Recognition: 2 theorem links
· Lean TheoremRender, Don't Decode: Weight-Space World Models with Latent Structural Disentanglement
Pith reviewed 2026-05-11 01:42 UTC · model grok-4.3
The pith
A world model stores each video state as the weights of a small implicit neural network and renders frames analytically from those weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
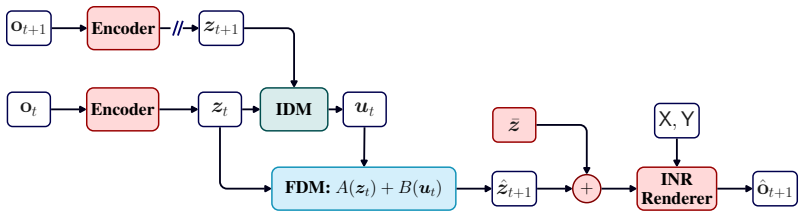
NOVA represents the system state as the weights and biases of an auxiliary coordinate-based implicit neural representation (INR). This structured representation is analytically rendered, which eliminates the decoder bottleneck while conferring compactness, portability, and zero-shot super-resolution. Furthermore, like most latent action models, NOVA can be distilled into a context-dependent video generator via an action-matching objective. Surprisingly, without resorting to auxiliary losses or adversarial objectives, NOVA can disentangle structural scene components such as background, foreground, and inter-frame motion, enabling users to edit either content or dynamics without compromising t
What carries the argument
The INR weight-and-bias vector that serves as the world-model state; it is rendered by direct coordinate-wise evaluation of the implicit network rather than decoded by a separate network.
If this is right
- World models become smaller and portable because the state is a modest set of network weights instead of a full decoder.
- Zero-shot super-resolution follows directly from rendering the same weights at higher coordinate resolution.
- Independent editing of content versus dynamics becomes possible once background, foreground, and motion are disentangled in weight space.
- The same weight states can be distilled into a context-dependent video generator using only an action-matching loss.
- Training and inference fit on a single consumer GPU at approximately 40 million total parameters.
Where Pith is reading between the lines
- The same weight-space encoding could be applied to 3-D scene modeling by replacing 2-D coordinate queries with volumetric ones.
- Disentangled motion weights might serve as editable control signals for physics-based simulators or game engines.
- Because the state size is independent of image resolution, the approach may scale to higher-resolution or longer video sequences without proportional memory growth.
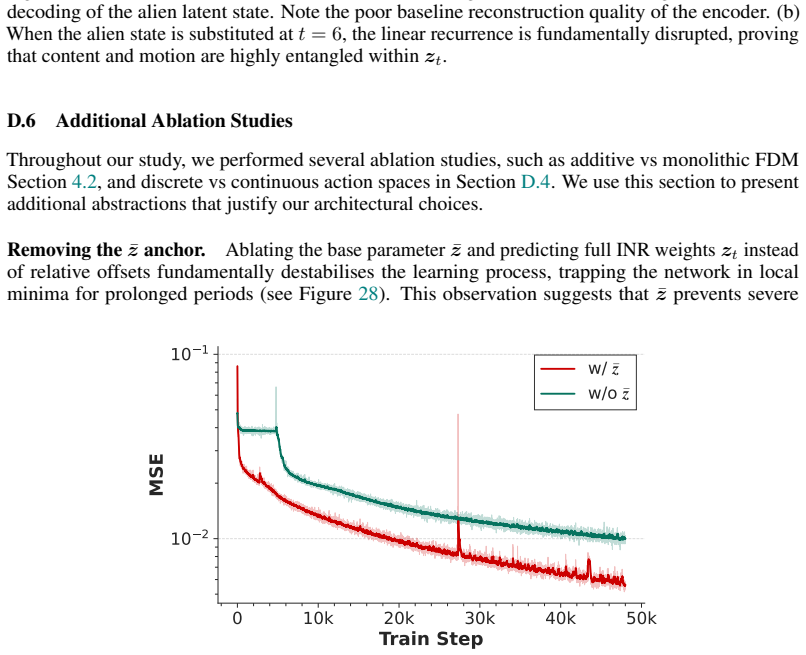
Load-bearing premise
Storing video dynamics inside the weights of a coordinate-based neural representation will capture motion accurately enough for controllable forecasting and will separate scene structure from dynamics without extra supervision.
