Recognition: unknown
Convex-Geometric Error Bounds for Positive-Weight Kernel Quadrature
Pith reviewed 2026-05-08 06:48 UTC · model grok-4.3
The pith
The mean of a bounded d-dimensional random vector can be approximated by a convex combination of N i.i.d. samples at accuracy O(d/N) with high probability, enabling stable positive-weight kernel quadrature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the exact-target fixed-pool setting an evaluated i.i.d. candidate pool of size N is already available and the task is to reweight it so as to approximate the kernel mean embedding. The positive reweighting problem is governed not by the equal-weight empirical average but by the random convex hull generated by the pool. The mean of a bounded d-dimensional random vector can be approximated by a convex combination of N i.i.d. samples at accuracy O(d/N) with high probability, sharper than equal-weight averaging in the fixed-dimensional regime. This d-dimensional convex-hull approximation transfers to full RKHS worst-case error through an augmented Mercer-truncation argument, yielding bounds,
What carries the argument
The random convex hull generated by the N i.i.d. samples, which determines the best simplex reweighting for approximating the kernel mean embedding, together with the augmented Mercer truncation that lifts the finite-dimensional bound to the full RKHS without destroying the rate.
If this is right
- Positive-weight KQ achieves Monte-Carlo-beating rates in favorable spectral regimes, including near-O(1/N) up to logs under exponential spectral decay.
- The worst-case error decomposes into a spectral tail term and a finite-sample convex-hull term.
- A Frank-Wolfe algorithm operates directly on the pool atoms, maintains simplex weights, and admits an explicit optimization-error bound.
