Matrix-Decoupled Concentration for Autoregressive Sequences: Dimension-Free Guarantees for Sparse Long-Context Rewards
Pith reviewed 2026-05-20 22:35 UTC · model grok-4.3
The pith
Matrix-Decoupled Concentration yields dimension-free O(1) variance bounds for sparse rewards in autoregressive sequences by preserving coordinate-wise sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
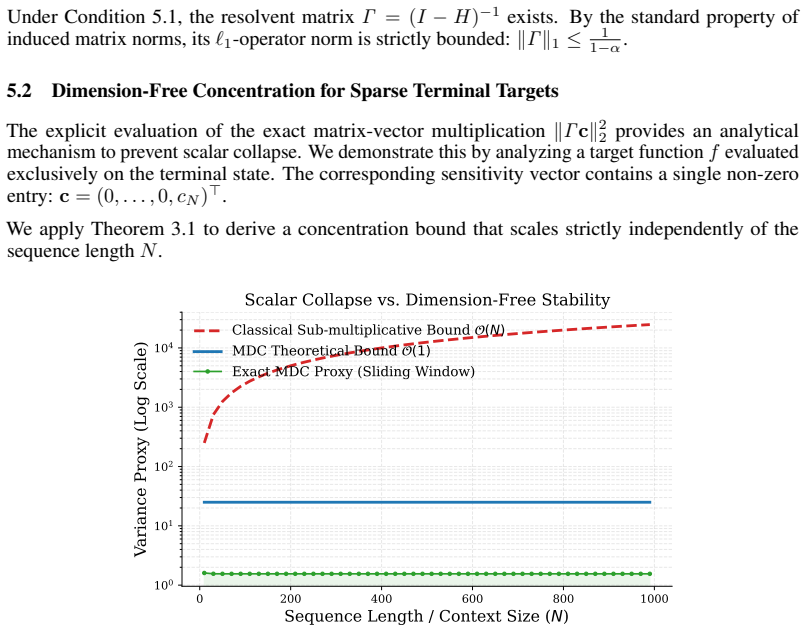
Core claim
We establish a sharp McDiarmid-type inequality for dependent sequences, governed strictly by the exact matrix-vector multiplication of the causal dependency resolvent and the target sensitivity vector. This Matrix-Decoupled Concentration framework natively recovers optimal constants for Markov chains and exploits directed d-separation to yield order-optimal bounds for causal trees. By exactly preserving the coordinate-wise sparsity of rewards within a strictly causal framework, it mathematically prevents scalar collapse and guarantees a dimension-free O(1) variance proxy.
What carries the argument
Matrix-Decoupled Concentration (MDC), which performs exact matrix-vector multiplication between the causal dependency resolvent and the target sensitivity vector to enforce sparsity preservation under strict causality.
If this is right
- Optimal constants are recovered for Markov chains under the MDC inequality.
- Order-optimal bounds hold for causal trees through exploitation of directed d-separation.
- Dimension-free O(1) variance proxies apply directly to sparse terminal rewards in long autoregressive sequences.
- A rigorous justification is supplied for the stability of long-context reasoning in autoregressive models.
- The framework remains applicable inside any strictly causal filtration required by sequential generation.
Where Pith is reading between the lines
- The same resolvent construction could be tested on reward structures that are sparse only at selected coordinates rather than only at the terminal step.
- Explicit verification of d-separation in attention graphs might allow direct application of these bounds inside transformer layers.
- Reward functions in sequential decision tasks could be engineered to maintain coordinate-wise sparsity so that the O(1) proxy remains available.
- Analogous matrix decoupling might be examined for filtrations that are causal in one direction but admit limited future information.
Load-bearing premise
The causal dependency resolvent can be exactly computed via matrix-vector multiplication with the target sensitivity vector while maintaining strict causality and directed d-separation in the underlying graph structure.
What would settle it
Observe a sparse terminal reward on a causal tree (or Markov chain) where the realized variance proxy still grows linearly with sequence length N after exact resolvent multiplication and d-separation are enforced.