What would settle it
On a held-out video dataset containing rapid object occlusions or camera motion, the model produces either inaccurate future frames under action control or entangled edits when users attempt to change only the background.
Figures

























read the original abstract
Training world models on vast quantities of unlabelled videos is a critical step toward fully autonomous intelligence. However, the prevailing paradigm of encoding raw pixels into opaque latent spaces and relying on heavy decoders for reconstruction leaves these models computationally expensive and uninterpretable. We address this problem by introducing NOVA, a world modelling framework that represents the system state as the weights and biases of an auxiliary coordinate-based implicit neural representation (INR). This structured representation is analytically rendered, which eliminates the decoder bottleneck while conferring compactness, portability, and zero-shot super-resolution. Furthermore, like most latent action models, NOVA can be distilled into a context-dependent video generator via an action-matching objective. Surprisingly, without resorting to auxiliary losses or adversarial objectives, NOVA can disentangle structural scene components such as background, foreground, and inter-frame motion, enabling users to edit either content or dynamics without compromising the other. We validate our framework on several challenging datasets, achieving strong controllable forecasting while operating on a single consumer GPU at $\sim$40M parameters. Ultimately, structured representations like INRs not only enhance our understanding of latent dynamics but also pave the way for immersive and customisable virtual experiences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NOVA, a world modeling framework that represents system states as the weights and biases of an auxiliary coordinate-based implicit neural representation (INR). This representation is analytically rendered to eliminate decoder bottlenecks, yielding compactness, portability, and zero-shot super-resolution. NOVA supports distillation into a context-dependent video generator via action-matching and, without auxiliary or adversarial losses, achieves unsupervised disentanglement of structural components such as background, foreground, and inter-frame motion. The approach is validated on multiple challenging datasets, delivering strong controllable forecasting at approximately 40M parameters on a single consumer GPU.
Significance. If the empirical claims hold, the work offers a potentially significant advance in efficient and interpretable world models by shifting state representation to INR weight space. The analytical rendering removes a common computational bottleneck, while the emergent disentanglement without extra objectives could enable more editable and customizable video prediction systems. The modest resource footprint further supports practical deployment in autonomous intelligence pipelines.
major comments (2)
- [§4] The central claim of reliable controllable forecasting and clean unsupervised disentanglement rests on the INR weight-space representation capturing video dynamics across datasets. The manuscript should include explicit quantitative metrics (e.g., prediction error, disentanglement scores) and ablations in the experiments section demonstrating that these properties arise from the INR formulation rather than dataset-specific artifacts or implicit regularization.
- [§3.3] The distillation into a video generator via action-matching is presented as straightforward, yet the manuscript must clarify whether this step preserves the claimed disentanglement properties or introduces trade-offs; a direct comparison of editing fidelity before and after distillation would strengthen the portability argument.
minor comments (2)
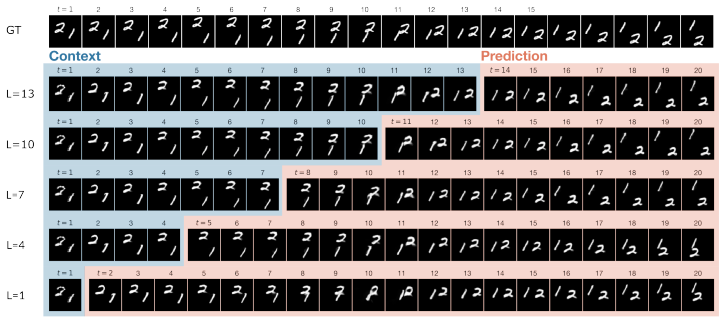
- [§3.1] Notation for the INR coordinate inputs and weight parameterization should be defined more explicitly in the methods to aid reproducibility.
