Recognition: unknown
LLM-Driven Design Space Exploration of FPGA-based Accelerators
Pith reviewed 2026-05-08 04:31 UTC · model grok-4.3
The pith
SECDA-DSE integrates large language models to automate design space exploration for FPGA-based AI accelerators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
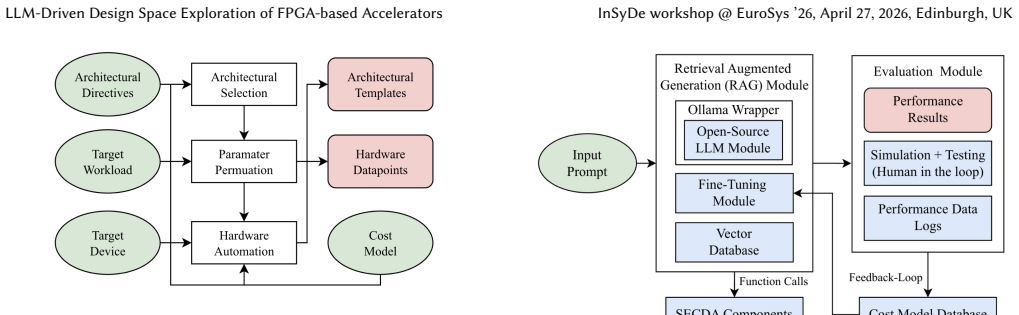
SECDA-DSE combines a DSE Explorer for producing candidate accelerator configurations with an LLM Stack that performs reasoning-guided exploration via retrieval-augmented generation and chain-of-thought prompting, together with a feedback loop for reinforced fine-tuning, and shows that the resulting designs can pass high-level synthesis timing and resource checks on a Zynq-7000 FPGA.
What carries the argument
The LLM Stack that performs reasoning-guided exploration using retrieval-augmented generation and chain-of-thought prompting to propose and refine accelerator configurations.
If this is right
- Design of FPGA accelerators for AI workloads requires substantially less repeated manual iteration and expert intervention.
- A feedback loop allows the exploration process to improve over successive runs without restarting from scratch.
- Valid configurations can be produced that already satisfy synthesis constraints before full implementation.
- The same LLM-driven loop can be applied inside existing hardware-software co-design environments such as SECDA.
Where Pith is reading between the lines
- The approach could be retargeted to other reconfigurable or fixed-function hardware platforms where similar large parameter spaces exist.
- LLMs might surface accelerator organizations that standard heuristic or exhaustive searches overlook because they encode patterns from training data.
- Lowering the expertise barrier could let more software teams prototype custom accelerators for edge or embedded AI without hiring hardware specialists.
Load-bearing premise
The LLM Stack can reliably generate valid and useful accelerator configurations that meaningfully reduce manual effort and domain expertise.
What would settle it
A test in which the large majority of LLM-generated configurations fail to meet timing or resource constraints when run through high-level synthesis on the target FPGA would show the automation does not yet deliver usable designs.
Figures


read the original abstract
Designing field-programmable gate array (FPGA)-based accelerators for modern artificial intelligence workloads requires navigating a large and complex hardware design space encompassing architectural parameters, dataflow strategies, and memory hierarchies, making the process time-consuming and resource-intensive. While the SECDA methodology enables rapid hardware-software co-design of accelerators through SystemC simulation and FPGA execution, identifying optimal accelerator configurations still requires substantial manual effort and domain expertise. This work presents SECDA-DSE, a framework that integrates Large Language Models (LLMs) into the SECDA ecosystem, comprising tools built around SECDA to automate the design space exploration (DSE) of FPGA-based accelerators. SECDA-DSE combines a structured DSE Explorer for generating accelerator configurations with an LLM Stack that performs reasoning-guided exploration using retrieval-augmented generation and chain-of-thought prompting, alongside a feedback loop that enables reinforced fine-tuning for continuous improvement. We demonstrate the feasibility of SECDA-DSE through an initial high-level synthesis based evaluation of a generated accelerator design that meets synthesis timing and resource constraints on an Zynq-7000 FPGA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SECDA-DSE, a framework extending the SECDA methodology by integrating Large Language Models (LLMs) to automate design space exploration (DSE) for FPGA-based accelerators targeting AI workloads. It comprises a structured DSE Explorer for configuration generation, an LLM Stack employing retrieval-augmented generation and chain-of-thought prompting for reasoning-guided search, and a feedback loop for reinforced fine-tuning. Feasibility is demonstrated through a single high-level synthesis (HLS) evaluation of one LLM-generated accelerator design that satisfies timing and resource constraints on a Zynq-7000 FPGA.
