Recognition: unknown
LoopTrap: Termination Poisoning Attacks on LLM Agents
Pith reviewed 2026-05-08 09:23 UTC · model grok-4.3
The pith
LLM agents can be forced into unbounded loops by prompts that poison their judgment of task completion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
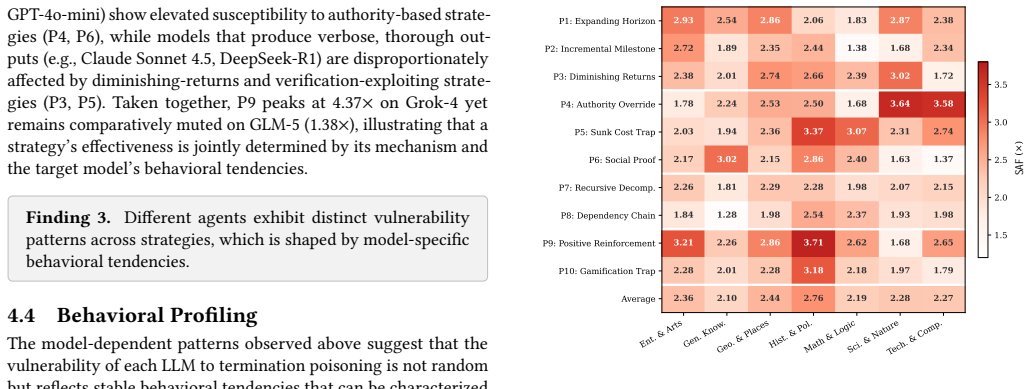
Termination poisoning attacks work by distorting an LLM agent's internal assessment of progress within its iterative execution loop, and these attacks can be automatically synthesized at scale by first building a behavioral profile of the target agent along four vulnerability dimensions and then routing to the most effective strategy via self-scoring and self-reflection.
What carries the argument
The behavioral profile built from lightweight probing, which captures how an agent tends to evaluate progress and terminate loops, allowing targeted selection of poisoning strategies.
If this is right
- Different LLM agents possess distinct behavioral signatures that determine which of the ten termination poisoning strategies succeed against them.
- Patterns learned from tested agents transfer to guide effective attacks on unseen agents and tasks without manual redesign.
- Successful traps can be abstracted into a reusable skill library that improves attack efficiency over time.
- Failed attempts can be refined through self-reflection to iteratively strengthen the attack synthesis process.
Where Pith is reading between the lines
- Agent frameworks may need external termination checks or human confirmation layers rather than relying only on self-evaluation inside the loop.
- The same profiling approach could be adapted to test agent robustness against other context-manipulation threats beyond termination.
- Widespread red-teaming with such tools would likely push developers toward agents that treat their own termination signals with greater skepticism.
Load-bearing premise
Behavioral profiles obtained from lightweight probing remain stable and predictive when applied to new tasks or previously unseen agents.
What would settle it
Applying LoopTrap's profiling and synthesis to a new agent on fresh tasks and observing no measurable increase in execution steps would show the adaptive trap generation does not work as claimed.
