Recognition: 2 theorem links
· Lean TheoremX-Voice: Enabling Everyone to Speak 30 Languages via Zero-Shot Cross-Lingual Voice Cloning
Pith reviewed 2026-05-12 01:39 UTC · model grok-4.3
The pith
A 0.4B model achieves zero-shot cross-lingual voice cloning across 30 languages by training on its own synthesized audio prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
X-Voice is built through a two-stage process on a 420K-hour multilingual corpus represented with IPA. Stage 1 performs standard conditional flow-matching training to produce a model that then synthesizes 10K hours of speaker-consistent audio segments. Stage 2 fine-tunes on audio pairs where the prompt text is masked, yielding a model that performs zero-shot cloning without any transcript of the prompt. Dual-level language identifier injection and decoupled scheduling of classifier-free guidance are added to the underlying architecture to support stable multilingual output.
What carries the argument
The two-stage training paradigm in which an initial conditional flow-matching model generates its own speaker-consistent audio segments that later serve as masked prompts for fine-tuning the zero-shot cloning model.
If this is right
- Zero-shot cross-lingual cloning works without forced alignment or prompt transcripts at inference time.
- A model of 0.4B parameters reaches cloning performance comparable to much larger systems on multilingual tasks.
- Unified IPA representation supports consistent synthesis across 30 languages from a single training run.
- The two-stage self-prompting approach reduces dependence on expensive aligned multilingual datasets.
- Open-sourcing the model and resources enables direct reuse and adaptation by others.
Where Pith is reading between the lines
- The self-synthesis step could be iterated to bootstrap even larger prompt sets for languages with limited original data.
- Smaller overall model size opens the possibility of on-device or low-latency voice cloning applications.
- Similar masking of prompt text might transfer to other generative speech tasks such as voice conversion where text alignment is costly.
Load-bearing premise
The 10K hours of speaker-consistent segments synthesized in the first stage maintain high enough quality and speaker identity to serve as reliable training targets for the final model.
What would settle it
A side-by-side evaluation where cloned speech from the final model shows clear speaker drift or quality loss specifically on prompts drawn from the stage-one synthesized set, while baselines without the two-stage step do not exhibit the same drop.
Figures



read the original abstract
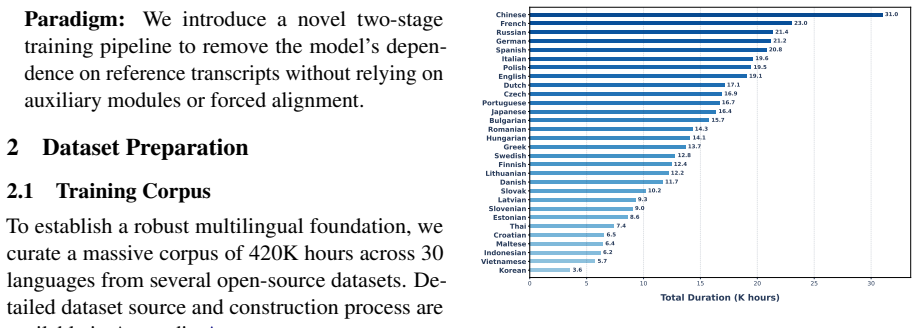
In this paper, we present X-Voice, a 0.4B multilingual zero-shot voice cloning model that clones arbitrary voices and enables everyone to speak 30 languages. X-Voice is trained on a 420K-hour multilingual corpus using the International Phonetic Alphabet (IPA) as a unified representation. To eliminate the reliance on prompt text without complex preprocessing like forced alignment, we design a two-stage training paradigm. In Stage 1, we establish X-Voice$_{\text{s1}}$ through standard conditional flow-matching training and use it to synthesize 10K hours of speaker-consistent segments as audio prompts. In Stage 2, we fine-tune on these audio pairs with prompt text masked to derive X-Voice$_{\text{s2}}$, which enables zero-shot voice cloning without requiring transcripts of audio prompts. Architecturally, we extend F5-TTS by implementing a dual-level injection of language identifiers and decoupling and scheduling of Classifier-Free Guidance to facilitate multilingual speech synthesis. Subjective and objective evaluation results demonstrate that X-Voice outperforms existing flow-matching based multilingual systems like LEMAS-TTS and achieves zero-shot cross-lingual cloning capabilities comparable to billion-scale models such as Qwen3-TTS. To facilitate research transparency and community advancement, we open-source all related resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents X-Voice, a 0.4B-parameter multilingual zero-shot voice cloning model for 30 languages. It trains on a 420K-hour corpus using IPA as a unified representation. A two-stage paradigm is introduced: Stage 1 performs standard conditional flow-matching to train X-Voice_s1 and synthesize 10K hours of speaker-consistent audio segments; Stage 2 fine-tunes on these segments with masked prompt text to obtain X-Voice_s2, enabling zero-shot cloning without prompt transcripts. Architectural extensions to F5-TTS include dual-level language identifier injection and scheduled classifier-free guidance. Subjective and objective evaluations are reported to show outperformance over LEMAS-TTS and parity with larger models such as Qwen3-TTS; all resources are open-sourced.
