Recognition: unknown
BioResearcher: Scenario-Guided Multi-Agent for Translational Medicine
Pith reviewed 2026-05-08 10:42 UTC · model grok-4.3
The pith
BioResearcher maps biomedical queries to versioned playbooks and specialized subagents to produce auditable evidence syntheses from literature, trials, and omics data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
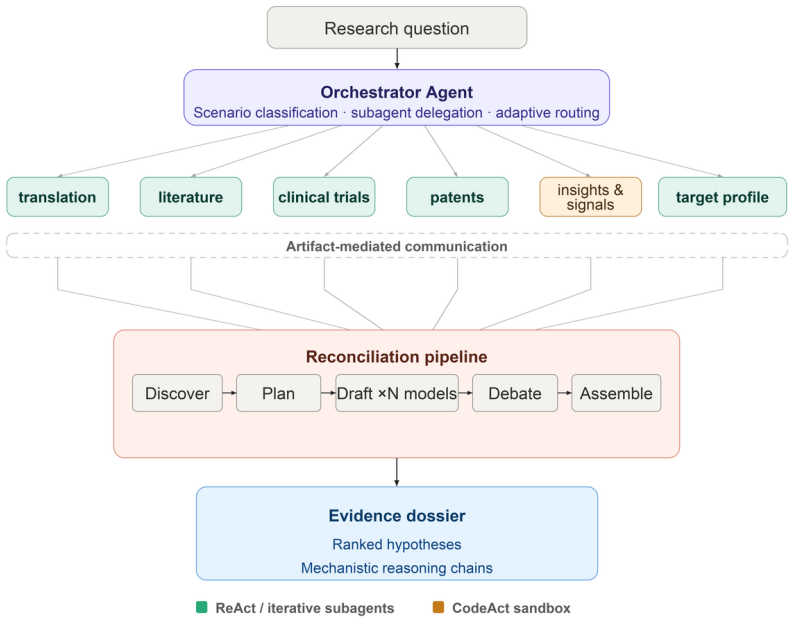
BioResearcher is a scenario-guided multi-agent system that maps queries to versioned research playbooks, delegates to specialized subagents over 30+ tools and machine-learning endpoints, mixes structured database access with sandboxed code for genome-scale analyses, and applies claim-level multi-model reconciliation before editorial assembly. This architecture is presented as the mechanism that enables reliable, auditable performance on the combination of literature, trials, patents, and quantitative multi-omics analysis required in translational medicine.
What carries the argument
The scenario-guided multi-agent architecture that maps queries to versioned research playbooks and coordinates subagents with structured tools and claim reconciliation.
If this is right
- The system outperforms evaluated baselines on single-step biomedical capability tests.
- It reaches leading performance on open-ended biomedical reasoning benchmarks.
- It achieves the highest positive hit rate and negative clear rate on a 30-query clinical end-to-end discovery benchmark.
- The combination of playbook guidance and multi-model reconciliation produces more consistent results across unit-level, open-ended, and end-to-end tasks than general-purpose alternatives.
Where Pith is reading between the lines
- The playbook and subagent structure could transfer to other domains that require traceable synthesis of heterogeneous evidence, such as regulatory science or materials discovery.
- Explicit versioning of playbooks offers a route to audit trails that might support regulatory review of AI-assisted research outputs.
- The reliance on sandboxed code execution for omics analyses suggests the design could scale to larger genome-scale or multi-omics integration problems if the underlying tools improve.
Load-bearing premise
The chosen benchmarks accurately reflect the full complexity, uncertainty handling, and provenance requirements of real translational medicine workflows.
What would settle it
A controlled test set of queries that deliberately include conflicting trial data or missing provenance details, checked to see whether BioResearcher outputs still preserve identifiers, uncertainty flags, and traceable sources.
