Recognition: unknown
Spark3R: Asymmetric Token Reduction Makes Fast Feed-Forward 3D Reconstruction
Pith reviewed 2026-05-08 13:36 UTC · model grok-4.3
The pith
Asymmetric compression of query versus key-value tokens speeds feed-forward 3D reconstruction up to 28 times without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
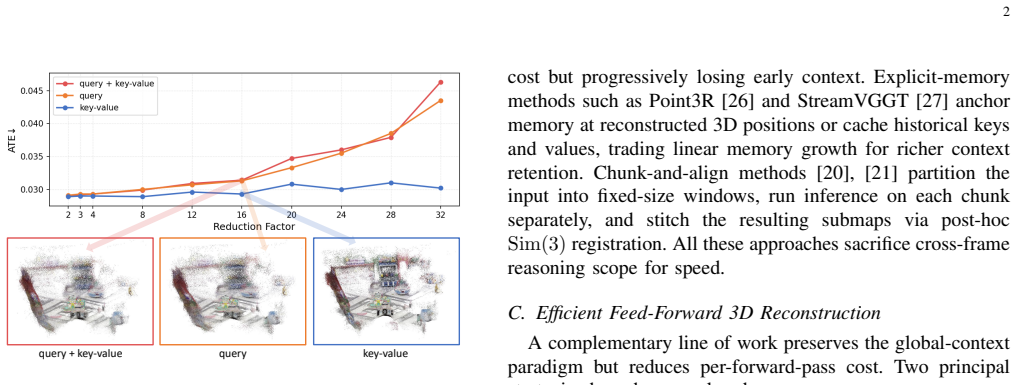
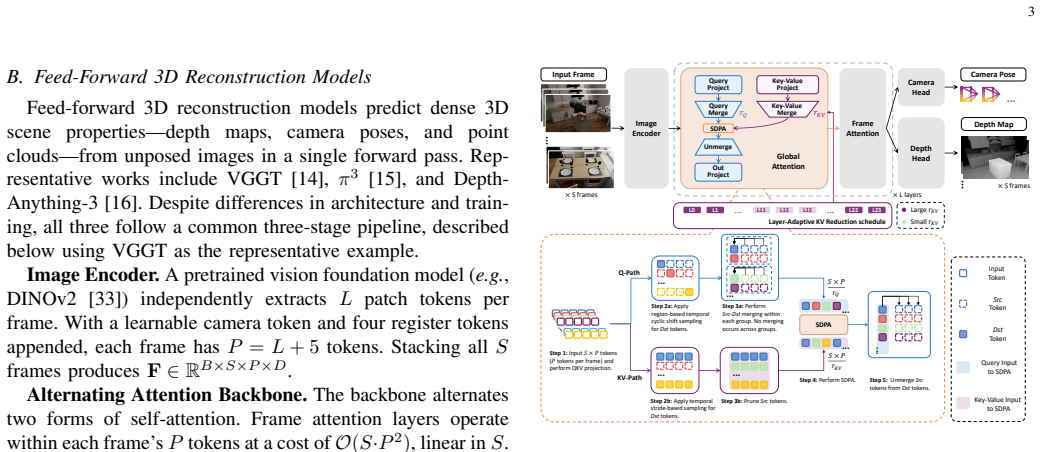
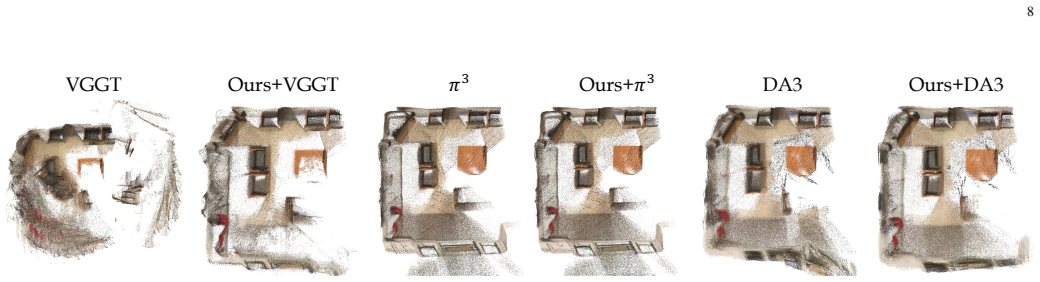
Query tokens encode view-specific geometric requests and remain sensitive to compression, whereas key-value tokens represent shared scene context and tolerate aggressive compression. Spark3R exploits this split by assigning distinct reduction factors, using intra-group token merging on queries and lightweight token pruning on key-value tokens, plus an adaptive schedule that changes the key-value reduction factor layer by layer. The framework requires no retraining and inserts directly into pretrained models such as VGGT, π³, and Depth-Anything-3, producing up to 28× speedup on 1,000-frame inputs while preserving competitive reconstruction quality.
