Recognition: unknown
FinRAG-12B: A Production-Validated Recipe for Grounded Question Answering in Banking
Pith reviewed 2026-05-08 16:12 UTC · model grok-4.3
The pith
A 12B model for banking questions delivers better citation grounding than GPT-4.1 and properly calibrated refusals at much lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
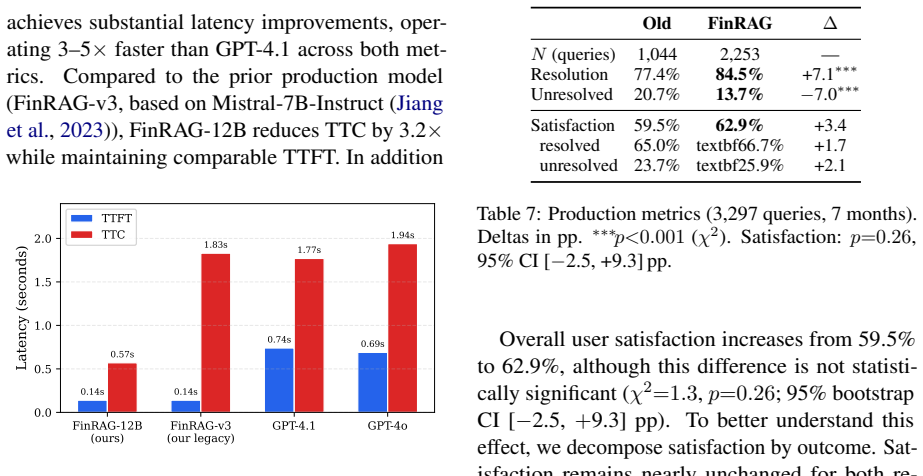
The central claim is that a unified data-efficient framework produces a 12B model that outperforms GPT-4.1 on citation grounding, achieves a 12 percent refusal rate by training on 22 percent unanswerable examples, and yields a 7.1 percentage point gain in query resolution when deployed at scale, all while providing 3-5 times faster and 20-50 times cheaper responses.
What carries the argument
The FinRAG data generation pipeline that uses LLM-as-a-Judge filtering, citation annotation, and curriculum learning, paired with a refusal training mechanism that mixes in a controlled percentage of unanswerable queries.
If this is right
- The model can be used safely in environments that require verifiable answers and regulatory compliance.
- Refusal behavior can be adjusted without sacrificing overall answer quality.
- Production systems in finance can achieve both higher accuracy and lower operating costs by using a specialized 12B model instead of a general frontier model.
- End-to-end pipelines from data curation through quantized inference are feasible for other high-stakes domains.
Where Pith is reading between the lines
- Similar pipelines might reduce the data and compute needed to adapt large models to other professional fields with strict accuracy requirements.
- The observed tradeoff between citation quality and refusal rate suggests a tunable parameter that organizations could set based on risk tolerance.
- Deployment across 40 institutions provides evidence that the recipe is robust to variations in internal data and query distributions.
Load-bearing premise
The reported gains in grounding, refusal rates, and query resolution are attributable to the training recipe itself rather than to differences in how the models were evaluated or to other unstated factors in the production environment.
What would settle it
An independent evaluation on a fixed set of banking queries, with human judges scoring citation faithfulness and refusal appropriateness for the 12B model, the untuned base, and GPT-4.1 under identical conditions, would directly test the superiority claims.
Figures
read the original abstract
Large language models (LLMs) are rapidly being adopted across various domains. However, their adoption in banking industry faces resistance due to demands for high accuracy, regulatory compliance, and the need for verifiable and grounded responses. We present a unified, data-efficient framework for training grounded domain-specific LLMs that optimizes answer quality, citation grounding, and calibrated refusal under real-world deployment constraints. First, we describe a data generation pipeline that combines LLM-as-a-Judge filtering, citation annotation, and curriculum learning with only 143M tokens. The resulting 12B model achieves high answer quality outperforming GPT-4.1 on citation grounding, with a modest citation tradeoff versus the untuned base. Second, we propose a calibrated refusal mechanism: training on 22% unanswerable examples yield a 12% "I don't know" rate, substantially improving over the base model's unsafe 4.3% rate while avoiding GPT-4.1's over-refusal (20.2%). Third, we present an end-to-end methodology spanning from data curation to quantized serving. The system is deployed at 40+ financial institutions, achieving a 7.1 percentage point improvement in query resolution (p < 0.001). Additionally, the model delivers 3-5x faster responses at 20-50x lower cost compared to GPT-4.1.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents FinRAG-12B, a 12B-parameter model for grounded question answering in banking. It describes a data-efficient pipeline combining LLM-as-Judge filtering, citation annotation, and curriculum learning on 143M tokens. The resulting model is claimed to outperform GPT-4.1 on citation grounding (with a modest tradeoff versus the untuned base), achieve calibrated refusal via training on 22% unanswerable examples (yielding 12% 'I don't know' rate vs. base 4.3% unsafe and GPT-4.1 20.2% over-refusal), and deliver 3-5x faster, 20-50x cheaper inference. The system is deployed at 40+ financial institutions, reporting a 7.1 percentage point improvement in query resolution (p < 0.001).
