Recognition: no theorem link
Agent-Diff: Benchmarking LLM Agents on Enterprise API Tasks via Code Execution with State-Diff-Based Evaluation
Pith reviewed 2026-05-16 02:55 UTC · model grok-4.3
The pith
Agent-Diff benchmarks LLM agents on enterprise API tasks using code execution and state-diff contracts to define success, evaluated on nine models across 224 tasks with code released.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
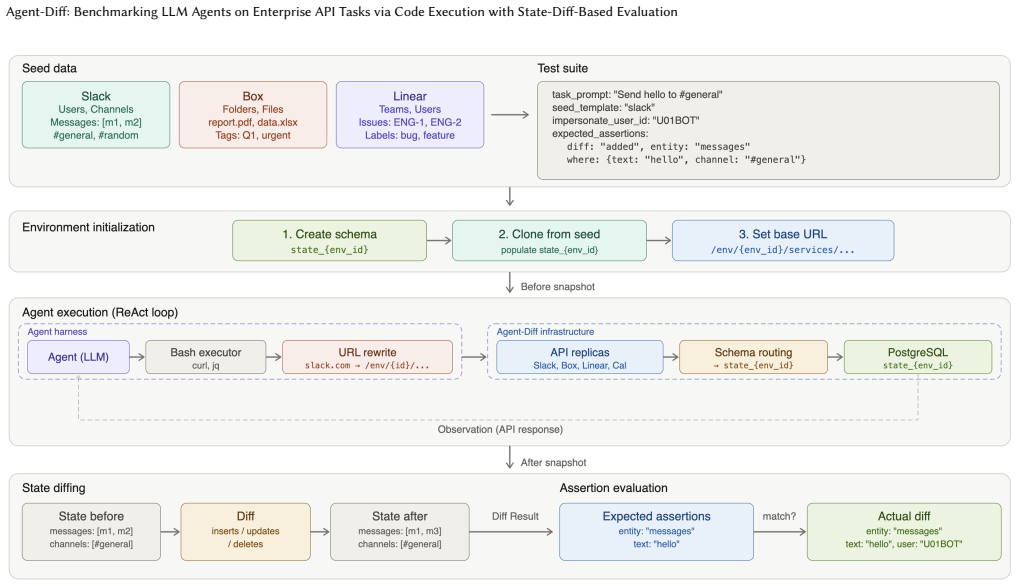
Agent-Diff captures the desirable features of both sandboxed and ecologically valid approaches by including access to the real API interfaces for software services while sandboxing the environment in which calls are made, processed, and evaluated, using a novel state-diff contract to define task success.
Load-bearing premise
That containerized replicas of enterprise APIs faithfully reproduce the behavior and state transitions of real production services, and that state-diff contracts alone are sufficient to determine task success without additional verification of side effects or correctness.
Figures





read the original abstract
We present Agent-Diff, a novel benchmarking framework for evaluating agentic Large Language Models (LLMs) on real-world productivity software API tasks via code execution. Agentic LLM performance varies due to differences in models, external tool access, prompt structures, and agentic frameworks. Benchmarks must make fundamental trade-offs between a sandboxed approach that controls for variation in software environments and more ecologically valid approaches employing real services. Agent-Diff attempts to capture the desirable features of both of these approaches by including access to the real API interfaces for software services while sandboxing the environment in which calls are made, processed, and evaluated. This approach relies on two key innovations. The first is a novel state-diff contract, which separates process from outcome - rather than fuzzy trace or parameter matching, we define task success as whether the expected change in environment state was achieved. The second is a novel sandbox built on containerized replicas of enterprise APIs, allowing all models to interact with the same service interfaces through code execution. This enables controlled evaluation against a common set of state-diff contracts while preserving the structure of real-world API interaction. Using the Agent-Diff framework, we provide benchmarks for nine LLMs across 224 tasks utilizing enterprise software workflows. In addition, we evaluate the robustness of the framework with ablation experiments to assess the contribution of access to API documentation on benchmark performance. Code and data: https://github.com/agent-diff-bench/agent-diff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agent-Diff, a benchmarking framework for agentic LLMs on enterprise API tasks that combines access to real API interfaces with a sandboxed environment via containerized replicas. Task success is defined by a novel state-diff contract that checks for expected changes in environment state rather than trace or parameter matching. The framework is applied to benchmark nine LLMs across 224 tasks, with additional ablation experiments on the impact of API documentation access; code and data are released on GitHub.
