Expressivity of Bi-Lipschitz Normalizing Flows: A Score-Based Diffusion Perspective
Pith reviewed 2026-05-08 05:16 UTC · model grok-4.3
The pith
Bi-Lipschitz normalizing flows achieve universal L1 approximation of probability densities via Gaussian pullbacks from variance-preserving maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For the probability flow ODE of a variance-preserving diffusion, Lipschitz regularity of the score induces a flow of bi-Lipschitz diffeomorphic transport maps. This ODE bridge allows proving that Gaussian pullbacks induced by bi-Lipschitz variance-preserving transport maps are L1-dense among all probability densities. For Gaussian convolution targets, convergence in Kullback-Leibler divergence is obtained without early stopping.
What carries the argument
The probability flow ODE bridge that links Lipschitz continuity of the score function to the bi-Lipschitz property of the induced transport maps.
If this is right
- Bi-Lipschitz normalizing flows can approximate compactly supported densities and finite Gaussian mixtures arbitrarily closely in L1 distance.
- Convergence in Kullback-Leibler divergence holds without early stopping when targets are Gaussian convolutions of compactly supported measures.
- Deterministic convergence guarantees follow for diffusion-based transport maps under the same score regularity conditions.
- Score regularity is verified explicitly for compactly supported densities, their Gaussian convolutions, and finite mixtures.
Where Pith is reading between the lines
- The result suggests that objectives derived from the probability flow ODE could be used to train bi-Lipschitz flows directly.
- Densities with non-Lipschitz scores may require different flow architectures or relaxation of the bi-Lipschitz constraint.
- The same ODE linking technique could be applied to other diffusion schedules beyond variance-preserving ones.
- The density result may connect to questions in optimal transport about which maps preserve bi-Lipschitz regularity.
Load-bearing premise
The score function remains Lipschitz continuous for the broad classes of target densities considered, including compactly supported measures, their Gaussian convolutions, and finite mixtures.
What would settle it
A concrete density whose score is not Lipschitz continuous at some point in the diffusion, for which no sequence of bi-Lipschitz variance-preserving maps pulls back a Gaussian to approximate it arbitrarily closely in L1.
Figures


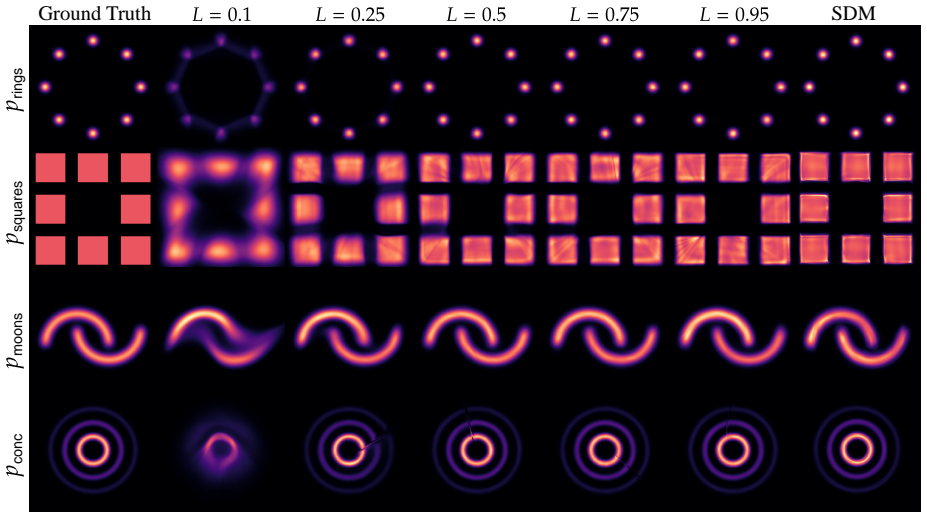
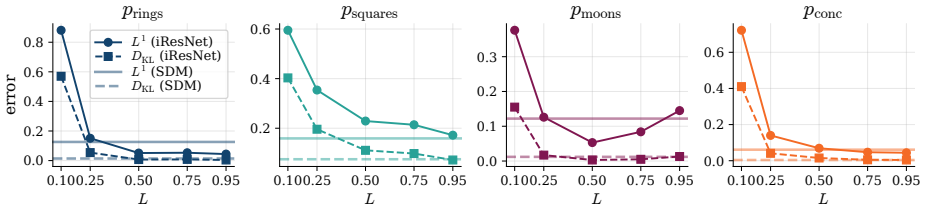
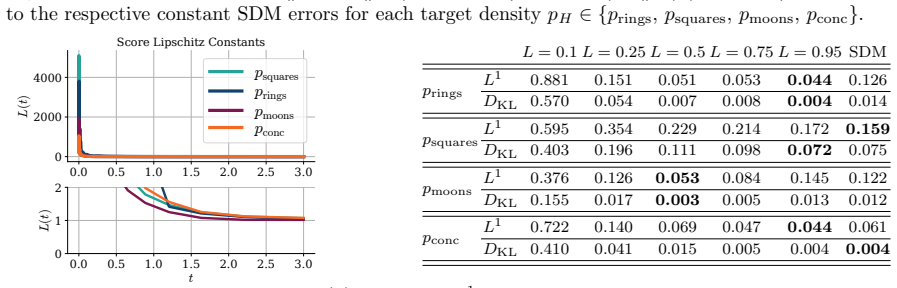
read the original abstract