- [Abstract] The abstract and introduction would benefit from naming the specific datasets used and citing the exact performance numbers rather than qualitative descriptors such as 'strong'.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments, which have helped us strengthen the manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: [§4] The central claim of reliable controllable forecasting and clean unsupervised disentanglement rests on the INR weight-space representation capturing video dynamics across datasets. The manuscript should include explicit quantitative metrics (e.g., prediction error, disentanglement scores) and ablations in the experiments section demonstrating that these properties arise from the INR formulation rather than dataset-specific artifacts or implicit regularization.
Authors: We agree that additional quantitative metrics and targeted ablations would further substantiate the claims. In the revised manuscript we have expanded §4 to report explicit prediction error metrics (PSNR, SSIM, LPIPS) for controllable forecasting across all datasets and introduced a disentanglement score that quantifies independent editability (background/foreground/motion) via optical-flow consistency and foreground segmentation overlap. We also include an ablation that replaces the INR weight-space state representation with a conventional latent vector of matched dimensionality while holding all other components fixed. The results show clear degradation in both forecasting accuracy and disentanglement quality, indicating that the observed properties are tied to the INR formulation rather than dataset artifacts or implicit regularization. revision: yes
-
Referee: [§3.3] The distillation into a video generator via action-matching is presented as straightforward, yet the manuscript must clarify whether this step preserves the claimed disentanglement properties or introduces trade-offs; a direct comparison of editing fidelity before and after distillation would strengthen the portability argument.
Authors: We thank the referee for this suggestion. The revised manuscript now includes a dedicated comparison in the experiments section that directly measures editing fidelity before and after distillation. Using the same set of structural edits (background change, foreground motion alteration, etc.), we evaluate both the original INR-based NOVA model and the distilled video generator with perceptual metrics (LPIPS, FID) and consistency checks (optical flow preservation). The results show that the core disentanglement properties are largely retained after distillation, with only modest trade-offs in fine-grained control attributable to the generative approximation. This addition clarifies the portability of the framework while acknowledging the small cost of distillation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents NOVA as a novel construction: system states are stored directly as weights/biases of an auxiliary INR, which is then analytically rendered to bypass decoders. No equations, derivations, or load-bearing steps are visible that reduce this representation, the claimed disentanglement, or the forecasting performance to fitted quantities defined by the same claims or to self-citations. The abstract and description frame the approach as an independent architectural choice whose benefits (compactness, zero-shot super-resolution, unsupervised structural separation) are asserted as empirical outcomes rather than tautological re-statements of inputs. No self-definitional loops, fitted-input predictions, or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coordinate-based implicit neural representations can faithfully encode and render dynamic scene states from their weights alone.
