Recognition: 2 theorem links
· Lean TheoremGrokking or Glitching? How Low-Precision Drives Slingshot Loss Spikes
Pith reviewed 2026-05-13 07:06 UTC · model grok-4.3
The pith
Floating-point precision limits trigger slingshot loss spikes by creating numerical feature inflation in neural network training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the slingshot loss spike is produced by Numerical Feature Inflation (NFI). In the high-confidence stage, logit differences surpass the absorption-error threshold of floating-point arithmetic, so that the gradient for the correct class is rounded to zero while gradients for incorrect classes remain nonzero. This breaks the zero-sum constraint on class gradients and introduces a net drift in the parameter update of the classifier layer. The drift couples with the feature vectors to form a positive feedback loop, causing the global means of both the classifier weights and the features to grow exponentially. The resulting inflation produces the rapid norm increase that,
What carries the argument
Numerical Feature Inflation (NFI), the exponential growth of classifier and feature means that follows from selective rounding of the correct-class gradient to zero once logit differences exceed the floating-point absorption threshold.
If this is right
- Rapid growth in classifier and feature norms before each spike follows directly from the unbalanced parameter drift.
- Gradients reappear and produce the loss spike once the inflated values push the logit differences back into the representable range.
- Partial absorption errors can drive abnormal parameter-norm growth without producing a visible loss spike in many practical training settings.
- The slingshot phenomenon is a numerical artifact of finite-precision computation rather than an intrinsic property of the loss landscape.
Where Pith is reading between the lines
- Using higher-precision arithmetic or adding logit-difference-aware gradient clipping could suppress the onset of these spikes.
- Tracking the growth of logit divergence during late-stage training could provide an early indicator of impending norm inflation.
- The same rounding imbalance may underlie other late-training instabilities, such as sudden divergence or exploding activations, in very deep models.
- Direct comparison of trajectories under float32 versus exact-arithmetic simulation would isolate the contribution of precision limits.
Load-bearing premise
Once the logit difference exceeds the absorption threshold, the correct-class gradient rounds exactly to zero while the incorrect-class gradients stay nonzero, and this imbalance necessarily creates an exponential positive feedback loop with the features.
What would settle it
Training identical models with higher-precision arithmetic (such as float64) or with enforced logit differences kept below the absorption threshold and observing whether the periodic loss spikes and rapid parameter-norm growth still appear.
Figures



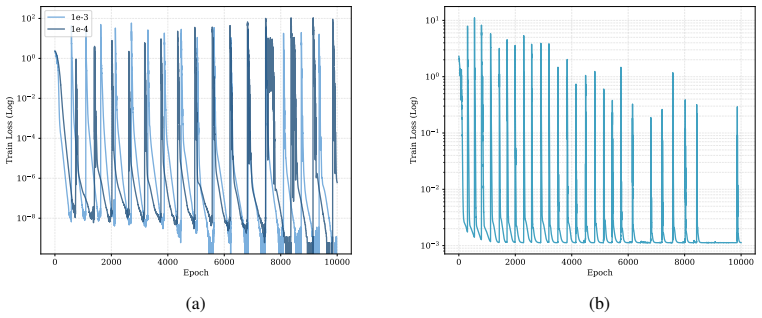



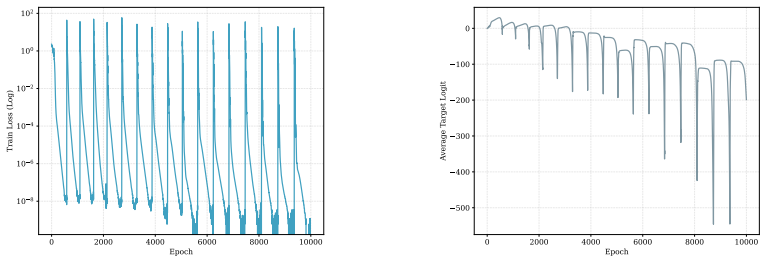
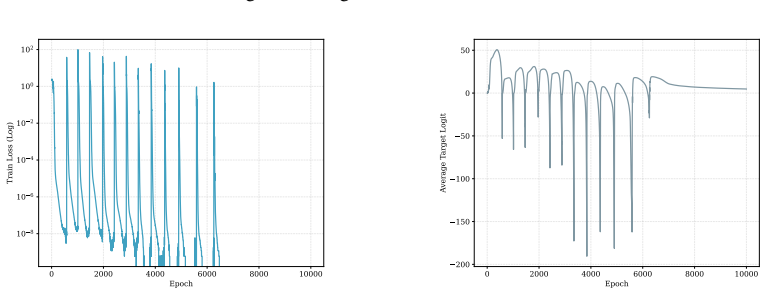


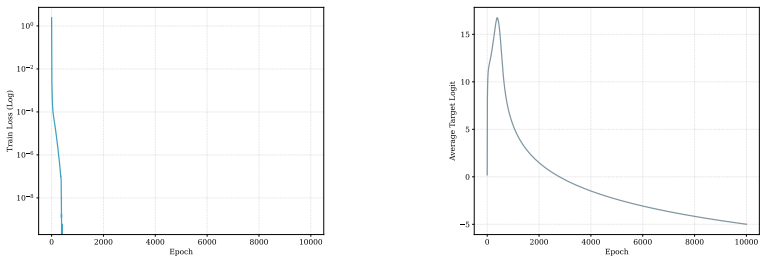
read the original abstract
