Recognition: unknown
AstroAlertBench: Evaluating the Accuracy, Reasoning, and Honesty of Multimodal LLMs in Astronomical Classification
Pith reviewed 2026-05-08 05:18 UTC · model grok-4.3
The pith
Multimodal LLMs show a disconnect between classification accuracy and honest self-evaluation on astronomical transient alerts
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
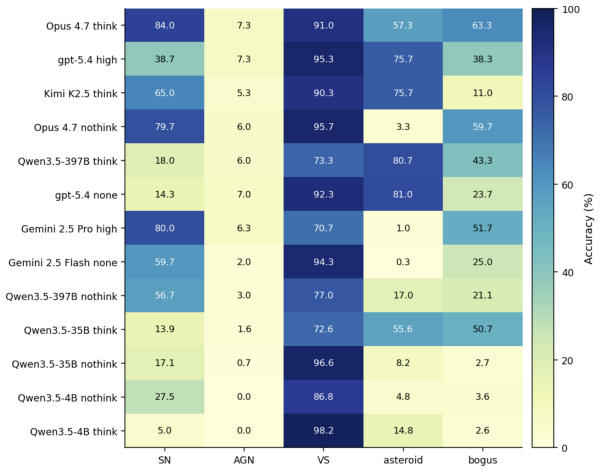
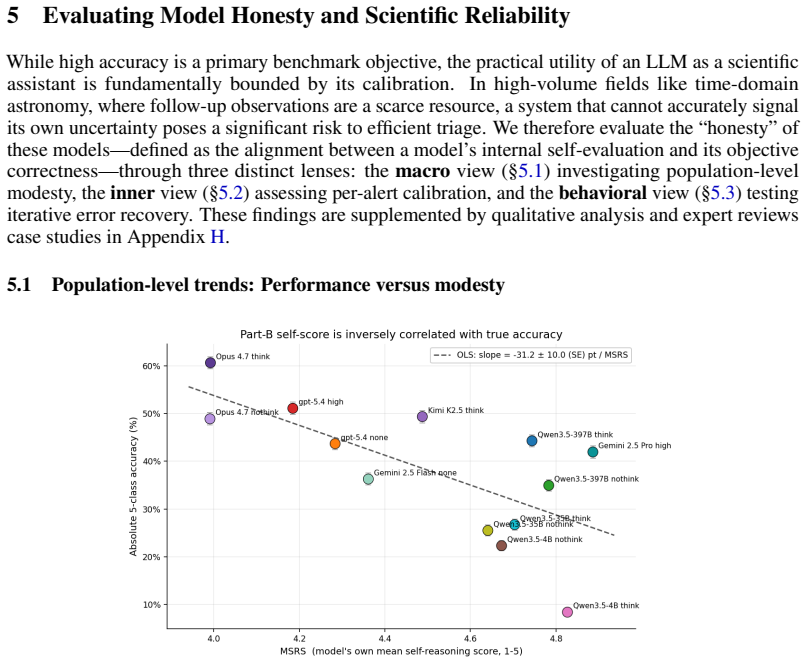
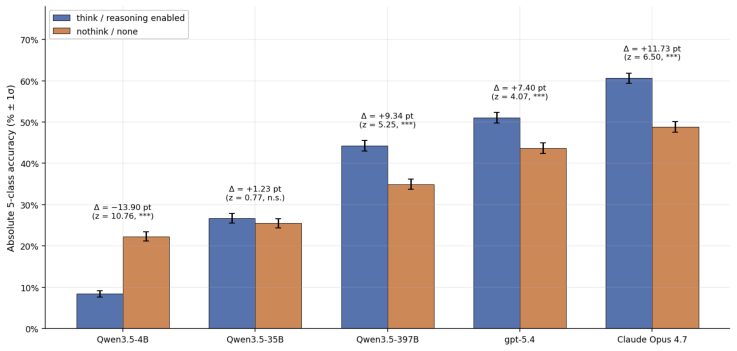
AstroAlertBench evaluates thirteen frontier multimodal LLMs on a pilot set of 1,500 real ZTF alerts by requiring each model to complete metadata grounding, scientific reasoning, and hierarchical classification; the evaluation finds that high accuracy scores frequently do not coincide with the models' ability to self-assess the validity of their reasoning chains.
