Recognition: unknown
LCC-LLM: Leveraging Code-Centric Large Language Models for Malware Attribution
Pith reviewed 2026-05-08 09:30 UTC · model grok-4.3
The pith
Grounding LLMs in decompiled code improves malware analysis reliability
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that code-centric representations, retrieval grounding, and verification-guided reasoning improve the reliability and operational usefulness of LLM-assisted malware attribution, demonstrated through evaluations on 43 task types and a successful real-world case study.
What carries the argument
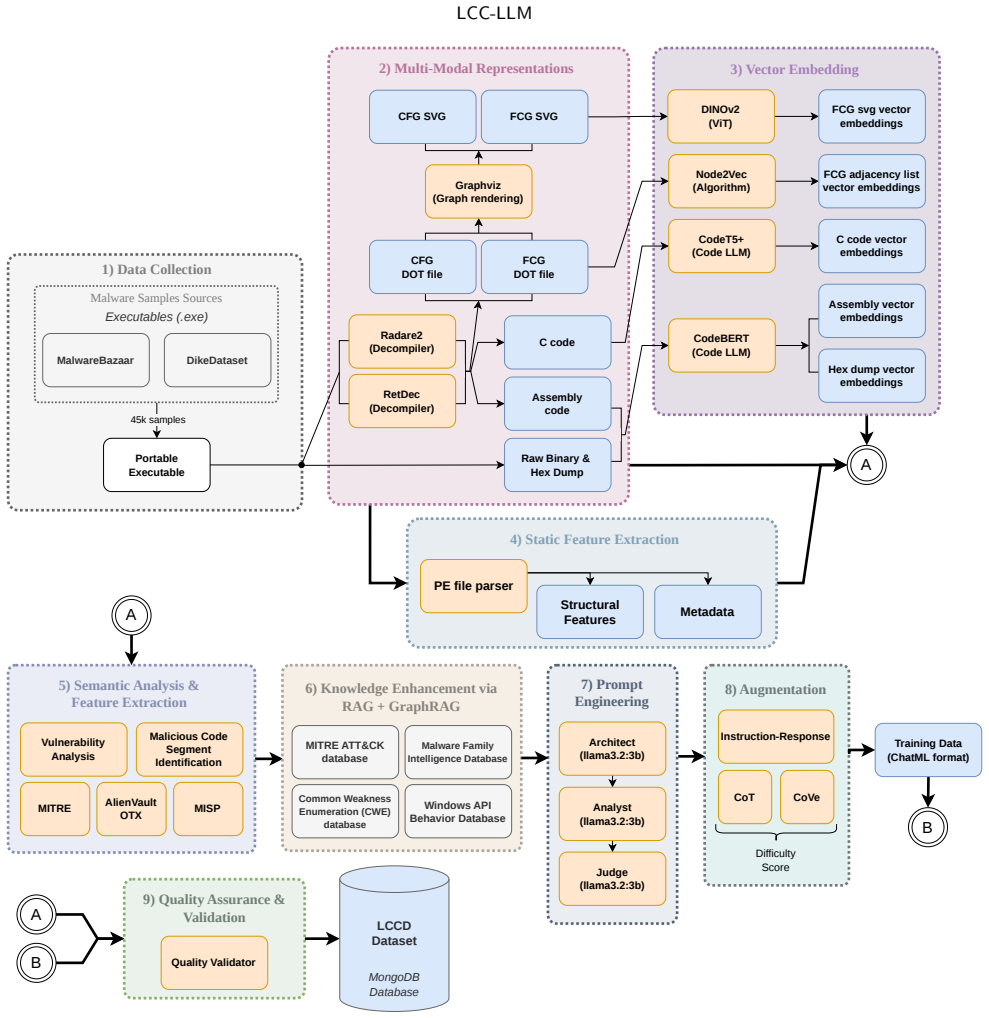
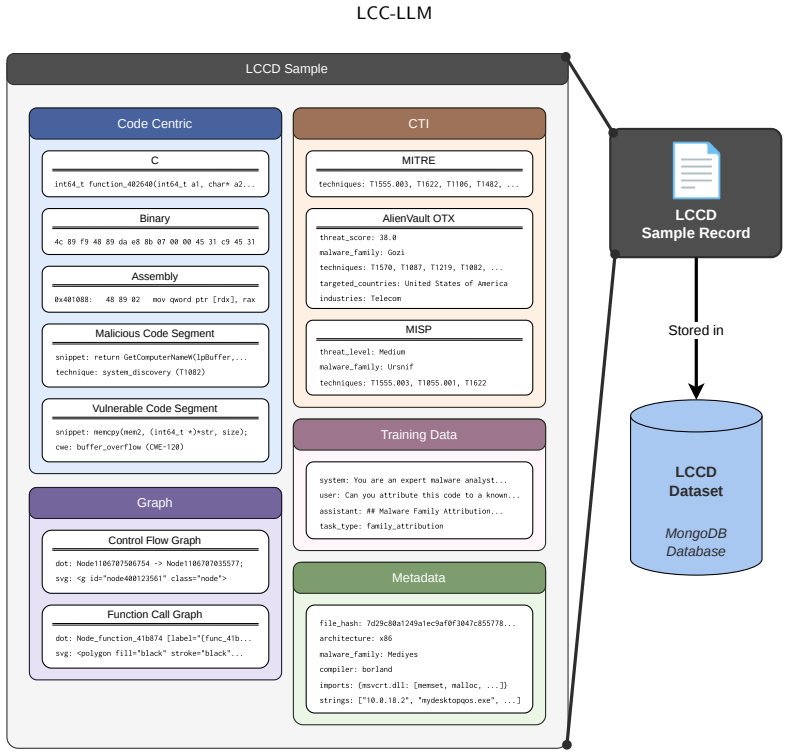
The central mechanism is the evidence-grounded framework using the LCCD dataset of decompiled C code, assembly, CFG/FCG artifacts, and a seven-layer retrieval-augmented generation pipeline with quality gates for factual reliability.
If this is right
- Highest performance occurs in structured report generation, IoC extraction, vulnerability assessment, malware configuration extraction, and malware class detection.
- The system achieves a complete pass rate in producing structured analyses, evidence, mappings, and guidance for real malware samples.
- Fine-tuned models using curriculum data support consistent multi-task performance.
- The combination of code representations and verification reduces factual errors in attribution tasks.
Where Pith is reading between the lines
- This grounding technique could apply to other code analysis domains like detecting vulnerabilities in open source projects.
- Future work might test the framework on larger or more diverse malware families to confirm scalability.
- Integration with human analysts could create hybrid workflows where the LLM handles initial evidence gathering.
Load-bearing premise
The reverse-engineering pipeline produces decompiled code and artifacts that accurately represent the malware's original behavior for reliable LLM reasoning.
What would settle it
A direct comparison of the pipeline's decompiled outputs against expert manual reverse engineering on a set of samples would reveal if inaccuracies in the code representations lead to incorrect analysis conclusions.
Figures











read the original abstract
