Recognition: unknown
MANTRA: Synthesizing SMT-Validated Compliance Benchmarks for Tool-Using LLM Agents
Pith reviewed 2026-05-08 10:13 UTC · model grok-4.3
The pith
MANTRA automatically synthesizes SMT-validated compliance benchmarks from natural-language manuals for tool-using LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
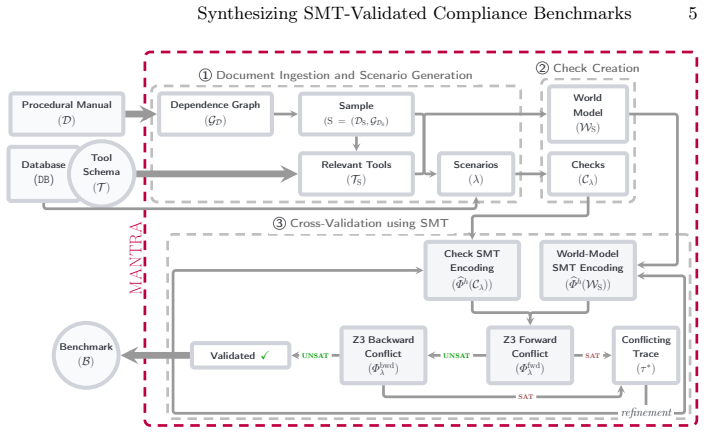
MANTRA independently generates a symbolic world model that captures the procedural dependencies in a manual and a set of trace-level compliance checks for a task. These are validated for consistency using SMT solving, with a structured repair loop to resolve inconsistencies that only requires human intervention as a fallback. The framework also provides a tunable notion of task complexity to derive challenging tasks. This approach supports arbitrary domains and long manuals, yielding benchmarks with richer compliance checks and stronger constraint enforcement than existing ones.
What carries the argument
The MANTRA framework, which generates and SMT-validates symbolic world models and trace-level compliance checks from natural-language manuals and tool schemas.
If this is right
- Benchmarks scale to manuals over 50 pages with minimal human effort across arbitrary domains.
- Generated compliance checks enforce richer and stronger constraints than those in existing benchmarks.
- Check granularity supports detailed debugging of specific agent failure modes.
- Tunable task complexity allows automatic derivation of challenging evaluation tasks.
- The method produces formally validated, machine-checkable benchmarks for tool-using agents.
Where Pith is reading between the lines
- The synthesis process could enable automatic regeneration of benchmarks when manuals are updated in deployed systems.
- Granular checks might be used to target agent training or fine-tuning on frequent violation patterns.
- This approach may extend to verifying compliance in other AI systems that execute sequences of actions from natural-language instructions.
Load-bearing premise
Natural-language manuals can be translated into symbolic world models and compliance checks that an SMT solver can validate as consistent without losing critical procedural meaning or introducing false constraints.
What would settle it
A manual and agent execution trace where the SMT-validated checks either incorrectly flag a compliant trace as non-compliant or miss a clear violation that a human expert identifies in the original manual.
