Recognition: unknown
Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
Pith reviewed 2026-05-08 13:12 UTC · model grok-4.3
The pith
Semantic latent spaces outperform reconstruction ones for robotic world models even with weaker pixel fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Semantic encoders such as V-JEPA 2.1 (strongest on policy), Web-DINO, and SigLIP 2 generally outperform reconstruction encoders like VAE and Cosmos on planning, downstream policy performance, and latent quality across model scales, even though the reconstruction models achieve higher visual fidelity scores. High-dimensional semantic spaces support effective world model training with or without compression. Visual fidelity alone is therefore insufficient for selecting world models intended for robotics.
What carries the argument
The three evaluation axes of visual fidelity, planning and downstream policy performance, and latent representation quality applied to action-conditioned latent diffusion models built from different pretrained encoders.
If this is right
- Visual fidelity metrics cannot be trusted by themselves to pick the best world model for robotics.
- Semantic encoders deliver better planning and policy outcomes at every tested model scale.
- World models can be trained successfully in high-dimensional semantic spaces without dimension compression.
- Pretrained semantic encoders supply stronger starting points than reconstruction autoencoders for diffusion-based robotic simulators.
Where Pith is reading between the lines
- Future robotic simulators could prioritize semantic pretraining objectives over pure pixel reconstruction when designing latent spaces.
- The advantage of semantic spaces may appear in other control tasks where relations between objects matter more than exact visual appearance.
- Direct tests on physical robots would show whether the observed policy gains transfer from simulation to hardware.
Load-bearing premise
That performance differences seen on the BridgeV2 dataset under one fixed training protocol will determine the best latent space for robotic world models in general.
What would settle it
A controlled experiment on a different robot dataset or with varied training protocols in which reconstruction encoders produce higher policy success rates than semantic encoders.
Figures














read the original abstract
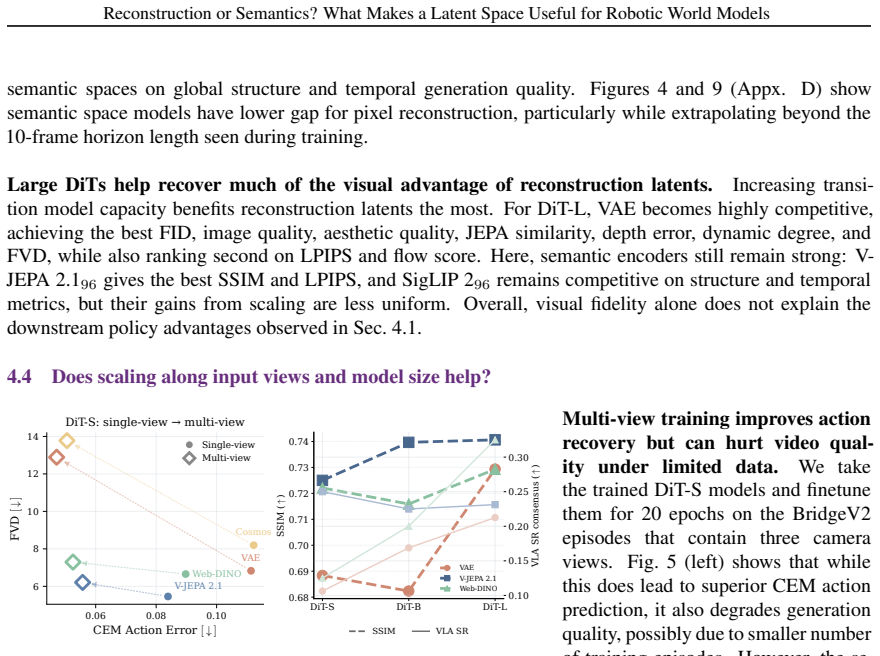
World model-based policy evaluation is a practical proxy for testing real-world robot control by rolling out candidate actions in action-conditioned video diffusion models. As these models increasingly adopt latent diffusion modeling (LDM), choosing the right latent space becomes critical. While the status quo uses autoencoding latent spaces like VAEs that are primarily trained for pixel reconstruction, recent work suggests benefits from pretrained encoders with representation-aligned semantic latent spaces. We systematically evaluate these latent spaces for action-conditioned LDM by comparing six reconstruction and semantic encoders to train world model variants under a fixed protocol on BridgeV2 dataset, and show effective world model training in high-dimensional representation spaces with and without dimension compression. We then propose three axes to assess robotic world model performance: visual fidelity, planning and downstream policy performance, and latent representation quality. Our results show visual fidelity alone is insufficient for world model selection. While reconstruction encoders like VAE and Cosmos achieve strong pixel-level scores, semantic encoders such as V-JEPA 2.1 (strongest overall on policy), Web-DINO, and SigLIP 2 generally excel across the other two axes at all model scales. Our study advocates semantic latent space as stronger foundation for policy-relevant robotics diffusion world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper systematically compares six off-the-shelf encoders (reconstruction-based: VAE, Cosmos; semantic: V-JEPA 2.1, Web-DINO, SigLIP 2 and others) for action-conditioned latent diffusion models trained as robotic world models on the BridgeV2 dataset under a fixed protocol. It evaluates them on three axes (visual fidelity, planning/policy performance, latent representation quality) and concludes that visual fidelity alone is insufficient for selection, with semantic encoders generally excelling on the other axes at all model scales and with/without dimension compression, advocating semantic latent spaces as a stronger foundation for policy-relevant robotics diffusion world models.