Many normalizing flow architectures impose regularity constraints, yet their distributional approximation properties are not fully characterized. We study the expressivity of bi-Lipschitz normalizing flows through the lens of score-based diffusion models. For the probability flow ODE of a variance-preserving diffusion, Lipschitz regularity of the score induces a flow of bi-Lipschitz diffeomorphic transport maps. This ODE bridge allows us to analyze the distributional approximation power of bi-Lipschitz normalizing flows and, conversely, derive deterministic convergence guarantees for diffusion-based transport. Our key idea is to use the probability flow ODE to link regularity of the score to regularity of the induced transport maps. We verify score regularity for broad target densities, including compactly supported densities, Gaussian convolutions of compactly supported measures and finite Gaussian mixtures. We obtain a universal distributional approximation result: Gaussian pullbacks induced by bi-Lipschitz variance-preserving transport maps are $L^1$-dense among all probability densities. For Gaussian convolution targets, we further obtain convergence in Kullback-Leibler divergence without early stopping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper links bi-Lipschitz normalizing flows to score-based diffusion models by showing that Lipschitz regularity of the score for a variance-preserving diffusion induces a flow of bi-Lipschitz diffeomorphic transport maps via the probability flow ODE. This connection yields a universal approximation theorem: Gaussian pullbacks induced by such bi-Lipschitz variance-preserving maps are L¹-dense among all probability densities. For targets that are Gaussian convolutions of compactly supported measures, the same framework gives KL convergence without early stopping. The key technical step is verification that the score remains Lipschitz for compactly supported densities, their Gaussian convolutions, and finite Gaussian mixtures.
Significance. If the regularity verifications and ODE-induced bi-Lipschitz property hold with explicit constants, the work supplies a rigorous expressivity characterization for a practically relevant subclass of normalizing flows and supplies deterministic convergence guarantees for diffusion-based transport. The L¹-density result and the no-early-stopping KL claim are non-trivial contributions that could inform architecture design in both normalizing-flow and diffusion literature.
major comments (3)
- [verification of score regularity (abstract and main technical sections)] The load-bearing step is the claim that the score remains Lipschitz (with a constant independent of or controlled as t→0) for compactly supported target densities. Without an explicit bound on the Lipschitz constant of the score or a demonstration that it does not diverge as the noise level vanishes, the induced transport maps lose the global bi-Lipschitz property required for the L¹-density argument.
- [universal approximation result] The universal L¹-density statement for Gaussian pullbacks is asserted after the ODE bridge; however, the manuscript must supply the precise density class on which the pullback is taken and the topology in which density is measured, because the bi-Lipschitz maps are constructed only for the verified score-regular classes.
