Recognition: unknown
MaMi-HOI: Harmonizing Global Kinematics and Local Geometry for Human-Object Interaction Generation
Pith reviewed 2026-05-08 09:19 UTC · model grok-4.3
The pith
MaMi-HOI overcomes geometric forgetting in diffusion models to generate human-object interactions that are both naturally moving and precisely contacting objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
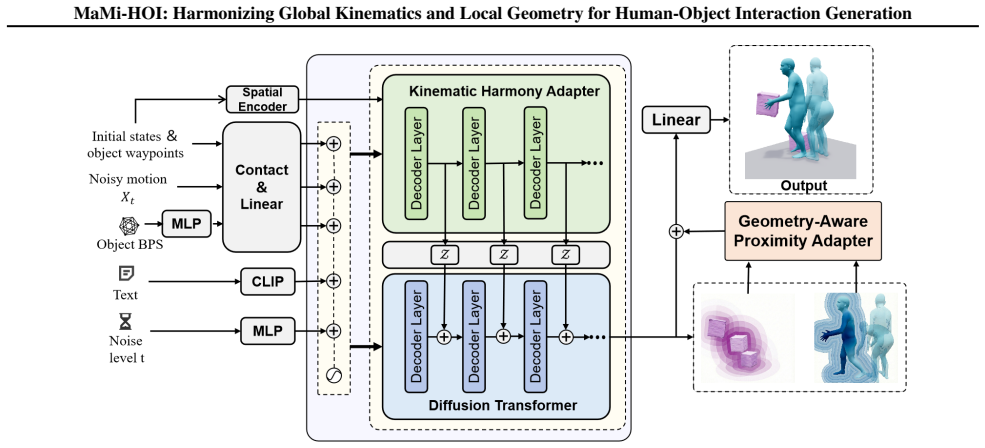
MaMi-HOI is a hierarchical framework reconciling macro-level kinematic fluidity with micro-level spatial precision. It counters geometric forgetting by using the Geometry-Aware Proximity Adapter (GAPA) to explicitly re-inject dense object details and perform residual snapping corrections for precise contact, paired with the Kinematic Harmony Adapter (KHA) to align whole-body posture with spatial objectives so the skeleton accommodates constraints naturally.
What carries the argument
The MaMi-HOI framework's Geometry-Aware Proximity Adapter (GAPA) for re-injecting object geometry to enable residual snapping corrections, combined with the Kinematic Harmony Adapter (KHA) for aligning whole-body posture with spatial objectives.
If this is right
- Precise object contacts are achieved simultaneously with natural whole-body motion.
- Generation extends reliably to long-term tasks involving complex trajectories.
- Global navigation and high-fidelity manipulation become bridged within the same 3D scene generation process.
- Quantitative and qualitative experiments confirm improvements in both contact accuracy and motion realism.
Where Pith is reading between the lines
- The adapter pattern could apply to other diffusion-based motion generators where local geometric details degrade in deeper layers.
- Robotics simulation and planning systems might gain more reliable contact-rich behaviors by incorporating similar geometry re-injection steps.
- Evaluating the method on a wider range of object shapes and interaction types would test whether the forgetting correction generalizes beyond the paper's scenes.
- Real-time VR or game engines could integrate the adapters to produce interactive, physically plausible human-object sequences on the fly.
Load-bearing premise
That geometric forgetting is the primary cause of imprecise contacts in existing methods and that the GAPA and KHA adapters can be added without introducing new motion artifacts or requiring major changes to the base diffusion process.
What would settle it
A controlled ablation on a standard HOI benchmark dataset measuring contact error rates and kinematic smoothness metrics over long sequences, where removing either adapter causes the method to lose its reported gains in precision or naturalness relative to baselines.