What carries the argument
The three-stage logical chain of metadata grounding, scientific reasoning, and hierarchical classification, together with an independent honesty metric that scores how accurately a model evaluates its own reasoning quality.
If this is right
- High-accuracy models cannot be treated as automatically reliable for live astronomical data review because they may still misjudge their own reasoning.
- The benchmark supplies a repeatable protocol for measuring both performance and self-awareness in scientific classification tasks.
- A human-in-the-loop review stage allows experts to annotate model outputs and thereby improve future iterations of the benchmark.
- Separate tracking of accuracy and honesty creates a concrete target for training methods that aim to make model self-assessment match actual correctness.
Where Pith is reading between the lines
- Surveys with different instruments or wavelengths could be added to test whether the accuracy-honesty gap persists across data types.
- Models that perform well on both metrics could be used as an initial filter to surface only the most uncertain alerts for human astronomers.
- The same staged evaluation plus honesty check might be adapted to other image-plus-text scientific domains such as medical or materials imaging.
Load-bearing premise
The 1,500-alert pilot sample from one survey stands in for the full diversity of astronomical data and that the honesty metric validly tracks real-world reliability of LLM outputs.
What would settle it
A larger and more diverse set of alerts in which every high-accuracy model also scores high on the honesty metric would show that the observed misalignment between accuracy and honesty is not a general feature.
Figures



















read the original abstract
Modern astronomical observatories generate a massive volume of multimodal data, creating a critical bottleneck for expert human review. While multimodal large language models (LLMs) have shown promise in interpreting complex visual and textual inputs, their ability to perform specialized scientific classification while providing interpretable reasoning remains understudied. We introduce AstroAlertBench, a comprehensive multimodal benchmark designed to evaluate LLM performance in astronomical event review along a three-stage logical chain: metadata grounding, scientific reasoning, and hierarchical classification over five categories. We use a pilot sample of 1,500 real-world alerts from the Zwicky Transient Facility (ZTF), a wide-field survey that scans the northern sky to detect transient astronomical events. On this dataset, we benchmark 13 frontier closed-source and open-weight LLMs that support visual input. Our results reveal that high accuracy does not always align with model ``honesty,'' defined as the ability to self-evaluate its reasoning, which affects its reliability as a real-world assistant. We further initialize a human-in-the-loop evaluation protocol as a precursor to future community-scale participation. Together, AstroAlertBench provides a framework for developing calibrated and interpretable astronomical assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AstroAlertBench, a multimodal benchmark for evaluating 13 frontier LLMs on astronomical transient classification using a pilot sample of 1,500 real ZTF alerts. Models are assessed along a three-stage logical chain (metadata grounding, scientific reasoning, hierarchical classification into five categories). The central result is that high accuracy does not always align with model 'honesty' (self-evaluation of reasoning), which the authors argue affects reliability as real-world assistants; a human-in-the-loop protocol is also initialized as a precursor to community evaluation.
Significance. If the results hold, the work is significant for astroinformatics by supplying a real-data framework to probe LLM limitations beyond raw accuracy in a high-volume scientific domain. Use of authentic ZTF alerts and the start of a human-in-the-loop protocol are strengths that support reproducible benchmarking and future community-scale participation. The focus on reasoning honesty directly addresses a practical barrier to deploying multimodal models as reliable astronomical assistants.