What carries the argument
Asymmetric token reduction that applies intra-group merging to query tokens and adaptive lightweight pruning to key-value tokens.
If this is right
- Pretrained models can process video-length inputs with hundreds or thousands of frames at practical speeds.
- No retraining or architectural changes are needed, so the method works immediately on published checkpoints.
- Reconstruction quality stays competitive rather than trading off sharply for speed.
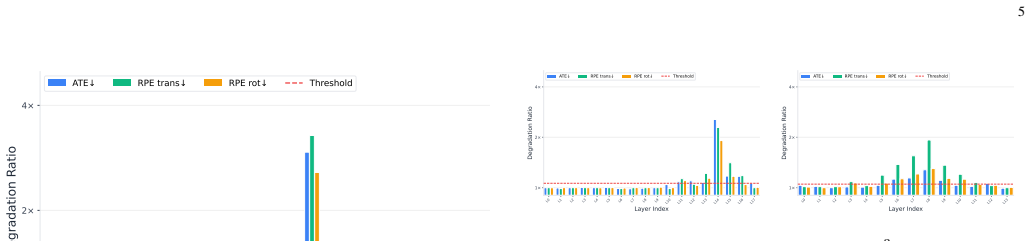
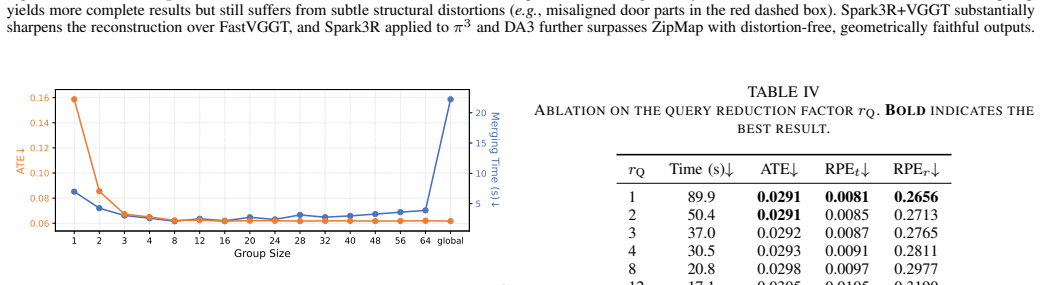
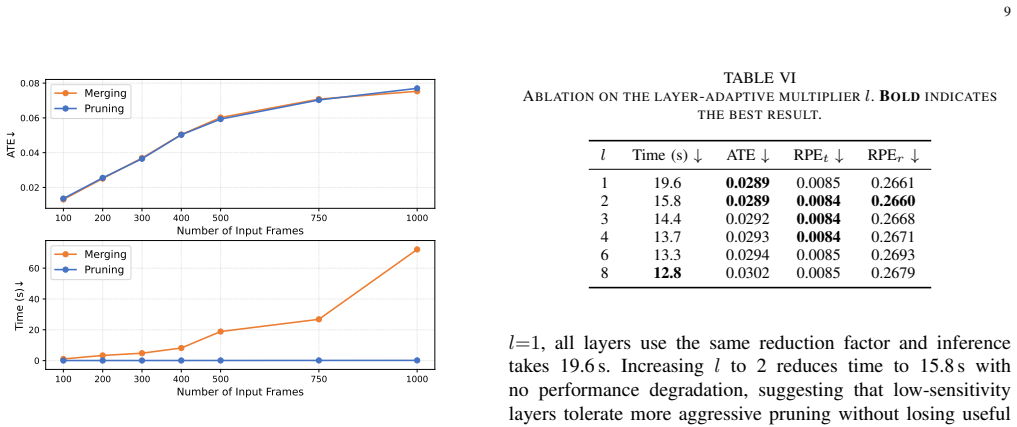
- Layer-wise adaptation of the key-value reduction factor improves the quality-efficiency balance beyond fixed-rate pruning.
- The same plug-in pattern applies to multiple distinct feed-forward 3D architectures.