invented entities (1)
-
NOVA framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
represents the system state as the weights and biases of an auxiliary coordinate-based implicit neural representation (INR)... additive formulation that cleanly isolates these properties... A(zt)+B(ut)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-level semantic ontology... background (¯z), foreground content (zt), motion (ut)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lamo: A latent motion world model for long-horizon prediction
Azwar Abdulsalam, Christopher Hoang, and Mengye Ren. Lamo: A latent motion world model for long-horizon prediction. InICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling,
work page 2026
-
[2]
Loick Chambon, Paul Couairon, Eloi Zablocki, Alexandre Boulch, Nicolas Thome, and Matthieu Cord. Naf: Zero-shot feature upsampling via neighborhood attention filtering.arXiv preprint arXiv:2511.18452,
-
[3]
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
10 Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation.arXiv preprint arXiv:1406.1078,
work page internal anchor Pith review arXiv
-
[4]
Emilien Dupont, Hyunjik Kim, SM Eslami, Danilo Rezende, and Dan Rosenbaum. From data to functa: Your data point is a function and you can treat it like one.arXiv preprint arXiv:2201.12204,
-
[5]
Amer Essakine, Yanqi Cheng, Chun-Wun Cheng, Lipei Zhang, Zhongying Deng, Lei Zhu, Carola-Bibiane Schönlieb, and Angelica I Aviles-Rivero. Where do we stand with implicit neural representations? a technical and performance survey.arXiv preprint arXiv:2411.03688,
-
[6]
Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938,
-
[7]
arXiv preprint arXiv:2601.05230 (2026)
Quentin Garrido, Tushar Nagarajan, Basile Terver, Nicolas Ballas, Yann LeCun, and Michael Rabbat. Learning latent action world models in the wild.arXiv preprint arXiv:2601.05230,
-
[8]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review arXiv
-
[9]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122,
work page internal anchor Pith review arXiv
-
[10]
Pre-trained video generative models as world simulators
URL https: //openreview.net/forum?id=S1lOTC4tDS. Haoran He, Yang Zhang, Liang Lin, Zhongwen Xu, and Ling Pan. Pre-trained video generative models as world simulators.arXiv preprint arXiv:2502.07825,
-
[11]
Hans Hersbach, Bill Bell, Paul Berrisford, Shoji Hirahara, András Horányi, Joaquín Muñoz-Sabater, Julien Nicolas, Carole Peubey, Raluca Radu, Dinand Schepers, et al. The era5 global reanalysis.Quarterly journal of the royal meteorological society, 146(730):1999–2049,
work page 1999
-
[12]
How far is video generation from world model: A physical law perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385,
-
[13]
11 Patrick Kidger and Cristian Garcia. Equinox: neural networks in JAX via callable PyTrees and filtered transformations.Differentiable Programming workshop at Neural Information Processing Systems 2021,
work page 2021
-
[14]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Ruikun Li, Jiazhen Liu, Huandong Wang, Qingmin Liao, and Yong Li. Weightflow: Learning stochastic dynamics via evolving weight of neural network.arXiv preprint arXiv:2508.00451, 2025a. Xinqing Li, Xin He, Le Zhang, Min Wu, Xiaoli Li, and Yun Liu. A comprehensive survey on world models for embodied ai.arXiv preprint arXiv:2510.16732, 2025b. Zhixuan Lin, Yi...
-
[16]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.https://arxiv.org/pdf/2603.19312v1,
work page internal anchor Pith review arXiv
-
[17]
Transformers are sample efficient world models.arXiv preprint arXiv:2209.00588, 2022
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models.arXiv preprint arXiv:2209.00588,
-
[18]
Christopher Rackauckas, Yingbo Ma, Julius Martensen, Collin Warner, Kirill Zubov, Rohit Supekar, Dominic Skinner, Ali Ramadhan, and Alan Edelman. Universal differential equations for scientific machine learning. arXiv preprint arXiv:2001.04385,
-
[19]
Learning to act without actions.arXiv preprint arXiv:2312.10812, 2023
Dominik Schmidt and Minqi Jiang. Learning to act without actions.arXiv preprint arXiv:2312.10812,
-
[20]
Towards scalable and versatile weight space learning.arXiv preprint arXiv:2406.09997,
Konstantin Schürholt, Michael W Mahoney, and Damian Borth. Towards scalable and versatile weight space learning.arXiv preprint arXiv:2406.09997,
-
[21]
Vincent Sitzmann, Julien NP Martel, Alexander W Bergman, David B Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions.arXiv preprint arXiv:2006.09661,
-
[22]
A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
URLhttps://arxiv.org/abs/2602.03604. SS Vallender. Calculation of the wasserstein distance between probability distributions on the line.Theory of Probability & Its Applications, 18(4):784–786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Chain of World: World model thinking in latent motion.arXiv preprint arXiv:2603.03195, 2026
Fuxiang Yang, Donglin Di, Lulu Tang, Xuancheng Zhang, Lei Fan, Hao Li, Chen Wei, Tonghua Su, and Baorui Ma. Chain of world: World model thinking in latent motion.arXiv preprint arXiv:2603.03195,
-
[24]
Latent Action Pretraining from Videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758,
-
[25]
What do latent action models actually learn?arXiv preprint arXiv:2506.15691, 2025
Chuheng Zhang, Tim Pearce, Pushi Zhang, Kaixin Wang, Xiaoyu Chen, Wei Shen, Li Zhao, and Jiang Bian. What do latent action models actually learn?arXiv preprint arXiv:2506.15691, 2025a. Xingyuan Zhang, Philip Becker-Ehmck, Patrick van der Smagt, and Maximilian Karl. Overcoming knowledge barriers: Online imitation learning from visual observation with pretr...
