Recognition: no theorem link
Multi-Dimensional Behavioral Evaluation of Agentic Stock Prediction Systems Using Large Language Model Judges with Closed-Loop Reinforcement Learning Feedback
Pith reviewed 2026-05-14 21:36 UTC · model grok-4.3
The pith
Behavioral scoring by LLM judges on six decision dimensions correlates with trading performance and improves stock forecast accuracy through closed-loop reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
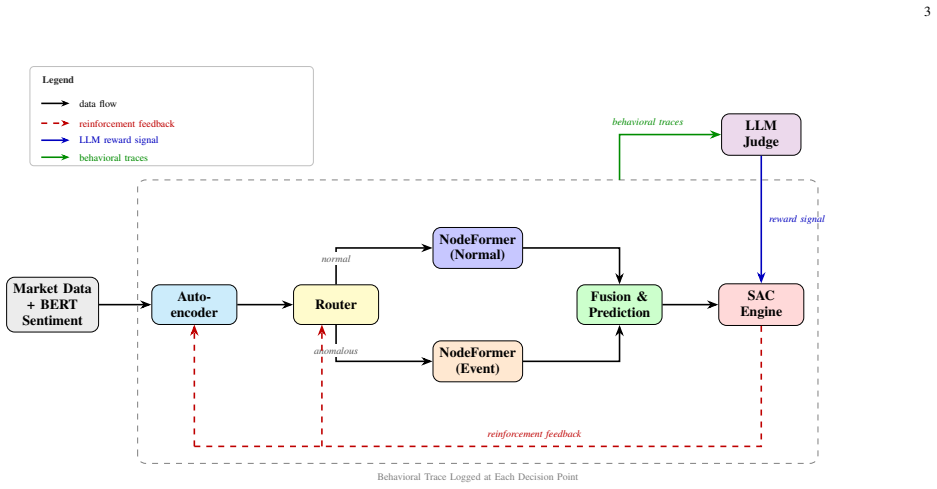
The central claim is that scoring the intermediate decision process of agentic stock predictors along six behavioral dimensions with an LLM judge ensemble yields a composite score that correlates at Spearman rho = 0.72 with realized 20-day Sharpe ratio, and that converting deficient dimension scores into reinforcement-learning penalties produces an 11.5 percent relative drop in one-day MAPE (from 0.61 percent to 0.54 percent) after three fine-tuning cycles on the 2017-2025 held-out test set, confirmed significant by Diebold-Mariano and Giacomini-White tests.
What carries the argument
An ensemble of three large language model judges that assign scores to five-day behavioral-trace episodes across the six dimensions, with a one-at-a-time perturbation procedure confirming dimension specificity and Krippendorff alpha of 0.85 measuring cross-judge agreement.
If this is right
- The behavioral score functions as a proxy for future trading performance that can be computed without waiting for realized returns.
- Dimension-specific penalties allow reinforcement learning to target particular weaknesses such as poor risk calibration or weak error recovery.
- Improvement is localized to high-volatility regimes according to the Giacomini-White test.
- The evaluation procedure is application-agnostic and can be applied to any agentic forecasting system that produces logged decision traces.
- Statistical significance holds under both equal-accuracy and conditional-predictive-ability tests.
Where Pith is reading between the lines
- Developers could use the dimension scores to automatically diagnose and patch specific failure modes in trading agents without needing external labels.
- The same scoring loop might be extended to live trading environments to detect whether behavioral quality translates differently under real-time market conditions.
- Combining the behavioral score with traditional point-forecast metrics could produce stronger overall benchmarks for financial AI systems.
- Testing whether scores remain stable when swapping one LLM judge model for another would clarify robustness across judge architectures.
Load-bearing premise
Large language model judges can score the six behavioral dimensions reliably and specifically without systematic bias or strong dependence on exact prompt wording.
What would settle it
Human financial experts independently scoring the same set of behavioral traces along the identical six dimensions and showing low agreement with the LLM ensemble, or new backtests in which the composite behavioral score shows no correlation with realized Sharpe ratios.