Where Pith is reading between the lines
- The functional split between query and key-value roles may exist in other vision-transformer tasks that process multi-view or sequential data, suggesting similar asymmetric reductions could be tested there.
- Future model designs could explicitly separate view-specific and scene-shared pathways to make such acceleration easier to apply by default.
- Evaluating the method on inputs with strong motion or changing lighting would test whether the tolerance of key-value tokens holds under more variable scene conditions.
Load-bearing premise
Query tokens are always more sensitive to compression than key-value tokens, and this distinction remains reliable across different pretrained models and input lengths without further tuning.
What would settle it
Apply the same aggressive pruning rate to both query and key-value tokens on 1,000-frame sequences and measure whether reconstruction quality falls below the level achieved by the asymmetric method.
Figures


read the original abstract
Feed-forward 3D reconstruction models based on Vision Transformers can directly estimate scene geometry and camera poses from a small set of input images, but scaling them to video inputs with hundreds or thousands of frames remains challenging due to the quadratic cost of global attention layers. Recent token-merging methods accelerate these models by compressing the token sequence within the global attention layers, but they apply a uniform reduction to query tokens and key-value tokens, ignoring their functionally distinct roles in 3D reconstruction. In this work, we identify a key property of feed-forward 3D reconstruction models: query tokens encode view-specific geometric requests and are sensitive to compression, while key-value tokens represent shared scene context and tolerate aggressive compression. Guided by this insight, we propose Spark3R, a training-free acceleration framework that decouples the compression of query tokens and key-value tokens by assigning distinct reduction factors, with intra-group token merging applied to query tokens and lightweight token pruning to key-value tokens. Additionally, Spark3R adaptively adjusts the key-value reduction factor across layers, further improving the quality-efficiency trade-off. As a plug-and-play framework requiring no retraining, Spark3R integrates directly into multiple pretrained feed-forward 3D reconstruction models, including VGGT, $\pi^3$, and Depth-Anything-3, and achieves up to $28\times$ speedup on 1,000-frame inputs while maintaining competitive reconstruction quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Spark3R, a training-free plug-and-play framework for accelerating feed-forward 3D reconstruction models based on Vision Transformers. It claims that query tokens encode view-specific geometric requests and are sensitive to compression, while key-value tokens represent shared scene context and tolerate aggressive compression. The method decouples their treatment by applying intra-group token merging to queries and lightweight pruning to KV tokens, with adaptive per-layer KV reduction factors, and reports integration into VGGT, π³, and Depth-Anything-3, achieving up to 28× speedup on 1,000-frame inputs while maintaining competitive reconstruction quality.
Significance. If the empirical claims hold, Spark3R provides a practical, training-free method to scale 3D reconstruction to long video sequences by mitigating the quadratic cost of global attention without retraining. The asymmetric reduction strategy based on functional token roles is a targeted optimization that could generalize to other attention-heavy vision models. The plug-and-play integration and high reported speedup are notable strengths that address a real scalability bottleneck in the field.
major comments (2)
- [Abstract and §3] Abstract and §3: The central claim rests on the functional distinction that query tokens are compression-sensitive while KV tokens are tolerant, yet no ablation studies, sensitivity analyses, or quantitative comparisons (e.g., quality drop when applying uniform vs. asymmetric reduction) are referenced to establish this distinction or demonstrate its generalization across the tested models (VGGT, π³, Depth-Anything-3) and long input sequences.
- [Evaluation] Evaluation (as referenced in abstract claims): The abstract asserts up to 28× speedup with maintained competitive quality on 1,000-frame inputs, but provides no specific quantitative metrics (e.g., reconstruction error, PSNR/accuracy scores, runtime breakdowns), baseline comparisons, or error analysis, making it impossible to verify the quality-efficiency trade-off or the adaptive KV reduction's contribution.
minor comments (1)
- [Abstract] Abstract: The model name π³ uses LaTeX rendering that may not render consistently in plain text; ensure uniform notation throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where the manuscript would benefit from greater explicitness and additional supporting experiments. We address each point below and commit to revisions that strengthen the presentation of the core claims without altering the technical approach.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: The central claim rests on the functional distinction that query tokens are compression-sensitive while KV tokens are tolerant, yet no ablation studies, sensitivity analyses, or quantitative comparisons (e.g., quality drop when applying uniform vs. asymmetric reduction) are referenced to establish this distinction or demonstrate its generalization across the tested models (VGGT, π³, Depth-Anything-3) and long input sequences.