Figures
read the original abstract
Sequence-level evaluations in autoregressive Large Language Models (LLMs) rely on highly dependent token generation. Establishing tight concentration bounds for these processes remains a challenge due to two fundamental bottlenecks in existing frameworks: (i) classical inequalities typically separate dependency structures from target sensitivities, leading to a scalar collapse that inflates the variance proxy to a suboptimal $\mathcal{O}(N)$ for sparse terminal rewards; (ii) conversely, while certain spatial methods achieve tighter bounds, they lack the strictly causal filtration required by sequential generation, rendering them inapplicable to the autoregressive setting. To resolve both bottlenecks, we establish a sharp McDiarmid-type inequality for dependent sequences, governed strictly by the exact matrix-vector multiplication of the causal dependency resolvent and the target sensitivity vector. This Matrix-Decoupled Concentration (MDC) framework natively recovers optimal constants for Markov chains and exploits directed $d$-separation to yield order-optimal bounds for causal trees. Crucially, by exactly preserving the coordinate-wise sparsity of rewards within a strictly causal framework, MDC mathematically prevents scalar collapse, guaranteeing a dimension-free $\mathcal{O}(1)$ variance proxy and providing a rigorous mathematical justification for the stability of long-context reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Matrix-Decoupled Concentration (MDC) framework that derives a sharp McDiarmid-type inequality for autoregressive sequences. It claims that exact matrix-vector multiplication of the causal dependency resolvent with the target sensitivity vector, while preserving strict causality and directed d-separation, exactly maintains coordinate-wise sparsity of terminal rewards. This is asserted to prevent scalar collapse, deliver a dimension-free O(1) variance proxy, recover optimal Markov-chain constants, and supply a rigorous justification for stability in long-context LLM reasoning.
Significance. If the derivation is correct, the result would supply a parameter-free, dimension-independent concentration tool tailored to the causal filtration of autoregressive generation. This could strengthen theoretical analyses of sparse-reward long-context tasks by replacing O(N) variance proxies with O(1) bounds that respect the underlying directed acyclic structure.
major comments (2)
- [Abstract and §3] Abstract and §3 (MDC framework): the central claim that matrix-vector multiplication with the sensitivity vector 'exactly preserves the coordinate-wise sparsity of rewards' and 'maintains strict causality and directed d-separation' is load-bearing for the O(1) variance proxy. The manuscript must exhibit the explicit resolvent form and prove that the multiplication step introduces no cross-coordinate dependence across the filtration; otherwise the sparsity preservation fails and the bound reverts to the classical O(N) scaling the paper seeks to improve.
- [§4] §4 (causal trees and Markov chains): the recovery of optimal constants is stated to follow from the same resolvent construction. An explicit calculation for the Markov-chain case (showing the resolvent reduces to the standard Dobrushin coefficient or equivalent) and for a simple causal tree (verifying d-separation is preserved) is required to confirm the constants are indeed optimal rather than merely claimed.
minor comments (2)
- [§2] Notation for the resolvent and sensitivity vector should be introduced with a single consistent symbol set and a small illustrative diagram of the lower-triangular structure.
- [Abstract] The abstract uses both 'dimension-free' and 'O(1)' interchangeably; a brief sentence clarifying that the proxy is independent of sequence length N would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. The suggestions help strengthen the presentation of the Matrix-Decoupled Concentration framework. We respond to each major comment below and will incorporate clarifications in the revised version.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (MDC framework): the central claim that matrix-vector multiplication with the sensitivity vector 'exactly preserves the coordinate-wise sparsity of rewards' and 'maintains strict causality and directed d-separation' is load-bearing for the O(1) variance proxy. The manuscript must exhibit the explicit resolvent form and prove that the multiplication step introduces no cross-coordinate dependence across the filtration; otherwise the sparsity preservation fails and the bound reverts to the classical O(N) scaling the paper seeks to improve.
