Recognition: unknown
The Missing Evaluation Axis: What 10,000 Student Submissions Reveal About AI Tutor Effectiveness
Pith reviewed 2026-05-08 05:12 UTC · model grok-4.3
The pith
AI tutor evaluations must track whether students actually apply the feedback, as behavioral signals from code changes reveal more about effectiveness than pedagogy scores alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that extending AI tutor evaluation with a behavioral dimension—measuring whether students modify their code after receiving feedback and whether those modifications correctly implement the tutor's advice—reveals substantial differences between tutors that pedagogy alone misses. When applied to real course data, this combined approach shows engagement patterns align better with student perceptions of helpfulness, yielding a more complete view of tutor performance than quality ratings in isolation.
What carries the argument
The proposed evaluation framework that analyzes pre- and post-feedback code submissions to quantify student engagement and correct application of tutor advice.
If this is right
- Comparisons of AI tutors must incorporate both pedagogical and engagement metrics to avoid incomplete conclusions.
- Student ratings of feedback helpfulness track more closely with observed code changes than with expert pedagogy scores.
- Deployed tutors can be differentiated by how well they prompt visible student action on suggestions.
- Large interaction datasets enable identification of feedback that students ignore despite high pedagogical quality.
Where Pith is reading between the lines
- Course designers could prioritize tutors that maximize observable engagement when choosing tools for large classes.
- Similar behavioral tracking might apply to other AI-assisted learning domains where user actions after advice can be logged.
- Optimizing tutors for both accurate advice and prompts that increase correct application could improve overall outcomes.
Load-bearing premise
That observed code changes after feedback mean students understood and correctly applied the advice rather than making unrelated edits or receiving help elsewhere.
What would settle it
If a large share of post-feedback code changes turn out to be incorrect, random, or uncorrelated with the specific advice given, the claim that behavioral signals reliably indicate effective tutor use would be undermined.
Figures

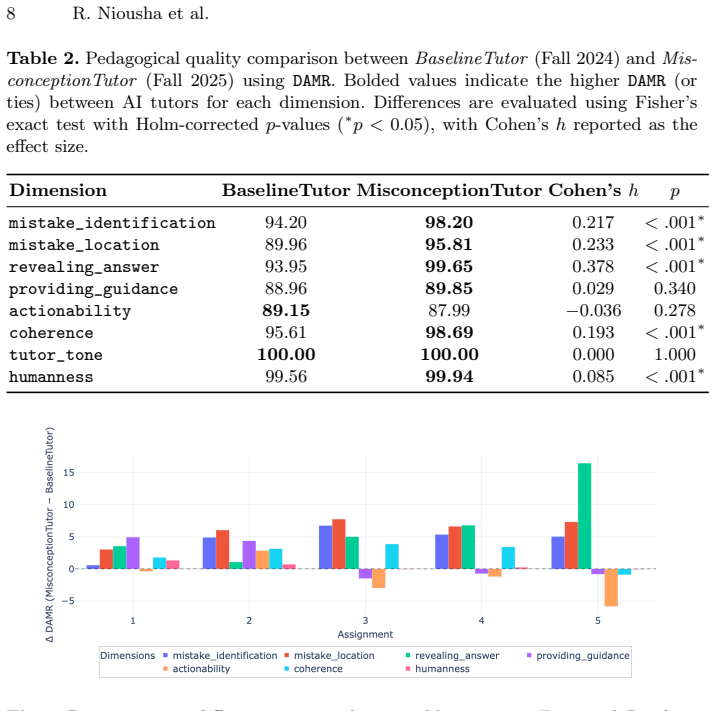
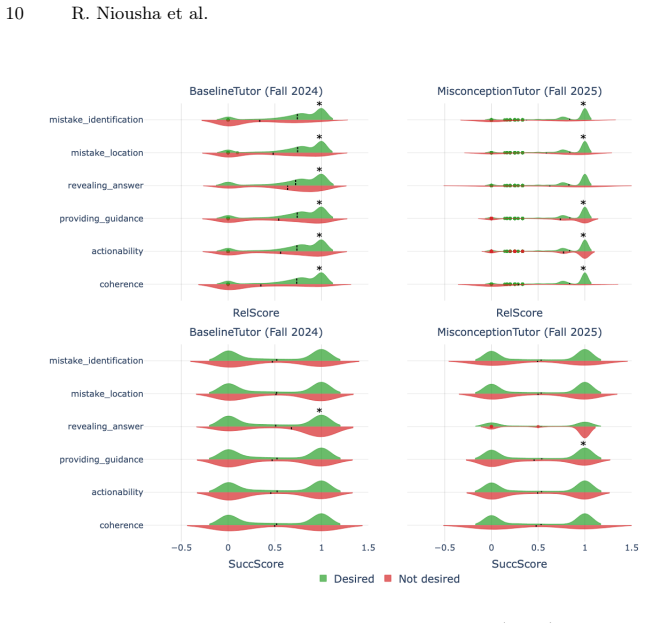
read the original abstract
Current Artificial Intelligence (AI)-based tutoring systems (AI tutors) are primarily evaluated based on the pedagogical quality of their feedback messages. While important, pedagogy alone is insufficient because it ignores a critical question: what do students actually do with the feedback they receive? We argue that AI tutor evaluation should be extended with a behavioral dimension grounded in student interaction data, which complements pedagogical assessment. We propose an evaluation framework and apply it to 10,235 code submissions with corresponding AI tutor feedback from an introductory undergraduate programming course to measure whether students act on tutor feedback and whether those actions are applied correctly. Using this framework to compare two deployed AI tutors across different semesters in a large-scale introductory computer science course reveals substantial differences in student engagement patterns that are not captured by pedagogy-only evaluation. Moreover, these engagement-based behavioral signals are more strongly associated with student perception of helpful feedback than pedagogical quality alone, providing a more complete and actionable picture of AI tutor performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard pedagogy-only evaluation of AI tutors is insufficient and should be extended with a behavioral axis measuring whether students act on feedback (via post-feedback code modifications) and apply it correctly. Analysis of 10,235 submissions from an introductory CS course shows substantial engagement differences between two deployed tutors not visible in pedagogy scores; moreover, these behavioral signals correlate more strongly with student-reported helpfulness than pedagogy alone.