Figures







read the original abstract
Translational medicine turns underspecified development goals into evidence synthesis that must combine literature, trials, patents, and quantitative multi-omics analysis while preserving identifiers, uncertainty, and retrievable provenance. General-purpose foundation models and off-the-shelf tool-augmented or multi-agent systems are not built for this: they tend to produce single-shot answers or run open-endedly, and fall short on the auditable, scenario-specific workflows that heterogeneous biomedical sources demand. This paper introduces Ingenix BioResearcher, a scenario-guided multi-agent system that maps queries to versioned research playbooks, delegates to specialized subagents over 30+ tools and machine-learning endpoints, mixes structured database access with sandboxed code for genome-scale analyses, and applies claim-level multi-model reconciliation before editorial assembly. We evaluate BioResearcher across unit-level capabilities, open-ended biomedical reasoning, and end-to-end clinical discovery. It leads evaluated baselines on 109 single-step tests (83.49% pass rate; 0.892 average score), achieves strong biomedical benchmark performance (89.33% on BixBench-Verified-50 and the top 0.758 mean score on BaisBench Scientific Discovery), and leads on a 30-query clinical end-to-end benchmark with the highest positive hit rate (74.7% $\pm$ 3.3%) and negative clear rate (96.8% $\pm$ 0.2%). These results show broad, competitive performance across unit-level, open-ended, and end-to-end clinical evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BioResearcher, a scenario-guided multi-agent system for translational medicine that maps queries to versioned research playbooks, delegates to specialized subagents over 30+ tools and ML endpoints, combines structured database access with sandboxed code for multi-omics analyses, and applies claim-level multi-model reconciliation. It reports leading performance on 109 single-step tests (83.49% pass rate, 0.892 average score), 89.33% on BixBench-Verified-50, top mean score of 0.758 on BaisBench Scientific Discovery, and leadership on a 30-query clinical end-to-end benchmark (74.7% ±3.3% positive hit rate, 96.8% ±0.2% negative clear rate).
Significance. If the benchmarks are representative and the results reproducible, the work shows that structured multi-agent orchestration with playbooks and provenance tracking can address gaps in general-purpose LLMs for auditable, multi-source biomedical workflows. This could inform design of domain-specific agents in medicine. The significance is reduced by the absence of benchmark construction details, which prevents assessing whether gains reflect general capability or test-specific engineering.
major comments (3)
- [Abstract and Evaluation] Abstract and Evaluation section: The central claim that BioResearcher leads on the 30-query clinical end-to-end benchmark (74.7% positive hit rate) rests on an unreleased test set; the manuscript provides no query selection criteria, ground-truth annotations, or exact rubric for 'positive hit' versus 'negative clear' scoring, preventing independent verification or checks for overfitting.
- [Evaluation] Evaluation section: No details are given on benchmark construction for BixBench-Verified-50, BaisBench, or the 109 single-step tests, including potential data leakage from training corpora, post-hoc tuning of agents or prompts, or how uncertainty and provenance requirements were operationalized in scoring; these omissions are load-bearing for the performance superiority claims.
- [Abstract] Abstract: The assertion that the system handles 'real translational-medicine requirements (auditable provenance, uncertainty, multi-omics synthesis)' is not supported by evidence that the 30-query benchmark captures the full complexity, heterogeneity, or failure modes of actual clinical discovery workflows.
minor comments (2)
- [Abstract] The abstract and evaluation paragraphs report aggregate scores without error bars or statistical significance tests against baselines, which would strengthen the comparison claims.
- [System Description] Notation for agent roles and playbook versioning is introduced without a dedicated diagram or table summarizing the 30+ tools and their interfaces.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough review and valuable suggestions for improving the clarity and reproducibility of our work. We have carefully considered each major comment and will make corresponding revisions to the manuscript. Our point-by-point responses are provided below.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: The central claim that BioResearcher leads on the 30-query clinical end-to-end benchmark (74.7% positive hit rate) rests on an unreleased test set; the manuscript provides no query selection criteria, ground-truth annotations, or exact rubric for 'positive hit' versus 'negative clear' scoring, preventing independent verification or checks for overfitting.
Authors: We agree that the current manuscript lacks sufficient details on the 30-query benchmark to allow independent verification. In the revision, we will add comprehensive information on the query selection criteria, the process for obtaining ground-truth annotations, and the exact rubric used for distinguishing 'positive hit' from 'negative clear' scores. We will also release the benchmark dataset publicly to support reproducibility and checks for overfitting. revision: yes
-
Referee: [Evaluation] Evaluation section: No details are given on benchmark construction for BixBench-Verified-50, BaisBench, or the 109 single-step tests, including potential data leakage from training corpora, post-hoc tuning of agents or prompts, or how uncertainty and provenance requirements were operationalized in scoring; these omissions are load-bearing for the performance superiority claims.
Authors: We concur with the need for more transparency on benchmark construction. The revised Evaluation section will include details on how BixBench-Verified-50, BaisBench, and the 109 single-step tests were constructed or selected, including any measures taken to mitigate data leakage from training corpora, confirmation regarding the absence of post-hoc tuning of agents or prompts, and how the scoring accounted for uncertainty and provenance requirements. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the system handles 'real translational-medicine requirements (auditable provenance, uncertainty, multi-omics synthesis)' is not supported by evidence that the 30-query benchmark captures the full complexity, heterogeneity, or failure modes of actual clinical discovery workflows.