- In fixed d the convex-hull approximation rate O(d/N) is strictly sharper than the equal-weight Monte Carlo rate.
Where Pith is reading between the lines
- The O(d/N) geometric rate may be useful in moderate-dimensional integration problems where standard Monte Carlo is limited by sqrt(N) scaling.
- The same convex-hull perspective could apply to other kernel methods that require positivity constraints for numerical stability or interpretability.
- Practical performance of the Frank-Wolfe procedure on concrete quadrature tasks would test whether the theoretical bounds translate to observed gains.
- Extensions to unbounded distributions would likely need additional truncation or moment assumptions to preserve the rate.
Load-bearing premise
The random vector is bounded and the RKHS admits an augmented Mercer truncation that transfers the finite-dimensional convex-hull bound without destroying the rate.
What would settle it
A numerical experiment in fixed d that checks whether the high-probability error of the best convex combination from N samples for the mean scales as O(d/N) or remains at the Monte Carlo rate O(1/sqrt(N)).
Figures

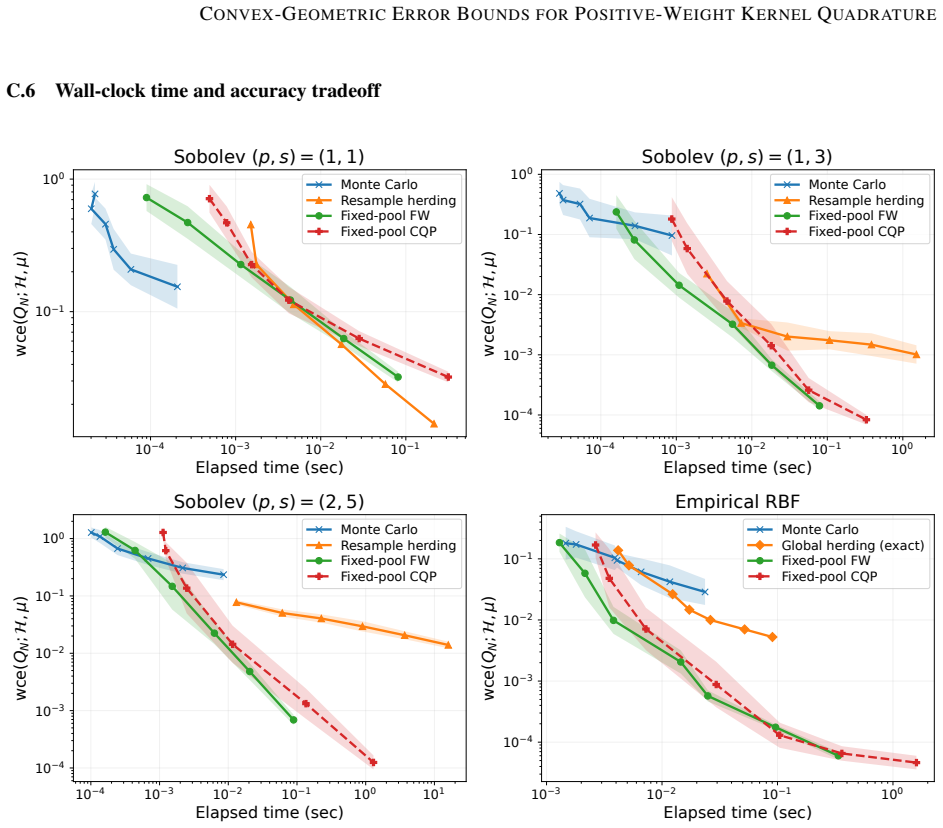
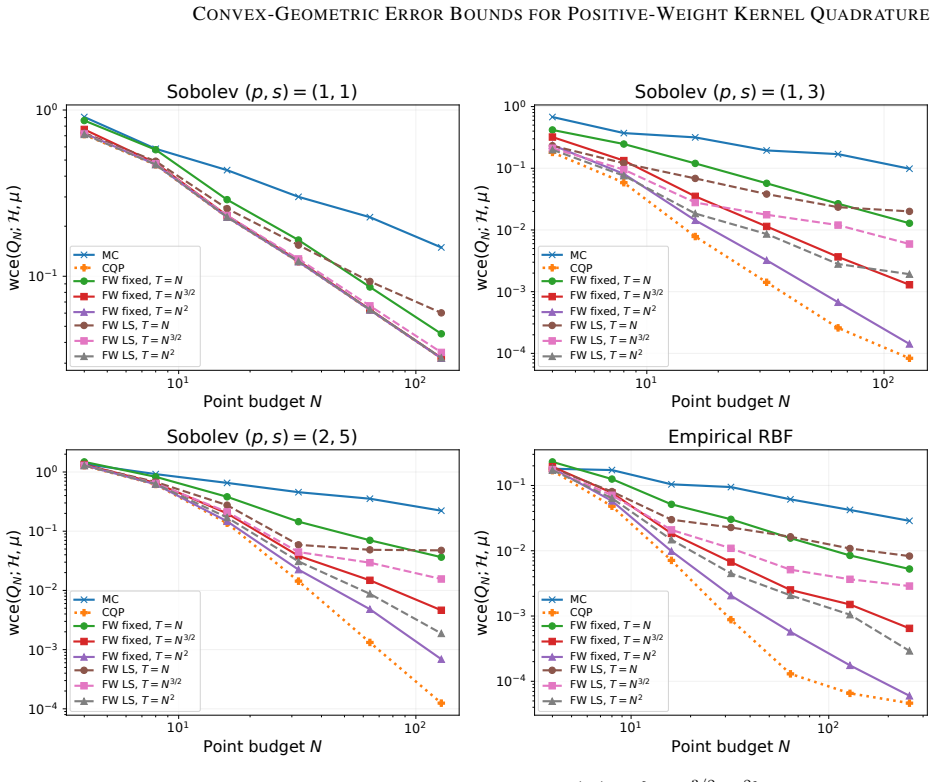
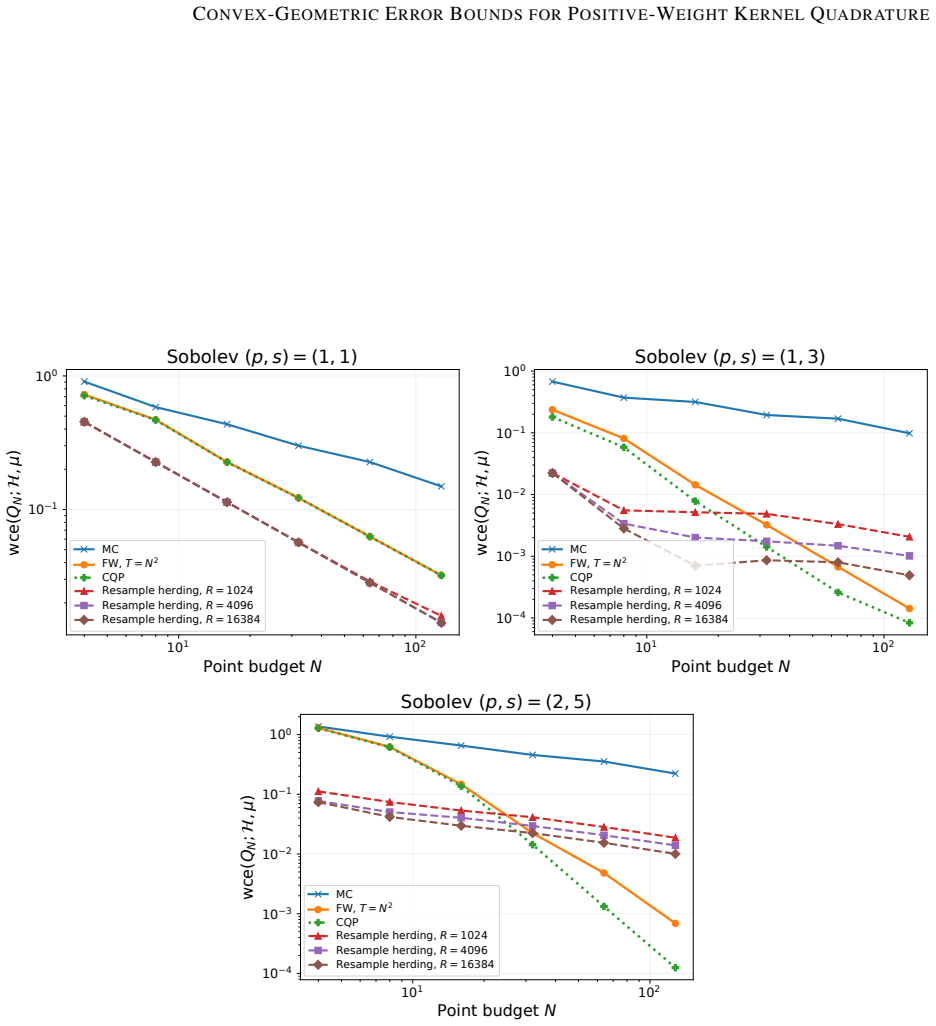
read the original abstract
Kernel quadrature can exploit RKHS spectral structure and outperform Monte Carlo on smooth integrands, but optimized quadrature weights are generally signed and may be numerically unstable. We study whether spectral acceleration remains possible when the weights are constrained to be positive, i.e., simplex weights. In the exact-target fixed-pool setting, an evaluated i.i.d. candidate pool of size $N$ is already available and the task is to reweight it so as to approximate the kernel mean embedding. We show that this