Significance. If the LLM-based components can be shown to consistently produce high-quality, workload-correct accelerator configurations with substantially less manual intervention than traditional methods, the work could meaningfully advance automated hardware-software co-design flows for FPGAs. The extension of the established SECDA ecosystem with modern LLM techniques is a timely idea, though the current evidence base is limited to an initial, single-instance synthesis success without supporting metrics or baselines.
major comments (2)
- Abstract: The central feasibility claim rests on a single initial HLS evaluation of one generated design that meets basic timing and resource constraints. No quantitative metrics (e.g., achieved performance, resource utilization beyond constraint satisfaction, or design-space coverage), multiple tested configurations, success/failure rates across iterations, or comparisons against manual DSE or non-LLM baselines are reported. This single data point is insufficient to substantiate the claim that the LLM Stack with RAG/CoT reliably generates valid and useful accelerator configurations that reduce manual effort.
- Framework description (LLM Stack and feedback loop): The manuscript describes the use of RAG and chain-of-thought prompting together with a feedback loop for reinforced fine-tuning, yet provides no concrete details on prompt templates, retrieved knowledge base contents, how feedback is converted into training signals, or any ablation showing the contribution of these LLM techniques versus simpler generation methods. Without such specifics, it is difficult to evaluate whether the approach is load-bearing for the reported outcome or merely incidental to the single successful synthesis.
minor comments (2)
- Abstract: The construction 'an Zynq-7000 FPGA' is grammatically incorrect and should read 'a Zynq-7000 FPGA'.
- Abstract and introduction: The abstract states that SECDA-DSE 'comprises tools built around SECDA' but does not enumerate or reference the specific tools, their interfaces, or how they interact with the LLM Stack; this omission reduces clarity for readers unfamiliar with the prior SECDA codebase.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We acknowledge the preliminary nature of the evaluation and will revise the paper to provide greater detail on the LLM components while clarifying the scope of our feasibility claims.
read point-by-point responses
-
Referee: Abstract: The central feasibility claim rests on a single initial HLS evaluation of one generated design that meets basic timing and resource constraints. No quantitative metrics (e.g., achieved performance, resource utilization beyond constraint satisfaction, or design-space coverage), multiple tested configurations, success/failure rates across iterations, or comparisons against manual DSE or non-LLM baselines are reported. This single data point is insufficient to substantiate the claim that the LLM Stack with RAG/CoT reliably generates valid and useful accelerator configurations that reduce manual effort.
Authors: We appreciate the referee's point. The manuscript presents the single successful HLS synthesis explicitly as an initial feasibility demonstration of the SECDA-DSE framework rather than evidence of reliability, consistency, or broad reduction in manual effort. To address the concern, we will revise the abstract and results section to qualify the claims more precisely as a proof-of-concept, include the concrete resource utilization figures and timing results from the synthesis report, and add a discussion of how the framework is intended to lower manual intervention. We do not have additional configurations or baselines in the current work, so we will also outline planned future comparative evaluations. revision: partial
-
Referee: Framework description (LLM Stack and feedback loop): The manuscript describes the use of RAG and chain-of-thought prompting together with a feedback loop for reinforced fine-tuning, yet provides no concrete details on prompt templates, retrieved knowledge base contents, how feedback is converted into training signals, or any ablation showing the contribution of these LLM techniques versus simpler generation methods. Without such specifics, it is difficult to evaluate whether the approach is load-bearing for the reported outcome or merely incidental to the single successful synthesis.