Figures






read the original abstract
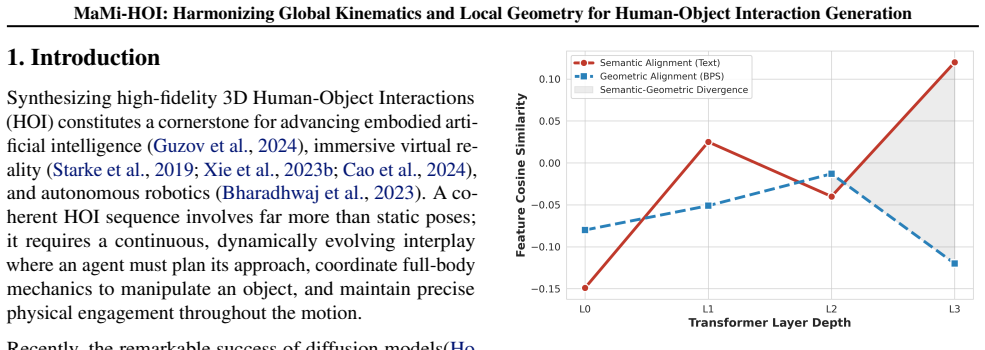
Generating realistic 3D Human-Object Interactions (HOI) is a fundamental task for applications ranging from embodied AI to virtual content creation, which requires harmonizing high-level semantic intent with strict low-level physical constraints. Existing methods excel at semantic alignment, however, they struggle to maintain precise object contact. We reveal a key finding termed \textit{Geometric Forgetting}: as diffusion model depth increases, semantic feature tend to overshadow object geometry feature, causing the model to lose its perception to object geometry. To address this, we propose MaMi-HOI, a hierarchical framework reconciling \textbf{Ma}cro-level kinematic fluidity with \textbf{Mi}cro-level spatial precision. First, to counteract geometric forgetting, we introduce the Geometry-Aware Proximity Adapter (GAPA), which explicitly re-injects dense object details to perform residual snapping corrections for precise contact. Nevertheless, such aggressive local enforcement can disrupt global dynamics, leading to robotic stiffness. In response, we introduce the Kinematic Harmony Adapter (KHA), which proactively aligns whole-body posture with spatial objectives, ensuring the skeleton actively accommodates constraints without compromising naturalness. Extensive experiments validate that MaMi-HOI simultaneously achieves natural motion and precise contact. Crucially, it extends generation capabilities to long-term tasks with complex trajectories, effectively bridging the gap between global navigation and high-fidelity manipulation in 3D scenes. Code is available at https://github.com/DON738110198/MaMi-HOI.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that diffusion-based HOI generation suffers from 'Geometric Forgetting,' where semantic features overshadow object geometry features at increasing model depth, causing imprecise contacts. To fix this, MaMi-HOI introduces a hierarchical framework with the Geometry-Aware Proximity Adapter (GAPA) for residual snapping corrections and the Kinematic Harmony Adapter (KHA) for whole-body posture alignment, claiming to achieve both natural motion and precise contact while extending to long-horizon tasks with complex trajectories in 3D scenes.
Significance. If validated, the approach could meaningfully advance HOI synthesis by reconciling global kinematics with local geometric constraints, with direct relevance to embodied AI and virtual content creation. The introduction of targeted adapters to mitigate a diagnosed diffusion pathology is a concrete engineering contribution, though its impact hinges on whether the adapters generalize without new artifacts.
major comments (2)
- [Abstract] Abstract: The central claim that 'Geometric Forgetting' is the key cause of imprecise contacts is presented as a revealed finding, yet no supporting quantitative evidence (layer-wise feature norms, attention weights, depth-vs-contact-error curves, or ablation on semantic vs. geometry feature dominance) is referenced. This makes it impossible to confirm that GAPA addresses the dominant failure mode rather than a secondary symptom, directly undermining the justification for the proposed adapters.
- [Abstract] Abstract / Experiments (implied): The assertion that GAPA and KHA can be inserted without creating new motion artifacts in long-horizon rollouts is load-bearing for the 'bridging global navigation and high-fidelity manipulation' claim, but the abstract provides no metrics, baselines, or ablation studies on contact precision, naturalness scores, or trajectory success rates to substantiate this. Without such data, the hierarchical reconciliation remains unverified.
minor comments (2)
- [Abstract] Abstract: Minor grammatical issues ('semantic feature tend' should be 'semantic features tend'; 'perception to object geometry' should be 'perception of object geometry') should be corrected for clarity.
- [Abstract] Abstract: The code link is provided, which is positive for reproducibility; ensure the repository includes the full training and evaluation scripts referenced in the experiments section.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, providing clarifications based on the manuscript content and indicating where we will make revisions to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Geometric Forgetting' is the key cause of imprecise contacts is presented as a revealed finding, yet no supporting quantitative evidence (layer-wise feature norms, attention weights, depth-vs-contact-error curves, or ablation on semantic vs. geometry feature dominance) is referenced. This makes it impossible to confirm that GAPA addresses the dominant failure mode rather than a secondary symptom, directly undermining the justification for the proposed adapters.
Authors: The manuscript presents Geometric Forgetting as a key finding supported by analysis of feature behavior across model depths, including comparisons of semantic and geometric feature influence and their correlation with contact errors. To improve accessibility and directly address the concern about substantiation in the abstract, we will revise the abstract to include a concise reference to this supporting analysis and the relevant figures. revision: yes
-
Referee: [Abstract] Abstract / Experiments (implied): The assertion that GAPA and KHA can be inserted without creating new motion artifacts in long-horizon rollouts is load-bearing for the 'bridging global navigation and high-fidelity manipulation' claim, but the abstract provides no metrics, baselines, or ablation studies on contact precision, naturalness scores, or trajectory success rates to substantiate this. Without such data, the hierarchical reconciliation remains unverified.