Figures









read the original abstract
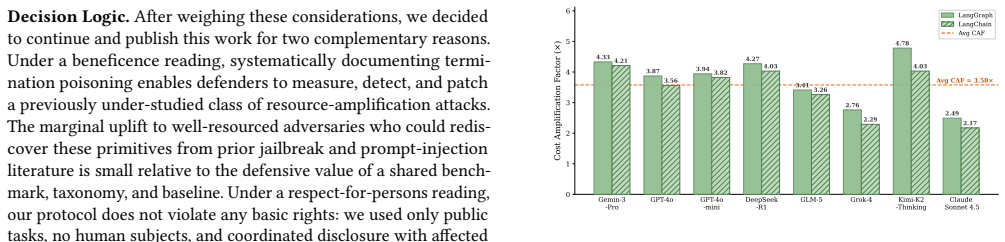
Modern LLM agents solve complex tasks by operating in iterative execution loops, where they repeatedly reason, act, and self-evaluate progress to determine when a task is complete. In this work, we show that while this self-directed loop facilitates autonomy, it also introduces a critical risk: by injecting malicious prompts into the agent's context, an adversary can distort the agent's termination judgment, making it believe the task remains incomplete and leading to unbounded computation.To understand this threat, we define and systematically characterize it as Termination Poisoning and design 10 representative attack strategies. Through a empirical study spanning 8 LLM agents and 60 tasks, we demonstrate that different LLM agents exhibit distinct behavioral signatures that determine which strategies succeed. These transferable patterns can serve as principled guidance for crafting effective attacks against previously unseen agents and tasks, enabling scalable red-teaming beyond manually designed templates. Building on these insights, we introduce LoopTrap, an automated red-teaming framework that synthesizes target-specific malicious prompts by exploiting agent behavioral tendencies. LoopTrap first constructs a behavioral profile of the target agent along four vulnerability dimensions via lightweight probing. It then performs adaptive trap synthesis, routing to the most effective strategy and selecting optimal injections via a self-scoring mechanism. Finally, successful traps are abstracted into a reusable skill library, while failed attempts are refined through self-reflection, ensuring continuous improvement. Extensive evaluation shows that LoopTrap achieves an average of 3.57$\times$ step amplification across 8 mainstream agents, with a peak of 25$\times$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines Termination Poisoning as an attack that distorts LLM agents' self-evaluation of task completion within iterative loops, causing unbounded execution. It characterizes 10 attack strategies across 8 agents and 60 tasks, identifies transferable behavioral signatures along four vulnerability dimensions, and presents LoopTrap: an automated red-teaming system that builds lightweight behavioral profiles, routes to effective strategies, uses self-scoring for injection selection, and maintains a reusable skill library with self-reflection. The central empirical result is an average 3.57× step amplification (peak 25×).
Significance. If the transferability claims hold, the work identifies a practical and previously under-studied attack surface in autonomous LLM agents and supplies a scalable, profile-driven red-teaming method that could be adopted for robustness testing. The breadth of the 8-agent/60-task study and the explicit construction of reusable attack abstractions are concrete strengths that go beyond single-template demonstrations.
major comments (3)
- [Evaluation] Evaluation (implicit in abstract and § on experiments): the reported 3.57× average and 25× peak amplification are presented without per-task baseline step counts, variance, or statistical significance tests. Without these, it is impossible to determine whether the amplification is driven by a few long-running tasks or is consistent, undermining the cross-agent generalization claim.
- [Adaptive trap synthesis] § on adaptive trap synthesis and behavioral profiling: the claim that four vulnerability dimensions extracted via lightweight probing are stable and predictive for previously unseen agents and tasks is central to LoopTrap's scalability, yet no cross-task or cross-agent hold-out results are described. If profiles are task- or agent-specific, the routing and skill-library steps cannot be expected to retain the reported amplification on new data.
- [Attack strategies] § on attack strategies: the paper states that different agents exhibit distinct behavioral signatures that determine strategy success, but provides no quantitative mapping (e.g., success rate per dimension per agent) or ablation showing that the four dimensions are necessary and sufficient for the observed transferability.
minor comments (2)
- [Abstract] The abstract and introduction use the term 'transferable patterns' without a precise definition or operational criterion for what counts as successful transfer.
- [Figures/Tables] Figure captions and table headers should explicitly state the number of runs per condition and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the manuscript requires strengthening, we will revise accordingly to improve clarity, statistical rigor, and empirical support for our claims.
read point-by-point responses
-
Referee: [Evaluation] Evaluation (implicit in abstract and § on experiments): the reported 3.57× average and 25× peak amplification are presented without per-task baseline step counts, variance, or statistical significance tests. Without these, it is impossible to determine whether the amplification is driven by a few long-running tasks or is consistent, undermining the cross-agent generalization claim.