LLMs are increasingly explored for malware analysis; however, current LLM-based malware attribution remains limited by unsupported indicators and insufficient code-level grounding for identifying malicious and vulnerable code segments. To address these limitations, this research introduces LCC-LLM, a code-centric benchmark dataset and evidence-grounded framework for malware attribution and multi-task static malware analysis. The proposed LCCD dataset contains approximately 34K PE samples processed through a large-scale reverse-engineering pipeline and represented using decompiled C code, assembly code, CFG/FCG artifacts, hexadecimal data, PE metadata, suspicious API evidence, and structural features. Beyond dataset construction, LCC-LLM integrates LangGraph-orchestrated static analysis with multi-source cybersecurity knowledge to support evidence-grounded malware reasoning. The framework employs a seven-layer retrieval-augmented generation pipeline, CoVe for IoC validation, and a multi-dimensional quality gate to improve factual reliability and analyst-oriented decision support. Curriculum-ordered instruction data is used to fine-tune DeepSeek-R1-Distill-Qwen-14B and Qwen3-Coder-30B-A3B using QLoRA. Evaluation across 43 malware-analysis task types achieves an average semantic similarity of 0.634, with the highest task-level performance in structured report generation, IoC extraction, vulnerability assessment, malware configuration extraction, and malware class detection. In a real-world case study using MalwareBazaar samples, the grounded pipeline achieves a 10/10 structured analysis pass rate, producing CFG/FCG evidence, MITRE ATT&CK mappings, detection guidance, and analyst-ready reports. These results show that code-centric representations, retrieval grounding, and verification-guided reasoning improve the reliability and operational usefulness of LLM-assisted malware attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents LCC-LLM, a code-centric benchmark dataset (LCCD) of ~34K PE samples represented via decompiled C code, assembly, CFG/FCG artifacts, hexadecimal data, PE metadata, suspicious APIs, and structural features, together with a LangGraph-orchestrated framework that combines multi-source RAG, CoVe IoC validation, and multi-dimensional quality gates. Curriculum-ordered instruction data is used to fine-tune DeepSeek-R1-Distill-Qwen-14B and Qwen3-Coder-30B-A3B via QLoRA. Evaluation on 43 malware-analysis task types reports an average semantic similarity of 0.634 (highest in structured report generation, IoC extraction, vulnerability assessment, malware configuration extraction, and class detection), and a real-world MalwareBazaar case study achieves a 10/10 structured analysis pass rate with CFG/FCG evidence, MITRE ATT&CK mappings, detection guidance, and analyst-ready reports.