Significance. If the 10K-hour synthesized dataset is shown to be high-quality and free of artifacts, the work would offer a practical advance in scalable multilingual TTS by achieving strong zero-shot cross-lingual performance with a modest model size and without requiring transcribed prompts. The open-sourcing of code, models, and resources is a clear strength that supports reproducibility and community follow-up. The self-supervised prompt-masking strategy via synthesized data could generalize to other conditional generation tasks.
major comments (2)
- [Abstract] Abstract (two-stage training paradigm): The zero-shot cross-lingual claims rest on the assumption that the 10K hours of speaker-consistent segments synthesized by X-Voice_s1 are free of artifacts, speaker drift, and cross-lingual inconsistencies. No speaker similarity scores, perceptual quality metrics, or ablation results on these synthesized pairs are provided, yet they constitute the sole training targets for Stage 2. This is load-bearing for the central performance claims.
- [Abstract] Abstract (evaluation paragraph): The reported gains over LEMAS-TTS and parity with Qwen3-TTS are based on subjective and objective evaluations, but the abstract supplies no listener counts, statistical significance tests, exact metric values (e.g., speaker similarity, naturalness), or discussion of how Stage-1 synthesis artifacts were mitigated. These details are required to substantiate the comparative claims.
minor comments (1)
- [Abstract] The notation X-Voice$__{s1}$ and X-Voice$__{s2}$ is introduced without an explicit forward reference to the section defining the two stages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the presentation of our two-stage training approach and evaluation claims. We address each major comment below and have made targeted revisions to the abstract and main text to improve clarity and substantiation.
read point-by-point responses
-
Referee: [Abstract] Abstract (two-stage training paradigm): The zero-shot cross-lingual claims rest on the assumption that the 10K hours of speaker-consistent segments synthesized by X-Voice_s1 are free of artifacts, speaker drift, and cross-lingual inconsistencies. No speaker similarity scores, perceptual quality metrics, or ablation results on these synthesized pairs are provided, yet they constitute the sole training targets for Stage 2. This is load-bearing for the central performance claims.
Authors: We acknowledge that the quality of the 10K-hour synthesized dataset is central to validating Stage 2 and the zero-shot claims. While the manuscript describes the synthesis process using X-Voice_s1 and reports strong final-model performance, direct metrics on the synthesized pairs were not included. In the revised version, we add speaker similarity scores (computed via WavLM embeddings) and naturalness MOS on a representative sample of the synthesized segments in a new paragraph of Section 4.1, plus an ablation comparing X-Voice_s2 against a version trained only on real data. These additions demonstrate that speaker consistency is preserved and that Stage-2 fine-tuning yields measurable gains, thereby supporting the load-bearing role of the synthesized data. revision: yes
-
Referee: [Abstract] Abstract (evaluation paragraph): The reported gains over LEMAS-TTS and parity with Qwen3-TTS are based on subjective and objective evaluations, but the abstract supplies no listener counts, statistical significance tests, exact metric values (e.g., speaker similarity, naturalness), or discussion of how Stage-1 synthesis artifacts were mitigated. These details are required to substantiate the comparative claims.