- [KL convergence section] For the KL-convergence claim on Gaussian-convolution targets, the paper states convergence without early stopping, yet no explicit error bound or rate is referenced in the abstract. If the proof relies on the same Lipschitz score assumption, the same potential divergence issue as t→0 must be ruled out explicitly.
minor comments (2)
- Notation for the variance-preserving diffusion and the probability-flow ODE should be introduced with a short self-contained paragraph early in the paper to aid readers unfamiliar with the diffusion literature.
- [Abstract] The abstract uses the phrase 'we verify score regularity'; the corresponding theorem or proposition number should be cited in the abstract for immediate traceability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below, along with indications of the revisions we intend to make to address the concerns raised.
read point-by-point responses
-
Referee: [verification of score regularity (abstract and main technical sections)] The load-bearing step is the claim that the score remains Lipschitz (with a constant independent of or controlled as t→0) for compactly supported target densities. Without an explicit bound on the Lipschitz constant of the score or a demonstration that it does not diverge as the noise level vanishes, the induced transport maps lose the global bi-Lipschitz property required for the L¹-density argument.
Authors: We appreciate the referee's identification of this critical technical point. In Proposition 3.3 and the surrounding discussion in Section 3, we verify that the score is Lipschitz for compactly supported densities under the variance-preserving diffusion, deriving the score explicitly via the convolution with the Gaussian kernel. The resulting bound depends on the radius of the support and the diffusion schedule but remains finite for each fixed t > 0. To ensure the global bi-Lipschitz property of the induced transport maps, we integrate the time-dependent Lipschitz constant along the probability flow ODE; the integrated quantity stays controlled because the vector field remains integrable. Nevertheless, we acknowledge that an explicit, t-independent statement of the bound is not highlighted in the main text. In the revision we will add a dedicated lemma with the explicit constant and a remark confirming that the bi-Lipschitz constants of the flow maps remain uniformly bounded as t → 0. revision: yes
-
Referee: [universal approximation result] The universal L¹-density statement for Gaussian pullbacks is asserted after the ODE bridge; however, the manuscript must supply the precise density class on which the pullback is taken and the topology in which density is measured, because the bi-Lipschitz maps are constructed only for the verified score-regular classes.
Authors: We agree that greater precision is required. The L¹-density claim is made with respect to the space of all probability densities on R^d that are absolutely continuous with respect to Lebesgue measure and possess finite first moments; the topology is the L¹ norm. The bi-Lipschitz maps are indeed constructed only for the three verified classes (compactly supported densities, their Gaussian convolutions, and finite Gaussian mixtures). Because these classes are dense in the L¹ topology among all integrable densities, the corresponding Gaussian pullbacks remain dense. In the revision we will insert a clarifying paragraph immediately after the statement of the universal approximation theorem that explicitly identifies the ambient function space, the L¹ topology, and the density argument that extends the result from the verified classes to all densities. revision: yes
-
Referee: [KL convergence section] For the KL-convergence claim on Gaussian-convolution targets, the paper states convergence without early stopping, yet no explicit error bound or rate is referenced in the abstract. If the proof relies on the same Lipschitz score assumption, the same potential divergence issue as t→0 must be ruled out explicitly.