Figures

read the original abstract
Tool-using large language model (LLM) agents are increasingly deployed in settings where their reliable behavior is governed by strict procedural manuals. Ensuring that such agents comply with the rules from these manuals is challenging, as they are typically written for humans in natural language while agent behavior manifests as an execution trace of tool calls. Existing evaluations of LLM agents rely on manually constructed benchmarks or LLM-based judges, which either do not scale or lack reliability for complex, long-horizon manuals. To overcome these limitations, we present MANTRA, a framework for automatically synthesizing machine-checkable compliance benchmarks from natural-language manuals and tool schemas. MANTRA independently generates (i) a symbolic world model capturing procedural dependencies, and (ii) a set of trace-level compliance checks for a given task, and validates their consistency using SMT solving. A structured repair loop resolves inconsistencies, requiring human intervention only as a fallback. %This yields benchmarks that are formally validated. Importantly, MANTRA supports arbitrary domains and long procedural manuals, and provides a tunable notion of task complexity which is utilized to automatically derive challenging tasks accompanying compliance checks. Using MANTRA, we build a new benchmark suite with 285 tasks across 6 domains scaling to 50+ page manuals with minimal human effort. Empirically, we show that the compliance checks are richer with stronger constraint enforcement compared to existing benchmarks. Additionally, the granularity of the checks can be used for debugging the agents' failure modes. These results demonstrate that combining automated benchmark generation with formally grounded validation methods enables scalable and reliable benchmarking of tool-using agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
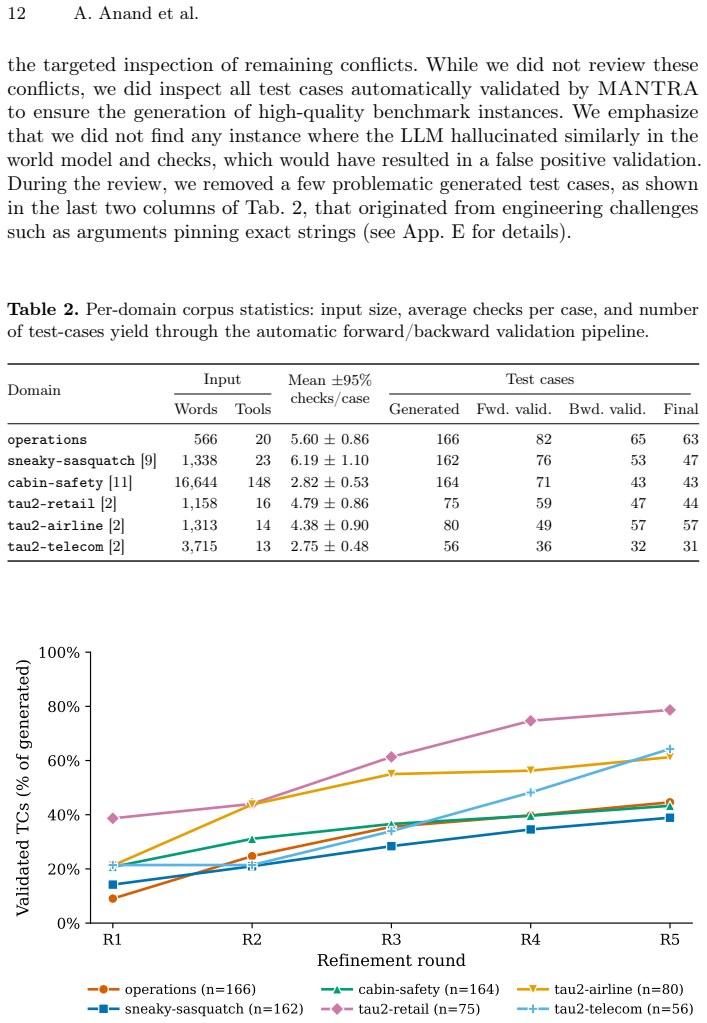
Summary. The manuscript introduces MANTRA, a framework for automatically synthesizing machine-checkable compliance benchmarks for tool-using LLM agents from natural-language procedural manuals and tool schemas. It independently generates a symbolic world model capturing procedural dependencies and a set of trace-level compliance checks, validates their mutual consistency via SMT solving, and applies a structured repair loop (with human fallback) to resolve inconsistencies. The authors report constructing a new benchmark suite of 285 tasks across 6 domains from manuals scaling to 50+ pages with minimal human effort, claiming richer compliance checks with stronger constraint enforcement than existing benchmarks, plus utility for debugging agent failure modes.
Significance. If the translation from natural-language manuals to symbolic models preserves procedural semantics, this approach could meaningfully advance scalable and reliable evaluation of LLM agents in procedural compliance settings, reducing dependence on manual benchmark construction or unreliable LLM judges. The use of SMT for internal consistency validation and the reported scale (285 tasks, long manuals) represent concrete strengths in formal grounding and automation.
major comments (3)
- [Abstract and framework description] The SMT validation step (described in the abstract and framework overview) confirms only that the generated symbolic world model and compliance checks are mutually consistent; it provides no independent check that the natural-language-to-symbolic translation faithfully preserves the original manual's semantics, edge cases, implicit constraints, or long-range dependencies. This assumption is load-bearing for all claims of richer checks and stronger enforcement, as formally consistent but semantically distorted benchmarks would not support the stated advantages over existing methods.