Significance. If the behavioral metric holds after validation, the work supplies a practical, data-grounded complement to existing evaluation that directly links tutor output to observable student uptake, offering clearer guidance for iterative improvement of deployed AI tutors.
major comments (1)
- [Framework / Methods] Framework / Methods (as described in abstract and skeptic note): The central inference that detected code changes after feedback reliably indicate students have correctly applied the tutor's advice is load-bearing for both the tutor-comparison result and the stronger-correlation claim, yet the manuscript provides no inter-rater reliability, ablation on edit-distance thresholds, timing controls, or manual ground-truth validation to rule out independent debugging, external help, or unrelated edits. Without these, the behavioral signals risk capturing noise rather than genuine uptake.
minor comments (2)
- [Abstract] Abstract: Exact correlation coefficients, p-values, and the precise statistical controls used for the perception association are not stated, preventing readers from judging effect size and robustness.
- [Methods] The manuscript should clarify the exact operational definition of 'correctly implement the advice' (e.g., required edit distance, semantic matching rules) and any data-exclusion criteria applied to the 10,235 submissions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need for stronger validation of the behavioral signals. We address the concern directly below.
read point-by-point responses
-
Referee: The central inference that detected code changes after feedback reliably indicate students have correctly applied the tutor's advice is load-bearing for both the tutor-comparison result and the stronger-correlation claim, yet the manuscript provides no inter-rater reliability, ablation on edit-distance thresholds, timing controls, or manual ground-truth validation to rule out independent debugging, external help, or unrelated edits. Without these, the behavioral signals risk capturing noise rather than genuine uptake.
Authors: We agree that the absence of explicit validation leaves the behavioral metric open to the alternative explanations noted. The current framework detects post-feedback edits via normalized edit distance and classifies application correctness by alignment with the specific suggestions in the tutor message (e.g., insertion of a required construct or correction of an identified error). To strengthen this, the revised manuscript will include: (1) manual ground-truth labeling of a stratified random sample of 200 submissions by two independent raters, with reported Cohen's kappa; (2) an ablation table varying the edit-distance threshold and showing stability of the tutor-comparison and correlation results; (3) a timing analysis that restricts the behavioral signal to edits occurring within a short window after feedback and compares it to longer windows to assess contamination by independent debugging. While the observed correlation with student-reported helpfulness already offers convergent validity, these additions will directly address the risk of noise. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's evaluation framework is constructed from direct empirical measurements on 10,235 code submissions: behavioral signals are defined via observable post-feedback code modifications, then correlated against independent student perception surveys and pedagogy scores. No step reduces a claimed result to its own inputs by construction, renames a fitted parameter as a prediction, or relies on load-bearing self-citations whose content is unverified. The association between behavioral signals and perceived helpfulness is a data-driven finding rather than a definitional tautology. The derivation chain remains self-contained against the provided submission logs and survey responses.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Code submission changes following tutor feedback indicate that students have acted on the feedback.