Significance. If the decompilation pipeline preserves semantics and the evaluation is robust, the work would constitute a meaningful advance in LLM-assisted malware attribution by shifting from unsupported indicators to code-level and structural grounding. The integration of LangGraph orchestration, verification-guided reasoning, and a large multi-task benchmark addresses documented limitations in current approaches and could improve operational reliability for analysts. Explicit strengths include the scale of the LCCD dataset, the curriculum fine-tuning protocol, and the end-to-end evidence pipeline demonstrated in the case study.
major comments (2)
- [Dataset construction and reverse-engineering pipeline] The central claims rest on the assumption that the large-scale reverse-engineering pipeline produces decompiled C code, assembly, CFG/FCG, and API evidence that faithfully represent original malware behavior for the 34K PE samples. The manuscript describes the pipeline but supplies no quantitative validation (e.g., manual audit rates, behavioral equivalence checks against packed/obfuscated binaries, or inter-tool agreement metrics). This unverified fidelity directly underpins the fine-tuning corpus, RAG grounding, and all reported task performances including the 0.634 average semantic similarity and 10/10 case-study pass rate.
- [Evaluation section] Evaluation across 43 task types reports an average semantic similarity of 0.634 without baselines, details on the semantic similarity computation (embedding model, aggregation method), error analysis, or controls for dataset-construction biases. These omissions make it impossible to determine whether the observed performance represents a genuine improvement or is inflated by the custom LCCD data distribution.
minor comments (2)
- [Fine-tuning description] The abstract and methods sections mention QLoRA fine-tuning but do not list the exact rank, alpha, dropout, or learning-rate schedule; adding these hyperparameters would improve reproducibility.
- [Results tables and figures] Figure captions and table headers could more explicitly state the number of samples per task type and the exact definition of 'semantic similarity' to aid quick assessment of the 43-task results.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments identify important areas for strengthening the manuscript, particularly around pipeline validation and evaluation transparency. We address each major comment below and will incorporate the necessary additions and clarifications in the revised version.
read point-by-point responses
-
Referee: [Dataset construction and reverse-engineering pipeline] The central claims rest on the assumption that the large-scale reverse-engineering pipeline produces decompiled C code, assembly, CFG/FCG, and API evidence that faithfully represent original malware behavior for the 34K PE samples. The manuscript describes the pipeline but supplies no quantitative validation (e.g., manual audit rates, behavioral equivalence checks against packed/obfuscated binaries, or inter-tool agreement metrics). This unverified fidelity directly underpins the fine-tuning corpus, RAG grounding, and all reported task performances including the 0.634 average semantic similarity and 10/10 case-study pass rate.
Authors: We acknowledge that the manuscript describes the pipeline steps in detail but does not include quantitative fidelity metrics, which is a valid concern given the central role of the LCCD dataset. The pipeline relies on established tools (Ghidra for decompilation and CFG/FCG extraction, custom scripts for API and metadata parsing) with documented configurations for handling PE samples. In the revised manuscript we will add a dedicated validation subsection reporting: (i) results from a manual audit of 150 randomly sampled binaries by two independent analysts, including agreement rates on semantic preservation of key behaviors; (ii) inter-tool consistency statistics between Ghidra and IDA Pro outputs on a 500-sample subset; and (iii) a stratified analysis of performance on packed versus unpacked samples together with the unpacking heuristics employed. These additions will provide concrete evidence while transparently noting limitations for heavily obfuscated cases where full behavioral equivalence cannot be statically verified. revision: yes
-
Referee: [Evaluation section] Evaluation across 43 task types reports an average semantic similarity of 0.634 without baselines, details on the semantic similarity computation (embedding model, aggregation method), error analysis, or controls for dataset-construction biases. These omissions make it impossible to determine whether the observed performance represents a genuine improvement or is inflated by the custom LCCD data distribution.