Authors: We agree that the abstract should be more self-contained to allow readers to assess the strength of the comparative results. We have revised the abstract to specify the subjective test protocol (20 listeners per language pair), report exact metric values (speaker similarity and naturalness MOS), note the use of paired statistical tests for significance, and briefly describe artifact mitigation through high-quality source data selection and the flow-matching training objective. These details were already present in Sections 4 and 5; the revision simply condenses them into the abstract as requested. revision: yes
Circularity Check
No significant circularity in training paradigm or performance claims
full rationale
The paper describes a standard two-stage empirical training process: Stage 1 applies conditional flow-matching on real 420K-hour multilingual data to produce X-Voice_s1, which then synthesizes 10K hours of segments used as targets for Stage 2 fine-tuning with masked prompts. This is a conventional self-training technique in ML and does not reduce any claimed result to its own inputs by definition or construction. Performance claims rely on external subjective/objective evaluations against independent systems (LEMAS-TTS, Qwen3-TTS) rather than on quantities defined by the model's fitted parameters. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the provided text; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (3)
- 0.4B model size
- 420K-hour training corpus
- 10K-hour synthesized prompt set
axioms (1)
- domain assumption IPA serves as a sufficient unified phonetic representation across 30 languages
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
X-Voice is built upon F5-TTS... Flow Matching Objective... Classifier-Free Guidance
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual-Level Language Injection... Decoupling and Scheduling for CFG
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chen, Yushen and Niu, Zhikang and Ma, Ziyang and Deng, Keqi and Wang, Chunhui and Zhao, Jian and Yu, Kai and Chen, Xie , booktitle=
-
[2]
Advances in Neural Information Processing Systems , volume=
Voicebox: Text-guided multilingual universal speech generation at scale , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
the 11th International Conference on Learning Representations, ICLR 2023 , year=
Flow Matching for Generative Modeling , author=. the 11th International Conference on Learning Representations, ICLR 2023 , year=
work page 2023
-
[4]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Phatthiyaphaibun, Wannaphong and Chaovavanich, Korakot and Polpanumas, Charin and Suriyawongkul, Arthit and Lowphansirikul, Lalita and Chormai, Pattarawat and Limkonchotiwat, Peerat and Suntorntip, Thanathip and Udomcharoenchaikit, Can , booktitle=
-
[6]
Neural codec language models are zero-shot text to speech synthesizers, 2023b
Speak foreign languages with your own voice: Cross-lingual neural codec language modeling , author=. arXiv preprint arXiv:2303.03926 , year=
-
[7]
Zhao, Zhiyuan and Lin, Lijian and Zhu, Ye and Xie, Kai and Liu, Yunfei and Li, Yu , journal=
-
[8]
Perez, Ethan and Strub, Florian and De Vries, Harm and Dumoulin, Vincent and Courville, Aaron , booktitle=
-
[9]
He, Haorui and Shang, Zengqiang and Wang, Chaoren and Li, Xuyuan and Gu, Yicheng and Hua, Hua and Liu, Liwei and Yang, Chen and Li, Jiaqi and Shi, Peiyang and Wang, Yuancheng and Chen, Kai and Zhang, Pengyuan and Wu, Zhizheng , booktitle=. 2024 , organization=