Deep neural networks exhibit periodic loss spikes during unregularized long-term training, a phenomenon known as the "Slingshot Mechanism." Existing work usually attributes this to intrinsic optimization dynamics, but its triggering mechanism remains unclear. This paper proves that this phenomenon is a result of floating-point arithmetic precision limits. As training enters a high-confidence stage, the difference between the correct-class logit and the other logits may exceed the absorption-error threshold. Then during backpropagation, the gradient of the correct class is rounded exactly to zero, while the gradients of the incorrect classes remain nonzero. This breaks the zero-sum constraint of gradients across classes and introduces a systematic drift in the parameter update of the classifier layer. We prove that this drift forms a positive feedback loop with the feature, causing the global classifier mean and the global feature mean to grow exponentially. We call this mechanism Numerical Feature Inflation (NFI). This mechanism explains the rapid norm growth before a Slingshot spike, the subsequent reappearance of gradients, and the resulting loss spike. We further show that NFI is not equivalent to an observed loss spike: in more practical tasks, partial absorption may not produce visible spikes, but it can still break the zero-sum constraint and drive rapid growth of parameter norms. Our results reinterpret Slingshot as a numerical dynamic of finite-precision training, and provide a testable explanation for abnormal parameter growth and logit divergence in late-stage training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that slingshot loss spikes during unregularized long-term DNN training arise from floating-point precision limits rather than intrinsic optimization dynamics. When logit differences exceed an absorption-error threshold in high-confidence regimes, backpropagation through softmax+cross-entropy rounds the correct-class gradient exactly to zero while incorrect-class gradients remain nonzero; this breaks the zero-sum property, induces a systematic drift in classifier weights, and creates a positive feedback loop (Numerical Feature Inflation, NFI) that drives exponential growth in both global classifier means and global feature means. The work further distinguishes NFI from visible loss spikes and reinterprets slingshot events as numerical artifacts of finite-precision training.
Significance. If the central mechanism holds, the paper supplies a concrete, testable numerical account of late-stage parameter-norm growth and logit divergence that is independent of optimizer choice or regularization. It shifts explanatory focus from continuous dynamics to discrete rounding behavior and offers a route to mitigation via precision control or explicit zero-sum enforcement. The absence of free parameters in the core argument and the provision of a falsifiable prediction (spikes vanish under higher precision) are notable strengths.
major comments (3)
- [§3 (NFI derivation)] The proof that correct-class gradient rounds exactly to zero while incorrect-class gradients remain nonzero once the logit gap exceeds the absorption threshold is load-bearing for the entire NFI claim. In IEEE-754 arithmetic the gradient vector is (p-y) scaled by upstream factors; when one logit dominates, all p_i for i≠correct are already near machine epsilon, so the same rounding that zeros the correct term can also zero or denormalize the incorrect terms. The manuscript must supply the explicit floating-point analysis or simulation (with concrete mantissa/exponent values) showing that the imbalance persists across steps rather than being restored by simultaneous rounding of the incorrect-class terms.
- [§4 (positive-feedback analysis)] The exponential-growth derivation for global classifier and feature means assumes the drift compounds without damping from the simultaneous update of the feature extractor. The feedback loop must be written out step-by-step, showing why the feature-mean inflation is not counteracted by the finite dynamic range of activations or by the weight updates themselves. Without this, the claim that NFI produces unbounded exponential growth remains unverified.