Authors: We agree that the evaluation section would be strengthened by additional methodological details and comparative context. The reported 0.634 figure is the macro-average semantic similarity across the 43 tasks, computed with a fixed sentence embedding model. In the revision we will: (1) explicitly state the embedding model, similarity function, and aggregation method; (2) add baseline results for the untuned base models both with and without the RAG component; (3) include an error analysis categorizing failures (factual inaccuracies, structural omissions, etc.) with representative examples; (4) provide controls for dataset bias by reporting performance stratified by sample attributes such as packing status and malware family; and (5) include a per-task performance table. These changes will enable readers to assess whether the results reflect genuine gains from the code-centric approach. revision: yes
Circularity Check
No circularity: empirical results from dataset construction, fine-tuning, and task evaluation do not reduce to inputs by construction
full rationale
The paper describes an empirical workflow: building the LCCD dataset via a reverse-engineering pipeline on 34K PE samples, fine-tuning LLMs with curriculum instruction data and QLoRA, then measuring performance via semantic similarity across 43 tasks plus a real-world case study. No equations, fitted parameters renamed as predictions, or self-citation chains are invoked to derive the reported 0.634 average similarity or 10/10 pass rate. All central claims are direct experimental outputs against external benchmarks and samples, satisfying the self-contained criterion with no definitional or statistical forcing.
Axiom & Free-Parameter Ledger
free parameters (1)
- QLoRA fine-tuning configuration
axioms (1)
- domain assumption Decompiled C code and CFG/FCG artifacts from the reverse-engineering pipeline accurately capture malware semantics and structure
Reference graph
Works this paper leans on
-
[1]
Adversarial attacks against windows pe malware detection: A survey of the state-of-the-art.Computers & Security, 128:103134, 2023
Xiang Ling, Lingfei Wu, Jiangyu Zhang, Zhenqing Qu, Wei Deng, XiangChen,YaguanQian,ChunmingWu,ShoulingJi,TianyueLuo, et al. Adversarial attacks against windows pe malware detection: A survey of the state-of-the-art.Computers & Security, 128:103134, 2023
2023
-
[2]
Cross-silo federated learn- ing in security operations centers for effective malware detection: G
Georgios Xenos and Dimitrios Serpanos. Cross-silo federated learn- ing in security operations centers for effective malware detection: G. xenos,d.serpanos.InternationalJournalofInformationSecurity,24 (4):185, 2025
2025
-
[3]
A survey of strategy-driven evasion methods for pe malware: Transformation, concealment, and attack.Computers & Security, 137:103595, 2024
Jiaxuan Geng, Junfeng Wang, Zhiyang Fang, Yingjie Zhou, Di Wu, and Wenhan Ge. A survey of strategy-driven evasion methods for pe malware: Transformation, concealment, and attack.Computers & Security, 137:103595, 2024
2024
-
[4]
Fcg-mfd: Benchmark function call graph- based dataset for malware family detection.Journal of Network and Computer Applications, 233:104050, 2025
Hassan Jalil Hadi, Yue Cao, Sifan Li, Naveed Ahmad, and Mo- hammed Ali Alshara. Fcg-mfd: Benchmark function call graph- based dataset for malware family detection.Journal of Network and Computer Applications, 233:104050, 2025
2025
-
[5]
Malware reverse engineeringwithlargelanguagemodelforsuperiorcodecomprehen- sibility and ioc recommendations
Ashley Q Williamson and Michael Beauparlant. Malware reverse engineeringwithlargelanguagemodelforsuperiorcodecomprehen- sibility and ioc recommendations. 2024
2024
-
[6]
Hamed Jelodar, Samita Bai, Parisa Hamedi, Hesamodin Mohamma- dian, Roozbeh Razavi-Far, and Ali Ghorbani. Large language model (llm) for software security: Code analysis, malware analysis, reverse engineering.arXiv preprint arXiv:2504.07137, 2025. First Author et al.:Preprint submitted to ElsevierPage 18 of 23 LCC-LLM