- domain assumption Whether those changes are correct can be determined from the resulting code state.
Reference graph
Works this paper leans on
-
[1]
Assessment & Evaluation in Higher Education43(8) (2018)
Carless, D., Boud, D.: The development of student feedback literacy: enabling uptake of feedback. Assessment & Evaluation in Higher Education43(8) (2018)
2018
-
[2]
Review of educational research74(1) (2004)
Fredricks, J.A., Blumenfeld, P.C., Paris, A.H.: School engagement: Potential of the concept, state of the evidence. Review of educational research74(1) (2004)
2004
-
[3]
In: International Conference on Artificial Intelligence in Education
Gupta, A., Reddig, J., Calo, T., Weitekamp, D., MacLellan, C.J.: Beyond final answers: Evaluating large language models for math tutoring. In: International Conference on Artificial Intelligence in Education. Springer (2025)
2025
-
[4]
Feedback in second language writing: Contexts and issues pp
Han, Y., Hyland, F.: Learner engagement with written feedback: A sociocognitive perspective. Feedback in second language writing: Contexts and issues pp. 247–264 (2019)
2019
-
[5]
Computers & Education90(2015)
Henrie, C.R., Halverson, L.R., Graham, C.R.: Measuring student engagement in technology-mediated learning: A review. Computers & Education90(2015)
2015
-
[6]
In: Lipnevich, A.A., Smith, J.K
Jonsson, A., Panadero, E.: Facilitating students’ active engagement with feed- back. In: Lipnevich, A.A., Smith, J.K. (eds.) The Cambridge Handbook of In- structional Feedback. Cambridge Handbooks in Psychology, Cambridge University Press (2018)
2018
-
[7]
Jurenka, I., Kunesch, M., McKee, K.R., Gillick, D., Zhu, S., Wiltberger, S., Phal, S.M., Hermann, K., Kasenberg, D., Bhoopchand, A., et al.: Towards responsible development of generative AI for education: An evaluation-driven approach. arXiv preprint arXiv:2407.12687 (2024)
-
[8]
In: International Conference on Computers in Education (2025)
Li, R., Jiang, Y.H., Wang, J., Jiang, B.: How real is AI tutoring? Comparing simu- lated and human dialogues in one-on-one instruction. In: International Conference on Computers in Education (2025)
2025
-
[9]
In: Proceedings of the 55th ACM technical symposium on computer science education V
Liu, R., Zenke, C., Liu, C., Holmes, A., Thornton, P., Malan, D.J.: Teaching CS50 with AI: leveraging generative artificial intelligence in computer science educa- tion. In: Proceedings of the 55th ACM technical symposium on computer science education V. 1 (2024)
2024
-
[10]
PeerJ Computer Science11(2025)
Liu, Z., Agrawal, P., Singhal, S., Madaan, V., Kumar, M., Verma, P.K.: LPITutor: an LLM based personalized intelligent tutoring system using RAG and prompt engineering. PeerJ Computer Science11(2025)
2025
-
[11]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (2025)
Macina, J., Daheim, N., Hakimi, I., Kapur, M., Gurevych, I., Sachan, M.: Mathtu- torbench: A benchmark for measuring open-ended pedagogical capabilities of LLM tutors. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (2025)
2025
-
[12]
In: Vlachos, A., Au- genstein, I
Macina, J., Daheim, N., Wang, L., Sinha, T., Kapur, M., Gurevych, I., Sachan, M.: Opportunities and challenges in neural dialog tutoring. In: Vlachos, A., Au- genstein, I. (eds.) Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, Dubrovnik, Croatia (May 2023)
2023
-
[13]
Educational Psychology Review35(2) (2023)
Martin, A.J.: Integrating motivation and instruction: Towards a unified approach in educational psychology. Educational Psychology Review35(2) (2023)
2023
-
[14]
In: International Conference on Artificial Intelligence in Education
Maurya, K.K., Kochmar, E.: Pedagogy-driven evaluation of generative AI-Powered intelligent tutoring systems. In: International Conference on Artificial Intelligence in Education. Springer (2025)
2025
-
[15]
In: Chiruzzo, L., Ritter, A., Wang, L
Maurya, K.K., Srivatsa, K.A., Petukhova, K., Kochmar, E.: Unifying AI tutor evaluation: An evaluation taxonomy for pedagogical ability assessment of LLM- powered AI tutors. In: Chiruzzo, L., Ritter, A., Wang, L. (eds.) Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association The Missing Evaluation Axis 15 for Computatio...