- [Abstract and evaluation section] The empirical claim that 'the compliance checks are richer with stronger constraint enforcement compared to existing benchmarks' (abstract) is presented without quantitative metrics, comparison methodology, error analysis, baseline details, or statistical support. This absence makes it impossible to evaluate the strength or reproducibility of the reported improvements.
- [Benchmark construction and results] The construction of 285 tasks with tunable complexity and scaling to 50+ page manuals (abstract) lacks discussion of how translation fidelity or task realism is assessed for long documents, nor any analysis of generation failure rates or human intervention frequency in the repair loop.
minor comments (1)
- [Framework details] The description of trace-level compliance checks would benefit from additional concrete examples or pseudocode to clarify their relation to tool-call sequences and how granularity aids debugging.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, acknowledging where the manuscript can be strengthened and outlining planned revisions.
read point-by-point responses
-
Referee: The SMT validation step (described in the abstract and framework overview) confirms only that the generated symbolic world model and compliance checks are mutually consistent; it provides no independent check that the natural-language-to-symbolic translation faithfully preserves the original manual's semantics, edge cases, implicit constraints, or long-range dependencies.
Authors: We agree that the SMT validation is limited to mutual consistency between the symbolic world model and the compliance checks, and does not provide an independent semantic fidelity check against the original natural-language manual. The framework relies on the generation process (guided by tool schemas and manual text) to capture procedural semantics, with the repair loop serving as a mechanism to resolve detected issues, including those potentially stemming from translation inaccuracies. We will revise the framework description and abstract to explicitly delineate the scope of SMT validation, add discussion of semantic preservation assumptions, and include examples of human fallback interventions that addressed potential fidelity issues. revision: yes
-
Referee: The empirical claim that 'the compliance checks are richer with stronger constraint enforcement compared to existing benchmarks' (abstract) is presented without quantitative metrics, comparison methodology, error analysis, baseline details, or statistical support.
Authors: We acknowledge that the abstract's phrasing of this claim would benefit from greater specificity and supporting details to enable evaluation of its strength. The evaluation section provides comparisons across domains, but we agree additional quantitative elements are needed. We will revise the abstract and evaluation section to include explicit metrics (such as average constraints per task and enforcement coverage), a clear comparison methodology against baselines, error analysis, baseline details, and any available statistical support from the experiments. revision: yes
-
Referee: The construction of 285 tasks with tunable complexity and scaling to 50+ page manuals (abstract) lacks discussion of how translation fidelity or task realism is assessed for long documents, nor any analysis of generation failure rates or human intervention frequency in the repair loop.
Authors: We agree that greater transparency on these practical aspects of benchmark construction would improve the manuscript, particularly for long documents. We will add a new subsection to the benchmark construction and results section that reports on translation fidelity assessment methods (including spot-checks and human review for long manuals), task realism validation, observed generation failure rates, and quantitative statistics on human intervention frequency in the repair loop across the six domains and 285 tasks. revision: yes
Circularity Check
No circularity detected; pipeline uses external SMT solver for independent consistency validation
full rationale
The paper describes an automated pipeline that generates a symbolic world model and trace-level compliance checks from natural-language manuals and tool schemas, then applies an external SMT solver to verify mutual consistency before a repair loop. This does not reduce any central claim to a self-definition, fitted parameter renamed as prediction, or self-citation chain, as the SMT step is an independent external tool and the generation process is presented as operating on the input manuals without tautological feedback into the outputs. No load-bearing uniqueness theorems or ansatzes from prior self-work are invoked, and empirical comparisons to existing benchmarks are separate from the synthesis mechanism. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Natural language manuals can be translated into symbolic world models that preserve all relevant procedural dependencies for compliance checking.