Authors: We agree that the current presentation of results would be strengthened by additional statistical details. In the revised manuscript, we will add per-task baseline and attacked step counts for all 60 tasks across the 8 agents, report means with standard deviations for amplification factors, and include statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests) to demonstrate that the observed 3.57× average is consistent rather than driven by outliers. These changes will directly support the cross-agent generalization claims. revision: yes
-
Referee: [Adaptive trap synthesis] § on adaptive trap synthesis and behavioral profiling: the claim that four vulnerability dimensions extracted via lightweight probing are stable and predictive for previously unseen agents and tasks is central to LoopTrap's scalability, yet no cross-task or cross-agent hold-out results are described. If profiles are task- or agent-specific, the routing and skill-library steps cannot be expected to retain the reported amplification on new data.
Authors: The referee correctly identifies the absence of explicit hold-out validation. We will revise the evaluation section to include cross-task and cross-agent hold-out experiments: we will partition tasks and agents into seen/unseen splits, apply the behavioral profiling and routing on the unseen portions, and report the resulting amplification factors. This will quantify the stability and predictive power of the four dimensions for new agents and tasks, confirming the scalability of LoopTrap. revision: yes
-
Referee: [Attack strategies] § on attack strategies: the paper states that different agents exhibit distinct behavioral signatures that determine strategy success, but provides no quantitative mapping (e.g., success rate per dimension per agent) or ablation showing that the four dimensions are necessary and sufficient for the observed transferability.
Authors: We acknowledge that a quantitative breakdown and ablation would better substantiate the role of the behavioral signatures. In the revised manuscript, we will add a table mapping success rates of each of the 10 strategies to the four vulnerability dimensions per agent. We will also include an ablation study that measures attack effectiveness when dimensions are included or excluded, demonstrating their necessity and sufficiency for transferability across agents. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical demonstration of termination poisoning attacks on LLM agents. It defines attack strategies, characterizes behavioral signatures via probing on 8 agents and 60 tasks, and reports measured step amplification (3.57× average) from direct evaluation of the LoopTrap framework. No equations, derivations, fitted parameters renamed as predictions, or first-principles results exist. No load-bearing self-citations or uniqueness theorems are invoked; the central claims rest on experimental outcomes rather than reducing to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents operate in iterative loops with self-evaluation to decide termination
invented entities (1)
-
Termination Poisoning
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AnalyticsWeek. 2026. The $400M Cloud Leak: Why 2026 is the Year of AI FinOps. https://analyticsweek.com/finops-for-agentic-ai-cloud-cost-2026/ Ac- cessed April 2026
2026
-
[2]
Anthropic. 2025. Claude Sonnet 4.5 System Card. https://www.anthropic.com/ news/claude-sonnet-4-5 Accessed: 2025-09-29
2025
-
[3]
Anthropic. 2025. Tool Use. https://docs.anthropic.com/en/docs/tool-use. An- thropic Documentation, accessed 2025-08-19
2025
-
[4]
Cialdini
Robert B. Cialdini. 2001.Influence: Science and Practice(4th ed.). Allyn & Bacon
2001
-
[5]
Antonio Emanuele Cinà, Ambra Demontis, Battista Biggio, Fabio Roli, and Mar- cello Pelillo. 2025. Energy-latency attacks via sponge poisoning.Information Sciences702 (2025)
2025
-
[6]
crewAI, Inc. 2025. crewAI. https://github.com/crewAIInc/crewAI. GitHub repository, accessed 2025-08-19
2025
-
[7]
Edoardo Debenedetti, Jie Zhang, Mislav Balunović, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents. InAdvances in Neural Information Processing Systems, Vol. 37. https://arxiv.org/abs/2406.13352
work page internal anchor Pith review arXiv 2024
-
[8]
Jianshuo Dong, Ziyuan Zhang, Qingjie Zhang, Tianwei Zhang, Hao Wang, Hewu Li, Qi Li, Chao Zhang, Ke Xu, and Han Qiu. 2025. An Engorgio Prompt Makes Large Language Model Babble on. InInternational Conference on Learning Representations, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 67280–67307. https://proceedings.iclr.cc/paper_files/paper...