Authors: We recognize that the 30-query benchmark may not fully capture the entire complexity of clinical workflows. We will modify the abstract to qualify the claim, stating that the system addresses key aspects of these requirements as demonstrated in the benchmark. We will further elaborate in the discussion on the benchmark's scope and limitations. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external benchmarks, not internal derivations or self-referential definitions.
full rationale
The paper describes an engineering system (scenario-guided multi-agent with tools and playbooks) and reports empirical results on separate benchmarks (109 unit tests, BixBench, BaisBench, 30-query clinical set). No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text. All performance numbers are presented as measured outcomes against external test sets rather than being constructed from the system's own definitions or prior author results. The evaluation sections treat benchmarks as independent oracles, satisfying the self-contained criterion for a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ludovico Mitchener, Jon M. Laurent, Alex Andonian, Benjamin Tenmann, Siddharth Narayanan, Geemi P. Wellawatte, Andrew White, Lorenzo Sani, and Samuel G. Rodriques. BixBench: a Comprehensive Benchmark for LLM-based Agents in Computational Biology, October 2025. arXiv:2503.00096 [q-bio]
-
[2]
Benchmarking AI scientists for omics data driven biological discovery, January 2026
Erpai Luo, Jinmeng Jia, Yifan Xiong, Xiangyu Li, Xiaobo Guo, Baoqi Yu, Minsheng Hao, Lei Wei, and Xuegong Zhang. Benchmarking AI scientists for omics data driven biological discovery, January 2026. arXiv:2505.08341 [cs]
-
[3]
NCBI GEO: archive for gene expression and epigenomics data sets: 23-year update
Emily Clough, Tanya Barrett, Stephen E Wilhite, Pierre Ledoux, Carlos Evangelista, Irene F Kim, Maxim Tomashevsky, Kimberly A Marshall, Katherine H Phillippy, Patti M Sherman, et al. NCBI GEO: archive for gene expression and epigenomics data sets: 23-year update. Nucleic Acids Research, 52(D1):D138–D144, 2024
2024
-
[4]
DeepEval: The open-source LLM evaluation framework
Confident AI. DeepEval: The open-source LLM evaluation framework. https://github. com/confident-ai/deepeval, 2024. Accessed 2026
2024
-
[5]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, December 2023
2023
-
[6]
Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D
Andres M. Bran, Sam Cox, Oliver Schilter, Carlo Baldassari, Andrew D. White, and Philippe Schwaller. Augmenting large language models with chemistry tools.Nature Machine Intelli- gence, 6(5):525–535, May 2024
2024
-
[7]
RetroInText: A Multimodal Large Language Model Enhanced Framework for Retrosynthetic Planning via In-Context Representation Learning
Chenglong Kang, Xiaoyi Liu, and Fei Guo. RetroInText: A Multimodal Large Language Model Enhanced Framework for Retrosynthetic Planning via In-Context Representation Learning. October 2024
2024
-
[8]
Baker, Ian A Watson, and Xia Ning
Reza Averly, Frazier N. Baker, Ian A Watson, and Xia Ning. LIDDIA: Language-based Intelligent Drug Discovery Agent. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12004–12028, Suzhou, China, November
2025
-
[9]
Association for Computational Linguistics
-
[10]
Ghamary, Laura Vinué, Brahm J
Martin Pacesa, Lennart Nickel, Christian Schellhaas, Joseph Schmidt, Ekaterina Pyatova, Lucas Kissling, Patrick Barendse, Jagrity Choudhury, Srajan Kapoor, Ana Alcaraz-Serna, Yehlin Cho, Kourosh H. Ghamary, Laura Vinué, Brahm J. Yachnin, Andrew M. Wollacott, Stephen Buckley, Adrie H. Westphal, Simon Lindhoud, Sandrine Georgeon, Casper A. Goverde, Georgios...