major comments (2)
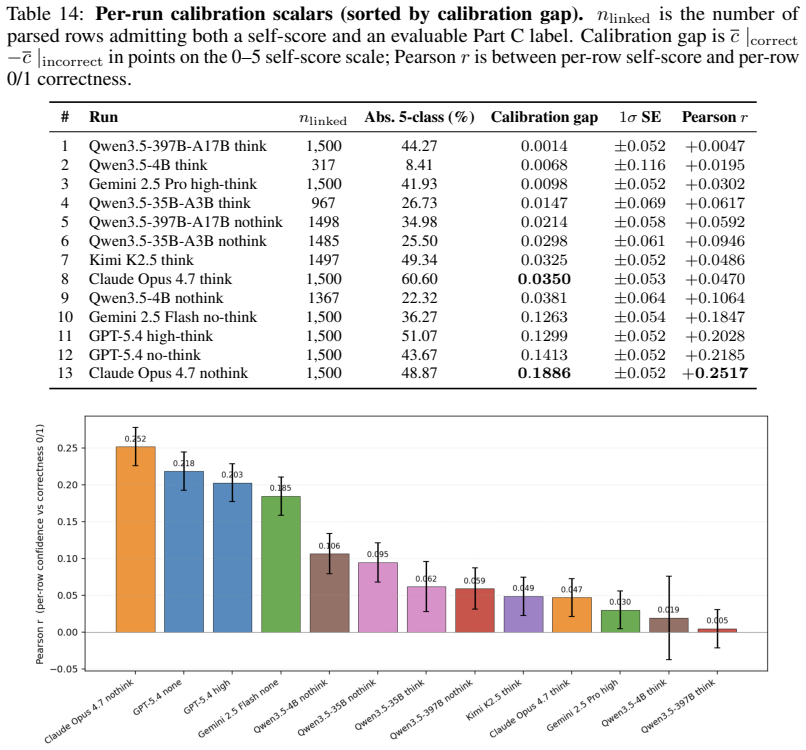
- [§3 (Benchmark Design)] §3 (Benchmark Design): The honesty metric (self-evaluation of reasoning) is introduced as a key indicator that misalignment with accuracy reduces real-world reliability, yet the manuscript shows no independent validation or correlation with external criteria such as expert agreement on classifications, uncertainty calibration, or performance in a deployed human-in-the-loop setting. This is load-bearing for the central claim.
- [§4 (Results)] §4 (Results): The analysis of the 1,500-alert pilot sample reports no statistical significance tests, error analysis, confidence intervals on accuracy-honesty scores, or assessment of selection biases in the ZTF alerts; these omissions leave the observed misalignment only moderately supported as a general finding.
minor comments (2)
- [Abstract] The abstract states that five classification categories are used but does not enumerate them, which would improve immediate clarity for readers.
- [§2 (Related Work)] Additional references to prior LLM evaluation benchmarks in scientific domains would better situate AstroAlertBench within the existing literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of validation and statistical rigor that we will address in revision. We respond point-by-point to the major comments below.
read point-by-point responses
-
Referee: [§3 (Benchmark Design)] The honesty metric (self-evaluation of reasoning) is introduced as a key indicator that misalignment with accuracy reduces real-world reliability, yet the manuscript shows no independent validation or correlation with external criteria such as expert agreement on classifications, uncertainty calibration, or performance in a deployed human-in-the-loop setting. This is load-bearing for the central claim.
Authors: We acknowledge that the honesty metric, based on model self-evaluation of reasoning quality, lacks direct correlation with external validators such as expert agreement or calibrated uncertainty in the current pilot results. The manuscript presents the observed accuracy-honesty misalignment as an empirical finding from the 1,500 ZTF alerts and positions the human-in-the-loop protocol as an initial step toward such validation. We agree this aspect requires clearer framing. In revision, we will expand the discussion in §3 and add a limitations subsection to explicitly note the absence of independent validation in this pilot, describe how the human-in-the-loop setup is designed to enable future expert correlations, and outline planned analyses for uncertainty calibration. These changes will qualify the central claim as preliminary while preserving the observed misalignment as a motivating observation. revision: partial
-
Referee: [§4 (Results)] The analysis of the 1,500-alert pilot sample reports no statistical significance tests, error analysis, confidence intervals on accuracy-honesty scores, or assessment of selection biases in the ZTF alerts; these omissions leave the observed misalignment only moderately supported as a general finding.