-
[26]
16 B.2 ARCHITECTURE& HYPERPARAMETERS
13 Render, Don’t Decode: Weight-Space World Models with Latent Structural Disentanglement —Supplementary Material— A RELATEDWORK15 B METHODOLOGICALDETAILS16 B.1 MOTIVATION: INRS ANDTHEDECODERBOTTLENECK. . . . . . . . . . . . . . . 16 B.2 ARCHITECTURE& HYPERPARAMETERS. . . . . . . . . . . . . . . . . . . . . . . . 17 B.3 CONTEXT-CONDITIONEDVIDEOGENERATION....
work page 2018
-
[27]
infer these from consecutive observations. LAPO [Schmidt and Jiang, 2023] and LAPA [Ye et al., 2024] learn inverse dynamics models that extract latent actions bridging consecutive states. Moto [Chen et al., 2025] and AdaWorld [Gao et al., 2025] incorporate such models into robot learning pipelines. Garrido et al
work page 2023
-
[28]
demonstrate that continuous latent actions, although sparse and noisy, capture for in-the-wild actions learning, whereas discrete codebooks struggle. For deployment without future frames, RSSMs [Hafner et al., 2020], IRIS [Micheli et al., 2022], and CoWVLA [Yang et al., 2026] use autoregressive models to generate actions. Our GCM follows this principle us...
work page 2020
-
[29]
introduce the term “functa”, showing that meta-learned [Zintgraf et al., 2019; Nzoyem et al., 2025] INR weight vectors can serve as data representations for downstream tasks. In the 3D domain, 3D Gaussian Splatting [Kerbl et al., 2023] and work such as GWM [Lu et al., 2025] exploitstructuredspatial representations for world modelling. Our work extends thi...
work page 2019
-
[30]
We set the values corresponding tou t as0in the input sequence
that processes a sequence of concatenated {zτ ,u τ }1≤τ≤t pairs, with learned positional embeddings. We set the values corresponding tou t as0in the input sequence. 9Note that the output layer is included in the layer count; meaning that 6 layers corresponds to a depth of 5, following Equinox’s convention [Kidger and Garcia, 2021]. 17 (e) Forward Dynamics...
work page 2021
-
[31]
(1) Moving MNIST[Srivastava et al., 2015] assesses deterministic spatial-temporal forecasting and boundary sharpness over time; sequences (T=
work page 2015
-
[32]
We use 8,000 training and 2,000 testing sequences
show two digits bouncing on a64×64 grayscale canvas. We use 8,000 training and 2,000 testing sequences. (2) PhyWorld 30K[Kang et al., 2024] evaluates modelling of complex, non-linear multi-body physical interactions. Rendered at 128×128 RGB resolution, we use exactly 26,066 training sequences and 1,635 testing sequences containing both in-distribution and...
work page 2024
-
[33]
Vector” describes the dimension of one-dimension latent vectors, while “Submodel
We implement the Standard WM in similar conditions toNOV A, even matching its batch sizes. As for the encoder-decoder-free LAPO [Schmidt and Jiang, 2023], we adapt the code from its official repos- itory, readily available and downloaded fromhttps://github.com/schmidtdominik/LAPO. Table 5: Parameter count across datasets. “Vector” describes the dimension ...