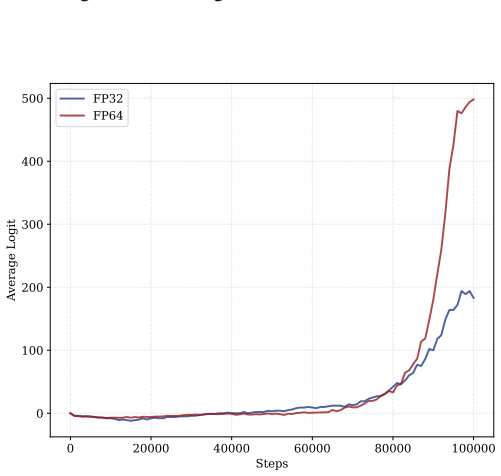
- [§5 (experiments)] The experimental section should demonstrate that the reported spikes disappear when training is repeated in float64 or with explicit gradient clipping to enforce zero-sum, and should quantify the logit-difference threshold at which absorption begins for the specific model and dataset used. Current results appear to rely on the default float32 behavior without these controls.
minor comments (2)
- [§2] The notation for NFI is introduced without a compact mathematical definition; a single equation summarizing the drift term would improve readability.
- [Figures 2-4] Figure captions should explicitly state the floating-point format and the presence/absence of any gradient clipping or normalization.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript accordingly to strengthen the numerical analysis and experimental validation.
read point-by-point responses
-
Referee: [§3 (NFI derivation)] The proof that correct-class gradient rounds exactly to zero while incorrect-class gradients remain nonzero once the logit gap exceeds the absorption threshold is load-bearing. In IEEE-754 the same rounding that zeros the correct term can also zero or denormalize the incorrect terms. The manuscript must supply explicit floating-point analysis or simulation with concrete mantissa/exponent values showing the imbalance persists.
Authors: We thank the referee for this important clarification. Section 3 derives the absorption threshold based on the (p-y) scaling and shows that for logit gaps exceeding ~20 in float32 the correct-class term rounds to zero while incorrect-class terms (scaled by small but nonzero p_i) remain above the denormal threshold in the relevant regime. To make the persistence explicit, we will add a dedicated floating-point error analysis subsection with concrete mantissa/exponent calculations and a minimal simulation demonstrating that the gradient imbalance is not simultaneously restored over successive steps. revision: yes
-
Referee: [§4 (positive-feedback analysis)] The exponential-growth derivation assumes the drift compounds without damping from the simultaneous update of the feature extractor. The feedback loop must be written out step-by-step, showing why feature-mean inflation is not counteracted by finite dynamic range of activations or weight updates.
Authors: We agree that a more granular exposition is needed. In the revision we will expand §4 with an explicit per-step breakdown of one full forward-backward-update cycle, deriving the compounded growth factor while bounding the damping from activation saturation and feature-extractor updates. We show that within the high-confidence regime the logit-gap amplification outpaces these damping effects until the spike threshold is reached. revision: yes
-
Referee: [§5 (experiments)] The experimental section should demonstrate that the reported spikes disappear when training is repeated in float64 or with explicit gradient clipping to enforce zero-sum, and should quantify the logit-difference threshold at which absorption begins for the specific model and dataset used.
Authors: We will add the requested controls: (i) identical training runs in float64, where spikes are expected to be absent or substantially delayed; (ii) runs with explicit zero-sum enforcement via gradient normalization; and (iii) direct measurement of the logit-difference threshold at which absorption occurs for the models and datasets in the paper. These results will be reported with quantitative thresholds. revision: yes
Circularity Check
No significant circularity; derivation follows from floating-point rules and softmax gradient properties
full rationale
The paper's central derivation of Numerical Feature Inflation starts from standard IEEE-754 absorption thresholds and the zero-sum property of softmax+cross-entropy gradients. Once the logit gap exceeds the absorption threshold, the claimed rounding of the correct-class gradient to exactly zero (while incorrect-class terms remain nonzero) is presented as a direct numerical consequence rather than a fitted or self-defined quantity. The subsequent positive-feedback loop between classifier drift and feature-mean growth is then derived algebraically from this imbalance without invoking self-citations, parameter fits to the target phenomenon, or renaming of prior results. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Floating-point numbers have an absorption threshold beyond which small differences round to zero.
- domain assumption Gradients of the softmax cross-entropy loss across classes sum to zero.