-
[7]
Dynamic malware analysis in the modern era—a state of the art survey.ACM Computing Surveys (CSUR), 52(5):1–48, 2019
Ori Or-Meir, Nir Nissim, Yuval Elovici, and Lior Rokach. Dynamic malware analysis in the modern era—a state of the art survey.ACM Computing Surveys (CSUR), 52(5):1–48, 2019
2019
-
[8]
Survey of machine learning techniques for malware analysis.Computers & Security, 81:123–147, 2019
Daniele Ucci, Leonardo Aniello, and Roberto Baldoni. Survey of machine learning techniques for malware analysis.Computers & Security, 81:123–147, 2019
2019
-
[9]
A survey on automated dynamic malware-analysis tech- niquesandtools.ACMcomputingsurveys(CSUR),44(2):1–42,2008
Manuel Egele, Theodoor Scholte, Engin Kirda, and Christopher Kruegel. A survey on automated dynamic malware-analysis tech- niquesandtools.ACMcomputingsurveys(CSUR),44(2):1–42,2008
2008
-
[10]
Code authorship attribution: Methods and challenges.ACM Computing Surveys (CSUR), 52(1): 1–36, 2019
Vaibhavi Kalgutkar, Ratinder Kaur, Hugo Gonzalez, Natalia Stakhanova, and Alina Matyukhina. Code authorship attribution: Methods and challenges.ACM Computing Surveys (CSUR), 52(1): 1–36, 2019
2019
-
[11]
An empirical study of malicious code in pypi ecosys- tem.In202338thIEEE/ACMInternationalConferenceonAutomated Software Engineering (ASE), pages 166–177
Wenbo Guo, Zhengzi Xu, Chengwei Liu, Cheng Huang, Yong Fang, and Yang Liu. An empirical study of malicious code in pypi ecosys- tem.In202338thIEEE/ACMInternationalConferenceonAutomated Software Engineering (ASE), pages 166–177. IEEE, 2023
2023
-
[12]
Jstrong: Malicious javascript detection based on code semantic representation and graph neural network.Computers & Security, 118:102715, 2022
Yong Fang, Chaoyi Huang, Minchuan Zeng, Zhiying Zhao, and Cheng Huang. Jstrong: Malicious javascript detection based on code semantic representation and graph neural network.Computers & Security, 118:102715, 2022
2022
-
[13]
https://doi.org/10.48550/ARXIV.2403.18624 arXiv:2403.18624
Yangruibo Ding, Yanjun Fu, Omniyyah Ibrahim, Chawin Sitawarin, Xinyun Chen, Basel Alomair, David Wagner, Baishakhi Ray, and Yizheng Chen. Vulnerability detection with code language models: How far are we?arXiv preprint arXiv:2403.18624, 2024
-
[14]
Jamal Al-Karaki, Muhammad Al-Zafar Khan, and Marwan Omar. Exploringllmsformalwaredetection:Review,frameworkdesign,and countermeasureapproaches.arXivpreprintarXiv:2409.07587,2024
-
[15]
Llm-maldetect:Alargelanguagemodel-basedmethodfor android malware detection.IEEE Access, 2025
Ruirui Feng, Hui Chen, Shuo Wang, Md Monjurul Karim, and Qing- shanJiang. Llm-maldetect:Alargelanguagemodel-basedmethodfor android malware detection.IEEE Access, 2025
2025
-
[16]
” digital camouflage”: The llvm challenge in llm-based malware detection.Journal of Systems and Software, page 112646, 2025
Ekin Böke and Simon Torka. ” digital camouflage”: The llvm challenge in llm-based malware detection.Journal of Systems and Software, page 112646, 2025
2025
-
[17]
Samita Bai, Hamed Jelodar, Tochukwu Emmanuel Nwankwo, Parisa Hamedi, Mohammad Meymani, Roozbeh Razavi-Far, and Ali A Ghorbani. Automated malware family classification using weighted hierarchical ensembles of large language models.arXiv preprint arXiv:2604.02490, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
LLM4CodeRE: Generative AI for Code Decompilation Analysis and Reverse Engineering
Hamed Jelodar, Samita Bai, Tochukwu Emmanuel Nwankwo, Parisa Hamedi, Mohammad Meymani, Roozbeh Razavi-Far, and Ali A Ghorbani. Llm4codere:Generativeaiforcodedecompilationanalysis and reverse engineering.arXiv preprint arXiv:2604.06095, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
HamedJelodar,MohammadMeymani,SamitaBai,RoozbehRazavi- Far, and Ali A Ghorbani. Sban: A framework & multi-dimensional dataset for large language model pre-training and software code mining.arXiv preprint arXiv:2510.18936, 2025
-
[20]
The malicia dataset: identification and analysis of drive-by download operations