Reference graph
Works this paper leans on
-
[1]
MIT press (2008)
Baier, C., Katoen, J.P.: Principles of model checking. MIT press (2008)
2008
-
[2]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Barres, V., Dong, H., Ray, S., Si, X., Narasimhan, K.: tau2-bench: Evaluating con- versational agents in a dual-control environment. arXiv preprint arXiv:2506.07982 (2025)
work page internal anchor Pith review arXiv 2025
-
[3]
Barrett, C., Tinelli, C.: Satisfiability Modulo Theories, pp. 305–343. Springer International Publishing, Cham (2018)
2018
-
[4]
arXiv preprint arXiv:2511.09008 (2025)
Bayless, S., Buliani, S., Cassel, D., Cook, B., Clough, D., Delmas, R., Diallo, N., Erata, F., Feng, N., Giannakopoulou, D., et al.: A neurosymbolic approach to natural language formalization and verification. arXiv preprint arXiv:2511.09008 (2025)
-
[5]
Cai, Y., Hou, Z., Sanan, D., Luan, X., Lin, Y., Sun, J., Dong, J.S.: Automated program refinement: Guide and verify code large language model with refinement calculus. Proc. ACM Program. Lang.9(POPL) (jan 2025).https://doi.org/10. 1145/3704905
2025
-
[6]
arXiv preprint arXiv:2409.08069 (2024)
Chen, A., Ge, X., Fu, Z., Xiao, Y., Chen, J.: Travelagent: An ai assistant for personalized travel planning. arXiv preprint arXiv:2409.08069 (2024)
-
[7]
Evaluating Large Language Models Trained on Code
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H.P.d.O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al.: Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review arXiv 2021
-
[8]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge,D.,Trinh,H.,Cheng,N.,Bradley,J.,Chao,A.,Mody,A.,Truitt,S.,Metropoli- tansky, D., Ness, R.O., Larson, J.: From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130 (2024)
work page internal anchor Pith review arXiv 2024
-
[9]
https://sneaky-sasquatch.fandom.com/ wiki/Doctor(2026), accessed: 2026-05-05
Fandom:Sneakysasquatchwiki-doctor. https://sneaky-sasquatch.fandom.com/ wiki/Doctor(2026), accessed: 2026-05-05
2026
-
[10]
arXiv preprint arXiv:2511.04662 (2025)
Feng, Y., Weir, N., Bostrom, K., Bayless, S., Cassel, D., Chaudhary, S., Kiesl-Reiter, B., Rangwala, H.: Vericot: Neuro-symbolic chain-of-thought validation via logical consistency checks. arXiv preprint arXiv:2511.04662 (2025)
-
[11]
Flight Safety Foundation: Cabin safety compendium.https://flightsafety.org/ wp-content/uploads/2016/09/cabin_safety_compendium.pdf (2016), accessed: 2026-05-05
2016
-
[12]
Cell 187(22), 6125–6151 (2024)
Gao, S., Fang, A., Huang, Y., Giunchiglia, V., Noori, A., Schwarz, J.R., Ektefaie, Y., Kondic, J., Zitnik, M.: Empowering biomedical discovery with ai agents. Cell 187(22), 6125–6151 (2024)
2024
-
[13]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., Wang, H., et al.: Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.109972(1), 32 (2023)
work page internal anchor Pith review arXiv 2023
-
[14]
In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Hao, Y., Chen, Y., Zhang, Y., Fan, C.: Large language models can solve real- world planning rigorously with formal verification tools. In: Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 3434–3483 (2025)
2025
-
[15]
Huang, D., Zhang, J.M., Harman, M., Zhang, Q., Du, M., Ng, S.K.: Benchmarking llms for unit test generation from real-world functions. ACM Trans. Softw. Eng. Methodol. (mar 2026).https://doi.org/10.1145/3805043, just Accepted
-
[16]
In: The Twelfth International Conference on Learning Representations (2024)
Huang, Y., Shi, J., Li, Y., Fan, C., Wu, S., Zhang, Q., Liu, Y., Zhou, P., Wan, Y., Gong, N.Z., Sun, L.: Metatool benchmark for large language models: Deciding whether to use tools and which to use. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[17]
arXiv preprint arXiv:2501.07913 (2025) 16 A
Kolt, N.: Governing ai agents. arXiv preprint arXiv:2501.07913 (2025) 16 A. Anand et al
-
[18]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026)
Lee, H., Zhang, Z., Lu, H., ZHANG, L.: SEC-bench: Automated benchmarking of LLM agents on real-world software security tasks. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2026)
2026
-
[19]