Authors: The abstract asserts qualitative convergence in KL divergence without early stopping; no quantitative rate is claimed or derived. In Section 4 the proof proceeds by showing that the KL divergence is monotonically decreasing along the probability-flow ODE and tends to zero as t → 0, using the Lipschitz regularity of the score to guarantee global existence of the ODE. For Gaussian-convolution targets the score is in fact C^∞ and its Lipschitz constant remains bounded as t → 0 because the Gaussian kernel smooths the compactly supported measure uniformly. We will add an explicit paragraph in the revision that records this boundedness for the Gaussian-convolution case and thereby rules out divergence of the Lipschitz constant. Because no rate is obtained in the current analysis, we do not plan to insert a rate statement into the abstract, but we will ensure the convergence claim is accompanied by the required regularity justification. revision: partial
Circularity Check
No circularity; derivations use standard ODE theory and independently verified regularity assumptions
full rationale
The paper connects score Lipschitz continuity to bi-Lipschitz transport maps through the probability flow ODE, invoking standard existence/uniqueness results for ODEs under Lipschitz conditions. It separately verifies the score regularity assumption for the target classes (compactly supported densities, their Gaussian convolutions, and finite mixtures) and then derives the L1-density of Gaussian pullbacks and KL convergence without early stopping. No step reduces by construction to a fitted parameter, self-definition, or load-bearing self-citation; the approximation results follow directly from the verified assumptions and ODE bridge without circular dependence on the target claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Lipschitz continuity of the score function induces bi-Lipschitz regularity on the probability flow ODE transport maps
- standard math Existence and uniqueness of solutions to the probability flow ODE under Lipschitz conditions
Reference graph
Works this paper leans on
-
[1]
Glow: Generative flow with invertible 1×1 convolutions
D. P. Kingma and P. Dhariwal. “Glow: Generative flow with invertible 1×1 convolutions”. In:Advances in Neural Information Processing Systems (NeurIPS). Vol. 31. 2018
2018
-
[2]
A hierarchical latent vector model for learning long-term structure in music
A. Roberts et al. “A hierarchical latent vector model for learning long-term structure in music”. In: International Conference of Machine Learning (ICML). 2018
2018
-
[3]
VideoFlow: A flow-based generative model for video
M. Kumar et al. “VideoFlow: A flow-based generative model for video”. In:Workshop on Invertible Neural Networks and Normalizing Flows. ICML Workshop. 2019
2019
-
[4]
Hyungjin Chung, Jeongsol Kim, and Jong Chul Ye
H. Chung, J. Kim, and J. C. Ye. “Diffusion models for inverse problems”. In:arXiv preprint arXiv:2508.01975 (2025)
-
[5]
Noise flow: Noise modeling with conditional normalizing flows
A. Abdelhamed, M. A. Brubaker, and M. S. Brown. “Noise flow: Noise modeling with conditional normalizing flows”. In:Proceedings of the IEEE International Conference on Computer Vision. 2019, pp. 3165–3173
2019
-
[6]
Learned discrepancy reconstruction and benchmark dataset for magnetic particle imag- ing
M. Iske et al. “Learned discrepancy reconstruction and benchmark dataset for magnetic particle imag- ing”. In:IEEE Transactions on Computational Imaging11 (2025), pp. 1059–1073
2025
-
[7]
Auto-encoding variational Bayes
D. P. Kingma and M. Welling. “Auto-encoding variational Bayes”. In:International Conference on Learning Representations (ICLR). 2014. 32
2014
-
[8]
Generative adversarial nets
I. Goodfellow et al. “Generative adversarial nets”. In:Advances in Neural Information Processing Systems (NeurIPS). 2014
2014
-
[9]
Variational inference with normalizing flows
D. J. Rezende and S. Mohamed. “Variational inference with normalizing flows”. In:International Conference on Machine Learning (ICML). Vol. 37. 2015
2015
-
[10]
Score-based generative modeling through stochastic differential equations
Y. Song et al. “Score-based generative modeling through stochastic differential equations”. In:Inter- national Conference on Learning Representations (ICLR). 2021
2021
-
[11]
Deep unsupervised learning using nonequilibrium thermodynamics
J. Sohl-Dickstein et al. “Deep unsupervised learning using nonequilibrium thermodynamics”. In:In- ternational Conference on Machine Learning (ICML). 2015