Significance. If the empirical ranking holds under broader conditions, the work provides actionable guidance for latent-space selection in robotic world models, potentially improving policy transfer by prioritizing semantic alignment over pixel reconstruction.
major comments (2)
- [Abstract and Evaluation Protocol] The central claim that semantic encoders (V-JEPA 2.1 strongest on policy) provide a stronger foundation rests on results from a single dataset (BridgeV2) and one fixed training protocol. The abstract's assertion that advantages hold 'at all model scales' and 'with and without dimension compression' therefore requires explicit ablations or additional datasets to rule out protocol- or distribution-specific effects before supporting the general recommendation.
- [Results] No variance, standard deviations, or statistical significance tests are referenced for the cross-encoder rankings on the planning/policy axis. Without these, the reported superiority (e.g., V-JEPA 2.1 as strongest overall) cannot be assessed for robustness against run-to-run variability or hyperparameter sensitivity in high-dimensional semantic spaces.
minor comments (2)
- [Methods] Clarify the exact procedure and hyperparameters for dimension compression when applied to semantic encoders, and whether any implicit tuning favors higher-dimensional representations.
- [Results] Add a table or figure summarizing all three axes side-by-side for each encoder and scale to improve readability of the comparative claims.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below with clarifications, explanations of our experimental design, and indications of revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation Protocol] The central claim that semantic encoders (V-JEPA 2.1 strongest on policy) provide a stronger foundation rests on results from a single dataset (BridgeV2) and one fixed training protocol. The abstract's assertion that advantages hold 'at all model scales' and 'with and without dimension compression' therefore requires explicit ablations or additional datasets to rule out protocol- or distribution-specific effects before supporting the general recommendation.
Authors: We agree that broader validation across datasets would strengthen the general recommendation. Our study deliberately uses a fixed protocol on BridgeV2 to enable controlled, apples-to-apples comparison of the six encoders. The claims regarding 'all model scales' and 'with and without dimension compression' are directly supported by the ablations we performed and reported within this setup. In the revised manuscript we will (1) revise the abstract to qualify the scope of the claims, (2) add an explicit limitations paragraph discussing single-dataset evaluation, and (3) include a forward-looking statement on the value of future multi-dataset studies. No new large-scale experiments are feasible within the revision timeline, but the existing scale and compression ablations already address part of the concern. revision: partial
-
Referee: [Results] No variance, standard deviations, or statistical significance tests are referenced for the cross-encoder rankings on the planning/policy axis. Without these, the reported superiority (e.g., V-JEPA 2.1 as strongest overall) cannot be assessed for robustness against run-to-run variability or hyperparameter sensitivity in high-dimensional semantic spaces.