Authors: The 1,500-alert dataset is presented throughout as a pilot sample whose primary purpose is to demonstrate the benchmark framework rather than support broad statistical generalizations. We agree that the results section would benefit from additional quantitative support. In the revised manuscript, we will add bootstrap-derived confidence intervals for accuracy and honesty scores, include basic error analysis with examples of misalignment cases, perform appropriate significance tests (e.g., McNemar or chi-squared tests for paired accuracy-honesty differences where applicable), and discuss potential selection biases in the ZTF alerts (such as magnitude limits, sky coverage, or transient type distributions). These updates will be incorporated into §4 and the supplementary material. revision: yes
Circularity Check
No circularity: empirical benchmark grounded in external data
full rationale
The paper is a pure empirical evaluation study that introduces AstroAlertBench as an operational framework for testing LLMs on 1,500 real ZTF alerts. The three-stage logical chain and honesty metric are defined as part of the benchmark protocol and applied to external model outputs and human review; results are reported as direct observations from this data rather than derived from any equations, fitted parameters, or self-referential predictions. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The derivation chain is therefore self-contained against external benchmarks and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three-stage logical chain (metadata grounding, scientific reasoning, and hierarchical classification) captures the essential aspects of astronomical event review.
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
Tinker , author =. 2025 , howpublished =
2025
-
[2]
2026 , month = feb, howpublished =
Qwen3.5: Towards Native Multimodal Agents , author =. 2026 , month = feb, howpublished =
2026
-
[3]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review arXiv
-
[4]
2026 , month = mar, howpublished =
GPT-5.4 Thinking System Card , author =. 2026 , month = mar, howpublished =
2026
-
[5]
2026 , month = apr, howpublished =
Claude Opus 4.7 System Card , author =. 2026 , month = apr, howpublished =
2026
-
[6]
ResearchBench: Benchmarking LLMs in Scientific Discovery via Inspiration-Based Task Decomposition
Researchbench: Benchmarking llms in scientific discovery via inspiration-based task decomposition , author=. arXiv preprint arXiv:2503.21248 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts , author=. arXiv preprint arXiv:2310.02255 , year=
work page internal anchor Pith review arXiv
-
[8]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[9]
The Zwicky Transient Facility Bright Transient Survey. III. BTSbot: automated identification and follow-up of bright transients with deep learning , author=. The Astrophysical Journal , volume=. 2024 , publisher=
2024
-
[10]
Publications of the Astronomical Society of the Pacific , volume=
The zwicky transient facility alert distribution system , author=. Publications of the Astronomical Society of the Pacific , volume=. 2019 , publisher=
2019
-
[11]
The Astronomical Journal , volume=
Alert classification for the ALeRCE broker system: the real-time stamp classifier , author=. The Astronomical Journal , volume=. 2021 , publisher=
2021
-
[12]
Kimi K2.5: Visual Agentic Intelligence
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
work page internal anchor Pith review arXiv
-
[13]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[14]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[15]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[16]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review arXiv
-
[17]
arXiv preprint arXiv:2304.05376 , year=
Chemcrow: Augmenting large-language models with chemistry tools , author=. arXiv preprint arXiv:2304.05376 , year=
-
[18]
arXiv preprint arXiv:2304.05332 , year=
Emergent autonomous scientific research capabilities of large language models , author=. arXiv preprint arXiv:2304.05332 , year=
-
[19]
SC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages=
AstroMLab 2: AstroLLaMA-2-70B model and benchmarking specialised LLMs for astronomy , author=. SC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages=. 2024 , organization=
2024
-
[20]
Nature Astronomy , volume=
Textual interpretation of transient image classifications from large language models , author=. Nature Astronomy , volume=. 2025 , publisher=
2025
-
[21]
Publications of the Astronomical Society of the Pacific , volume=
Machine learning for the zwicky transient facility , author=. Publications of the Astronomical Society of the Pacific , volume=. 2019 , publisher=
2019
-
[22]