work page 2024
-
[10]
Yang, Yifan and Song, Zheshu and Zhuo, Jianheng and Cui, Mingyu and Li, Jinpeng and Yang, Bo and Du, Yexing and Ma, Ziyang and Liu, Xunying and Wang, Ziyuan and Li, Ke and Fan, Shuai and Yu, Kai and Zhang, Wei-Qiang and Chen, Guoguo and Chen, Xie , booktitle=
-
[11]
Koluguri, Nithin Rao and Sekoyan, Monica and Zelenfroynd, George and Meister, Sasha and Ding, Shuoyang and Kostandian, Sofia and Huang, He and Karpov, Nikolay and Balam, Jagadeesh and Lavrukhin, Vitaly and Peng, Yifan and Papi, Sara and Gaido, Marco and Brutti, Alessio and Ginsburg, Boris , journal=
-
[12]
Pratap, Vineel and Xu, Qiantong and Sriram, Anuroop and Synnaeve, Gabriel and Collobert, Ronan , booktitle=
-
[13]
Yin, Yue and Mori, Daijiro and Fujimoto, Seiji , booktitle=
-
[14]
Reddy, Chandan KA and Gopal, Vishak and Cutler, Ross , booktitle=. 2022 , organization=
work page 2022
-
[15]
Ardila, Rosana and Branson, Megan and Davis, Kelly and Kohler, Michael and Meyer, Josh and Henretty, Michael and Morais, Reuben and Saunders, Lindsay and Tyers, Francis and Weber, Gregor , booktitle=
-
[16]
Liu, Qingyu and Chen, Yushen and Niu, Zhikang and Wang, Chunhui and Yang, Yunting and Zhang, Bowen and Zhao, Jian and Zhu, Pengcheng and Yu, Kai and Chen, Xie , booktitle=. 2026 , organization=
work page 2026
-
[17]
Nguyen, Vinh Huy and Nguyen, Dinh Thuan , year =
-
[18]
ParlaSpeech-HR - a Freely Available ASR Dataset for Croatian Bootstrapped from the ParlaMint Corpus
Ljube. ParlaSpeech-HR - a Freely Available ASR Dataset for Croatian Bootstrapped from the ParlaMint Corpus. Proceedings of the workshop ParlaCLARIN III within the 13th language resources and evaluation Conference , pages=
-
[19]
Ljube. The. International Conference on Speech and Computer , pages=. 2024 , organization=
work page 2024
-
[20]
International Conference on Machine Learning , pages=
Casanova, Edresson and Weber, Julian and Shulby, Christopher D and Junior, Arnaldo Candido and G. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
-
[21]
arXiv preprint arXiv:2406.04904 , year=
Casanova, Edresson and Davis, Kelly and G. arXiv preprint arXiv:2406.04904 , year=
-
[22]
Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and Gao, Zhifu and Yan, Zhijie , journal=
-
[23]
Du, Zhihao and Wang, Yuxuan and Chen, Qian and Shi, Xian and Lv, Xiang and Zhao, Tianyu and Gao, Zhifu and Yang, Yexin and Gao, Changfeng and Wang, Hui and Yu, Fan and Liu, Huadi and Sheng, Zhengyan and Gu, Yue and Deng, Chong and Wang, Wen and Zhang, Shiliang and Yan, Zhijie and Zhou, Jingren , journal=
-
[24]
Du, Zhihao and Gao, Changfeng and Wang, Yuxuan and Yu, Fan and Zhao, Tianyu and Wang, Hao and Lv, Xiang and Wang, Hui and Ni, Chongjia and Shi, Xian and An, Keyu and Yang, Guanrou and Li, Yabin and Chen, Yanni and Gao, Zhifu and Chen, Qian and Gu, Yue and Chen, Mengzhe and Chen, Yafeng and Zhang, Shiliang and Wang, Wen and Ye, Jieping , journal=
-
[25]
Liao, Shijia and Wang, Yuxuan and Li, Tianyu and Cheng, Yifan and Zhang, Ruoyi and Zhou, Rongzhi and Xing, Yijin , journal=
-
[26]
Liao, Shijia and Wang, Yuxuan and Liu, Songting and Cheng, Yifan and Zhang, Ruoyi and Li, Tianyu and Li, Shidong and Zheng, Yisheng and Liu, Xingwei and Wang, Qingzheng and Zhou, Zhizhuo and Liu, Jiahua and Chen, Xin and Han, Dawei , journal=
-
[27]