Figures






read the original abstract
Forecast evaluation in finance has relied on aggregate accuracy metrics and predictive-accuracy tests built on point-forecast errors. These instruments evaluate forecast outputs but cannot evaluate the process of forecast generation, which is increasingly relevant as forecasting systems become agentic, issuing forecasts through sequences of interdependent autonomous decisions whose individual quality is hidden by output-level errors. We propose a behavioral forecast-evaluation methodology that complements accuracy tests by assessing the intermediate decision process itself. Behavioral traces logged at every autonomous decision point are grouped into five-day episodes and scored along six domain-specific dimensions (regime detection, routing, adaptation, risk calibration, strategy coherence, error recovery) by an ensemble of three large language model (LLM) judges. A perturbation procedure that corrupts one dimension while leaving the other five intact confirms dimension specificity, with cross-model agreement reaching Krippendorff's $\alpha = 0.85$. The composite behavioral score correlates at Spearman $\rho = 0.72$ with realized 20-day Sharpe ratio from offline backtesting. Closing the loop, the framework converts deficient per-dimension scores into a credit-assigned penalty added to the Soft Actor-Critic reward. Three fine-tuning cycles, confined to the validation period, produce on the held-out 2017-2025 test period a one-day MAPE reduction from 0.61% to 0.54% (11.5% relative; $p<0.001$, Cohen's $d=0.31$), significant under a Diebold-Mariano test of equal predictive accuracy ($\mathrm{DM}=-7.83$) and localized by a Giacomini-White conditional predictive ability test to the high-volatility regime. The methodology is application-agnostic. Results are from offline backtesting and do not address effects specific to live deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a behavioral evaluation framework for agentic stock-prediction systems that logs decision traces, scores them along six dimensions (regime detection, routing, adaptation, risk calibration, strategy coherence, error recovery) via an ensemble of three LLM judges, validates dimension specificity through perturbation, reports a Spearman ρ=0.72 correlation between the composite score and 20-day Sharpe ratio, and closes the loop by feeding per-dimension penalties into a Soft Actor-Critic reward. Three RL fine-tuning cycles on the validation set yield an 11.5% relative MAPE reduction (0.61% to 0.54%) on the held-out 2017-2025 test set, significant under Diebold-Mariano (DM=-7.83) and Giacomini-White tests.
Significance. If the LLM-based behavioral scores prove reliable and free of systematic bias, the work supplies a process-level complement to conventional point-forecast metrics and demonstrates that credit-assigned RL feedback can measurably improve downstream accuracy in an offline backtesting setting. The reported correlation with realized Sharpe and the localized improvement in high-volatility regimes would be of direct interest to researchers developing autonomous forecasting agents.
major comments (3)
- [Abstract] Abstract and Methods: The reliability of the six-dimensional LLM scoring rests on Krippendorff’s α=0.85 and a single perturbation test, yet the manuscript supplies neither human-expert ratings on the same rubric nor any calibration of the rubric against realized trading outcomes beyond the aggregate Spearman correlation; without such external anchoring, systematic judge bias cannot be ruled out and directly threatens the validity of both the correlation and the subsequent RL reward signal.
- [Results] Results: The closed-loop incorporation of LLM-assigned per-dimension scores into the Soft Actor-Critic reward creates a circular dependence between the evaluation metric and the training objective; the reported MAPE improvement after three cycles therefore requires an ablation that isolates the contribution of the behavioral penalty from other RL components or from simple continued training on the same data.
- [Methods] Methods: Implementation details are missing for (a) the exact LLM prompts and temperature settings used by the three judges, (b) the precise procedure for corrupting one behavioral dimension while preserving the others, and (c) the temporal data splits and feature construction used in the 2017-2025 held-out test period; these omissions prevent independent reproduction and assessment of potential confounds such as look-ahead bias or regime-specific leakage.
minor comments (1)
- [Abstract] The abstract states that the methodology is “application-agnostic,” yet all empirical results are confined to equity price forecasting; a brief discussion of how the six dimensions would be redefined for other domains would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to supply the requested implementation details and to expand the discussion of limitations regarding LLM judge reliability. Below we respond point by point to each major comment.
read point-by-point responses
-
Referee: [Abstract] Abstract and Methods: The reliability of the six-dimensional LLM scoring rests on Krippendorff’s α=0.85 and a single perturbation test, yet the manuscript supplies neither human-expert ratings on the same rubric nor any calibration of the rubric against realized trading outcomes beyond the aggregate Spearman correlation; without such external anchoring, systematic judge bias cannot be ruled out and directly threatens the validity of both the correlation and the subsequent RL reward signal.