The Astronomical Journal , volume=
Alert classification for the ALeRCE broker system: The light curve classifier , author=. The Astronomical Journal , volume=. 2021 , publisher=
2021
-
[23]
The Astronomical Journal , volume=
The automatic learning for the rapid classification of events (ALeRCE) alert broker , author=. The Astronomical Journal , volume=. 2021 , publisher=
2021
-
[24]
Publications of the Astronomical Society of the Pacific , volume=
The zwicky transient facility: science objectives , author=. Publications of the Astronomical Society of the Pacific , volume=. 2019 , publisher=
2019
-
[25]
Monthly Notices of the Royal Astronomical Society , volume=
Real-bogus classification for the Zwicky Transient Facility using deep learning , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2019 , publisher=
2019
-
[26]
Publications of the Astronomical Society of the Pacific , volume=
The zwicky transient facility: Data processing, products, and archive , author=. Publications of the Astronomical Society of the Pacific , volume=. 2019 , publisher=
2019
-
[27]
Publications of the Astronomical Society of the Pacific , volume=
The Zwicky Transient Facility: system overview, performance, and first results , author=. Publications of the Astronomical Society of the Pacific , volume=. 2019 , publisher=
2019
-
[28]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[29]
International conference on machine learning , pages=
On calibration of modern neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[30]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review arXiv
-
[31]
Advances in Neural Information Processing Systems , volume=
Can llms solve molecule puzzles? a multimodal benchmark for molecular structure elucidation , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Nature , volume=
Mathematical discoveries from program search with large language models , author=. Nature , volume=. 2024 , publisher=
2024
-
[33]
Galactica: A Large Language Model for Science
Galactica: A large language model for science , author=. arXiv preprint arXiv:2211.09085 , year=
work page internal anchor Pith review arXiv
-
[34]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review arXiv
-
[35]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[36]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[37]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review arXiv
-
[38]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[39]
Games and economic behavior , volume=
Potential games , author=. Games and economic behavior , volume=. 1996 , publisher=
1996
-
[40]
Concurrent submission to NeurIPS 2026 , year=
Pessimism-Free Offline Learning in General-Sum Games via KL Regularization , author=. Concurrent submission to NeurIPS 2026 , year=
2026
-
[41]
International Conference on Machine Learning , pages=
Independent policy gradient for large-scale markov potential games: Sharper rates, function approximation, and game-agnostic convergence , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[42]
IEEE Control Systems Letters , volume=
Learning Nash in constrained Markov games with an -potential , author=. IEEE Control Systems Letters , volume=. 2024 , publisher=
2024
-
[43]
2025 IEEE 64th Conference on Decision and Control (CDC) , pages=
Markov potential game construction and multi-agent reinforcement learning with applications to autonomous driving , author=. 2025 IEEE 64th Conference on Decision and Control (CDC) , pages=. 2025 , organization=
2025
-
[44]
arXiv preprint arXiv:2106.01969 , year=
Global convergence of multi-agent policy gradient in markov potential games , author=. arXiv preprint arXiv:2106.01969 , year=
-
[45]
IEEE Transactions on Automatic Control , year=
Markov -Potential Games , author=. IEEE Transactions on Automatic Control , year=
-
[46]
2025 , publisher=
An -Potential Game Framework for Non-Cooperative Dynamic Games: Theory and Algorithms , author=. 2025 , publisher=
2025
-
[47]
SIAM Journal on Control and Optimization , volume=
An-Potential Game Framework for-Player Dynamic Games , author=. SIAM Journal on Control and Optimization , volume=. 2025 , publisher=
2025
-
[48]
arXiv preprint arXiv:2305.12553 , year=
Markov -Potential Games , author=. arXiv preprint arXiv:2305.12553 , year=
-
[49]
arXiv preprint arXiv:2310.06243 , year=
Sample-efficient multi-agent rl: An optimization perspective , author=. arXiv preprint arXiv:2310.06243 , year=
-
[50]
Corruption-robust Offline Multi-agent Reinforcement Learning From Human Feedback
Corruption-robust Offline Multi-agent Reinforcement Learning From Human Feedback , author=. arXiv preprint arXiv:2603.28281 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Journal of the ACM (JACM) , volume=