Significance. If the containerized replicas are shown to faithfully reproduce production API behavior and the state-diff contracts are validated as sufficient for determining success, the framework would provide a useful middle ground between fully sandboxed and live-service benchmarks, supporting more reproducible evaluation of agentic systems on realistic productivity workflows. The public code release is a positive contribution to reproducibility.
major comments (2)
- [Framework description and sandbox construction] The central claim that the sandboxed replicas preserve the structure of real-world API interaction while enabling controlled state-diff evaluation depends on the unverified assumption that containerized replicas produce identical state transitions to production services. No differential testing, invariant checks, side-effect logging, or comparison against live services (e.g., for authentication flows, rate limits, or eventual consistency) is described anywhere in the manuscript, including the framework or evaluation sections. This is load-bearing for ecological validity.
- [Results and ablation experiments] The abstract states that benchmarks are provided for nine LLMs across 224 tasks, yet the manuscript supplies no quantitative performance numbers, error analysis, or explicit validation that state-diff contracts accurately capture intended outcomes without missing side effects. This absence weakens support for any claims about LLM agent performance or framework robustness.
minor comments (2)
- [Abstract] The abstract mentions 'benchmarks' and 'ablation experiments' but reports no concrete metrics or tables, which reduces the standalone readability of the summary.
- [Evaluation method] Notation for the state-diff contract could be clarified with a formal definition or pseudocode example to make the separation of process from outcome more precise.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important aspects of ecological validity and result presentation that we address below. We have revised the manuscript accordingly to strengthen these elements while preserving the core contributions.
read point-by-point responses
-
Referee: [Framework description and sandbox construction] The central claim that the sandboxed replicas preserve the structure of real-world API interaction while enabling controlled state-diff evaluation depends on the unverified assumption that containerized replicas produce identical state transitions to production services. No differential testing, invariant checks, side-effect logging, or comparison against live services (e.g., for authentication flows, rate limits, or eventual consistency) is described anywhere in the manuscript, including the framework or evaluation sections. This is load-bearing for ecological validity.
Authors: We agree that explicit documentation of replica fidelity is important for supporting ecological validity. The containerized replicas were constructed directly from the public API specifications and interface definitions of the target enterprise services, with internal development-time checks to confirm that state transitions for each task matched the expected outcomes under the state-diff contracts. However, the manuscript does not describe differential testing or live-service comparisons. In the revised version, we will add a dedicated subsection in the Framework section (new Section 3.4) that details the replica construction process, the invariant checks performed, side-effect logging during task execution, and a discussion of limitations regarding authentication flows and rate-limit behaviors. This addition directly addresses the concern without altering the experimental results. revision: yes
-
Referee: [Results and ablation experiments] The abstract states that benchmarks are provided for nine LLMs across 224 tasks, yet the manuscript supplies no quantitative performance numbers, error analysis, or explicit validation that state-diff contracts accurately capture intended outcomes without missing side effects. This absence weakens support for any claims about LLM agent performance or framework robustness.
Authors: The evaluation section (Section 4) of the manuscript already contains the quantitative results: Table 2 reports per-model success rates across all 224 tasks, and Section 4.3 provides error analysis broken down by failure modes. Section 3.3 describes the state-diff validation process, including manual review of 50 randomly sampled tasks to confirm that contracts captured intended outcomes without overlooking side effects. To make these elements more prominent and directly tied to the abstract claims, we will revise the abstract to include key aggregate metrics (e.g., average success rate across models) and expand Section 3.3 with two additional concrete examples of state-diff contract validation. These changes improve clarity without requiring new experiments. revision: partial
Circularity Check
No circularity detected in framework definition or evaluation claims
full rationale
The paper defines Agent-Diff as a benchmarking framework using state-diff contracts for task success and containerized API replicas for controlled execution. No equations, fitted parameters, or predictions are introduced that reduce to the inputs by construction. The state-diff contract is presented as a novel definition separating process from outcome, not derived from prior results within the paper. No self-citations appear as load-bearing justifications for uniqueness or ansatzes. The GitHub release is cited as external grounding. The derivation chain consists of independent design choices for sandboxing and evaluation, with no renaming of known results or self-referential fitting. This is a standard non-circular introduction of a new evaluation method.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MANTRA: Synthesizing SMT-Validated Compliance Benchmarks for Tool-Using LLM Agents