Authors: We agree that human-expert ratings on the rubric and additional calibration against trading outcomes would strengthen external validity. The present work supplies internal validation through Krippendorff’s α=0.85 and the perturbation test that isolates each dimension. The Spearman ρ=0.72 correlation with 20-day Sharpe ratio remains the primary external anchor. In the revised manuscript we have added a dedicated limitations paragraph that explicitly discusses the risk of systematic judge bias and states that human calibration is reserved for future work. revision: partial
-
Referee: [Results] Results: The closed-loop incorporation of LLM-assigned per-dimension scores into the Soft Actor-Critic reward creates a circular dependence between the evaluation metric and the training objective; the reported MAPE improvement after three cycles therefore requires an ablation that isolates the contribution of the behavioral penalty from other RL components or from simple continued training on the same data.
Authors: We acknowledge the concern. The three LLM judges are frozen and receive no updates during RL; penalties are computed once on validation episodes and then applied as a fixed additive term to the SAC reward. All policy optimization occurs on the validation set, while the reported MAPE reduction and statistical tests are obtained on the completely held-out 2017-2025 test set. We have added clarifying text in the revised Results section that emphasizes the separation between the fixed judges and the trainable policy, thereby addressing the circularity issue without new experiments. revision: partial
-
Referee: [Methods] Methods: Implementation details are missing for (a) the exact LLM prompts and temperature settings used by the three judges, (b) the precise procedure for corrupting one behavioral dimension while preserving the others, and (c) the temporal data splits and feature construction used in the 2017-2025 held-out test period; these omissions prevent independent reproduction and assessment of potential confounds such as look-ahead bias or regime-specific leakage.
Authors: We thank the referee for identifying these omissions. The revised manuscript now contains a new Appendix that supplies (a) the verbatim prompts and temperature=0.2 setting used by all three judges, (b) the exact corruption procedure (targeted replacement of only the elements belonging to the chosen dimension while leaving all other trace components unchanged), and (c) the precise temporal splits (training 2010-2016, validation 2016-2017, test 2017-2025) together with the feature list (20 lagged returns, volatility, volume) constructed without look-ahead information. These additions enable full reproduction. revision: yes
Circularity Check
No significant circularity detected in the derivation chain.
full rationale
The paper logs agent traces, scores them on six dimensions via LLM judges (validated by Krippendorff α=0.85 and perturbation specificity), reports an external Spearman ρ=0.72 correlation with realized 20-day Sharpe from offline backtesting, and applies the scores only as an RL reward signal during validation-period fine-tuning. Final claims rest on held-out 2017-2025 test-set MAPE reduction (0.61% to 0.54%) plus Diebold-Mariano and Giacomini-White tests. No equation or step reduces by construction to its own inputs; the accuracy metric is independent of the behavioral scores, the correlation supplies an external anchor, and no self-citation or ansatz smuggling is present in the provided derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Comparing predictive accuracy,
F. X. Diebold and R. S. Mariano, “Comparing predictive accuracy,” Journal of Business & Economic Statistics, vol. 13, no. 3, pp. 253–263, 1995
work page 1995
-
[2]
Testing the equality of prediction mean squared errors,
D. Harvey, S. Leybourne, and P. Newbold, “Testing the equality of prediction mean squared errors,”International Journal of Forecasting, vol. 13, no. 2, pp. 281–291, 1997
work page 1997
-
[3]
Asymptotic inference about predictive ability,
K. D. West, “Asymptotic inference about predictive ability,”Economet- rica, vol. 64, no. 5, pp. 1067–1084, 1996
work page 1996
-
[4]
Tests of conditional predictive ability,
R. Giacomini and H. White, “Tests of conditional predictive ability,” Econometrica, vol. 74, no. 6, pp. 1545–1578, 2006
work page 2006
-
[5]