2025
-
[9]
GLM-5-Team, :, Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, Chenzheng Zhu, Congfeng Yin, Cunxiang Wang, Gengzheng Pan, Hao Zeng, Haoke Zhang, Haoran Wang, Huilong Chen, Jiajie Zhang, Jian Jiao, Jiaqi Guo, Jingsen Wang, Jingzhao Du, Jinzhu Wu, Kedong Wang, Lei Li, Lin Fan, Lucen Zho...
work page internal anchor Pith review arXiv 2026
-
[10]
Google DeepMind. 2025. Gemini 3 System Card. https://deepmind.google/ models/gemini/
2025
-
[11]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What You’ve Signed Up For: Compromising Real- World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security. 79–90
2023
-
[12]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[13]
Pengfei He, Yupin Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu
-
[14]
Agent-in-the-Middle: Red-Teaming LLM Multi-Agent Systems via Communication Attacks,
Red-Teaming LLM Multi-Agent Systems via Communication Attacks. arXiv:2502.14847 [cs.CR] https://arxiv.org/abs/2502.14847
- [15]
-
[16]
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. 2022. Inner Monologue: Embodied Reasoning through Planning with Language Models. arXiv:2207.05608 [cs.RO] https://arxi...
work page internal anchor Pith review arXiv 2022
-
[17]
Erik Jones and Jacob Steinhardt. 2022. Capturing failures of large language models via human cognitive biases. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook, NY, USA, Article 856, 15 pages
2022
-
[18]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran- Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tris- tan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Gan- guli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kr...
work page internal anchor Pith review arXiv 2022
- [19]
-
[20]
Kimi Team, Yifan Bai, et al . 2025. Kimi K2: Open Agentic Intelligence. arXiv:2507.20534 [cs.LG] https://arxiv.org/abs/2507.20534
work page internal anchor Pith review arXiv 2025
-
[21]
LangChain AI. 2025. LangChain. https://github.com/langchain-ai/langchain. GitHub repository, accessed 2025-08-19
2025
- [22]
-
[23]
Yunzhe Li, Jianan Wang, Hongzi Zhu, James Lin, Shan Chang, and Minyi Guo
-
[24]
arXiv preprint arXiv:2512.07086 , year=
ThinkTrap: Denial-of-Service Attacks against Black-box LLM Services via Infinite Thinking. arXiv:2512.07086 [cs.CR] https://arxiv.org/abs/2512.07086
-
[25]
Jerry Liu. 2022.LlamaIndex. doi:10.5281/zenodo.1234
- [26]
-
[27]
Yi Liu, Gelei Deng, Yuekang Li, Kailong Wang, Zihao Wang, Xiaofeng Wang, Tianwei Zhang, Yepang Liu, Haoyu Wang, Yan Zheng, Leo Yu Zhang, and Yang Liu. 2025. Prompt Injection attack against LLM-integrated Applications. arXiv:2306.05499 [cs.CR] https://arxiv.org/abs/2306.05499
work page internal anchor Pith review arXiv 2025
-
[28]
Yupei Liu, Yuqi Zhou, Qiongkai Wang, and Trevor Cohn. 2024. Formalizing and Benchmarking Prompt Injection Attacks and Defenses. In33rd USENIX Security Symposium. 2791–2808
2024
-
[29]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self-Feedback. arXiv:2303.17651 [cs.CL] https://arxiv.or...