Authors: We acknowledge that reporting variability would improve confidence in the rankings. Training each world-model variant is computationally expensive; therefore we report single-run results for the full set of encoders and scales. However, the superiority of semantic encoders is consistent across three independent evaluation axes (visual fidelity, planning/policy, representation quality) and across model scales, which mitigates the risk of isolated run-specific artifacts. In the revision we will add a dedicated limitations subsection on single-run evaluation, report standard deviations for the subset of smaller-scale models where we have multiple seeds, and note that hyperparameter sensitivity was controlled by using the same training protocol for all encoders. revision: partial
- Full validation on additional robotic datasets beyond BridgeV2 to confirm the ranking is not distribution-specific
Circularity Check
No significant circularity: empirical encoder comparison
full rationale
The paper conducts a direct empirical comparison of six off-the-shelf encoders (VAE, Cosmos, V-JEPA 2.1, Web-DINO, SigLIP 2, and one other) by training action-conditioned LDM world models on BridgeV2 under a fixed protocol. It reports results on three evaluation axes without any mathematical derivations, parameter-fitting steps that are then relabeled as predictions, self-referential definitions, or load-bearing uniqueness theorems. All claims rest on observable performance differences across visual fidelity, policy/planning, and latent quality metrics, which are independent of the paper's own inputs by construction. Minor self-citations to prior encoder work are present but do not support the central ranking; the study remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Y ogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopad- hyay, Y ongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation
Jason Ansel, Edward Y ang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, et al. Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. In Proceedings of the 29th ACM international conference on architectural support for programming la...
2024
-
[3]
Self-supervised learning from images with a joint-embedding predic- tive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Y ann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predic- tive architecture. In Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 15619–15629, 2023
2023
-
[4]
V -JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning, June 2025
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba, Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, V asil Khalidov, Patrick Labatut, Fran- cisco Massa, Marc Szafraniec, Kapil Krishnakumar, Y ong Li,...
2025
-
[5]
SemanticGen: Video Generation in Seman- tic Space, December 2025
Jianhong Bai, Xiaoshi Wu, Xintao Wang, Xiao Fu, Y uanxing Zhang, Qinghe Wang, Xiaoyu Shi, Meng- han Xia, Zuozhu Liu, Haoji Hu, Pengfei Wan, and Kun Gai. SemanticGen: Video Generation in Seman- tic Space, December 2025
2025
-
[6]
Shuai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, 10 Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng...
work page internal anchor Pith review arXiv 2025
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Y uanzhi Zhu, Mingkun Y ang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Y e, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Y ang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review arXiv 2025
-
[8]
Back to the features: Dino as a foundation for video world models.arXiv preprint arXiv:2507.19468,
Federico Baldassarre, Marc Szafraniec, Basile Terver, V asil Khalidov, Francisco Massa, Y ann LeCun, Patrick Labatut, Maximilian Seitzer, and Piotr Bojanowski. Back to the features: Dino as a foundation for video world models. arXiv preprint arXiv:2507.19468, 2025
-
[9]
Model-predictive control via cross-entropy and gradient-based optimization
Homanga Bharadhwaj, Kevin Xie, and Florian Shkurti. Model-predictive control via cross-entropy and gradient-based optimization. In Learning for Dynamics and Control , pages 277–286. PMLR, 2020
2020
-
[10]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Y ufei Guo, Li Jing, David Schnurr, Joe Tay- lor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. 2024. URL https://openai. com/research/video-generation-models-as-world-simulators, 3(1):3, 2024
2024
-
[11]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision , pages 9650–9660, 2021
2021
-
[12]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Informa- tion Processing Systems, 37:24081–24125, 2024
2024
-
[13]
V ery deep {vae}s generalize autoregressive models and can outperform them on images
Rewon Child. V ery deep {vae}s generalize autoregressive models and can outperform them on images. In International Conference on Learning Representations , 2021. URL https://openreview.net/ forum?id=RLRXCV6DbEJ
2021
-
[14]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In In- ternational Conference on Learning Representations, 2021. URL htt...
2021
-
[15]
Simulation tools for model-based robotics: Comparison of bullet, havok, mujoco, ode and physx
Tom Erez, Y uval Tassa, and Emanuel Todorov. Simulation tools for model-based robotics: Comparison of bullet, havok, mujoco, ode and physx. In 2015 IEEE international conference on robotics and automation (ICRA), pages 4397–4404. IEEE, 2015
2015
-
[16]
Scaling rectified flow transformers for high- resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Y am Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high- resolution image synthesis. In F orty-first international conference on machine learning, 2024
2024
-
[17]
arXiv preprint arXiv:2601.04137 (2026)
Chun-Kai Fan, Xiaowei Chi, Xiaozhu Ju, Hao Li, Y ong Bao, Y u-Kai Wang, Lizhang Chen, Zhiyuan Jiang, Kuangzhi Ge, Ying Li, et al. Wow, wo, val! a comprehensive embodied world model evaluation turing test. arXiv preprint arXiv:2601.04137, 2026
-
[18]
Scaling language-free visual representation learning
David Fan, Shengbang Tong, Jiachen Zhu, Koustuv Sinha, Zhuang Liu, Xinlei Chen, Michael Rabbat, Nicolas Ballas, Y ann LeCun, Amir Bar, et al. Scaling language-free visual representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 370–382, 2025. 11 Reconstruction or Semantics? What Makes a Latent Space Usefu...