2025
-
[16]
Educational psychologist50(1) (2015)
Miller, B.W.: Using reading times and eye-movements to measure cognitive en- gagement. Educational psychologist50(1) (2015)
2015
-
[17]
In: International Conference on Artificial Intelligence in Education
Mittal, M., Tyagi, G., Bailey, A., Ranade, G., Norouzi, N.: Askademia: A real- time AI system for automatic responses to student questions. In: International Conference on Artificial Intelligence in Education. Springer (2025)
2025
-
[18]
In: Proceedings of the 57th ACM Technical Symposium on Computer Science Education V
Niousha, R., Boatright Smith, S., O’Neill, A., Zamfirescu-Pereira, J., DeNero, J., Norouzi, N.: Misconception-aware LLM programming tutor: Lessons learned from student-tutor interactions. In: Proceedings of the 57th ACM Technical Symposium on Computer Science Education V. 2 (2026)
2026
-
[19]
OpenAI: GPT-4 (2023)
2023
-
[20]
OpenAI: Introducing GPT-4.1 in the API (2025)
2025
-
[21]
Journal of Educational Psychology108(8), 1098 (2016)
Patchan, M.M., Schunn, C.D., Correnti, R.J.: The nature of feedback: How peer feedback features affect students’ implementation rate and quality of revisions. Journal of Educational Psychology108(8), 1098 (2016)
2016
-
[22]
In: Proceed- ings of the ACM Global on Computing Education Conference 2025 Vol 1 (2025)
Qi, L., Zamfirescu-Pereira, J., Kim, T., Hartmann, B., DeNero, J., Norouzi, N.: A knowledge-component-based methodology for evaluating ai assistants. In: Proceed- ings of the ACM Global on Computing Education Conference 2025 Vol 1 (2025)
2025
-
[23]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
Ross, A., Andreas, J.: Toward in-context teaching: Adapting examples to students’ misconceptions. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
2024
-
[24]
In- structional science18(2) (1989)
Sadler, D.R.: Formative assessment and the design of instructional systems. In- structional science18(2) (1989)
1989
- [25]
-
[26]
In: Proceedings of the 15th Inter- national Conference on Educational Data Mining
Tack, A., Piech, C.: The AI teacher test: Measuring the pedagogical ability of blender and GPT-3 in educational dialogues. In: Proceedings of the 15th Inter- national Conference on Educational Data Mining. International Educational Data Mining Society, Durham, United Kingdom (July 2022)
2022
-
[27]
Educational Research for Policy and Practice21(3) (2022)
Tay, H.Y., Lam, K.W.: Students’ engagement across a typology of teacher feedback practices. Educational Research for Policy and Practice21(3) (2022)
2022
-
[28]
Siddiqui, M., J
Weitekamp, D., N. Siddiqui, M., J. MacLellan, C.: Tutorgym: A testbed for eval- uating AI agents as tutors and students. In: International Conference on Artificial Intelligence in Education. Springer (2025)
2025
-
[29]
Frontiers in psychology10(2020)
Wisniewski, B., Zierer, K., Hattie, J.: The power of feedback revisited: A meta- analysis of educational feedback research. Frontiers in psychology10(2020)
2020
-
[30]
Educational Psychology Re- view34(1) (2022)
Wong, Z.Y., Liem, G.A.D.: Student engagement: Current state of the construct, conceptual refinement, and future research directions. Educational Psychology Re- view34(1) (2022)
2022
-
[31]
Journal of Educational Psychology116(1) (2024)
Wong, Z.Y., Liem, G.A.D., Chan, M., Datu, J.A.D.: Student engagement and its association with academic achievement and subjective well-being: A systematic review and meta-analysis. Journal of Educational Psychology116(1) (2024)
2024
-
[32]
(Now what?)
Zamfirescu-Pereira, J., Qi, L., Hartmann, B., DeNero, J., Norouzi, N.: 61A bot report: AI assistants in CS1 save students homework time and reduce demands on staff. (Now what?). In: Proceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.