Intellagent: A multi-agent framework for evaluating conversational ai systems
Levi, E., Kadar, I.: Intellagent: A multi-agent framework for evaluating conversa- tional ai systems. arXiv preprint arXiv:2501.11067 (2025)
-
[20]
API-bank: A comprehensive benchmark for tool-augmented LLMs
Li, M., Zhao, Y., Yu, B., Song, F., Li, H., Yu, H., Li, Z., Huang, F., Li, Y.: API- bank: A comprehensive benchmark for tool-augmented LLMs. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 3102–3116. Association for Computational Linguistics, Singapore (Dec 2023). https://doi.org/10.18653/v1/2023.emnlp-main.187
-
[21]
arXiv e-prints pp
Li, Z., Huang, S., Wang, J., Zhang, N., Antoniades, A., Hua, W., Zhu, K., Zeng, S., Wang, W.Y., Yan, X.: Agentorca: A dual-system framework to evaluate language agents on operational routine and constraint adherence. arXiv e-prints pp. arXiv– 2503 (2025)
2025
-
[22]
Advances in neural information processing systems37, 74325–74362 (2024)
Ma, C., Zhang, J., Zhu, Z., Yang, C., Yang, Y., Jin, Y., Lan, Z., Kong, L., He, J.: Agentboard: An analytical evaluation board of multi-turn llm agents. Advances in neural information processing systems37, 74325–74362 (2024)
2024
-
[23]
Evaluation and benchmark- ing of llm agents: A survey
Mohammadi, M., Li, Y., Lo, J., Yip, W.: Evaluation and benchmarking of llm agents: A survey. In: Proceedings of the 31st ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining V.2. p. 6129–6139. KDD ’25, Association for Computing Ma- chinery, New York, NY, USA (2025).https://doi.org/10.1145/3711896.3736570
-
[24]
Nature Biomedical Engineering9(4), 432–438 (2025)
Moritz, M., Topol, E., Rajpurkar, P.: Coordinated ai agents for advancing healthcare. Nature Biomedical Engineering9(4), 432–438 (2025)
2025
-
[25]
In: Tools and Algorithms for the Construction and Analysis of Systems
de Moura, L., Bjørner, N.: Z3: An efficient smt solver. In: Tools and Algorithms for the Construction and Analysis of Systems. pp. 337–340. Springer Berlin Heidelberg, Berlin, Heidelberg (2008)
2008
-
[26]
arXiv preprint arXiv:2506.08119 (2025)
Nandi, S., Datta, A., Vichare, N., Bhattacharya, I., Raja, H., Xu, J., Ray, S., Carenini, G., Srivastava, A., Chan, A., et al.: Sop-bench: Complex industrial sops for evaluating llm agents. arXiv preprint arXiv:2506.08119 (2025)
-
[27]
International Journal of Frontiers in Science and Technology Research 8(2), 001–015 (2025)
Ozman, F.M.: Systematic literature review on the rise of agentic ai in enterprise operations. International Journal of Frontiers in Science and Technology Research 8(2), 001–015 (2025)
2025
-
[28]
In: Find- ings of the Association for Computational Linguistics: EMNLP 2023
Pan, L., Albalak, A., Wang, X., Wang, W.: Logic-LM: Empowering large lan- guage models with symbolic solvers for faithful logical reasoning. In: Find- ings of the Association for Computational Linguistics: EMNLP 2023. pp. 3806–
2023
-
[29]
Association for Computational Linguistics, Singapore (Dec 2023).https: //doi.org/10.18653/v1/2023.findings-emnlp.248
-
[30]
In: Forty-second International Conference on Machine Learning (2025)
Patil, S.G., Mao, H., Yan, F., Ji, C.C.J., Suresh, V., Stoica, I., Gonzalez, J.E.: The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[31]
Pysklo, H.M., Zhuravel, A., Watson, P.D.: Agent-diff: Benchmarking llm agents on enterprise api tasks via code execution with state-diff-based evaluation. arXiv preprint arXiv:2602.11224 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2026)
Qi, Y., Peng, H., Wang, X., Xin, A., Liu, Y., Xu, B., Hou, L., Li, J.: AGENTIF: Benchmarking large language models instruction following ability in agentic sce- narios. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2026)
2026
-
[33]
In: The Twelfth International Conference on Learning Representations (2024)
Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., Zhao, S., Hong, L., Tian, R., Xie, R., Zhou, J., Gerstein, M., dahai li, Liu, Synthesizing SMT-Validated Compliance Benchmarks 17 Z., Sun, M.: ToolLLM: Facilitating large language models to master 16000+ real- world APIs. In: The Twelfth International Conference o...