Authors: We agree that the manuscript would be stronger with explicit ablations directly comparing uniform versus asymmetric reduction. Section 3 motivates the distinction from the roles of queries (view-specific geometric requests) versus KV tokens (shared scene context) in the attention layers of feed-forward 3D models, but dedicated quantitative validation was not included. In the revision we will add a new ablation subsection (and corresponding table) that reports reconstruction accuracy, PSNR, and error metrics under uniform reduction, our asymmetric strategy, and layer-wise adaptive KV pruning. These experiments will cover all three evaluated models and input lengths up to 1,000 frames, with sensitivity analysis on the reduction factors. revision: yes
-
Referee: [Evaluation] Evaluation (as referenced in abstract claims): The abstract asserts up to 28× speedup with maintained competitive quality on 1,000-frame inputs, but provides no specific quantitative metrics (e.g., reconstruction error, PSNR/accuracy scores, runtime breakdowns), baseline comparisons, or error analysis, making it impossible to verify the quality-efficiency trade-off or the adaptive KV reduction's contribution.
Authors: The current abstract summarizes the headline result, but the referee is correct that specific numbers, runtime breakdowns, and direct baseline comparisons are not referenced from the abstract or evaluation section. The revision will expand the abstract to cite the relevant tables/figures and add a concise summary paragraph in Section 4 that reports concrete metrics (PSNR, depth accuracy, wall-clock time) for the 28× speedup case on 1,000-frame inputs, together with comparisons against uniform token merging and the unaccelerated baselines. We will also include an error analysis of the adaptive KV reduction factor and its contribution to the observed trade-off. revision: yes
Circularity Check
No circularity: empirical heuristic with independent experimental validation
full rationale
The paper's central contribution is an empirical observation about differential compression sensitivity of query vs. KV tokens in pretrained ViT-based 3D reconstructors, followed by a training-free asymmetric reduction scheme (intra-group merging for queries, pruning for KV, with adaptive per-layer factors). No load-bearing step reduces to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The method is presented as a plug-and-play heuristic validated on external models (VGGT, π³, Depth-Anything-3) and long sequences; the functional distinction is not derived from the method itself but tested against it. This matches the default expectation of a non-circular empirical acceleration paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProc. of CVPR, 2016, pp. 4104–4113
2016
-
[2]
Photo tourism: exploring photo collections in 3d,
N. Snavely, S. M. Seitz, and R. Szeliski, “Photo tourism: exploring photo collections in 3d,”ACM Trans. Graph., vol. 25, no. 3, p. 835–846, Jul. 2006. [Online]. Available: https://doi.org/10.1145/1141911.1141964
-
[3]
Pixelwise view selection for unstructured multi-view stereo,
J. L. Sch ¨onberger, E. Zheng, J.-M. Frahm, and M. Pollefeys, “Pixelwise view selection for unstructured multi-view stereo,” inProc. of ECCV. Springer, 2016, pp. 501–518
2016
-
[4]
Mvsnet: Depth inference for unstructured multi-view stereo,
Y . Yao, Z. Luo, S. Li, T. Fang, and L. Quan, “Mvsnet: Depth inference for unstructured multi-view stereo,” inProc. of ECCV, 2018, pp. 767– 783
2018
-
[5]
Nerf: Representing scenes as neural radiance fields for view synthesis,
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “Nerf: Representing scenes as neural radiance fields for view synthesis,”Communications of the ACM, vol. 65, no. 1, pp. 99–106, 2021
2021
-
[6]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Transactions on Graphics, vol. 42, no. 4, pp. 139–1, 2023
2023
-
[7]
Scaffold- gs: Structured 3d gaussians for view-adaptive rendering,
T. Lu, M. Yu, L. Xu, Y . Xiangli, L. Wang, D. Lin, and B. Dai, “Scaffold- gs: Structured 3d gaussians for view-adaptive rendering,” inProc. of CVPR, 2024, pp. 20 654–20 664