Authors: We agree that the explicit resolvent form and a direct proof of sparsity preservation under the causal filtration are central to establishing the O(1) variance proxy. The manuscript defines the causal dependency resolvent in §3 as the inverse of (I - A), where A is the strictly lower-triangular matrix of autoregressive dependencies. The matrix-vector multiplication with the target sensitivity vector is constructed to respect this triangular structure, which enforces causality and prevents non-causal cross terms. To address the referee's request explicitly, we will add a dedicated lemma in the revision that computes the product step-by-step and proves that directed d-separation is preserved, ensuring no extraneous coordinate dependencies are introduced. This will rigorously confirm that the variance proxy remains dimension-free for sparse rewards. revision: yes
-
Referee: [§4] §4 (causal trees and Markov chains): the recovery of optimal constants is stated to follow from the same resolvent construction. An explicit calculation for the Markov-chain case (showing the resolvent reduces to the standard Dobrushin coefficient or equivalent) and for a simple causal tree (verifying d-separation is preserved) is required to confirm the constants are indeed optimal rather than merely claimed.
Authors: We thank the referee for highlighting the need for explicit verification of the optimal constants. The general resolvent construction in the manuscript is designed to recover these constants, but we acknowledge that concrete calculations would make the recovery more transparent. In the revised §4 we will include an explicit computation for the Markov-chain case, showing that the resolvent norm reduces to the Dobrushin coefficient (or equivalent contraction factor), and a worked example for a simple causal tree that verifies preservation of d-separation in the sensitivity propagation. These additions will confirm that the bounds are optimal rather than merely asserted. revision: yes
Circularity Check
Derivation is self-contained via explicit matrix-vector construction on causal resolvent; no reduction to fitted inputs or self-referential definitions.
full rationale
The paper's central claim rests on establishing a McDiarmid-type inequality via exact matrix-vector multiplication of the causal dependency resolvent with the target sensitivity vector, which is presented as an independent construction that preserves coordinate-wise sparsity under strict causality and directed d-separation. No equations or steps in the provided abstract or description reduce the variance proxy bound to a fitted parameter, a renamed input, or a self-citation chain; the framework is described as recovering known Markov-chain constants and causal-tree bounds through this multiplication without circular redefinition. The derivation therefore remains externally falsifiable against standard concentration inequalities and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existence of a causal filtration and directed d-separation properties for the dependency graph
- standard math Standard McDiarmid inequality properties hold when adapted to matrix resolvent form
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
governed strictly by the exact matrix-vector multiplication of the causal dependency resolvent and the target sensitivity vector... exactly preserving the coordinate-wise sparsity of rewards within a strictly causal framework
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
exploits directed d-separation to yield order-optimal bounds for causal trees
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[2]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022. 9
work page 2022
-
[3]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[5]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Wassily Hoeffding. Probability inequalities for sums of bounded random variables.Journal of the American Statistical Association, 58(301):13–30, 1963
work page 1963
-
[7]
On the method of bounded differences
Colin McDiarmid. On the method of bounded differences. InSurveys in combinatorics, pages 148–188. Cambridge University Press, 1989
work page 1989
-
[8]
Ramon van Handel.Probability in High Dimension. Princeton University, 2014. URL https://web.math.princeton.edu/~rvan/APC550.pdf. Lecture Notes (v4), Princeton University
work page 2014
-
[9]