2025
-
[11]
Advancing Protein Design via Multi-Agent Reinforcement Learning with Pareto-Based Collaborative Optimization, January 2026
Mingming Zhu, Jiahua Rao, Xiaoyu Chen, Qianmu Yuan, and Yuedong Yang. Advancing Protein Design via Multi-Agent Reinforcement Learning with Pareto-Based Collaborative Optimization, January 2026. ISSN: 2692-8205 Pages: 2026.01.13.699365 Section: New Results
2026
-
[12]
Gordon, Michael J
Manvitha Ponnapati, Sam Cox, Cade W. Gordon, Michael J. Hammerling, Siddharth Narayanan, Jon M. Laurent, James D. Braza, Michaela M. Hinks, Michael D. Skarlinski, Samuel G. Rodriques, and Andrew White. ProteinCrow: A Language Model Agent That Can Design Proteins. July 2025
2025
-
[13]
Roohani, Andrew H
Yusuf H. Roohani, Andrew H. Lee, Qian Huang, Jian V ora, Zachary Steinhart, Kexin Huang, Alexander Marson, Percy Liang, and Jure Leskovec. BioDiscoveryAgent: An AI Agent for Designing Genetic Perturbation Experiments. October 2024
2024
-
[14]
ProtAgents: Protein discovery via large language model multi-agent collaborations combining physics and machine learning
Alireza Ghafarollahi and Markus Buehler. ProtAgents: Protein discovery via large language model multi-agent collaborations combining physics and machine learning. March 2024. 6
2024
-
[15]
A generative AI-discovered TNIK inhibitor for idiopathic pulmonary fibrosis: a randomized phase 2a trial
Zuojun Xu, Feng Ren, Ping Wang, Jie Cao, Chunting Tan, Dedong Ma, Li Zhao, Jinghong Dai, Yipeng Ding, Haohui Fang, Huiping Li, Hong Liu, Fengming Luo, Ying Meng, Pinhua Pan, Pingchao Xiang, Zuke Xiao, Sujata Rao, Carol Satler, Sang Liu, Yuan Lv, Heng Zhao, Shan Chen, Hui Cui, Mikhail Korzinkin, David Gennert, and Alex Zhavoronkov. A generative AI-discover...
2025
-
[16]
TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools, March 2025
Shanghua Gao, Richard Zhu, Zhenglun Kong, Ayush Noori, Xiaorui Su, Curtis Ginder, Theodoros Tsiligkaridis, and Marinka Zitnik. TxAgent: An AI Agent for Therapeutic Reasoning Across a Universe of Tools, March 2025
2025
-
[17]
MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making
Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik Siu Chan, Xuhai Xu, Daniel McDuff, Hyeon- hoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae Won Park. MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making. November 2024
2024
-
[18]
Dyke Ferber, Omar S. M. El Nahhas, Georg Wölflein, Isabella C. Wiest, Jan Clusmann, Marie-Elisabeth Leßmann, Sebastian Foersch, Jacqueline Lammert, Maximilian Tschochohei, Dirk Jäger, Manuel Salto-Tellez, Nikolaus Schultz, Daniel Truhn, and Jakob Nikolas Kather. Development and validation of an autonomous artificial intelligence agent for clinical decisio...
2025
-
[19]
Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, and Zhiyong Lu
Qiao Jin, Zifeng Wang, Charalampos S. Floudas, Fangyuan Chen, Changlin Gong, Dara Bracken-Clarke, Elisabetta Xue, Yifan Yang, Jimeng Sun, and Zhiyong Lu. Matching patients to clinical trials with large language models.Nature Communications, 15(1):9074, November 2024
2024
-
[20]
Castro, Shruthi Bannur, Tristan Lazard, Drew FK Williamson, Faisal Mahmood, Javier Alvarez-Valle, Stephanie Hyland, and Kenza Bouzid
Anurag Jayant Vaidya, Felix Meissen, Daniel C. Castro, Shruthi Bannur, Tristan Lazard, Drew FK Williamson, Faisal Mahmood, Javier Alvarez-Valle, Stephanie Hyland, and Kenza Bouzid. NOV A: An Agentic Framework for Automated Histopathology Analysis and Discovery. November 2025
2025
-
[21]
Bulaong, John E
Kyle Swanson, Wesley Wu, Nash L. Bulaong, John E. Pak, and James Zou. The Virtual Lab of AI agents designs new SARS-CoV-2 nanobodies.Nature, 646(8085):716–723, October 2025
2025
-
[22]
Carter, Xin Zhou, Matthew Wheeler, Jonathan A
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, Di Yin, Shruti Marwaha, Jennefer N. Carter, Xin Zhou, Matthew Wheeler, Jonathan A. Bernstein, Mengdi Wang, Peng He, Jingtian Zhou, Michael Snyder, Le Cong, Aviv Regev, and Jure Leskovec. Biomni: A General-Purpose Biomedical AI Agent.bi...
2025
-
[23]
BioLab: End-to-End Autonomous Life Sciences Research with Multi-Agents System Integrating Biological Foundation Models, September 2025
Ruofan Jin, Yucheng Guo, Yuanhao Qu, Ming Yang, Chun Shang, Qirong Yang, Linlin Chao, Yi Zhou, Ruilai Xu, Ziyao Xu, Ruhong Zhou, Zaixi Zhang, Mengdi Wang, Xiaoming Zhang, and Le Cong. BioLab: End-to-End Autonomous Life Sciences Research with Multi-Agents System Integrating Biological Foundation Models, September 2025. ISSN: 2692-8205 Pages: 2025.09.03.674...