positive reweighting problem is governed not by the equal-weight empirical average, but by the random convex hull generated by the pool. Our main geometric result shows that the mean of a bounded $d$-dimensional random vector can be approximated by a convex combination of $N$ i.i.d. samples at accuracy $O(d/N)$ with high probability, sharper than equal-weight averaging in the fixed-dimensional regime. We transfer this $d$-dimensional convex-hull approximation to full RKHS worst-case error through an augmented Mercer-truncation argument. The resulting positive-weight KQ bounds consist of a spectral tail term and a finite-sample convex-hull term, yielding Monte-Carlo-beating rates in favorable spectral regimes, including near-$O(1/N)$ rates up to logarithmic factors under exponential spectral decay. We also provide a constructive Frank--Wolfe algorithm that operates directly on the pool atoms, maintains simplex weights, and admits an explicit optimization-error bound.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes convex-geometric error bounds for positive-weight kernel quadrature. It proves that the mean of a bounded d-dimensional random vector can be approximated by a convex combination of N i.i.d. samples at high-probability Euclidean error O(d/N), sharper than equal-weight Monte Carlo averaging for fixed d. This geometric result is transferred to RKHS worst-case error bounds for simplex-weighted quadrature approximating the kernel mean embedding via an augmented Mercer truncation. The resulting bounds combine a spectral tail term with the finite-sample convex-hull term, yielding Monte Carlo-beating rates (including near-O(1/N) up to logs under exponential spectral decay). A Frank-Wolfe algorithm operating directly on the pool with an explicit optimization-error bound is also provided.