2024
-
[8]
HiCoM: Hierarchical coherent motion for dynamic streamable scenes with 3D gaussian splatting,
Q. Gao, J. Meng, C. Wen, J. Chen, and J. Zhang, “HiCoM: Hierarchical coherent motion for dynamic streamable scenes with 3D gaussian splatting,” inProc. of NeurIPS, 2024. 10
2024
-
[9]
Recon- gs: Continuum-preserved gaussian streaming for fast and compact re- construction of dynamic scenes,
J. Fu, Q. Gao, C. Wen, Y . Wu, S. Ma, J. Zhang, and J. Zhang, “Recon- gs: Continuum-preserved gaussian streaming for fast and compact re- construction of dynamic scenes,” inProc. of NeurIPS, 2025
2025
-
[10]
Virpnet: A multimodal virtual point generation network for 3d object detection,
L. Wang, S. Sun, and J. Zhao, “Virpnet: A multimodal virtual point generation network for 3d object detection,”IEEE Transactions on Multimedia, vol. 26, pp. 10 597–10 609, 2024
2024
-
[11]
Robo3R: Enhancing Robotic Manipulation with Accurate Feed-Forward 3D Reconstruction
S. Yang, L. Xu, H. Li, J. Mu, J. Zeng, D. Lin, and J. Pang, “Robo3r: Enhancing robotic manipulation with accurate feed-forward 3d recon- struction,”arXiv preprint arXiv:2602.10101, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Language-assisted 3d scene understanding,
Y . Wu, Q. Gao, R. Zhang, H. Li, and J. Zhang, “Language-assisted 3d scene understanding,”IEEE Transactions on Multimedia, vol. 27, pp. 3869–3879, 2025
2025
-
[13]
3ur-llm: An end- to-end multimodal large language model for 3d scene understanding,
H. Xiong, Y . Zhuge, J. Zhu, L. Zhang, and H. Lu, “3ur-llm: An end- to-end multimodal large language model for 3d scene understanding,” IEEE Transactions on Multimedia, vol. 27, pp. 2899–2911, 2025
2025
-
[14]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inProc. of CVPR, 2025
2025
-
[15]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He, “π 3: Scalable permutation-equivariant visual geometry learning,”arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang, “Depth anything 3: Recovering the visual space from any views,”arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Continuous 3d perception model with persistent state,
Q. Wang, Y . Zhang, A. Holynski, A. A. Efros, and A. Kanazawa, “Continuous 3d perception model with persistent state,” inProc. of CVPR, 2025, pp. 10 510–10 522
2025
-
[18]
Ttt3r: 3d reconstruction as test-time training
X. Chen, Y . Chen, Y . Xiu, A. Geiger, and A. Chen, “Ttt3r: 3d reconstruction as test-time training,”arXiv preprint arXiv:2509.26645, 2025
-
[19]
InfiniteVGGT: Visual geometry grounded transformer for endless streams
S. Yuan, Y . Yang, X. Yang, X. Zhang, Z. Zhao, L. Zhang, and Z. Zhang, “Infinitevggt: Visual geometry grounded transformer for endless streams,”arXiv preprint arXiv:2601.02281, 2026
-
[20]
Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences,
K. Deng, Z. Ti, J. Xu, J. Yang, and J. Xie, “Vggt-long: Chunk it, loop it, align it–pushing vggt’s limits on kilometer-scale long rgb sequences,” arXiv preprint arXiv:2507.16443, 2025
-
[21]
Laser: Layer-wise scale alignment for training-free streaming 4d reconstruction,
T. Ding, Y . Xie, Y . Liang, M. Chatterjee, P. Miraldo, and H. Jiang, “Laser: Layer-wise scale alignment for training-free streaming 4d reconstruction,” 2026. [Online]. Available: https://arxiv.org/abs/2512. 13680
2026
-
[22]
Y . Shen, Z. Zhang, Y . Qu, X. Zheng, J. Ji, S. Zhang, and L. Cao, “Fastvggt: Training-free acceleration of visual geometry transformer,” arXiv preprint arXiv:2509.02560, 2025
-
[23]
Z. Shu, C. Lin, T. Xie, W. Yin, B. Li, Z. Pu, W. Li, Y . Yao, X. Cao, X. Guo, and X.-X. Long, “Litevggt: Boosting vanilla vggt via geometry-aware cached token merging,” 2025. [Online]. Available: https://arxiv.org/abs/2512.04939
-
[24]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProc. of CVPR, 2024, pp. 20 697– 20 709
2024
-
[25]
Grounding image matching in 3d with mast3r,
V . Leroy, Y . Cabon, and J. Revaud, “Grounding image matching in 3d with mast3r,” inProc. of ECCV. Springer, 2024, pp. 71–91
2024
-
[26]
arXiv preprint arXiv:2507.02863 (2025)
