud Elkhodr and Ergun Gide. Ai leads, humans lead, or collaborate? empirical findings and the sage roadmap for embedding genai in systems analysis and design education.STEM Education, 6(2):194–229, 2026
2026
-
[20]
Markus Knauff and Jelica Nejasmic. An efficiency comparison of document preparation systems used in academic research and development.PLoS ONE, 9(12):e115069, 2014. doi: 10.1371/journal.pone.0115069
-
[21]
Latex is not easy: Creating accessible scientific documents with r markdown.Journal on Technology and Persons with Disabilities, 7:157–171, 2019
J Seo, Sean McCurry, and Accessibility Team. Latex is not easy: Creating accessible scientific documents with r markdown.Journal on Technology and Persons with Disabilities, 7:157–171, 2019
2019
-
[22]
Cognitive load as a mediator in self-efficacy and english learning motivation among vocational college students.PloS one, 19(11):e0314088, 2024
Hui Zhang. Cognitive load as a mediator in self-efficacy and english learning motivation among vocational college students.PloS one, 19(11):e0314088, 2024
2024
-
[23]
Pan Liu, Qiang Jiang, Weiyan Xiong, and Wei Zhao. How task and individual characteristics affect students’ cognitive load: The moderating role of ai-generated content.International Review of Research in Open and Distributed Learning, 27(1):130–154, 2026
2026
-
[24]
Designing ai writing workflow ux for reduced cognitive loads
Brian Packer and Simeon Keates. Designing ai writing workflow ux for reduced cognitive loads. InInternational conference on human-computer interaction, pages 306–325. Springer, 2023
2023
-
[25]
Cloud-based latex editors for collaborative academic projects, case study in overleaf, 2026
Antonio José Sánchez Egea, Silvia García Vilana, Hernán Alberto González Rojas, and Amelia Nápoles Alberro. Cloud-based latex editors for collaborative academic projects, case study in overleaf, 2026
2026
-
[26]
Technical skills by major
Wentworth Institute of Technology. Technical skills by major. Co-ops + Careers resource, 2024. URLhttps: //coopsandcareers.wit.edu/resources/technical-competencies/
2024
-
[27]
Technical competencies and professional skills
uConnect. Technical competencies and professional skills. Career Development Resource, 2021. URL https: //cdn.uconnectlabs.com/wp-content/uploads/sites/46/2021/03/Technical-Skills-by-Major. pdf
2021
-
[28]
George S. Howard. Response-shift bias: A problem in evaluating interventions with pre/post self-reports. Evaluation Review, 4(1):93–106, 1980. doi: 10.1177/0193841X8000400105
-
[29]
Likert scale: Explored and explained.British journal of applied science & technology, 7(4):396–403, 2015
Ankur Joshi, Saket Kale, Satish Chandel, and D Kumar Pal. Likert scale: Explored and explained.British journal of applied science & technology, 7(4):396–403, 2015
2015
-
[30]
Research first look: Can large lan- guage models transform automated scoring further? American Institutes for Research, 2025
NAEP Research and Development Hub. Research first look: Can large lan- guage models transform automated scoring further? American Institutes for Research, 2025. URL https://naep-research.airprojects.org/R-D-Hub/ research-first-look-can-large-language-models-transform-automated-scoring-further
2025
-
[31]
Wilcoxon signed-rank test.Wiley encyclopedia of clinical trials, pages 1–3, 2007
Robert F Woolson. Wilcoxon signed-rank test.Wiley encyclopedia of clinical trials, pages 1–3, 2007
2007
-
[32]
Rank-biserial correlation.Psychometrika, 21(3):287–290, 1956
Edward E Cureton. Rank-biserial correlation.Psychometrika, 21(3):287–290, 1956
1956
-
[33]
routledge, 2013
Jacob Cohen.Statistical power analysis for the behavioral sciences. routledge, 2013
2013
-
[34]
Teoria statistica delle classi e calcolo delle probabilita.Pubblicazioni del R istituto superiore di scienze economiche e commericiali di firenze, 8:3–62, 1936
Carlo Bonferroni. Teoria statistica delle classi e calcolo delle probabilita.Pubblicazioni del R istituto superiore di scienze economiche e commericiali di firenze, 8:3–62, 1936
1936
-
[35]
Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal statistical society: series B (Methodological), 57(1):289–300, 1995. 21
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.