Authors: The full manuscript includes quantitative evaluations of long-horizon generation in the experiments section, reporting metrics for contact precision, naturalness via perceptual studies, trajectory success rates, and ablations against baselines that confirm the adapters do not introduce new artifacts. We will revise the abstract to summarize key quantitative results from these studies to better support the claims. revision: yes
Circularity Check
No circularity; adapters introduced as direct engineering fix to empirically noted limitation without self-referential definitions or fitted predictions.
full rationale
The paper's chain begins with an observed limitation (geometric forgetting in diffusion depth) and responds by proposing two new adapters (GAPA for residual snapping, KHA for posture alignment). No equations appear that define a target quantity in terms of itself, no 'predictions' reduce to parameters fitted on the same data, and no self-citations or uniqueness theorems are invoked as load-bearing justification. Claims of improved natural motion and precise contact rest on experimental validation rather than tautological construction, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic features tend to overshadow object geometry features as diffusion model depth increases
invented entities (2)
-
Geometry-Aware Proximity Adapter (GAPA)
no independent evidence
-
Kinematic Harmony Adapter (KHA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 International Conference on 3D Vision (3DV) , pages=
Interaction replica: Tracking human--object interaction and scene changes from human motion , author=. 2024 International Conference on 3D Vision (3DV) , pages=. 2024 , organization=
2024
-
[2]
ACM Transactions on Graphics , volume=
Neural state machine for character-scene interactions , author=. ACM Transactions on Graphics , volume=. 2019 , publisher=
2019
-
[3]
Proceedings of the ACM on Computer Graphics and Interactive Techniques , volume=
Hierarchical planning and control for box loco-manipulation , author=. Proceedings of the ACM on Computer Graphics and Interactive Techniques , volume=. 2023 , publisher=
2023
-
[4]
Avatargo: Zero-shot 4d human-object interaction generation and animation , author=. arXiv preprint arXiv:2410.07164 , year=
-
[5]
Zero-shot robot manipulation from passive human videos , author=. arXiv preprint arXiv:2302.02011 , year=
-
[6]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
On the continuity of rotation representations in neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[7]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Expressive body capture: 3d hands, face, and body from a single image , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[8]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Efficient learning on point clouds with basis point sets , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[9]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[10]
ACM Transactions on Graphics (TOG) , volume=
Object motion guided human motion synthesis , author=. ACM Transactions on Graphics (TOG) , volume=. 2023 , publisher=
2023
-
[11]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[12]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Point transformer , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[13]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Guiding Human-Object Interactions with Rich Geometry and Relations , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[14]
European Conference on Computer Vision , pages=
Controllable human-object interaction synthesis , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[15]
International Journal of Computer Vision , volume=
3d-future: 3d furniture shape with texture , author=. International Journal of Computer Vision , volume=. 2021 , publisher=
2021
-
[16]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[17]
Hoi-dyn: Learn- ing interaction dynamics for human-object motion diffusion
HOI-Dyn: Learning Interaction Dynamics for Human-Object Motion Diffusion , author=. arXiv preprint arXiv:2507.01737 , year=
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Interdiff: Generating 3d human-object interactions with physics-informed diffusion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
Human motion diffusion model , author=. arXiv preprint arXiv:2209.14916 , year=
work page internal anchor Pith review arXiv
-
[20]
The Replica Dataset: A Digital Replica of Indoor Spaces
The replica dataset: A digital replica of indoor spaces , author=. arXiv preprint arXiv:1906.05797 , year=
work page internal anchor Pith review arXiv 1906
-
[21]
arXiv preprint arXiv:2310.08580 , year=
Omnicontrol: Control any joint at any time for human motion generation , author=. arXiv preprint arXiv:2310.08580 , year=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cg-hoi: Contact-guided 3d human-object interaction generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Hoi-diff: Text-driven synthesis of 3d human-object interactions using diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[24]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Chainhoi: Joint-based kinematic chain modeling for human-object interaction generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[25]
arXiv preprint arXiv:2407.20545 , year=
Stackflow: Monocular human-object reconstruction by stacked normalizing flow with offset , author=. arXiv preprint arXiv:2407.20545 , year=
-
[26]
European Conference on Computer Vision , pages=
Chore: Contact, human and object reconstruction from a single rgb image , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Joint reconstruction of 3d human and object via contact-based refinement transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hoianimator: Generating text-prompt human-object animations using novel perceptive diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Text2hoi: Text-guided 3d motion generation for hand-object interaction , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
Thor: Text to human-object interaction diffusion via relation intervention , author=. arXiv preprint arXiv:2403.11208 , year=
-
[31]
International conference on machine learning , pages=
Improved denoising diffusion probabilistic models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[32]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora: A review on background, technology, limitations, and opportunities of large vision models , author=. arXiv preprint arXiv:2402.17177 , year=
work page internal anchor Pith review arXiv
-
[33]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review arXiv
-
[34]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Diffusion-based generation, optimization, and planning in 3d scenes , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Generating human motion in 3d scenes from text descriptions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[37]
Advances in Neural Information Processing Systems , volume=
Humanise: Language-conditioned human motion generation in 3d scenes , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Synthesizing diverse human motions in 3d indoor scenes , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Human-object interaction from human-level instructions , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[40]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Generating diverse and natural 3d human motions from text , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.