Antonio Nappa, M Zubair Rafique, and Juan Caballero. The malicia dataset: identification and analysis of drive-by download operations. International Journal of Information Security, 14(1):15–33, 2015
2015
-
[21]
Microsoftmalwareclassificationchallenge.arXiv preprint arXiv:1802.10135, 2018
Royi Ronen, Marian Radu, Corina Feuerstein, Elad Yom-Tov, and MansourAhmadi. Microsoftmalwareclassificationchallenge.arXiv preprint arXiv:1802.10135, 2018
-
[22]
EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models
Hyrum S Anderson and Phil Roth. Ember: an open dataset for training static pe malware machine learning models.arXiv preprint arXiv:1804.04637, 2018
work page Pith review arXiv 2018
-
[23]
Richard Harang and Ethan M Rudd. Sorel-20m: A large scale benchmark dataset for malicious pe detection.arXiv preprint arXiv:2012.07634, 2020
-
[24]
Bodmas: An open dataset for learning based temporal analysis of pe malware
Limin Yang, Arridhana Ciptadi, Ihar Laziuk, Ali Ahmadzadeh, and Gang Wang. Bodmas: An open dataset for learning based temporal analysis of pe malware. In2021 IEEE Security and Privacy Work- shops (SPW), pages 78–84. IEEE, 2021
2021
-
[25]
Explainable malware detectionthroughintegratedgraphreductionandlearningtechniques
Hesamodin Mohammadian, Griffin Higgins, Samuel Ansong, Roozbeh Razavi-Far, and Ali A Ghorbani. Explainable malware detectionthroughintegratedgraphreductionandlearningtechniques. Big Data Research, page 100555, 2025
2025
-
[26]
Sigil: a signature-based approach of malware detection on intermediate language
Giancarlo Fortino, Claudia Greco, Antonella Guzzo, and Michele Ianni. Sigil: a signature-based approach of malware detection on intermediate language. InEuropean symposium on research in computer security, pages 256–266. Springer, 2023
2023
-
[27]
Static multi feature-based malware detection using multi spp- net in smart iot environments.IEEE Transactions on Information Forensics and Security, 19:2487–2500, 2024
Jueun Jeon, Byeonghui Jeong, Seungyeon Baek, and Young-Sik Jeong. Static multi feature-based malware detection using multi spp- net in smart iot environments.IEEE Transactions on Information Forensics and Security, 19:2487–2500, 2024
2024
-
[28]
On the security of machine learning in malware c&c detection: A survey.ACM Computing Surveys (CSUR), 49(3):1–39, 2016
Joseph Gardiner and Shishir Nagaraja. On the security of machine learning in malware c&c detection: A survey.ACM Computing Surveys (CSUR), 49(3):1–39, 2016
2016
-
[29]
A compre- hensivesurveyondeeplearningbasedmalwaredetectiontechniques
Mohana Gopinath and Sibi Chakkaravarthy Sethuraman. A compre- hensivesurveyondeeplearningbasedmalwaredetectiontechniques. Computer science review, 47:100529, 2023
2023
-
[30]
Malwareanalysisofimagedbinarysamples by convolutional neural network with attention mechanism
Hiromu Yakura, Shinnosuke Shinozaki, Reon Nishimura, Yoshihiro Oyama,andJunSakuma. Malwareanalysisofimagedbinarysamples by convolutional neural network with attention mechanism. In ProceedingsoftheEighthACMConferenceonDataandApplication Security and Privacy, pages 127–134. ACM, March 2018
2018
-
[31]
A survey of malware analysis using community detection algorithms.ACM Computing Surveys, 56(2):1–29, 2023
Amira, Abdelouahid Derhab, Elmouatez Billah Karbab, and Omar Nouali. A survey of malware analysis using community detection algorithms.ACM Computing Surveys, 56(2):1–29, 2023
2023
-
[32]
Acomprehensive survey on deep learning based malware detection techniques.Com- puter Science Review, 47:100529, 2023
M.GopinathandSibiChakkaravarthySethuraman. Acomprehensive survey on deep learning based malware detection techniques.Com- puter Science Review, 47:100529, 2023
2023
-
[33]
Nicholas
Edward Raff, Jon Barker, Jared Sylvester, Robert Brandon, Bryan Catanzaro, and Charles K. Nicholas. Malware detection by eating a whole EXE. InWorkshops at the Thirty-Second AAAI Conference on Artificial Intelligence, 2018
2018
-
[34]
An investigation of byte n-gram features for malware classification