2024
-
[34]
In: Proceedings of the AAAI conference on artificial intelligence
Reddy, C.K., Shojaee, P.: Towards scientific discovery with generative ai: Progress, opportunities, and challenges. In: Proceedings of the AAAI conference on artificial intelligence. vol. 39, pp. 28601–28609 (2025)
2025
-
[35]
VERGE: Formal Refinement and Guidance Engine for Verifiable LLM Reasoning
Singh, V., Cassel, D., Weir, N., Feng, N., Bayless, S.: Verge: Formal refinement and guidance engine for verifiable llm reasoning. arXiv preprint arXiv:2601.20055 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Strands Labs: Strands agents.https://github.com/strands-agents (2026), ac- cessed: 2026-05-05
2026
-
[37]
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
Sun, Q., Liu, Z., Ma, C., Ding, Z., Xu, F., Yin, Z., Zhao, H., Wu, Z., Cheng, K., Liu, Z., et al.: Scienceboard: Evaluating multimodal autonomous agents in realistic scientific workflows. arXiv preprint arXiv:2505.19897 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
In: Forty-second International Conference on Machine Learning (2025)
Vergopoulos, K., Mueller, M.N., Vechev, M.: Automated benchmark generation for repository-level coding tasks. In: Forty-second International Conference on Machine Learning (2025)
2025
-
[39]
Nature620(7972), 47–60 (2023)
Wang, H., Fu, T., Du, Y., Gao, W., Huang, K., Liu, Z., Chandak, P., Liu, S., Van Katwyk, P., Deac, A., et al.: Scientific discovery in the age of artificial intelli- gence. Nature620(7972), 47–60 (2023)
2023
-
[40]
In: The Fourteenth International Conference on Learning Representations (2026)
Wang, Z., Chang, Q., Patel, H., Biju, S., Wu, C.E., Liu, Q., Ding, A., Rezazadeh, A., Shah, A., Bao, Y., Siow, E.: MCP-bench: Benchmarking tool-using LLM agents with complex real-world tasks via MCP servers. In: The Fourteenth International Conference on Learning Representations (2026)
2026
-
[41]
In: The Thirteenth International Conference on Learning Representations (2025)
White, C., Dooley, S., Roberts, M., Pal, A., Feuer, B., Jain, S., Shwartz-Ziv, R., Jain, N., Saifullah, K., Dey, S., Shubh-Agrawal, Sandha, S.S., Naidu, S.V., Hegde, C., LeCun, Y., Goldstein, T., Neiswanger, W., Goldblum, M.: Livebench: A chal- lenging, contamination-limited LLM benchmark. In: The Thirteenth International Conference on Learning Representa...
2025
-
[42]
Faithful logical reasoning via symbolic chain-of-thought , url =
Xu, J., Fei, H., Pan, L., Liu, Q., Lee, M.L., Hsu, W.: Faithful logical reasoning via symbolic chain-of-thought. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 13326– 13365. Association for Computational Linguistics, Bangkok, Thailand (Aug 2024). https://doi.org/10.18653/v1/2024.acl...
-
[43]
Advances in Neural Information Processing Systems35, 20744–20757 (2022)
Yao, S., Chen, H., Yang, J., Narasimhan, K.: Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems35, 20744–20757 (2022)
2022
-
[44]
In: The Thirteenth International Conference on Learning Representations (2025)
Yao, S., Shinn, N., Razavi, P., Narasimhan, K.R.: tau-bench: A benchmark for tool-agent-user interaction in real-world domains. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[45]
Enterprise Information Systems16(4), 668–720 (2022)
Zdravković, M., Panetto, H., Weichhart, G.: Ai-enabled enterprise information systems for manufacturing. Enterprise Information Systems16(4), 668–720 (2022)
2022
-
[46]
arXiv preprint arXiv:2412.06512 (2024)
Zhang, Y., Cai, Y., Zuo, X., Luan, X., Wang, K., Hou, Z., Zhang, Y., Wei, Z., Sun, M., Sun, J., et al.: The fusion of large language models and formal methods for trustworthy ai agents: A roadmap. arXiv preprint arXiv:2412.06512 (2024)
-
[47]
In: The Fourteenth International Conference on Learning Representations (2026) 18 A
Zhou, C., Liu, A., Deng, Y., Zeng, Z., Zhang, T., Zhu, H., Cai, J., Mao, Y., Zhang, C., Tan, L., ZiyanXU, Zhai, B., HengyiLIu, Zhu, S., Zhou, W., Lian, F.: Autocodebench: Large language models are automatic code benchmark generators. In: The Fourteenth International Conference on Learning Representations (2026) 18 A. Anand et al
2026
-
[48]
In: The Twelfth International Conference on Learning Representations (2024)
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., Neubig, G.: Webarena: A realistic web environment for building autonomous agents. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[49]
SSC” Conditional Rule / 4.2. Delivery Requirements / 3.2. The “Over-Budget
Zwerdling, N., Boaz, D., Rabinovich, E., Uziel, G., Amid, D., Anaby Tavor, A.: Towards enforcing company policy adherence in agentic workflows. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. pp. 595–606. Association for Computational Linguistics, Suzhou (China) (Nov 2025).https://doi.org/10.1865...