2025
-
[19]
Ctrl-world: A controllable generative world model for robot manipulation, 2025
Y anjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable genera- tive world model for robot manipulation. arXiv preprint arXiv:2510.10125, 2025
-
[20]
David Ha and Jürgen Schmidhuber. World models. eprint arXiv: 1803.10122 , 2018
work page internal anchor Pith review arXiv 2018
-
[21]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In International conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[22]
Momentum contrast for unsuper- vised visual representation learning
Kaiming He, Haoqi Fan, Y uxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsuper- vised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[23]
Masked autoen- coders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Y anghao Li, Piotr Dollár, and Ross Girshick. Masked autoen- coders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[24]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017
2017
- [25]
-
[26]
Cotracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea V edaldi, and Christian Rupprecht. Cotracker: It is better to track together. In Proc. ECCV, 2024
2024
-
[27]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Y ang. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF international conference on computer vision , pages 5148–5157, 2021
2021
-
[28]
Openvla: An open-source vision- language-action model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, et al. Openvla: An open-source vision- language-action model. In Conference on Robot Learning , pages 2679–2713. PMLR, 2025
2025
-
[29]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review arXiv 2013
-
[30]
Imagenet classification with deep convolu- tional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolu- tional neural networks. Advances in neural information processing systems , 25, 2012
2012
-
[31]
R-bench: Are your large multimodal model robust to real-world corruptions?, 2024
Chunyi Li, Jianbo Zhang, Zicheng Zhang, Haoning Wu, Y uan Tian, Wei Sun, Guo Lu, Xiaohong Liu, Xiongkuo Min, Weisi Lin, and Guangtao Zhai. R-bench: Are your large multimodal model robust to real-world corruptions?, 2024
2024
-
[32]
Gonzalez, Ion Stoica, Song Han, and Y ao Lu
Dacheng Li, Y unhao Fang, Y ukang Chen, Shuo Y ang, Shiyi Cao, Justin Wong, Michael Luo, Xiao- long Wang, Hongxu Yin, Joseph E. Gonzalez, Ion Stoica, Song Han, and Y ao Lu. Worldmodel- bench: Judging video generation models as world models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , 2025....
2025
-
[33]
Evaluating real-world robot manipulation policies in simula- tion
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Oier Mees, Karl Pertsch, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, et al. Evaluating real-world robot manipulation policies in simula- tion. In Conference on Robot Learning , pages 3705–3728. PMLR, 2025
2025
-
[34]
Worldeval: World model as real-world robot policies evaluator,
Y axuan Li, Yichen Zhu, Junjie Wen, Chaomin Shen, and Yi Xu. Worldeval: World model as real-world robot policies evaluator. arXiv preprint arXiv:2505.19017, 2025. 12 Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
-
[35]
Y aron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In The Eleventh International Conference on Learning Representations , 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[36]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[37]
VDT: General- purpose video diffusion transformers via mask modeling
Haoyu Lu, Guoxing Y ang, Nanyi Fei, Y uqi Huo, Zhiwu Lu, Ping Luo, and Mingyu Ding. VDT: General- purpose video diffusion transformers via mask modeling. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Un0rgm9f04
2024
-
[38]
arXiv preprint arXiv:2603.14482 (2026)
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Y ann LeCun, Nicolas Ballas, and Adrien Bardes. V -jepa 2.1: Unlocking dense features in video self- supervised learning. arXiv preprint arXiv:2603.14482, 2026
-
[39]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Y uke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems (RSS) , 2024
2024
-
[40]
Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots
Soroush Nasiriany, Sepehr Nasiriany, Abhiram Maddukuri, and Y uke Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots. In International Conference on Learning Representations (ICLR), 2026
2026
-
[41]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, V asil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review arXiv 2023
-
[42]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision , pages 4195–4205, 2023
2023
-
[43]
Sample-efficient cross-entropy method for real-time planning
Cristina Pinneri, Shambhuraj Sawant, Sebastian Blaes, Jan Achterhold, Joerg Stueckler, Michal Rolinek, and Georg Martius. Sample-efficient cross-entropy method for real-time planning. In Conference on Robot Learning, pages 1049–1065. PMLR, 2021
2021
-
[44]
Worldgym: World model as an environment for policy evaluation, 2025
Julian Quevedo, Ansh Kumar Sharma, Yixiang Sun, V arad Suryavanshi, Percy Liang, and Sherry Y ang. Worldgym: World model as an environment for policy evaluation. arXiv preprint arXiv:2506.00613 , 2025