Settling the complexity of computing two-player Nash equilibria , author=. Journal of the ACM (JACM) , volume=. 2009 , publisher=
2009
-
[52]
Journal of Computer and system Sciences , volume=
On the complexity of the parity argument and other inefficient proofs of existence , author=. Journal of Computer and system Sciences , volume=. 1994 , publisher=
1994
-
[53]
Communications of the ACM , volume=
The complexity of computing a Nash equilibrium , author=. Communications of the ACM , volume=. 2009 , publisher=
2009
-
[54]
International conference on machine learning , pages=
Pessimistic q-learning for offline reinforcement learning: Towards optimal sample complexity , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[55]
Operations research , volume=
Model-based reinforcement learning for offline zero-sum Markov games , author=. Operations research , volume=. 2024 , publisher=
2024
-
[56]
Beyond Pessimism: Offline Learning in KL-regularized Games
Beyond Pessimism: Offline Learning in KL-regularized Games , author=. arXiv preprint arXiv:2604.06738 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[58]
2016 , publisher=
Twenty lectures on algorithmic game theory , author=. 2016 , publisher=
2016
-
[59]
2006 , publisher=
Prediction, learning, and games , author=. 2006 , publisher=
2006
-
[60]
Theory of computing , volume=
The multiplicative weights update method: a meta-algorithm and applications , author=. Theory of computing , volume=. 2012 , publisher=
2012
-
[61]
Machine Intelligence Research , volume=
Offline pre-trained multi-agent decision transformer , author=. Machine Intelligence Research , volume=. 2023 , publisher=
2023
-
[62]
arXiv preprint arXiv:2102.04402 , year=
Contrasting centralized and decentralized critics in multi-agent reinforcement learning , author=. arXiv preprint arXiv:2102.04402 , year=
-
[63]
International Journal of Group Decision and Negotiation , volume=
Automated negotiation: prospects, methods and challenges , author=. International Journal of Group Decision and Negotiation , volume=
-
[64]
2001 , publisher=
Strategic negotiation in multiagent environments , author=. 2001 , publisher=
2001
-
[65]
Communications of the ACM , volume=
Algorithmic game theory , author=. Communications of the ACM , volume=. 2010 , publisher=
2010
-
[66]
Econometrica: Journal of the Econometric Society , pages=
A theory of auctions and competitive bidding , author=. Econometrica: Journal of the Econometric Society , pages=. 1982 , publisher=
1982
-
[67]
Games and Economic Behavior , volume=
On the value of information in a strategic conflict , author=. Games and Economic Behavior , volume=. 1990 , publisher=
1990
-
[68]
1995 , publisher=
Repeated games with incomplete information , author=. 1995 , publisher=
1995
-
[69]
Bayesian
Games with incomplete information played by “Bayesian” players, I--III Part I. The basic model , author=. Management science , volume=. 1967 , publisher=
1967
-
[70]
Mathematics of operations research , volume=
Optimal auction design , author=. Mathematics of operations research , volume=. 1981 , publisher=
1981
-
[71]
The Journal of finance , volume=
Counterspeculation, auctions, and competitive sealed tenders , author=. The Journal of finance , volume=. 1961 , publisher=
1961
-
[72]
Proceedings of the national academy of sciences , volume=
Stochastic games , author=. Proceedings of the national academy of sciences , volume=. 1953 , publisher=
1953
-
[73]
Behavior Regularized Offline Reinforcement Learning
Behavior regularized offline reinforcement learning , author=. arXiv preprint arXiv:1911.11361 , year=
work page internal anchor Pith review arXiv 1911
-
[74]
Proceedings of the AAAI conference on artificial intelligence , volume=
Adaptive trust region policy optimization: Global convergence and faster rates for regularized mdps , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[75]
Foundations and Trends
Online learning and online convex optimization , author=. Foundations and Trends. 2025 , publisher=
2025
-
[76]
2000 , publisher=
Empirical Processes in M-estimation , author=. 2000 , publisher=
2000
-
[77]
IEEE transactions on information theory , volume=
Minimum complexity density estimation , author=. IEEE transactions on information theory , volume=. 2002 , publisher=
2002
-
[78]
, author=
On general minimax theorems. , author=
-
[79]
Dynamic Games and Applications , volume=
Upper and lower values in zero-sum stochastic games with asymmetric information , author=. Dynamic Games and Applications , volume=. 2021 , publisher=
2021
-
[80]
Games and Economic Behavior , volume=
Adaptive game playing using multiplicative weights , author=. Games and Economic Behavior , volume=. 1999 , publisher=
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.