2015
-
[12]
Normalizing flows for probabilistic modeling and inference
G. Papamakarios et al. “Normalizing flows for probabilistic modeling and inference”. In:Journal of Machine Learning Research22 (2021), pp. 1–64
2021
-
[13]
NICE: Non-linear independent components estimation
L. Dinh, D. Krueger, and Y. Bengio. “NICE: Non-linear independent components estimation”. In: International Conference on Learning Representations (ICLR) Workshop. 2015
2015
-
[14]
Invertible residual networks
J. Behrmann et al. “Invertible residual networks”. In:International Conference on Machine Learning (ICML). 2019
2019
-
[15]
Invertible residual networks in the context of regularization theory for linear inverse problems
C. Arndt et al. “Invertible residual networks in the context of regularization theory for linear inverse problems”. In:Inverse Problems39.12 (2023)
2023
-
[16]
Remarks on a multivariate transformation
M. Rosenblatt. “Remarks on a multivariate transformation”. In:The Annals of Mathematical Statistics 23.3 (1952), pp. 470–472
1952
-
[17]
Contributions to the theory of convex bodies
H. Knothe. “Contributions to the theory of convex bodies”. In:Michigan Mathematical Journal4 (1957), pp. 39–52
1957
-
[18]
Polar factorization and monotone rearrangement of vector-valued functions
Y. Brenier. “Polar factorization and monotone rearrangement of vector-valued functions”. In:Com- munications on Pure and Applied Mathematics44.4 (1991), pp. 375–417
1991
-
[19]
Monotonicity properties of optimal transportation and the FKG and related inequal- ities
L. A. Caffarelli. “Monotonicity properties of optimal transportation and the FKG and related inequal- ities”. In:Communications in Mathematical Physics214 (2000), pp. 547–563
2000
-
[20]
On a partial differential equation involving the jacobian determinant
B. Dacorogna and J. Moser. “On a partial differential equation involving the jacobian determinant”. In:Annales de l’I. H. P.1.7 (1990), pp. 1–26
1990
-
[21]
Relaxing bijectivity constraints with continuously indexed normalising flows
R. Cornish et al. “Relaxing bijectivity constraints with continuously indexed normalising flows”. In: International Conference on Machine Learning (ICML). Vol. 119. 2020, pp. 2133–2143
2020
-
[22]
The expressive power of a class of normalizing flow models
Z. Kong and K. Chaudhuri. “The expressive power of a class of normalizing flow models”. In:Inter- national Conference on Artificial Intelligence and Statistics. Vol. 108. 2020, pp. 3599–3609
2020
-
[23]
On the expressivity of bi-Lipschitz normalizing flows
A. Verine et al. “On the expressivity of bi-Lipschitz normalizing flows”. In:Proceedings of Machine Learning Research. Vol. 189. 2022
2022
-
[24]
Denoising diffusion probabilistic models
J. Ho, A. Jain, and P. Abbeel. “Denoising diffusion probabilistic models”. In:Advances in Neural Information Processing Systems (NeurIPS). 2020
2020
-
[25]
Neural ordinary differential equations
R. T. Q. Chen et al. “Neural ordinary differential equations”. In:Advances in Neural Information Processing Systems (NeurIPS). Vol. 31. 2018
2018
-
[26]
Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions
H. Chen, H. Lee, and J. Lu. “Improved analysis of score-based generative modeling: User-friendly bounds under minimal smoothness assumptions”. In:International Conference on Machine Learn- ing (ICML). Vol. 202. Proceedings of Machine Learning Research. PMLR, 2023, pp. 4735–4763
2023
-
[27]
Sampling is as easy as learning the score: Theory for diffusion models with minimal data assumptions
S. Chen et al. “Sampling is as easy as learning the score: Theory for diffusion models with minimal data assumptions”. In:International Conference on Learning Representations (ICLR). 2023
2023
-
[28]
Convergence of score-based generative modeling for general data distribu- tions
H. Lee, J. Lu, and Y. Tan. “Convergence of score-based generative modeling for general data distribu- tions”. In:International Conference on Algorithmic Learning Theory. PMLR, 2023, pp. 946–985
2023
-
[29]
KL convergence guarantees for score diffusion models under minimal data assumptions
G. Conforti, A. Durmus, and M. Gentiloni Silveri. “KL convergence guarantees for score diffusion models under minimal data assumptions”. In:SIAM Journal on Mathematics of Data Science7.1 (2025), pp. 86–109. 33
2025
-
[30]
Bakry, I