Tan, Xu and Chen, Jiawei and Liu, Haohe and Cong, Jian and Zhang, Chen and Liu, Yanqing and Wang, Xi and Leng, Yichong and Yi, Yuanhao and He, Lei and Zhao, Sheng and Qin, Tao and Soong, Frank and Liu, Tie-Yan , journal=. 2024 , publisher=
work page 2024
-
[28]
Shen, Kai and Ju, Zeqian and Tan, Xu and Liu, Eric and Leng, Yichong and He, Lei and Qin, Tao and Zhao, Sheng and Bian, Jiang , booktitle=
-
[29]
Ju, Zeqian and Wang, Yuancheng and Shen, Kai and Tan, Xu and Xin, Detai and Yang, Dongchao and Liu, Yanqing and Leng, Yichong and Song, Kaitao and Tang, Siliang and Wu, Zhizheng and Qin, Tao and Li, Xiang-Yang and Ye, Wei and Zhang, Shikun and Bian, Jiang and He, Lei and Li, Jinyu and Zhao, Sheng , booktitle=
-
[30]
arXiv preprint arXiv:2103.03541 , year=
Multilingual byte2speech models for scalable low-resource speech synthesis , author=. arXiv preprint arXiv:2103.03541 , year=
-
[31]
Bytes are all you need: End-to-end multilingual speech recognition and synthesis with bytes , author=. ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2019 , organization=
work page 2019
-
[32]
One Model, Many Languages: Meta-Learning for Multilingual Text-to-Speech , author=. Proc. Interspeech 2020 , pages=
work page 2020
-
[33]
Zhou, Siyi and Zhou, Yiquan and He, Yi and Zhou, Xun and Wang, Jinchao and Deng, Wei and Shu, Jingchen , booktitle=. Index
-
[34]
Li, Yunpei and Zhou, Xun and Wang, Jinchao and Wang, Lu and Wu, Yong and Zhou, Siyi and Zhou, Yiquan and Shu, Jingchen , journal=
-
[35]
Hu, Hangrui and Zhu, Xinfa and He, Ting and Guo, Dake and Zhang, Bin and Wang, Xiong and Guo, Zhifang and Jiang, Ziyue and Hao, Hongkun and Guo, Zishan and Zhang, Xinyu and Zhang, Pei and Yang, Baosong and Xu, Jin and Zhou, Jingren and Lin, Junyang , journal=
-
[36]
Zhang, Bowen and Guo, Congchao and Yang, Geng and Yu, Hang and Zhang, Haozhe and Lei, Heidi and Mai, Jialong and Yan, Junjie and Yang, Kaiyue and Yang, Mingqi and Huang, Peikai and Jin, Ruiyang and Jiang, Sitan and Cheng, Weihua and Li, Yawei and Xiao, Yichen and Zhou, Yiying and Zhang, Yongmao and Lu, Yuan and He, Yucen , journal=
-
[37]
Torgashov, Nikita and Henter, Gustav Eje and Skantze, Gabriel , journal=
-
[38]
Kim, Sungwon and Kim, Heeseung and Yoon, Sungroh , journal=
-
[39]
Liu, Qingyu and Xu, Rixi and Chen, Yushen and Niu, Zhikang and Li, Haitao and Zhu, Pengcheng and Zhang, Bowen and Zhao, Jian and Yang, Yunting and Sisman, Berrak and Yu, Kai and Chen, Xie , year =
-
[40]
Zhang, Haitong and Zhan, Haoyue and Zhang, Yang and Yu, Xinyuan and Lin, Yue , journal=. Revisiting
-
[41]
Li, Haitao and Jin, Chunxiang and Li, Chenglin and Guan, Wenhao and Huang, Zhengxing and Chen, Xie , journal=
-
[42]
Chen, Sanyuan and Wang, Chengyi and Chen, Zhengyang and Wu, Yu and Liu, Shujie and Chen, Zhuo and Li, Jinyu and Kanda, Naoyuki and Yoshioka, Takuya and Xiao, Xiong and Wu, Jian and Zhou, Long and Ren, Shuo and Qian, Yanmin and Qian, Yao and Wu, Jian and Zeng, Michael and Yu, Xiangzhan and Wei, Furu , journal=. 2022 , publisher=
work page 2022
-
[43]
International Conference on Machine Learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[44]
Gao, Zhifu and Zhang, ShiLiang and McLoughlin, Ian and Yan, Zhijie , booktitle=
-
[45]
Gong, Yitian and Jiang, Botian and Zhao, Yiwei and Yuan, Yucheng and Chen, Kuangwei and Jiang, Yaozhou and Chang, Cheng and Hong, Dong and Chen, Mingshu and Li, Ruixiao and Zhang, Yiyang and Gao, Yang and Chen, Hanfu and Chen, Ke and Wang, Songlin and Yang, Xiaogui and Zhang, Yuqian and Huang, Kexin and Lin, Zhengyuan and Yu, Kang and Chen, Ziqi and Wang,...