Edward Raff, Richard Zak, Russell Cox, Jared Sylvester, Paul Yacci, Rebecca Ward, Anna Tracy, Mark McLean, and Charles Nicholas. An investigation of byte n-gram features for malware classification. Journal of Computer Virology and Hacking Techniques, 14:1–20, 2018
2018
-
[35]
Towards a fair comparison and realistic evaluation framework of android malware detectors based on static analysis and machine learning.Computers & Security, 124:102996, 2023
BorjaMolina-Coronado,UsueMori,AlexanderMendiburu,andJose Miguel-Alonso. Towards a fair comparison and realistic evaluation framework of android malware detectors based on static analysis and machine learning.Computers & Security, 124:102996, 2023
2023
-
[36]
Graph neural network-based android malware classification with jumping knowledge
WaiWengLo,SiamakLayeghy,MohanadSarhan,MarcusGallagher, and Marius Portmann. Graph neural network-based android malware classification with jumping knowledge. In2022 IEEE Conference on Dependable and Secure Computing (DSC), pages 1–9. IEEE, June 2022
2022
-
[37]
Rami Sihwail, Khairuddin Omar, and K. A. Zainol Ariffin. A survey onmalwareanalysistechniques:Static,dynamic,hybridandmemory analysis.International Journal of Advanced Science, Engineering and Information Technology, 8(4-2):1662–1671, 2018
2018
-
[38]
In2018 8th International Conference on Cloud Computing,DataScience&Engineering(Confluence),pages14–15
ShubhamAgarwalandGauravRaj.FRAME:Frameworkforrealtime analysis of malware. In2018 8th International Conference on Cloud Computing,DataScience&Engineering(Confluence),pages14–15. IEEE, 2018
2018
-
[39]
Dynamic malware analysis in the modern era—a state of the art survey.ACM Computing Surveys, 52(5):1–48, 2019
Ori Or-Meir, Nir Nissim, Yuval Elovici, and Lior Rokach. Dynamic malware analysis in the modern era—a state of the art survey.ACM Computing Surveys, 52(5):1–48, 2019
2019
-
[40]
Malqwen: Fine tuned llm for static android malware analysis report
TegarGanangSatrioPriambodo,AngelaOryzaPrabowo,AnnisaDwi Puspitarini, Raihan Adam Handoyo Winarso, Nur Aisyah, Moham- mad Yoga Pratama, Diana Purwitasari, and Baskoro Adi Pratomo. Malqwen: Fine tuned llm for static android malware analysis report. IEEE Access, 13:208483–208497, 2025
2025
-
[41]
Seman- tic preprocessing for llm-based malware analysis.arXiv preprint arXiv:2506.12113, 2025
Benjamin Marais, Tony Quertier, and Grégoire Barrue. Seman- tic preprocessing for llm-based malware analysis.arXiv preprint arXiv:2506.12113, 2025
-
[42]
DikeDataset, 2021
George-Andrei Iosif. DikeDataset, 2021. URLhttps://github.com/i osifache/DikeDataset. original-date: 2021-03-10T10:59:27Z
2021
-
[43]
MalwareBazaar | Malware sample exchange
Abuse.ch. MalwareBazaar | Malware sample exchange. URLhttps: //bazaar.abuse.ch/. First Author et al.:Preprint submitted to ElsevierPage 19 of 23 LCC-LLM
-
[44]
RetDec: A Retargetable Machine-Code Decompiler, March 2026
Avast Software. RetDec: A Retargetable Machine-Code Decompiler, March 2026. URLhttps://retdec.com/. original-date: 2017-12- 12T09:04:24Z
2026
-
[45]
Radare2: Libre Reversing Framework for Unix Geeks, March 2026
Radare Org. Radare2: Libre Reversing Framework for Unix Geeks, March 2026. URLhttps://github.com/radareorg/radare2. original- date: 2012-07-03T07:42:26Z
2026
-
[46]
Capstone Engine, March 2026
Nguyen Anh Quynh. Capstone Engine, March 2026. URLhttps: //github.com/capstone- engine/capstone. original-date: 2013-11- 27T02:32:11Z
2026
-
[47]
Guangyu Zhang, Xixuan Wang, Shiyu Sun, Peiyan Xiao, Kun Sun, and Yanhai Xiong. TraceRAG: A LLM-Based Framework for Explainable Android Malware Detection and Behavior Analysis, September 2025. URLh t tp : / / a r x i v . o r g / a b s / 2 5 0 9 . 0 8 8 65. arXiv:2509.08865 [cs]
- [48]
-
[49]
Stephanie Lin, Jacob Hilton, and Owain Evans
Yue Wang, Hung Le, Akhilesh Gotmare, Nghi Bui, Junnan Li, and Steven Hoi. CodeT5+: Open Code Large Language Models for Code Understanding and Generation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1069– 1088, Singapore, December 2023. Association for C...