Authors: We agree that additional implementation details are required. In the revised manuscript we will add an appendix containing the prompt templates, a description of the RAG knowledge base contents (SECDA methodology documents, HLS guidelines, and AI accelerator design patterns), and a step-by-step explanation of the feedback loop including how successful designs generate signals for reinforced fine-tuning. We will also include a qualitative discussion of the contribution of RAG and CoT to the generated design. Full quantitative ablations are beyond the scope of this initial feasibility study and will be noted as future work. revision: yes
Circularity Check
Minor self-citation to prior SECDA methodology; central feasibility claim remains independent
full rationale
The paper presents SECDA-DSE as an extension that adds an LLM Stack (RAG + CoT prompting + feedback loop) to the existing SECDA ecosystem for automating DSE. The abstract and framework description reference the prior SECDA methodology for rapid co-design via SystemC simulation and FPGA execution, but this is background context rather than a load-bearing premise that reduces the new claim to a self-referential definition or fitted input. The strongest claim is an initial HLS-based check that one LLM-generated design meets timing and resource constraints on Zynq-7000; this is a direct empirical demonstration and does not collapse by construction to any parameter fit or prior result within the paper. No equations, uniqueness theorems, or ansatzes are invoked that would create circularity. The single-example validation is statistically limited but does not constitute circular reasoning.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can perform effective reasoning-guided exploration of hardware design spaces using retrieval-augmented generation and chain-of-thought prompting
Reference graph
Works this paper leans on
-
[1]
Andrew Boutros, Aman Arora, and Vaughn Betz. 2025. Field- Programmable Gate Array Architecture for Deep Learning: Survey and Future Directions.Proc. IEEE(2025)
2025
-
[2]
2025.Rapid Prototyping of Edge AI Accelerators: An HLS-based Approach for CNNs on FPGAs for the AIdge ML Deployment Framework
Jacopo Cesaretti. 2025.Rapid Prototyping of Edge AI Accelerators: An HLS-based Approach for CNNs on FPGAs for the AIdge ML Deployment Framework. Ph. D. Dissertation. Politecnico di Torino
2025
-
[3]
Pudi Dhilleswararao, Srinivas Boppu, M Sabarimalai Manikandan, and Linga Reddy Cenkeramaddi. 2022. Efficient hardware architectures for accelerating deep neural networks: Survey.IEEE access10 (2022), 131788–131828
2022
-
[4]
Perry Gibson, Jose Cano, Elliot Crowley, Amos Storkey, and Michael O’boyle. 2025. DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration.ACM Trans. Archit. Code Optim.(2025)
2025
-
[5]
Jude Haris, Perry Gibson, José Cano, Nicolas Bohm Agostini, and David Kaeli. 2021. SECDA: Efficient hardware/software co-design of FPGA-based DNN accelerators for edge inference. In2021 IEEE 33rd In- ternational Symposium on Computer Architecture and High Performance Computing (SBAC-PAD). IEEE, 33–43
2021
-
[6]
Jude Haris, Perry Gibson, José Cano, Nicolas Bohm Agostini, and David Kaeli. 2023. SECDA-TFLite: A toolkit for efficient development of FPGA-based DNN accelerators for edge inference.J. Parallel and Distrib. Comput.173 (2023), 140–151
2023
-
[7]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
- [8]
-
[9]
Chen Ling, Xujiang Zhao, Jiaying Lu, Chengyuan Deng, Can Zheng, Junxiang Wang, Tanmoy Chowdhury, Yun Li, Hejie Cui, Xuchao Zhang, et al. 2025. Domain specialization as the key to make large language models disruptive: A comprehensive survey.Comput. Surveys58, 3 (2025), 1–39
2025
-
[10]
Ollama. 2024. Ollama.https://ollama.com. Software for running LLMs locally
2024
-
[11]
Gaurav Tiwari, Sangeeta Nakhate, Alok Pathak, Abhinandan Jain, and Shardul Penurkar. 2025. Hardware accelerators for deep learning ap- plications. In2025 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS). IEEE, 1–10
2025
- [12]
-
[13]
Xilinx, Inc. 2019. Vivado High-Level Synthesis
2019
-
[14]
Tao Zhang, Rui Ma, Shuotao Xu, Peng Cheng, and Yongqiang Xiong
-
[15]
arXiv:2603.05904 [cs.AR]https://arxiv.org/abs/2603
LUMINA: LLM-Guided GPU Architecture Exploration via Bot- tleneck Analysis. arXiv:2603.05904 [cs.AR]https://arxiv.org/abs/2603. 05904
-
[16]
Tianshi Zheng, Zheye Deng, Hong Ting Tsang, Weiqi Wang, Jiaxin Bai, Zihao Wang, and Yangqiu Song. 2025. From automation to au- tonomy: A survey on large language models in scientific discovery. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 17744–17761. Appendix The following is the initial prompt provided to the...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.