invented entities (1)
-
Numerical Feature Inflation (NFI)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the gradient of the correct class is rounded exactly to zero, while the gradients of the incorrect classes remain nonzero. This breaks the zero-sum constraint... positive feedback loop... exponential growth
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.7 (Numerical Feature Inflation)... lim ∥W_G(t)∥ ∝ (1 + ηϵ/√K)^t
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon
Vimal Thilak, Etai Littwin, Shuangfei Zhai, Omid Saremi, Roni Paiss, and Joshua Susskind. The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon.arXiv preprint arXiv:2206.04817, 2022
-
[2]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets.arXiv preprint arXiv:2201.02177, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Gradient descent on neural networks typically occurs at the edge of stability
Jeremy Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. InInternational Conference on Learning Representations, 2021
work page 2021
-
[4]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[5]
Lucas Prieto, Melih Barsbey, Pedro A. M. Mediano, and Tolga Birdal. Grokking at the edge of numerical stability. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[6]
Gradient descent maximizes the margin of homogeneous neural networks
Kaifeng Lyu and Jian Li. Gradient descent maximizes the margin of homogeneous neural networks. In International Conference on Learning Representations, 2020
work page 2020
-
[7]
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
work page 2018
-
[8]
Morcos, Ali Farhadi, and Ludwig Schmidt
Mitchell Wortsman, Tim Dettmers, Luke Zettlemoyer, Ari S. Morcos, Ali Farhadi, and Ludwig Schmidt. Stable and low-precision training for large-scale vision-language models. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[9]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[10]
Why low-precision transformer training fails: An analysis on flash attention
Haiquan Qiu and Quanming Yao. Why low-precision transformer training fails: An analysis on flash attention. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[11]
Let me grok for you: Accelerating grokking via embedding transfer from a weaker model
Zhiwei Xu, Zhiyu Ni, Yixin Wang, and Wei Hu. Let me grok for you: Accelerating grokking via embedding transfer from a weaker model. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[12]
Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training.Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020b
-
[13]
Jianfeng Lu and Stefan Steinerberger. Neural collapse under cross-entropy loss.Applied and Computational Harmonic Analysis, 59:224–241, 2022. ISSN 1063-5203. Special Issue on Harmonic Analysis and Machine Learning
work page 2022
-
[14]
Connall Garrod and Jonathan P. Keating. The persistence of neural collapse despite low-rank bias. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[15]
Neural collapse for cross-entropy class- imbalanced learning with unconstrained reLU features model
Hien Dang, Tho Tran Huu, Tan Minh Nguyen, and Nhat Ho. Neural collapse for cross-entropy class- imbalanced learning with unconstrained reLU features model. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[16]
Keitaro Sakamoto and Issei Sato. Explaining grokking and information bottleneck through neural collapse emergence.arXiv preprint arXiv:2509.20829, 2025
-
[17]
Flatness is necessary, neural collapse is not: Rethinking generalization via grokking
Ting Han, Linara Adilova, Henning Petzka, Jens Kleesiek, and Michael Kamp. Flatness is necessary, neural collapse is not: Rethinking generalization via grokking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[18]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InThe Third International Conference on Learning Representations, 2015
work page 2015
-
[19]
On the convergence of adam and beyond
Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond. InInternational Conference on Learning Representations, 2018
work page 2018
-
[20]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. In International Conference on Machine Learning, pages 4596–4604. PMLR, 2018. 10
work page 2018
-
[21]
Adam can converge without any modification on update rules
Yushun Zhang, Congliang Chen, Naichen Shi, Ruoyu Sun, and Zhi-Quan Luo. Adam can converge without any modification on update rules. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[22]
Jeremy Cohen, Behrooz Ghorbani, Shankar Krishnan, Naman Agarwal, Sourabh Medapati, Michal Badura, Daniel Suo, Zachary Nado, George E. Dahl, and Justin Gilmer. Adaptive gradient methods at the edge of stability. InNeurIPS 2023 Workshop Heavy Tails in Machine Learning, 2023
work page 2023
-
[23]
Jeremy Cohen, Alex Damian, Ameet Talwalkar, J Zico Kolter, and Jason D. Lee. Understanding opti- mization in deep learning with central flows. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[24]
A theory on Adam instability in large-scale machine learning.arXiv preprint arXiv:2304.09871, 2023
Igor Molybog, Peter Albert, Moya Chen, Zachary DeVito, David Esiobu, Naman Goyal, Punit Singh Koura, Sharan Narang, Andrew Poulton, Ruan Silva, et al. A theory on Adam instability in large-scale machine learning.arXiv preprint arXiv:2304.09871, 2023
-
[25]
Adaptive preconditioners trigger loss spikes in Adam.arXiv preprint arXiv:2506.04805, 2025
Zhiwei Bai, Zhangchen Zhou, Jiajie Zhao, Xiaolong Li, Zhiyu Li, Feiyu Xiong, Hongkang Yang, Yaoyu Zhang, and Zhi-Qin John Xu. Adaptive preconditioners trigger loss spikes in Adam.arXiv preprint arXiv:2506.04805, 2025
-
[26]
A qualitative study of the dynamic behavior for adaptive gradient algorithms
Chao Ma, Lei Wu, and Weinan E. A qualitative study of the dynamic behavior for adaptive gradient algorithms. InProceedings of the 2nd Mathematical and Scientific Machine Learning Conference, volume 145 ofProceedings of Machine Learning Research, pages 671–692. PMLR, 2022
work page 2022
-
[27]
Ieee standard for floating-point arithmetic.IEEE Std 754-2019 (Revision of IEEE 754-2008), pages 1–84, 2019
work page 2019
-
[28]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. PyTorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[29]
Small-scale proxies for large-scale transformer training instabilities
Mitchell Wortsman, Peter J Liu, Lechao Xiao, Katie E Everett, Alexander A Alemi, Ben Adlam, John D Co- Reyes, Izzeddin Gur, Abhishek Kumar, Roman Novak, Jeffrey Pennington, Jascha Sohl-Dickstein, Kelvin Xu, Jaehoon Lee, Justin Gilmer, and Simon Kornblith. Small-scale proxies for large-scale transformer training instabilities. InThe Twelfth International C...