-
[50]
CodeBERT:APre-TrainedModelforProgrammingand NaturalLanguages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and MingZhou. CodeBERT:APre-TrainedModelforProgrammingand NaturalLanguages. InTrevorCohn,YulanHe,andYangLiu,editors, Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1536–1547, Online, November 2020. Associatio...
-
[51]
Jesia Yuki, Mohammadhossein Amouei, Benjamin C. M. Fung, Philippe Charland, and Andrew Walenstein. AsmDocGen: Gener- ating Functional Natural Language Descriptions for Assembly Code. pages 35–45, March 2026. ISBN 978-989-758-706-1. doi: 10.5220/ 0012761400003753. URLhttps://www.scitepress.org/Link.aspx?d oi=10.5220/0012761400003753
-
[52]
node2vec: Scalable Feature Learning for Networks
Aditya Grover and Jure Leskovec. node2vec: Scalable Feature Learning for Networks. InProceedings of the 22nd ACM SIGKDD InternationalConferenceonKnowledgeDiscoveryandDataMining, KDD ’16, pages 855–864, New York, NY, USA, August 2016. As- sociation for Computing Machinery. ISBN 978-1-4503-4232-2. doi: 10.1145/2939672.2939754. URLhttps://dl.acm.org/doi/10.1...
-
[53]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Fran- cisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Is- hanMisra,MichaelRabbat,VasuSharma,GabrielSynnaeve,HuXu, HervéJegou,JulienMairal,PatrickLabatut,Arman...
work page internal anchor Pith review arXiv 2024
-
[54]
Malware Detection PE-Based Analysis Using Deep Learning Algorithm Dataset, June 2018
AnhPhamTuan,AnTranHungPhuong,NguyenVuThanh,andToan Nguyen Van. Malware Detection PE-Based Analysis Using Deep Learning Algorithm Dataset, June 2018. URLhttps://doi.org/10 .6084/m9.figshare.6635642
2018
-
[55]
AVClass, February 2023
Malicia Lab. AVClass, February 2023. URLhttps://github.com/mal icialab/avclass. original-date: 2016-07-01T16:57:31Z
2023
-
[56]
Chain-of- Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of- Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc., 2022. URLhttps: //proceedings.neurips.cc/paper_files/paper/2022...
2022
-
[57]
Chain-of-Verification Reduces Hallucination in Large Language Models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-Verification Reduces Hallucination in Large Language Models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 3563– 3578, Bangkok, Thailand, August 2024. ...
-
[58]
Daya Guo and et al Yang. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, September 2025. ISSN 1476-4687. doi: 10.1038/s41586-025-09422 -z. URLhttps://www.nature.com/articles/s41586-025-09422-z
-
[59]
Fenrir v2.0 — Cybersecurity Instruction-Tuning Dataset, October 2025
Alican Kiraz. Fenrir v2.0 — Cybersecurity Instruction-Tuning Dataset, October 2025. URLhttps://huggingface.co/datasets/ AlicanKiraz0/Cybersecurity-Dataset-Heimdall-v2.0
2025
-
[60]
Trendyol Cybersecurity Defense Instruction-Tuning Dataset v2.0, July 2025
Trendyol Security Team. Trendyol Cybersecurity Defense Instruction-Tuning Dataset v2.0, July 2025. URLh t t p s : //huggingface.co/datasets/Trendyol/Trendyol- Cybersecurity -Instruction-Tuning-Dataset
2025
-
[61]
CVEChat-StyleMulti-TurnCybersecurity Dataset (1999–2025), March 2026
ansulevandAlicanKiraz. CVEChat-StyleMulti-TurnCybersecurity Dataset (1999–2025), March 2026. URLhttps://huggingface.co/d atasets/ansulev/All-CVE-Chat-MultiTurn-1999-2025-Dataset. First Author et al.:Preprint submitted to ElsevierPage 20 of 23 LCC-LLM A. Advanced Testing Scenario Outputs This appendix provides the raw, unedited outputs gen- erated by the f...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.