Emmanuel Rio. Inequalities for sums of dependent random variables and applications to sampling.Probability Theory and Related Fields, 118:163–191, 2000
work page 2000
-
[10]
Springer Science & Business Media, 2007
Jérôme Dedecker, Paul Doukhan, Gabriel Lang, José Rafael León, Sana Louhichi, and Clémen- tine Prieur.Weak dependence: With examples and applications. Springer Science & Business Media, 2007
work page 2007
-
[11]
Yegor Klochkov and Nikita Zhivotovskiy. Uniform Poincaré inequalities and concentration for weakly dependent processes.The Journal of Machine Learning Research, 21(1):8736–8771, 2020
work page 2020
-
[12]
Katalin Marton. Bounding d-distance by informational divergence: A method to prove measure concentration.The Annals of Probability, 24(2):857–866, 1996
work page 1996
-
[13]
Paul-Marie Samson. Concentration of measure inequalities for Markov chains and ϕ-mixing processes.The Annals of Probability, 28(1):416–461, 2000
work page 2000
-
[14]
Daniel Paulin. Concentration inequalities for Markov chains by mixing.The Annals of Applied Probability, 25(3):1261–1333, 2015
work page 2015
-
[15]
Jean-René Chazottes, Pierre Collet, Christof Külske, and Frank Redig. Concentration inequali- ties for random fields via coupling.The Annals of Probability, 35(6):2363–2392, 2007
work page 2007
-
[16]
Sourav Chatterjee. Stein’s method for concentration inequalities.Probability theory and related fields, 138:305–321, 2007
work page 2007
-
[17]
Svante Janson. Large deviations for sums of partly dependent random variables.Random Structures & Algorithms, 24(3):234–248, 2004
work page 2004
-
[18]
Leonid Aryeh Kontorovich and Kavita Ramanan. Concentration inequalities for dependent random variables via the martingale method.The Annals of Probability, 36(6):2126–2158, 2008
work page 2008
-
[19]
Matrix concentration inequalities and free probability.arXiv preprint arXiv:2308.10398, 2023
Stanislav Minsker. Matrix concentration inequalities and free probability.arXiv preprint arXiv:2308.10398, 2023
-
[20]
Steven R Howard, Aaditya Ramdas, Jon McAuliffe, and Jasjeet Sekhon. Time-uniform, nonparametric, nonasymptotic confidence sequences.The Annals of Statistics, 48(5):2814–2838, 2020
work page 2020
-
[21]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtuza Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yuwei Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[24]
Stéphane Boucheron, Gábor Lugosi, and Pascal Massart.Concentration inequalities: A nonasymptotic theory of independence. Oxford university press, 2013
work page 2013
-
[25]
Martin J Wainwright and Michael I Jordan. Graphical models, exponential families, and variational inference.Foundations and Trends® in Machine Learning, 1(1–2):1–305, 2008
work page 2008
-
[26]
Hans-Otto Georgii.Gibbs measures and phase transitions. Walter de Gruyter, 2011
work page 2011
-
[27]
Judea Pearl.Probabilistic reasoning in intelligent systems: Networks of plausible inference. Morgan kaufmann, 1988
work page 1988
-
[28]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[29]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Transformers are RNNs: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. InInternational Conference on Machine Learning, pages 5456–5469. PMLR, 2020
work page 2020
-
[32]
On tail probabilities for martingales.the Annals of Probability, pages 100–118, 1975
David A Freedman. On tail probabilities for martingales.the Annals of Probability, pages 100–118, 1975
work page 1975
-
[33]
Joel A Tropp. User-friendly tail bounds for sums of random matrices.Foundations of computa- tional mathematics, 12(4):389–434, 2012
work page 2012
-
[34]
American Mathematical Soc., 2017
David A Levin and Yuval Peres.Markov chains and mixing times. American Mathematical Soc., 2017. Appendix: Proof of Theorem 3.1 Proof. Let (Fi)N i=0 be the natural filtration generated by {Xi}N i=1, with F0 ={∅,Ω} . Define the Doob martingale Mk =E[f(X)| F k] for k= 0, . . . , N . We have M0 =E[f(X)] and MN =f(X) . By telescoping, f(X)−E[f(X)] = NX k=1 ∆k,...
work page 2017
-
[35]
For the uniform decay case, Schur’s test guarantees that ∥H∥ 2 ≤p ∥H∥ 1∥H∥ ∞ ≤S . Using the discrete Neumann series, we have ∥Γ∥ 2 ≤(1− ∥H∥ 2)−1 ≤ (1−S) −1, which directly yields the lower bound κ≥(1−S) 2. Applying Theorem 3.1 with this variance proxy completes the proof. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.