P. R. Hansen, A. Lunde, and J. M. Nason, “The model confidence set,” Econometrica, vol. 79, no. 2, pp. 453–497, 2011
work page 2011
-
[6]
A. Timmermann, “Forecast combinations,” inHandbook of Economic Forecasting, G. Elliott, C. W. J. Granger, and A. Timmermann, Eds. North-Holland, 2006, vol. 1, pp. 135–196
work page 2006
-
[7]
M. Al Ridhawi, M. Haj Ali, and H. Al Osman, “Adaptive regime-aware stock price prediction using autoencoder-gated dual node transformers with reinforcement learning control,”Submitted to Applied Intelligence, 2026, under review. Preprint: arXiv:2603.19136
-
[8]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
work page 2024
-
[9]
The Rise and Potential of Large Language Model Based Agents: A Survey
Z. Xi, W. Chen, X. Guo, W. He, Y . Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhouet al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Lopez de Prado,Advances in Financial Machine Learning
M. Lopez de Prado,Advances in Financial Machine Learning. John Wiley & Sons, 2018
work page 2018
-
[11]
Analyzing the critical steps in deep learning- based stock forecasting: a literature review,
Z. D. Aks ¸ehir and E. Kılıc ¸, “Analyzing the critical steps in deep learning- based stock forecasting: a literature review,”PeerJ Computer Science, vol. 10, p. e2312, 2024
work page 2024
-
[12]
Data- driven stock forecasting models based on neural networks: A review,
W. Bao, Y . Cao, Y . Yang, H. Che, J. Huang, and S. Wen, “Data- driven stock forecasting models based on neural networks: A review,” Information Fusion, vol. 113, p. 102616, 2025
work page 2025
-
[13]
Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xinget al., “Judging LLM-as-a-Judge with MT- Bench and Chatbot Arena,”Advances in Neural Information Processing Systems, vol. 36, 2023
work page 2023
-
[14]
G-Eval: NLG evaluation using GPT-4 with better human alignment,
Y . Liu, D. Iter, Y . Xu, S. Wang, R. Xu, and C. Zhu, “G-Eval: NLG evaluation using GPT-4 with better human alignment,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 2511–2522
work page 2023
-
[15]
AlpacaFarm: A simulation framework for methods that learn from human feedback,
Y . Dubois, X. Li, R. Taori, T. Zhang, I. Gulrajani, J. Ba, C. Guestrin, P. Liang, and T. B. Hashimoto, “AlpacaFarm: A simulation framework for methods that learn from human feedback,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[16]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022
work page 2022
-
[17]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInternational Conference on Machine Learning. PMLR, 2018, pp. 1861–1870
work page 2018
-
[18]
Stock market prediction using node transformer architecture integrated with BERT sentiment analysis,
M. Al Ridhawi, M. Haj Ali, and H. Al Osman, “Stock market prediction using node transformer architecture integrated with BERT sentiment analysis,”IEEE Access, 2026
work page 2026
-
[19]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProceedings of the Eleventh International Conference on Learning Representations (ICLR), 2023, openReview: tvI4u1ylcqs
work page 2023
-
[20]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems, vol. 36, 2023, pp. 8634–8652
work page 2023
-
[21]
Computing Krippendorff’s alpha-reliability,
K. Krippendorff, “Computing Krippendorff’s alpha-reliability,”Annen- berg School for Communication Departmental Papers, 2011, available at https://repository.upenn.edu/asc papers/43/
work page 2011
-
[22]
A coefficient of agreement for nominal scales,
J. Cohen, “A coefficient of agreement for nominal scales,”Educational and Psychological Measurement, vol. 20, no. 1, pp. 37–46, 1960
work page 1960
-
[23]
Hillsdale, NJ, USA: Lawrence Erlbaum Associates, 1988
——,Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Hillsdale, NJ, USA: Lawrence Erlbaum Associates, 1988
work page 1988
-
[24]
B. Efron and R. J. Tibshirani,An Introduction to the Bootstrap. New York, NY , USA: Chapman and Hall/CRC, 1993
work page 1993
-
[25]
D. V . Cicchetti, “Guidelines, criteria, and rules of thumb for evaluat- ing normed and standardized assessment instruments in psychology,” Psychological Assessment, vol. 6, no. 4, pp. 284–290, 1994. APPENDIX APPENDIXA. LLM JUDGEPROMPTTEMPLATE This appendix records the prompt template applied uni- formly to all three judges (GPT 5.4, Claude 4.6 Opus, and ...
work page 1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.