2025
-
[24]
OriGene: A Self- Evolving Virtual Disease Biologist Automating Therapeutic Target Discovery, June 2025
Zhongyue Zhang, Zijie Qiu, Yingcheng Wu, Shuya Li, Dingyan Wang, Zhuomin Zhou, Duo An, Yuhan Chen, Yu Li, Yongbo Wang, Chubin Ou, Zichen Wang, Jack Xiaoyu Chen, Bo Zhang, Yusong Hu, Wenxin Zhang, Zhijian Wei, Runze Ma, Qingwu Liu, Bo Dong, Yuexi He, Qiantai Feng, Lei Bai, Qiang Gao, Siqi Sun, and Shuangjia Zheng. OriGene: A Self- Evolving Virtual Disease ...
2025
-
[25]
Li, Shanghua Gao, Wanxiang Shen, Valentina Giunchiglia, Andrew Shen, Yepeng Huang, Zhenglun Kong, and Marinka Zitnik
Pengwei Sui, Michelle M. Li, Shanghua Gao, Wanxiang Shen, Valentina Giunchiglia, Andrew Shen, Yepeng Huang, Zhenglun Kong, and Marinka Zitnik. Medea: An omics AI agent for therapeutic discovery.bioRxiv: The Preprint Server for Biology, page 2026.01.16.696667, January 2026
2026
-
[26]
BioMaster: Multi-agent System for Automated Bioinformatics Analysis Workflow, January 2025
Houcheng Su, Weicai Long, and Yanlin Zhang. BioMaster: Multi-agent System for Automated Bioinformatics Analysis Workflow, January 2025. Pages: 2025.01.23.634608 Section: New Results. 7
2025
-
[27]
Language Model Powered Digital Biology with BRAD, December 2024
Joshua Pickard, Ram Prakash, Marc Andrew Choi, Natalie Oliven, Cooper Stansbury, Jillian Cwycyshyn, Alex Gorodetsky, Alvaro Velasquez, and Indika Rajapakse. Language Model Powered Digital Biology with BRAD, December 2024. arXiv:2409.02864 [cs]
-
[28]
GeneAgent: self-verification language agent for gene-set analysis using domain databases.Nature Methods, 22(8):1677–1685, August 2025
Zhizheng Wang, Qiao Jin, Chih-Hsuan Wei, Shubo Tian, Po-Ting Lai, Qingqing Zhu, Chi-Ping Day, Christina Ross, Robert Leaman, and Zhiyong Lu. GeneAgent: self-verification language agent for gene-set analysis using domain databases.Nature Methods, 22(8):1677–1685, August 2025
2025
-
[29]
KARMA: Leveraging Multi- Agent LLMs for Automated Knowledge Graph Enrichment
Yuxing Lu, Wei Wu, Xukai Zhao, Rui Peng, and Jinzhuo Wang. KARMA: Leveraging Multi- Agent LLMs for Automated Knowledge Graph Enrichment. October 2025
2025
-
[30]
Topo-I inhibitor combinations in NSCLC,
Timothy A. Yap, Elisa Fontana, Elizabeth K. Lee, David R. Spigel, Martin Højgaard, Stephanie Lheureux, Niharika B. Mettu, Benedito A. Carneiro, Louise Carter, Ruth Plummer, Gregory M. Cote, Funda Meric-Bernstam, Joseph O’Connell, Joseph D. Schonhoft, Marisa Wainszelbaum, Adrian J. Fretland, Peter Manley, Yi Xu, Danielle Ulanet, Victoria Rimkunas, Mike Zin...
2023
-
[31]
drug name, disease name), is it present and unambiguously identified in the actual output?
Canonical entity: When the expected output labels a canonical name (e.g. drug name, disease name), is it present and unambiguously identified in the actual output?
-
[32]
Identifier match: Do all identifiers labelled in the expected output appear in the actual output with matching values?
-
[33]
ATR inhibitor–sensitizing mutations,
No fabrication: The actual output does not introduce alternative identifiers that contradict the expected ones, and does not confuse the entity with a same-string alias of a different gene/disease/drug. A three-tier rubric yields the bands [0.0,0.2] , [0.4,0.6] , [0.8,1.0] ; the gaps make tier boundaries unambiguous and the judge commits to one tier per t...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.