-
[46]
Zhu, Han and Ye, Lingxuan and Kang, Wei and Yao, Zengwei and Guo, Liyong and Kuang, Fangjun and Han, Zhifeng and Zhuang, Weiji and Lin, Long and Povey, Daniel , journal=
-
[47]
Desplanques, Brecht and Thienpondt, Jenthe and Demuynck, Kris , booktitle=. 2020 , organization=
work page 2020
-
[48]
Wang, Yuxuan and Skerry-Ryan, RJ and Stanton, Daisy and Wu, Yonghui and Weiss, Ron J. and Jaitly, Navdeep and Yang, Zongheng and Xiao, Ying and Chen, Zhifeng and Bengio, Samy and Le, Quoc and Agiomyrgiannakis, Yannis and Clark, Rob and Saurous, Rif A. , booktitle=. 2017 , organization=
work page 2017
-
[49]
Ren, Yi and Ruan, Yangjun and Tan, Xu and Qin, Tao and Zhao, Sheng and Zhao, Zhou and Liu, Tie-Yan , booktitle=
-
[50]
International Conference on Machine Learning , pages=
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[51]
IEEE Transactions on Audio, Speech and Language Processing , volume=
Neural codec language models are zero-shot text to speech synthesizers , author=. IEEE Transactions on Audio, Speech and Language Processing , volume=. 2025 , publisher=
work page 2025
-
[52]
BASE TTS: Lessons from building a billion-parameter text-to-speech model on 100k hours of data
Base. arXiv preprint arXiv:2402.08093 , year=
-
[53]
Anastassiou, Philip and Chen, Jiawei and Chen, Jitong and Chen, Yuanzhe and Chen, Zhuo and Chen, Ziyi and Cong, Jian and Deng, Lelai and Ding, Chuang and Gao, Lu and Gong, Mingqing and Huang, Peisong and Huang, Qingqing and Huang, Zhiying and Huo, Yuanyuan and Jia, Dongya and Li, Chumin and Li, Feiya and Li, Hui and Li, Jiaxin and Li, Xiaoyang and Li, Xin...
-
[54]
Eskimez, Sefik Emre and Wang, Xiaofei and Thakker, Manthan and Li, Canrun and Tsai, Chung-Hsien and Xiao, Zhen and Yang, Hemin and Zhu, Zirun and Tang, Min and Tan, Xu and Liu, Yanqing and Zhao, Sheng and Kanda, Naoyuki , booktitle=. E2. 2024 , organization=
work page 2024
-
[55]
Neekhara, Paarth and Hussain, Shehzeen and Ghosh, Subhankar and Li, Jason and Ginsburg, Boris , booktitle=. Improving Robustness of
-
[56]
arXiv preprint arXiv:2504.20334 , year=
Towards Flow-Matching-based TTS without Classifier-Free Guidance , author=. arXiv preprint arXiv:2504.20334 , year=
-
[57]
Jiang, Ziyue and Ren, Yi and Li, Ruiqi and Ji, Shengpeng and Zhang, Boyang and Ye, Zhenhui and Zhang, Chen and Jionghao, Bai and Yang, Xiaoda and Zuo, Jialong and Zhang, Yu and Liu, Rui and Yin, Xiang and Zhao, Zhou , journal=
-
[58]
Better speech synthesis through scaling
Better speech synthesis through scaling , author=. arXiv preprint arXiv:2305.07243 , year=
-
[59]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[60]
International Conference on Machine Learning , pages=
Variational inference with normalizing flows , author=. International Conference on Machine Learning , pages=. 2015 , organization=
work page 2015
-
[61]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.