D. Bakry, I. Gentil, and M. Ledoux.Analysis and Geometry of Markov Diffusion Operators. Vol. 348. Grundlehren der mathematischen Wissenschaften. Cham: Springer, 2014
2014
-
[31]
Coupling-based invertible neural networks are universal diffeomorphism approxi- mators
T. Teshima et al. “Coupling-based invertible neural networks are universal diffeomorphism approxi- mators”. In:Advances in Neural Information Processing Systems (NeurIPS). Vol. 33. 2020
2020
-
[32]
Universal approximation property of invertible neural networks
I. Ishikawa et al. “Universal approximation property of invertible neural networks”. In:Journal of Machine Learning Research24 (2023), pp. 1–68
2023
-
[33]
Approximation capabilities of neural ODEs and invertible residual networks
H. Zhang et al. “Approximation capabilities of neural ODEs and invertible residual networks”. In: International Conference on Machine Learning (ICML). Vol. 119. 2020, pp. 11086–11095
2020
-
[34]
On the approximation of bi-Lipschitz maps by invertible neural networks
B. Jin, Z. Zhou, and J. Zou. “On the approximation of bi-Lipschitz maps by invertible neural networks”. In:Neural Networks174 (2024)
2024
-
[35]
Universal approximation of residual flows in maximum mean discrepancy
Z. Kong and K. Chaudhuri. “Universal approximation of residual flows in maximum mean discrepancy”. In:ICML 2021 Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models. 2021
2021
-
[36]
On the uni- versality of volume-preserving and coupling-based normalizing flows,
F. Draxler et al. “On the universality of coupling-based normalizing flows”. In:arXiv preprint arXiv:2402.06578 (2024)
-
[37]
Nearlyd-linear convergence bounds for diffusion models via stochastic localization
J. Benton et al. “Nearlyd-linear convergence bounds for diffusion models via stochastic localization”. In:International Conference on Learning Representations (ICLR). 2024
2024
-
[38]
Y. Yu and L. Yu. “Advancing Wasserstein convergence analysis of score-based models: Insights from discretization and second-order acceleration”. In:arXiv preprint arXiv:2502.04849(2025)
-
[39]
K. Y. Yang and A. Wibisono. “Convergence in KL divergence of the inexact Langevin algorithm with application to score-based generative models”. In:arXiv preprint arXiv:2211.01512(2022)
-
[40]
Convergence analysis for general probability flow ODEs of diffusion models in Wasserstein distances
X. Gao and L. Zhu. “Convergence analysis for general probability flow ODEs of diffusion models in Wasserstein distances”. In:International Conference on Artificial Intelligence and Statistics. PMLR, 2025, pp. 1009–1017
2025
-
[41]
The probability flow ODE is provably fast
S. Chen et al. “The probability flow ODE is provably fast”. In:Advances in Neural Information Processing Systems (NeurIPS). 2023
2023
-
[42]
Improved convergence of score-based diffusion models via prediction-correction
F. Pedrotti, J. Maas, and M. Mondelli. “Improved convergence of score-based diffusion models via prediction-correction”. In:Transactions on Machine Learning Research(2024)
2024
-
[43]
Heat flow, log-concavity, and Lipschitz transport maps
G. Brigati and F. Pedrotti. “Heat flow, log-concavity, and Lipschitz transport maps”. In:Electronic Communications in Probability30 (2025)
2025
-
[44]
C. Mooney et al. “Global well-posedness and convergence analysis of score-based generative models via sharp Lipschitz estimates”. In:arXiv preprint arXiv:2405.16104(2024)
-
[45]
Regularity of the score function in generative models
A. St´ ephanovitch. “Regularity of the score function in generative models”. In:arXiv preprint arXiv:2506.19559 (2025)
-
[46]
Spectral normalization for generative adversarial networks
T. Miyato et al. “Spectral normalization for generative adversarial networks”. In:International Con- ference on Learning Representations (ICLR). 2018
2018
-
[47]
Fourier features let networks learn high frequency functions in low dimensional domains
M. Tancik et al. “Fourier features let networks learn high frequency functions in low dimensional domains”. In:Advances in Neural Information Processing Systems (NeurIPS). 2020
2020
-
[48]
Amann.Ordinary Differential Equations: An Introduction to Nonlinear Analysis
H. Amann.Ordinary Differential Equations: An Introduction to Nonlinear Analysis. Berlin, New York: Walter de Gruyter, 1990
1990
-
[49]
Øksendal.Stochastic Differential Equations
B. Øksendal.Stochastic Differential Equations. 6th ed. Universitext. Berlin: Springer, 2003. 34
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.