MANTRA automatically synthesizes SMT-validated compliance benchmarks for LLM agents from natural language manuals and tool schemas, producing 285 tasks across 6 domains with minimal human effort.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2024. Model Context Protocol. https://www.anthropic.com/news/ model-context-protocol
work page 2024
-
[2]
2026.2026 Agentic Coding Trends Report: How coding agents are reshaping software development
Anthropic. 2026.2026 Agentic Coding Trends Report: How coding agents are reshaping software development. Technical Report. Anthropic. https://resources. anthropic.com/2026-agentic-coding-trends-report Accessed: 2026-01-28. Covers trends like multi-agent teams, long-running agents, and productivity gains in SDLC
-
[3]
Anthropic. 2026. claude-code (GitHub repository). https://github.com/ anthropics/claude-code
work page 2026
-
[4]
Jayachandu Bandlamudi, Ritwik Chaudhuri, Neelamadhav Gantayat, Sambit Ghosh, Kushal Mukherjee, Prerna Agarwal, Renuka Sindhgatta, and Sameep Mehta. 2025. A Framework for Testing and Adapting REST APIs as LLM Tools. doi:10.48550/arXiv.2504.15546 arXiv:2504.15546 [cs]
- [5]
-
[6]
Box, Inc. 2026. Box API Reference. https://developer.box.com/reference/ Ac- cessed: 2026-01-25
work page 2026
-
[7]
Box, Inc. 2026. box-python-sdk. https://github.com/box/box-python-sdk GitHub repository
work page 2026
-
[8]
Cursor. 2026. Cursor CLI. https://cursor.com/blog/cli
work page 2026
-
[9]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. 2025. SWE-Bench Pro: Can AI Agents Solve L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Xuanqi Gao, Siyi Xie, Juan Zhai, Shiqing Ma, and Chao Shen. 2025. MCP-RADAR: A Multi-Dimensional Benchmark for Evaluating Tool Use Capabilities in Large Language Models. doi:10.48550/arXiv.2505.16700 arXiv:2505.16700 [cs]
-
[11]
Google. 2026. gemini-cli (GitHub repository). https://github.com/google-gemini/ gemini-cli
work page 2026
-
[12]
Google LLC. 2026. Google Calendar API v3 Reference. https://developers.google. com/calendar/api/v3/reference Accessed: 2026-02-02
work page 2026
-
[13]
Adam Jones and Conor Kelly. 2025. Code execution with MCP: Building more efficient agents. https://www.anthropic.com/engineering/code-execution-with- mcp. Anthropic Engineering Blog
work page 2025
-
[14]
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhou- jun Li, Fei Huang, and Yongbin Li. 2023. API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs. doi:10.48550/arXiv.2304.08244 arXiv:2304.08244 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.08244 2023
-
[15]
Linear Inc. 2026. Linear GraphQL API Public Schema. https://studio. apollographql.com/public/Linear-API/ Accessed: 2026-02-02
work page 2026
-
[16]
Linear Inc. 2026. @linear/sdk. https://www.npmjs.com/package/@linear/sdk npm package
work page 2026
-
[17]
Ziyang Luo, Zhiqi Shen, Wenzhuo Yang, Zirui Zhao, Prathyusha Jwalapuram, Amrita Saha, Doyen Sahoo, Silvio Savarese, Caiming Xiong, and Junnan Li. 2025. MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers. doi:10.48550/arXiv.2508.14704 arXiv:2508.14704 [cs]
-
[18]
Seiji Maekawa, Jackson Hassell, Pouya Pezeshkpour, Tom Mitchell, and Es- tevam Hruschka. 2025. Towards Reliable Benchmarking: A Contamination Free, Controllable Evaluation Framework for Multi-step LLM Function Calling. doi:10.48550/arXiv.2509.26553 arXiv:2509.26553 [cs]
-
[19]
Tula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. 2024. The Land- scape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey. doi:10.48550/arXiv.2404.11584 arXiv:2404.11584 [cs]
-
[20]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Mari- anna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Donald B. Rubin. 1981. The Bayesian Bootstrap.The Annals of Statistics9, 1 (1981), 130–134
work page 1981
-
[22]
Slack Technologies. 2026. python-slack-sdk. https://github.com/slackapi/python- slack-sdk GitHub repository
work page 2026
-
[23]
Slack Technologies. 2026. Slack Web API Methods. https://api.slack.com/ methods Accessed: 2026-02-02
work page 2026
-
[24]
Zhenting Wang, Qi Chang, Hemani Patel, Shashank Biju, Cheng-En Wu, Quan Liu, Aolin Ding, Alireza Rezazadeh, Ankit Shah, Yujia Bao, and Eugene Siow
-
[25]
doi:10.48550/ARXIV.2508.20453 Version Number: 1
MCP-Bench: Benchmarking Tool-Using LLM Agents with Complex Real- World Tasks via MCP Servers. doi:10.48550/ARXIV.2508.20453 Version Number: 1
-
[26]
Yunhe Yan, Shihe Wang, Jiajun Du, Yexuan Yang, Yuxuan Shan, Qichen Qiu, Xianqing Jia, Xinge Wang, Xin Yuan, Xu Han, Mao Qin, Yinxiao Chen, Chen Peng, Shangguang Wang, and Mengwei Xu. 2025. MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents. doi:10.48550/arXiv. 2506.07672 arXiv:2506.07672 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[27]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2024. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv:2406.12045 [cs.AI] https://arxiv.org/abs/2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. doi:10.48550/arXiv.2305.10601 arXiv:2305.10601 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10601 2023
-
[29]
Shunyu Yao, Jeffrey Zhao, Dian Yu, et al. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. doi:10.48550/arXiv.2210.03629 arXiv:2210.03629 [cs]. A Uncertainty and Ablation Analysis A.1 Score Uncertainty Evaluation We quantify uncertainty via the Bayesian bootstrap [ 21] with a uniform Dirichlet prior, placing noa prioripreference among tas...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2023
-
[30]
with test-level clustering. Estimand.For each strategy𝑠, we compute: Δ𝑠 = ˆ𝑝top 𝑠 − ˆ𝑝bottom 𝑠 (21) where ˆ𝑝group 𝑠 is the weighted proportion of runs in that group that employed strategy 𝑠. A positive Δ indicates higher usage among top-performing models; a negative Δ indicates higher usage among bottom-performing models. Bootstrap Resampling.We used a pa...