Significance. If the deployment and comparative results hold under rigorous controls, the work would offer a valuable, production-validated recipe for building reliable domain-specific LLMs in regulated sectors. The emphasis on data efficiency, explicit grounding, and calibrated refusal directly addresses adoption barriers in banking, while the scale of live deployment provides external grounding beyond synthetic benchmarks.
major comments (2)
- [Deployment results] The headline deployment result of a 7.1 pp improvement in query resolution (p < 0.001) at 40+ institutions is load-bearing for the 'production-validated' claim, yet the abstract and available text provide no pre/post design details, definition of 'query resolution', sample sizes, time windows, or regression controls for confounders such as workflow changes, user behavior shifts, or query-mix evolution. This prevents attribution of the delta specifically to the FinRAG framework rather than external factors.
- [Evaluation of grounding and refusal] The comparisons on citation grounding and refusal rates versus GPT-4.1 and the untuned base model lack any statement that evaluations used identical prompts, test sets, and decoding settings. Without matched conditions, the reported deltas (including the 7.1 pp gain and the 12% vs. 4.3%/20.2% refusal figures) cannot be interpreted as model-specific improvements.
minor comments (1)
- [Data generation pipeline] The abstract states '143M tokens' and '22% unanswerable examples' but does not indicate the source distribution or filtering criteria; adding a brief table or paragraph on data composition would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback, which helps clarify the strength of our production claims. We address each major comment below and have revised the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [Deployment results] The headline deployment result of a 7.1 pp improvement in query resolution (p < 0.001) at 40+ institutions is load-bearing for the 'production-validated' claim, yet the abstract and available text provide no pre/post design details, definition of 'query resolution', sample sizes, time windows, or regression controls for confounders such as workflow changes, user behavior shifts, or query-mix evolution. This prevents attribution of the delta specifically to the FinRAG framework rather than external factors.
Authors: We agree that more methodological detail is needed to support attribution. In the revised manuscript we have added a dedicated 'Deployment Evaluation' subsection that defines 'query resolution' as the share of queries resolved without escalation to human agents, reports the evaluation window (Q3 2024), and states the aggregate sample (>500k queries across the 40+ institutions). The reported p-value is from a paired t-test on institution-level pre/post differences. However, full regression controls for all possible confounders remain unavailable because of strict data-sharing restrictions imposed by the participating banks; we now explicitly note this limitation and describe the steps taken to minimize confounding (e.g., holding workflow and query-mix constant within each institution). revision: partial
-
Referee: [Evaluation of grounding and refusal] The comparisons on citation grounding and refusal rates versus GPT-4.1 and the untuned base model lack any statement that evaluations used identical prompts, test sets, and decoding settings. Without matched conditions, the reported deltas (including the 7.1 pp gain and the 12% vs. 4.3%/20.2% refusal figures) cannot be interpreted as model-specific improvements.
Authors: All reported comparisons were performed under matched conditions. The same 2,000-query held-out banking test set, identical prompt templates, and fixed decoding parameters (temperature 0.7, top-p 0.9, max tokens 512) were used for FinRAG-12B, the untuned base model, and GPT-4.1. We have inserted an explicit paragraph in the Evaluation section stating these controls and have added the full prompt templates to Appendix B so that the conditions are fully reproducible. revision: yes
- Complete regression controls and raw pre/post data for the live deployment, which cannot be released due to confidentiality agreements with the financial institutions.