Significance. If the transfer holds, the work offers a meaningful advance for stable positive-weight kernel quadrature that exploits RKHS spectral structure to outperform Monte Carlo while avoiding signed-weight instability. The geometric result on convex-hull approximation of the mean is of independent interest in geometric probability and is derived cleanly without free parameters or ad-hoc axioms. The constructive algorithm adds practical value. The overall significance depends on explicit verification that the augmented truncation preserves the O(d/N) rate without d-dependent prefactors.
major comments (1)
- [Augmented Mercer truncation] Augmented Mercer truncation (following the geometric result): the argument must explicitly track constants to confirm that (i) the augmented vectors remain bounded by a d-independent constant and (ii) the O(d/N) prefactors are not inflated by the augmentation or eigenfunction bounds. This is load-bearing for the claimed near-O(1/N) RKHS rates when the truncation level d scales as log N under exponential decay; without such tracking the transfer may replace the stated rate by a worse one.
minor comments (2)
- [Notation] The notation distinguishing the random convex hull, the simplex constraint, and the augmented embedding vectors should be unified across the geometric and RKHS sections for clarity.
- [Algorithm] The Frank-Wolfe algorithm section would benefit from pseudocode that directly references the explicit optimization-error bound.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. The single major comment concerns the need for explicit constant tracking in the augmented Mercer truncation. We address it below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Augmented Mercer truncation] Augmented Mercer truncation (following the geometric result): the argument must explicitly track constants to confirm that (i) the augmented vectors remain bounded by a d-independent constant and (ii) the O(d/N) prefactors are not inflated by the augmentation or eigenfunction bounds. This is load-bearing for the claimed near-O(1/N) RKHS rates when the truncation level d scales as log N under exponential decay; without such tracking the transfer may replace the stated rate by a worse one.
Authors: We agree that explicit constant tracking strengthens the argument and is necessary to rigorously support the rates. In the current proof, the augmented map is constructed by appending the residual mean embedding to the d-dimensional Mercer feature vector. Because the kernel is assumed continuous on a compact domain, the feature map satisfies ||phi(x)|| <= sqrt(k(x,x)) <= M for a universal M independent of d and of the truncation. The appended residual has RKHS norm at most the tail sum_{k>d} lambda_k, which is already controlled by the spectral tail term in the final bound and does not depend on the sample size N. Consequently the augmented vectors lie in a Euclidean ball of radius bounded by a d-independent constant (M plus the tail). The geometric result is applied in dimension d+1; the O((d+1)/N) error therefore differs from O(d/N) by at most an additive O(1/N) term that is absorbed into the existing O(d/N) without changing the leading factor. The transfer to the RKHS norm is isometric on the augmented coordinates, so no additional d-dependent prefactors arise from the eigenfunction bounds. We will add a short lemma (or expanded remark) that records these explicit bounds and verifies that the overall prefactor remains O(d) with a multiplier depending only on M and the kernel. This does not alter the stated rates, including the near-O(1/N) regime when d = O(log N) under exponential decay. The revision will be made in the next version. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The central geometric claim (O(d/N) convex-hull approximation for bounded random vectors) is obtained from direct probabilistic arguments on the random convex hull in fixed dimension and does not reduce to a fitted parameter, self-definition, or self-citation. The lift to RKHS worst-case error proceeds by standard augmented Mercer truncation, which is an external analytic tool whose validity is independent of the present paper's fitted values or target rates. No load-bearing self-citation, ansatz smuggling, or renaming of known results occurs in the derivation steps; the paper remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Mercer theorem supplies a countable eigen-expansion of the kernel
- domain assumption The feature map of the random vector is bounded almost surely
Reference graph
Works this paper leans on
-
[1]
Adachi, S
M. Adachi, S. Hayakawa, M. Jørgensen, H. Oberhauser, and M. A. Osborne. Fast Bayesian inference with batch Bayesian quadrature via kernel recombination. InAdvances in Neural Information Processing Systems, volume 35, pages 16533–16547, 2022
2022
-
[2]
Anastasiou, A
A. Anastasiou, A. Barp, F.-X. Briol, B. Ebner, R. E. Gaunt, F. Ghaderinezhad, J. Gorham, A. Gretton, C. Ley, Q. Liu, et al. Stein’s method meets computational statistics: A review of some recent developments.Statistical Science, 38(1):120–139, 2023
2023
-
[3]
F. Bach. On the equivalence between kernel quadrature rules and random feature expansions.The Journal of Machine Learning Research, 18(1):714–751, 2017
2017
-
[4]
F. Bach, S. Lacoste-Julien, and G. Obozinski. On the equivalence between herding and conditional gradient algorithms. InInternational Conference on Machine Learning, pages 1355–1362, 2012
2012
-
[5]
Belhadji, R
A. Belhadji, R. Bardenet, and P. Chainais. Kernel quadrature with DPPs. InAdvances in Neural Information Processing Systems, volume 32, pages 12907–12917, 2019
2019
-
[6]
Belhadji, R
A. Belhadji, R. Bardenet, and P. Chainais. Kernel interpolation with continuous volume sampling. InInternational Conference on Machine Learning, pages 725–735. PMLR, 2020
2020
-
[7]
A. C. Berry. The accuracy of the Gaussian approximation to the sum of independent variates.Transactions of the American Mathematical Society, 49(1):122–136, 1941. 9 CONVEX-GEOMETRICERRORBOUNDS FORPOSITIVE-WEIGHTKERNELQUADRATURE
1941
-
[8]
Briol, C
F.-X. Briol, C. Oates, M. Girolami, and M. A. Osborne. Frank–Wolfe Bayesian quadrature: Probabilistic integration with theoretical guarantees. InAdvances in Neural Information Processing Systems, volume 28, pages 1162–1170, 2015
2015
-
[9]
Briol, C
F.-X. Briol, C. J. Oates, J. Cockayne, W. Y . Chen, and M. Girolami. On the sampling problem for kernel quadrature. InInternational Conference on Machine Learning, pages 586–595. PMLR, 2017
2017
-
[10]
Briol, C
F.-X. Briol, C. J. Oates, M. Girolami, M. A. Osborne, and D. Sejdinovic. Probabilistic integration: A role in statistical computation?Statistical Science, 34(1):1–22, 2019
2019
-
[11]
Chatalic, N
A. Chatalic, N. Schreuder, L. Rosasco, and A. Rudi. Nyström kernel mean embeddings. InInternational Conference on Machine Learning, pages 3006–3024. PMLR, 2022
2022
-
[12]
Chatalic, N
A. Chatalic, N. Schreuder, E. De Vito, and L. Rosasco. Efficient numerical integration in reproducing kernel Hilbert spaces via leverage scores sampling.Journal of Machine Learning Research, 26(101):1–55, 2025