-
[34]
"" C.2 Execution ReAct prompt ReAct system prompt (with API docs). REACT_SYSTEM_PROMPT =
Only use <done> when the task is fully completed (not just when you've gathered information).↩→ ## API Documentation {api_docs} Agent-Diff: Benchmarking LLM Agents on Enterprise API Tasks via Code Execution with State-Diff-Based Evaluation """ C.2 Execution ReAct prompt ReAct system prompt (with API docs). REACT_SYSTEM_PROMPT = """You are an AI assistant ...
-
[35]
Execute ONE command at a time, then wait for the result
-
[36]
Parse API responses carefully - extract IDs and data needed for subsequent calls.↩→
-
[37]
If a command fails, analyze the error and try a different approach.↩→
-
[38]
Perseid Meteor Shower Watch Party
Only use <done> when the task is fully completed (not just when you've gathered information).↩→ """ Table 10: System prompt length (approximate tokens) by documentation condition and service. Serviceno_docs relevant all_docs Box 380 3,230 22,320 Calendar 450 9,980 22,390 Linear 390 6,340 22,330 Slack 380 3,890 22,330 Hubert M. Pysklo, Artem Zhuravel, and ...
work page 2026
-
[39]
Tool Use Errors Errors related to how the agent interacts with tools and APIs.↩→ Evaluate each subtype explicitly: endpoint_selection: Determine whether the agent consistently selects correct endpoints.↩→ - present: True if there are any incorrect or irrelevant endpoint↩→ choices - explanation: Brief summary of the issue (or why none were found)↩→ - examp...
-
[40]
Model Refusal Determine whether the agent refuses to perform the task, asks the↩→ user for information it could retrieve itself, OR delegates execution back to user. This includes: - Explicitly refusing to perform the task - Asking user for IDs, tokens, or file contents the agent could↩→ find itself - Passive delegation: gathering information but providin...
-
[41]
Hallucination Errors Hallucinations are when the agent FABRICATES or ASSERTS invented↩→ information as truth. Distinct from reasoning errors (logic failures) and assumption errors (guessing without checking).↩→ For EACH type, explicitly evaluate whether it occurred. You MUST↩→ provide a judgment (present: true/false) and example for EVERY↩→ category: - pa...
-
[42]
Reasoning Errors Reasoning errors involve logic failures, memory issues, or flawed↩→ inference. About HOW the agent thinks, not fabricating information.↩→ IMPORTANT DISTINCTIONS: - state_tracking_error = agent FORGETS (memory failure) - state_hallucination = agent INVENTS (fabrication) - assumption_error = agent GUESSES without checking - hallucination = ...
-
[43]
Recovery Strategies For EACH type, evaluate whether the agent attempted it. Provide↩→ present: true/false and example for EVERY category: - retry_same: Retried exact same action unchanged. - retry_modified_params: Retried with adjusted parameters. - switch_tool: Switched to different tool/endpoint for same goal.↩→ - lookup_correct_value: Searched/queried ...
-
[44]
Category 7: Qualitative Summary
Other Errors Determine if there are errors not covered by categories 1-4.↩→ Returns: present, explanation (including proposed subcategory↩→ name), example. Category 7: Qualitative Summary
-
[45]
Qualitative Summary Provide a high-level narrative analysis of this run. Scoring dimensions (each 0--5): - planning_score: Action sequencing, adaptation, efficiency.↩→ 5=Excellent (clear, efficient, proactive) 3=Mixed (progress with avoidable detours) 0=Non-functional (no meaningful plan) - reasoning_score: Correctness of inferences, use of context.↩→ 5=E...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.