-
[50]
Urgent Business Need: Q2 board presentation
Travel & Expense Branching Logic / 5. Compliance & Termination States / Global Operations & Procurement Standard Operating Procedure (SOP) v.4.2 / 4. Hardware Procurement & Logistics Please book GlobalGate trip GGT-55102 from Chicago to Toronto as a business-class flight for 2 days. The flight is 5 hours 40 minutes, the daily budget is $220, and the reaso...
-
[51]
SSC” Conditional Rule / 3.1. Regional Overrides / 3.2. The “Over-Budget
Compliance & Termination States / 4.1. Inventory Check Logic Please arrange 2 HelioView 32Q Monitor units for Dana Voss and deliver them to her residence at 1842 Cedar Lane, Ann Arbor, MI 48104. The total quoted value is $2040, and the request number is HWR-2026-118. Synthesizing SMT-Validated Compliance Benchmarks 35 Table 3: Sample scenarios across samp...
2040
-
[52]
Compliance & Termination States / Global Operations & Procurement Standard Operating Procedure (SOP) v.4.2 / 4
Travel & Expense Branching Logic / 5. Compliance & Termination States / Global Operations & Procurement Standard Operating Procedure (SOP) v.4.2 / 4. Hardware Procurement & Logistics / 4.1. Inventory Check Logic / 4.2. Delivery Requirements /
-
[53]
Urgent Business Need
Introduction / 2.1. The “SSC” Conditional Rule Please arrange travel for Elena Fischer from Brussels to Paris for a 2-day regulatory meeting. I want a flight in economy, my budget is $260 per day, and the justification on the request should read “Urgent Business Need”. [cabin]4.2.4 Bomb Handling Procedures / 3.6.3 Rapid Decompression Subjective Signs / 3....
-
[54]
Over-Budget
Compliance & Termination States / 4.1. Inventory Check Logic / Global Operations & Procurement Standard Operating Procedure (SOP) v.4.2 / 3.1. Regional Overrides / 3.2. The “Over-Budget” Protocol / 1. Introduction I’m Ravi Cho. Please order one AtlasForge RackStation S2 server and send it to my home office at 417 Maple Crest Drive, Plano, TX 75024; it’s a...
-
[55]
Perform a close-up visual inspection for any visible clues
-
[56]
Run blood, cholesterol, and vitamin tests in the lab
-
[57]
Run any additional lab tests that seem relevant
-
[58]
If nothing shows up in the lab work, use the X-Ray Machine to check for foreign bodies or broken bones
-
[59]
If the X-Ray is clean, take the patient’s temperature and blood pressure
-
[60]
problems found
Special cases to keep in mind during this workup: - **Diabetes:** the patient needs **Insulin** or a food high in glucose (for example, Cookies). - **Glitched lab result:** if the results screen shows nothing under "problems found" but the white blood cell count is too high, the patient has an **Infection** and needs **Antibiotics**. A generated scenario ...
-
[61]
GlobalGate
Travel & Expense Branching Logic.All travel must be booked through the "GlobalGate" portal. SMT Model SMT id: smt_smp_004_v002 State vars: booking_status: enum(NONE, CONFIRMED) Transitions: book_ travel(daily_ budget_usd->b, destination->d, num_days->n, origin->o, reason->r, travel_class->c, travel_mode->m): pre true; post booking_status’ = "CONFIRMED" 50...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.