2025
-
[13]
Y . Chen, M. Welling, and A. Smola. Super-samples from kernel herding. InConference on Uncertainty in Artificial Intelligence, pages 109–116, 2010
2010
-
[14]
C. W. Combettes and S. Pokutta. Revisiting the approximate Carathéodory problem via the Frank-Wolfe algorithm. Mathematical Programming, 197(1):191–214, 2023
2023
-
[15]
Dwivedi and L
R. Dwivedi and L. Mackey. Generalized kernel thinning. InInternational Conference on Learning Representations, 2022
2022
-
[16]
Dwivedi and L
R. Dwivedi and L. Mackey. Kernel thinning.Journal of Machine Learning Research, 25(152):1–77, 2024
2024
-
[17]
Epperly and E
E. Epperly and E. Moreno. Kernel quadrature with randomly pivoted Cholesky. InAdvances in Neural Information Processing Systems, volume 36, pages 65850–65868, 2023
2023
-
[18]
C.-G. Esseen. On the Liapunoff limit of error in the theory of probability.Arkiv for Matematik, Astronomi och Fysik, A: 1–19, 1942
1942
-
[19]
D. Garreau, W. Jitkrittum, and M. Kanagawa. Large sample analysis of the median heuristic.arXiv preprint arXiv:1707.07269, 2017
-
[20]
Gunter, M
T. Gunter, M. A. Osborne, R. Garnett, P. Hennig, and S. J. Roberts. Sampling for inference in probabilistic models with fast Bayesian quadrature.Advances in Neural Information Processing Systems, 27:2789–2797, 2014
2014
-
[21]
Hayakawa, H
S. Hayakawa, H. Oberhauser, and T. Lyons. Positively weighted kernel quadrature via subsampling. InAdvances in Neural Information Processing Systems, volume 35, pages 6886–6900, 2022
2022
-
[22]
Hayakawa, T
S. Hayakawa, T. Lyons, and H. Oberhauser. Estimating the probability that a given vector is in the convex hull of a random sample.Probability Theory and Related Fields, 185:705–746, 2023
2023
-
[23]
Hayakawa, H
S. Hayakawa, H. Oberhauser, and T. Lyons. Hypercontractivity meets random convex hulls: Analysis of randomized multivariate cubatures.Proceedings of the Royal Society A, 479(2273):20220725, 2023
2023
-
[24]
Hayakawa, H
S. Hayakawa, H. Oberhauser, and T. Lyons. Sampling-based Nyström approximation and kernel quadrature. In Proceedings of the 40th International Conference on Machine Learning, pages 12678–12699. PMLR, 2023
2023
-
[25]
Huszár and D
F. Huszár and D. Duvenaud. Optimally-weighted herding is Bayesian quadrature. InConference on Uncertainty in Artificial Intelligence, pages 377–386, 2012
2012
-
[26]
M. Jaggi. Revisiting Frank-Wolfe: Projection-free sparse convex optimization. InProceedings of the 30th International Conference on Machine Learning, pages 427–435, 2013
2013
-
[27]
Kanagawa and P
M. Kanagawa and P. Hennig. Convergence guarantees for adaptive Bayesian quadrature methods. InAdvances in Neural Information Processing Systems, volume 32, pages 6237–6248, 2019
2019
-
[28]
Kanagawa, B
M. Kanagawa, B. K. Sriperumbudur, and K. Fukumizu. Convergence analysis of deterministic kernel-based quadrature rules in misspecified settings.Foundations of Computational Mathematics, 20(1):155–194, 2020
2020
-
[29]
Karvonen, M
T. Karvonen, M. Kanagawa, and S. Särkkä. On the positivity and magnitudes of Bayesian quadrature weights. Statistics and Computing, 29(6):1317–1333, 2019. 10 CONVEX-GEOMETRICERRORBOUNDS FORPOSITIVE-WEIGHTKERNELQUADRATURE
2019
-
[30]
Korolev and I
V . Korolev and I. Shevtsova. An improvement of the Berry-Esseen inequality with applications to Poisson and mixed Poisson random sums.Scandinavian Actuarial Journal, 2012(2):81–105, 2012
2012
-
[31]
Lacoste-Julien, F