-
[45]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/ blog?id=qwen3.5
2026
-
[46]
Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026
Qwen Team. Qwen3.6-27B: Flagship-level coding in a 27B dense model, April 2026. URL https: //qwen.ai/blog?id=qwen3.6-27b
2026
-
[47]
Learning transferable visual models from nat- ural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. In International conference on machine learning , pages 8748–8763. PmLR, 2021
2021
-
[48]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 10684–10695, 2022
2022
-
[49]
The cross-entropy method: a unified approach to combinato- rial optimization, Monte-Carlo simulation, and machine learning , volume 133
Reuven Y Rubinstein and Dirk P Kroese. The cross-entropy method: a unified approach to combinato- rial optimization, Monte-Carlo simulation, and machine learning , volume 133. Springer, 2004
2004
-
[50]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard V encu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in neural information processing systems, 35:25278–25294, 2022. 13 Reconstruction or Semantics? ...
2022
-
[51]
arXiv preprint arXiv:2602.08971 (2026)
Y u Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models. arXiv preprint arXiv:2602.08971, 2026
-
[52]
World-gymnast: Training robots with reinforcement learning in a world model, 2026
Ansh Kumar Sharma, Yixiang Sun, Ninghao Lu, Y unzhe Zhang, Jiarao Liu, and Sherry Y ang. World-gymnast: Training robots with reinforcement learning in a world model. arXiv preprint arXiv:2602.02454, 2026
-
[53]
Latent diffusion model without variational autoencoder
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Y uan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder. In The F ourteenth Inter- national Conference on Learning Representations , 2026. URL https://openreview.net/forum? id=kdpeJNbFyf
2026
-
[54]
Improving the diffusability of autoencoders
Ivan Skorokhodov, Sharath Girish, Benran Hu, Willi Menapace, Y anyu Li, Rameen Abdal, Sergey Tulyakov, and Aliaksandr Siarohin. Improving the diffusability of autoencoders. In F orty-second In- ternational Conference on Machine Learning , 2025. URL https://openreview.net/forum?id= 2hEDcA7xy4
2025
-
[55]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent V anhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
2016
-
[56]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision , pages 402–419. Springer, 2020
2020
-
[57]
Predictive inverse dynamics models are scalable learners for robotic manipulation
Y ang Tian, Sizhe Y ang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. In The Thirteenth Interna- tional Conference on Learning Representations , 2025. URL https://openreview.net/forum?id= meRCKuUpmc
2025
-
[58]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Y uval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems , pages 5026–5033. IEEE, 2012
2012
-
[59]
Beyond language modeling: An exploration of multimodal pretraining.arXiv preprint arXiv:2603.03276,
Shengbang Tong, David Fan, John Nguyen, Ellis Brown, Gaoyue Zhou, Shengyi Qian, Boyang Zheng, Théophane V allaeys, Junlin Han, Rob Fergus, et al. Beyond language modeling: An exploration of multimodal pretraining. arXiv preprint arXiv:2603.03276, 2026
-
[60]
Shengbang Tong, Boyang Zheng, Ziteng Wang, Bingda Tang, Nanye Ma, Ellis Brown, Jihan Y ang, Rob Fergus, Y ann LeCun, and Saining Xie. Scaling text-to-image diffusion transformers with representation autoencoders. arXiv preprint arXiv:2601.16208, 2026
-
[61]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdul- mohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Y e Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features. arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review arXiv 2025
-
[62]
Scalable policy evaluation with video world models.arXiv preprint arXiv:2511.11520, 2025
Wei-Cheng Tseng, Jinwei Gu, Qinsheng Zhang, Hanzi Mao, Ming-Y u Liu, Florian Shkurti, and Lin Y en-Chen. Scalable policy evaluation with video world models. arXiv preprint arXiv:2511.11520 , 2025
-
[63]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd V an Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review arXiv 2018
-
[64]
Score-based generative modeling in latent space.Advances in neural information processing systems , 34:11287–11302, 2021
Arash V ahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space.Advances in neural information processing systems , 34:11287–11302, 2021. 14 Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
2021
-
[65]
Attention is all you need
Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[66]
Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, Abraham Lee, Kuan Fang, Chelsea Finn, and Sergey Levine
Homer Rich Walke, Kevin Black, Tony Z. Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen- Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, Abraham Lee, Kuan Fang, Chelsea Finn, and Sergey Levine. Bridgedata v2: A dataset for robot learning at scale. In Jie Tan, Marc Tou- ssaint, and Kourosh Darvish, editors, Proceedings of The 7th Conference on Ro...