work page 2023
-
[34]
D Additional Results D.1 Latent Structural Disentanglement Background absorption by ¯z.In all Moving MNIST sequences, the background is uniformly dark. As seen in Figure 11, we observe that ¯z naturally absorbs this, indicating that the per-frame offsets zt have near-zero contribution to background pixels. The utility of ¯z extends beyond structural disen...
work page 2026
-
[35]
By framing the temporal predictions as small residuals zt relative to ¯z, analogous to residual learning [He et al., 2016], we stabilise optimisation and prevent the network from collapsing into local minima. Consequently, even in complex scenes where background disentanglement is challenging, the residual anchoring provided by ¯zmay remain beneficial for...
work page 2016
-
[36]
Figure 14 shows qualitative video forecasting results on Moving MNIST, conditioned on 10 initial frames and rolling out for 10 predicted frames. NOV A produces sharp predictions without checkerboard artefacts, a common failure mode in transposed- CNN decoders. Forecasting over longer horizons Tinf = 1000 Long-horizon generation is a potent test of identit...
work page 2024
-
[37]
Table 7: Long-horizon identity-consistency metrics. We report the median, min, and max over T= 1000frames and over two sequences{54,57}, limited as such for computational reasons. Metric Method Median Min Max W1 ↓Standard WM 0.0780 0.0462 0.1308 LAPO 0.0110 0.0037 0.0847 NOV A 0.1222 0.0258 0.6138 JSD↓Standard WM 0.4255 0.3313 0.4966 LAPO 0.0771 0.0703 0....
work page 1982
-
[38]
from in-band ones at the training sample locations
Injected alien collision dynamics (actions) are the same, leading to unphysical behaviours. from in-band ones at the training sample locations. 12 The loss cannot differentiate them, so the corresponding weights are optimised against noise and produce artefacts at super-resolution. Theorem 1(Nyquist–Shannon Sampling Theorem (Informal)).If a continuous fun...
work page 2020
-
[39]
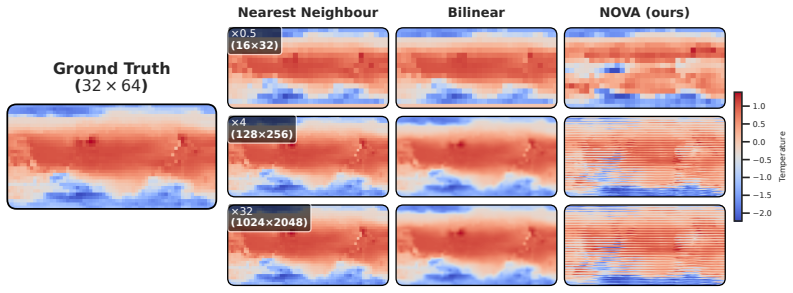
×0.5 (16×32) Nearest Neighbour Bilinear NOVA (ours) ×4 (128×256) ×32 (1024×2048) −2.0 −1.5 −1.0 −0.5 0.0 0.5 1.0 T emperature Figure 22:Zero-shot super-resolution on WeatherBench without frequency masking.Compared to Figure 7, horizontal bars are visible, indicating spectral aliasing along the vertical axis. Figure 23:Latent action dimensions on MiniGrid....
work page 2048
-
[40]
shares several similarities with contemporary architectures, most notably Weight-space Adaptive Recurrent Prediction (WARP) [Nzoyem et al., 2026]. Both frame- works view the latent state of the dynamic system not as a standard feature vector, but as the weights and biases of an INR. In WARP, this is governed by a continuous linear recurrence defined as zt...
work page 2026
-
[41]
Following the processing of the initial 3 frames and autoregressive generation after those, we intervened at t= 6 by replacing the naturally evolved statez t with the latent encoding of an alien frame. However, the intervention sequence (Figure 27b) demonstrates a catastrophic failure, as W ARP allows the alien injection to fundamentally corrupt the forwa...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.