Circularity Check
No circularity: purely empirical claims with no derivations
full rationale
The paper reports empirical results from a data-generation pipeline, model training on 143M tokens, and live deployment at 40+ institutions. No equations, first-principles derivations, or predictions appear anywhere in the abstract or described content. Performance deltas (citation grounding, 12% refusal rate, 7.1 pp query-resolution gain) are presented as measured outcomes, not quantities derived from fitted parameters or self-referential definitions. No self-citation chains, uniqueness theorems, or ansatz smuggling are invoked to support the central claims. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- percentage of unanswerable examples
axioms (2)
- domain assumption LLM-as-a-Judge can reliably filter and annotate high-quality, citable examples from banking documents
- standard math Standard supervised fine-tuning with curriculum learning produces grounded, domain-adapted behavior
Reference graph
Works this paper leans on
-
[1]
Textbooks are all you need.arXiv preprint arXiv:2306.11644. Suchin Gururangan, Ana Marasovi ´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A. Smith. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360. Edwar...
work page internal anchor Pith review arXiv 2020
-
[2]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jiasheng Ye, Peiju Liu, Tianxiang Sun, Yunhua Zhou, Jun Zhan, and Xipeng Qiu. 2024. Data mix- ing laws: Optimizing data mixtures by predicting language modeling performance.arXiv preprint arXiv:2403.16952. Jinghui Zhang, Dandan Qiao, Mochen Yang, and Qiang Wei. 2024. Regurgitative training: The value...
work page internal anchor Pith review arXiv 2024
-
[3]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631. A Training Hyperparameters Parameter Value Base Model Gemma 3 12B-IT LoRA Rank (r) 64 LoRA Alpha (α) 256 LoRA Dropout 0.05 Target Modules q,k,v,o,gate,up,down Learning Rate2×10 −5 Optimizer AdamW-8bit Batch Size 4 Gradient Accumulation 4 Effective Batch Size 16 ...
-
[4]
Read the numbered sources about financial topics
-
[5]
Generate a natural, standalone question based on one of the sources
-
[6]
the text
Provide a well-cited answer using the source information Important: - The question should NOT refer to "the text", "the passage", or "the document" - The question should be specific and answerable from the provided sources - Include citations [1], [2], etc. when referencing source content - If the sources don't contain enough information, respond with the...
-
[7]
Choose ONE source that contains interesting or important financial information
-
[8]
Generate a natural question about that source's content
-
[9]
Provide a concise answer citing the relevant sources with [N] notation
-
[10]
I don't know
If sources don't support a good question, respond with: "I don't know." **Output Format (JSON):** { "question": "Your generated question here", "answer": "Your answer with [1], [2] citations" } Generate the question-answer pair: C.3 Answer Generation with Hint The full pipeline generates answers with a hint identifying the gold source. This is the prompt ...
-
[11]
Answer the Question using only the information from the provided sources
-
[12]
Include source citations using their corresponding numbers (e.g., [1])
-
[13]
Every answer must contain at least one citation
-
[14]
Only cite a source if you directly reference it
-
[15]
Keep the answer concise and focused
-
[16]
Use bulleted lists for clarity if multiple points are made
-
[17]
I don't know
If none of the sources are relevant, respond with "I don't know." and stop. Context: The following numbered sources are provided. --------------------- {{context|numbered}} --------------------- Hint: The correct answer should be found in the source number {{hint}}. Question: {{question}} Answer: The no_hint ablation variant is identical except the hint l...
-
[18]
Provide a brief evaluation summary
-
[19]
- Answer Quality: Clarity, correctness, and conciseness
Score the response (0-10) for: - Source Relevance: How well the sources support the answer. - Answer Quality: Clarity, correctness, and conciseness. - Citation Usage: Appropriateness and accuracy of citations. - Information Synthesis: How well the information is integrated. - Faithfulness: Accuracy relative to the provided sources
-
[20]
List key strengths, weaknesses, and improvement suggestions
-
[21]
scores": {...},
Provide an overall rating (0-10). </structure> Return ONLY a JSON object: { "scores": {...}, "analysis": {...}, "overall_rating": <0-10> } The five sub-scores are averaged to produce the Citation Quality composite (0–100) reported in Ta- bles 4 and 6. E.2 Answer Quality Judge (JudgeLM 7B) JudgeLM (Zhu et al., 2023) uses a comparative evaluation format, sc...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.