2023
-
[67]
DDT: Decoupled diffusion Transformer.arXiv:2504.05741, 2025
Shuai Wang, Zhi Tian, Weilin Huang, and Limin Wang. Ddt: Decoupled diffusion transformer. arXiv preprint arXiv:2504.05741, 2025
-
[68]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Y e, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal mod- els in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review arXiv 2025
-
[69]
Image quality assessment: from error visibility to structural similarity
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing , 13(4):600–612, 2004
2004
-
[70]
Learning interactive real-world simulators
Sherry Y ang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In NeurIPS Workshop on Generalization in Planning, 2023
2023
-
[71]
Reconstruction vs
Jingfeng Y ao, Bin Y ang, and Xinggang Wang. Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[72]
An image is worth 32 tokens for reconstruction and generation
Qihang Y u, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An image is worth 32 tokens for reconstruction and generation. Advances in Neural Information Processing Systems, 37:128940–128966, 2024
2024
-
[73]
arXiv preprint arXiv:2505.09694 (2025)
Hu Y ue, Siyuan Huang, Y ue Liao, Shengcong Chen, Pengfei Zhou, Liliang Chen, Maoqing Y ao, and Guanghui Ren. Ewmbench: Evaluating scene, motion, and semantic quality in embodied world models. arXiv preprint arXiv:2505.09694, 2025
-
[74]
Patel, Paul Pu Liang, Daniel Khashabi, Cheng Peng, Rama Chellappa, Tianmin Shu, Alan L
Jiahan Zhang, Muqing Jiang, Nanru Dai, Taiming Lu, Arda Uzunoglu, Shunchi Zhang, Y ana Wei, Jiahao Wang, Vishal M Patel, Paul Pu Liang, et al. World-in-world: World models in a closed-loop world.arXiv preprint arXiv:2510.18135, 2025
-
[75]
Reinforcing action policies by prophesying
Jiahui Zhang, Ze Huang, Chun Gu, Zipei Ma, and Li Zhang. Reinforcing action policies by prophesying. arXiv preprint arXiv:2511.20633, 2025
-
[76]
Rae-nwm: Navigation world model in dense visual representation space
Mingkun Zhang, Wangtian Shen, Fan Zhang, Haijian Qin, Zihao Pei, and Ziyang Meng. Rae-nwm: Navigation world model in dense visual representation space. arXiv preprint arXiv:2603.09241, 2026
-
[77]
The unreasonable ef- fectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable ef- fectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 586–595, 2018
2018
-
[78]
Shilong Zhang, He Zhang, Zhifei Zhang, Chongjian Ge, Shuchen Xue, Shaoteng Liu, Mengwei Ren, Soo Y e Kim, Y uqian Zhou, Qing Liu, et al. Both semantics and reconstruction matter: Making rep- resentation encoders ready for text-to-image generation and editing. arXiv preprint arXiv:2512.17909 , 2025
-
[79]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representa- tion autoencoders. arXiv preprint arXiv:2510.11690, 2025. 15 Reconstruction or Semantics? What Makes a Latent Space Useful for Robotic World Models
work page internal anchor Pith review arXiv 2025
-
[80]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Gaoyue Zhou, Hengkai Pan, Y ann LeCun, and Lerrel Pinto. DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning. In F orty-Second International Conference on Machine Learning, June 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.