Y . Wu, W. Zheng, J. Zhou, and J. Lu, “Point3r: Streaming 3d reconstruction with explicit spatial pointer memory,” 2025. [Online]. Available: https://arxiv.org/abs/2507.02863
-
[27]
arXiv preprint arXiv:2507.11539 (2025)
D. Zhuo, W. Zheng, J. Guo, Y . Wu, J. Zhou, and J. Lu, “Streaming 4d visual geometry transformer,” 2026. [Online]. Available: https://arxiv.org/abs/2507.11539
-
[28]
Vgg-t 3: Offline feed-forward 3d reconstruction at scale,
S. Elflein, R. Li, S. Agostinho, Z. Gojcic, L. Leal-Taix ´e, Q. Zhou, and A. Osep, “Vgg-t 3: Offline feed-forward 3d reconstruction at scale,”
-
[29]
Available: https://arxiv.org/abs/2602.23361
[Online]. Available: https://arxiv.org/abs/2602.23361
-
[30]
Zipmap: Linear-time stateful 3d reconstruction via test-time training,
H. Jin, R. Wu, T. Zhang, R. Gao, J. T. Barron, N. Snavely, and A. Holynski, “Zipmap: Linear-time stateful 3d reconstruction via test-time training,” 2026. [Online]. Available: https://arxiv.org/abs/2603. 04385
2026
-
[31]
T. Zhang, S. Bi, Y . Hong, K. Zhang, F. Luan, S. Yang, K. Sunkavalli, W. T. Freeman, and H. Tan, “Test-time training done right,” 2025. [Online]. Available: https://arxiv.org/abs/2505.23884
-
[32]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” 2023. [Online]. Available: https://arxiv.org/abs/1706.03762
work page internal anchor Pith review arXiv 2023
-
[33]
FlashAttention: Fast and memory-efficient exact attention with IO-awareness,
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R ´e, “FlashAttention: Fast and memory-efficient exact attention with IO-awareness,” 2022
2022
-
[34]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”Transactions on Machine Learning Research Journal, pp. 1–31, 2024
2024
-
[35]
Vision transformers for dense prediction,
R. Ranftl, A. Bochkovskiy, and V . Koltun, “Vision transformers for dense prediction,” inProc. of CVPR, 2021, pp. 12 179–12 188
2021
-
[36]
Token merging: Your ViT but faster,
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your ViT but faster,” inICLR, 2023
2023
-
[37]
Token merging for fast stable diffusion,
D. Bolya and J. Hoffman, “Token merging for fast stable diffusion,”
-
[38]
Available: https://arxiv.org/abs/2303.17604
[Online]. Available: https://arxiv.org/abs/2303.17604
-
[39]
arXiv preprint arXiv:2602.16284 , year=
A. Zweiger, X. Fu, H. Guo, and Y . Kim, “Fast kv compaction via attention matching,” 2026. [Online]. Available: https://arxiv.org/abs/ 2602.16284
-
[40]
Scene coordinate regression forests for camera relocalization in rgb-d images,
J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgib- bon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” inProc. of CVPR, 2013, pp. 2930–2937
2013
-
[41]
Neural rgb-d surface reconstruction,
D. Azinovi ´c, R. Martin-Brualla, D. B. Goldman, M. Nießner, and J. Thies, “Neural rgb-d surface reconstruction,” inProc. of CVPR, 2022, pp. 6290–6301
2022
-
[42]
A benchmark for the evaluation of rgb-d slam systems,
J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” inProc. of IROS. IEEE, 2012, pp. 573–580
2012
-
[43]
Scannet: Richly-annotated 3d reconstructions of indoor scenes,
A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, “Scannet: Richly-annotated 3d reconstructions of indoor scenes,” inProc. of CVPR, 2017, pp. 5828–5839
2017
-
[44]
A naturalistic open source movie for optical flow evaluation,
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black, “A naturalistic open source movie for optical flow evaluation,” inProc. of ECCV. Springer, 2012, pp. 611–625
2012
-
[45]
Re- fusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals,
E. Palazzolo, J. Behley, P. Lottes, P. Giguere, and C. Stachniss, “Re- fusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals,” inProc. of IROS. IEEE, 2019, pp. 7855–7862
2019
-
[46]
Vision meets robotics: The kitti dataset,
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The kitti dataset,”The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, 2013. Zecheng Tangis currently pursuing the M.S. degree in computer science and technology with Peking University Shenzhen Graduate School, Shen- zhen, China. His research interests incl...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.