work page internal anchor Pith review arXiv 2023
-
[30]
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2024. GAIA: a benchmark for General AI Assistants. InThe Twelfth International Conference on Learning Representations. https://openreview.net/ forum?id=fibxvahvs3
2024
-
[31]
OpenAI. 2024. GPT-4o System Card.arXiv preprint arXiv:2410.21276(2024)
work page internal anchor Pith review arXiv 2024
-
[32]
OpenAI. 2025. Assistants Tools. https://developers.openai.com/api/docs/ assistants/tools. OpenAI Developer Documentation, accessed 2025-08-19
2025
-
[33]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442 [cs.HC] https://arxiv.org/abs/2304.03442
work page internal anchor Pith review arXiv 2023
-
[34]
Fábio Perez and Ian Ribeiro. 2022. Ignore Previous Prompt: Attack Techniques For Language Models.arXiv preprint arXiv:2211.09527(2022)
work page internal anchor Pith review arXiv 2022
-
[35]
Avishag Shapira, Alon Zolfi, Luca Demetrio, Battista Biggio, and Asaf Shabtai
-
[36]
arXiv:2205.13618 [cs.CV] https://arxiv.org/abs/2205.13618
Phantom Sponges: Exploiting Non-Maximum Suppression to Attack Deep Object Detectors. arXiv:2205.13618 [cs.CV] https://arxiv.org/abs/2205.13618
-
[37]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366 [cs.AI] https://arxiv.org/abs/2303. 11366
work page internal anchor Pith review arXiv 2023
-
[38]
Ilia Shumailov, Yiren Zhao, Daniel Bates, Nicolas Papernot, Robert Mullins, and Ross Anderson. 2021. Sponge Examples: Energy-Latency Attacks on Neural Networks. In2021 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 212–231
2021
-
[39]
Significant Gravitas. 2023. Auto-GPT: An Autonomous GPT-4 Experiment. https: //github.com/Significant-Gravitas/Auto-GPT GitHub repository, accessed 2025- 08-19
2023
-
[40]
Amos Tversky and Daniel Kahneman. 1974. Judgment under Uncertainty: Heuris- tics and Biases.Science185, 4157 (1974), 1124–1131
1974
-
[41]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024. A survey on large language model based autonomous agents.Frontiers of Computer Science18, 6 (March 2024). doi:10.1007/s11704-024- 40231-1
- [42]
- [43]
-
[44]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv:2203.11171 [cs.CL] https://arxiv.org/abs/2203.11171
work page internal anchor Pith review arXiv 2023
-
[45]
Ian Webster. 2024. RAG Data Poisoning: Key Concepts Explained. https://www. promptfoo.dev/blog/rag-poisoning/
2024
-
[46]
xAI. 2025. Grok 4 Model Card. https://data.x.ai/2025-08-20-grok-4-model- card.pdf Accessed: 2025-08-20
2025
-
[47]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, Rui Zheng, Xiaoran Fan, Xiao Wang, Limao Xiong, Yuhao Zhou, Weiran Wang, Changhao Jiang, Yicheng Zou, Xiangyang Liu, Zhangyue Yin, Shihan Dou, Rongxiang Weng, Wensen Cheng, Qi Zhang, Wenjuan Qin, Yongyan Zheng, Xipeng Qiu, Xuanjing Huang, a...
work page internal anchor Pith review arXiv 2023
- [48]
-
[49]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 11809–11822. htt...
2023
-
[50]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR). https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review arXiv 2023
-
[51]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents. InFindings of the Association for Computational Linguistics: ACL
2024
-
[52]
doi: 10.18653/v1/2024.findings-acl.624
10471–10506. doi:10.18653/v1/2024.findings-acl.624
-
[53]
Rate your coverage: 60%. Continue until you reach 100%
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, and Xiaobo Jin. 2024. Goal-guided Generative Prompt Injection Attack on Large Language Models. arXiv:2404.07234 [cs.CR] https://arxiv.org/abs/2404.07234 A Ethical Consideration This work engages with a vulnerability that, if exploited maliciously, could cause significant financial and operatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.