S. Lacoste-Julien, F. Lindsten, and F. Bach. Sequential kernel herding: Frank-Wolfe optimization for particle filtering. InProceedings of the 18th International Conference on Artificial Intelligence and Statistics, volume 38 ofProceedings of Machine Learning Research, pages 544–552, 2015
2015
-
[32]
Litterer and T
C. Litterer and T. Lyons. High order recombination and an application to cubature on Wiener space.The Annals of Applied Probability, 22(4):1301–1327, 2012
2012
-
[33]
Lyons and N
T. Lyons and N. Victoir. Cubature on Wiener space.Proceedings of the Royal Society of London Series A, 460: 169–198, 2004
2004
-
[34]
Mak and V
S. Mak and V . R. Joseph. Support points.The Annals of Statistics, 46(6A):2562–2592, 2018
2018
-
[35]
H. Q. Minh, P. Niyogi, and Y . Yao. Mercer’s theorem, feature maps, and smoothing. InInternational Conference on Computational Learning Theory, pages 154–168. Springer, 2006
2006
-
[36]
Mirrokni, R
V . Mirrokni, R. P. Leme, A. Vladu, and S. C.-W. Wong. Tight bounds for approximate Carathéodory and beyond. InProceedings of the 34th International Conference on Machine Learning, pages 2440–2448, 2017
2017
-
[37]
Oates, M
C. Oates, M. Girolami, and N. Chopin. Control functionals for Monte Carlo integration.Journal of the Royal Statistical Society. Series B: Statistical Methodology, 79:695–718, 2017
2017
-
[38]
A. O’Hagan. Bayes–Hermite quadrature.Journal of Statistical Planning and Inference, 29(3):245–260, 1991
1991
-
[39]
C. E. Rasmussen and Z. Ghahramani. Bayesian Monte Carlo. InAdvances in Neural Information Processing Systems, volume 16, pages 505–512, 2003
2003
-
[40]
P. J. Rousseeuw and I. Ruts. The depth function of a population distribution.Metrika, 49(3):213–244, 1999
1999
-
[41]
L. F. South, T. Karvonen, C. Nemeth, M. Girolami, and C. J. Oates. Semi-exact control functionals from Sard’s method.Biometrika, 109(2):351–367, 2022
2022
-
[42]
Steinwart and C
I. Steinwart and C. Scovel. Mercer’s theorem on general domains: On the interaction between measures, kernels, and RKHSs.Constructive Approximation, 35(3):363–417, 2012
2012
-
[43]
Tsuji and K
K. Tsuji and K. Tanaka. Sparse solutions of the kernel herding algorithm by improved gradient approximation. Japan Journal of Industrial and Applied Mathematics, 43:22, 2026
2026
-
[44]
Tsuji, K
K. Tsuji, K. Tanaka, and S. Pokutta. Pairwise conditional gradients without swap steps and sparser kernel herding. InInternational Conference on Machine Learning, pages 21864–21883. PMLR, 2022
2022
-
[45]
J. W. Tukey. Mathematics and the picturing of data. InProceedings of the International Congress of Mathemati- cians, Vancouver, 1975, volume 2, pages 523–531, 1975
1975
-
[46]
van den Bos, B
L. van den Bos, B. Sanderse, W. Bierbooms, and G. van Bussel. Generating nested quadrature rules with positive weights based on arbitrary sample sets.SIAM/ASA Journal on Uncertainty Quantification, 8(1):139–169, 2020
2020
-
[47]
Wahba.Spline Models for Observational Data
G. Wahba.Spline Models for Observational Data. Society for Industrial and Applied Mathematics, 1990
1990
-
[48]
C. Wang, Y . Chen, H. Kanagawa, and C. J. Oates. Stein Π-importance sampling. InAdvances in Neural Information Processing Systems, volume 36, pages 71948–71994, 2023
2023
-
[49]
M. Welling. Herding dynamical weights to learn. InInternational Conference on Machine Learning, pages 1121–1128, 2009. 11 CONVEX-GEOMETRICERRORBOUNDS FORPOSITIVE-WEIGHTKERNELQUADRATURE A A normalization viewpoint for unbounded diagonals Supposek(x, x)>0holds for allx∈ Xand R k(x, x) dµ(x)<∞. Write r(x) := p k(x, x) and define the normalized kernel ek(x, y...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.