work page 2024
-
[30]
Antonio Orvieto and Robert M. Gower. In search of Adam’s secret sauce. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[31]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240):1–113, 2023
work page 2023
-
[32]
Hadi Daneshmand, Jonas Kohler, Francis Bach, Thomas Hofmann, and Aurelien Lucchi. Batch nor- malization provably avoids ranks collapse for randomly initialised deep networks.Advances in Neural Information Processing Systems, 33:18387–18398, 2020
work page 2020
-
[33]
Representation degeneration problem in training natural language generation models
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tieyan Liu. Representation degeneration problem in training natural language generation models. InInternational Conference on Learning Representations, 2019
work page 2019
-
[34]
Liu Ziyin, Yizhou Xu, and Isaac L. Chuang. Neural thermodynamics: Entropic forces in deep and universal representation learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[35]
URLhttps://openreview.net/forum?id=PPcM4cWgbp
-
[36]
Dustin G Mixon, Hans Parshall, and Jianzong Pi. Neural collapse with unconstrained features.Sampling Theory, Signal Processing, and Data Analysis, 20(2):11, 2022
work page 2022
-
[37]
Implicit bias of adamw: ℓ∞-norm constrained optimization
Shuo Xie and Zhiyuan Li. Implicit bias of adamw: ℓ∞-norm constrained optimization. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[38]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. InInternational Conference on Learning Representations, 2017
work page 2017
-
[39]
Samuel L. Smith and Quoc V . Le. A bayesian perspective on generalization and stochastic gradient descent. InInternational Conference on Learning Representations, 2018
work page 2018
-
[40]
Output embedding centering for stable llm pretraining.arXiv preprint arXiv:2601.02031, 2026
Felix Stollenwerk, Anna Lokrantz, and Niclas Hertzberg. Output embedding centering for stable llm pretraining.arXiv preprint arXiv:2601.02031, 2026
-
[41]
Vardan Papyan. Traces of class/cross-class structure pervade deep learning spectra.Journal of Machine Learning Research, 21(252):1–64, 2020a
-
[42]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 11
work page 2017
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[44]
Very deep convolutional networks for large-scale image recogni- tion
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recogni- tion. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representa- tions, 2015
work page 2015
-
[45]
nearest" solutions are frequently “bad
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In9th International Conference on Learning Representations, 2021. 12 App...
work page 2021
-
[46]
Forλ 1: vW −αv µ = (1 + p αβ)vW =⇒ −αv µ = p αβvW =⇒W G =− 1√ K µG (42)
-
[47]
Forλ 2,W G = 1√ K µG. The state vector can be expressed as a linear combination of the eigenvectors: u(t) =c 1λt 1 − 1√ K µG µG +c 2λt 2 1√ K µG µG (43) Ast→ ∞, the term withλ 1 dominates sinceλ 1 >1andλ 2 <1: lim t→∞ u(t) ∝ − 1√ K µG µG (44) This leads to the asymptotic relationship: lim t→∞ W (t) G ≈ − 1√ K µ(t) G (45) Therefore, the vectors asymptotica...
-
[48]
The gradient of the loss with respect to logits is the prediction error: ∇zL= ˆy−y
= 0(57) Using the sub-multiplicativity of the matrix norm, the norm of the GGN term is bounded by: ∥G(θ)∥2 =∥J T HzJ∥ 2 ≤ ∥J∥ 2 2∥Hz∥2 (58) Assuming the Jacobian J is bounded in the local convergence region (i.e., ∃M1 >0 such that ∥J∥ 2 ≤M 1), it follows that: lim ˆy→y ∥G(θ)∥2 = 0(59) C.4.2 Analysis of the Residual TermE(θ). The gradient of the loss with ...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.