Recognition: unknown
When and Why SignSGD Outperforms SGD: A Theoretical Study Based on ell₁-norm Lower Bounds
Pith reviewed 2026-05-08 12:09 UTC · model grok-4.3
The pith
SignSGD reduces optimization complexity by a factor of d compared to SGD under sparse noise using ℓ1-norm analysis
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under ℓ1-norm stationarity, ℓ∞-smoothness, and separable noise, SignSGD has an upper bound that is d times better than the lower bound for SGD when the noise is sparse, establishing when and why sign-based methods are superior. This is matched for Muon in the matrix setting.
What carries the argument
The comparison between the upper bound of SignSGD and the lower bound of SGD under the ℓ1-norm geometry and separable noise model.
If this is right
- SignSGD is minimax optimal in the ℓ1 setting for sparse noise problems.
- Extending the sign operator to matrices preserves the optimal scaling for Muon.
- The theoretical bounds accurately predict faster convergence in pretraining large language models like GPT-2.
Where Pith is reading between the lines
- This suggests sign-based methods may be particularly suited for high-dimensional sparse optimization tasks common in deep learning.
- Future work could test if relaxing the separable noise assumption still yields similar benefits.
- Similar analyses might apply to other coordinate-wise optimizers beyond SignSGD and Muon.
Load-bearing premise
The problem is assumed to satisfy ℓ1-norm stationarity and have separable noise that aligns with coordinate-wise updates.
What would settle it
An empirical test on a problem with sparse noise where the convergence rate of SignSGD is measured against SGD to check if the speedup is exactly proportional to the dimension d.
Figures

read the original abstract
Sign-based optimization algorithms, such as SignSGD and Muon, have garnered significant attention for their remarkable performance in training large foundation models. Despite this empirical success, we still lack a theoretical understanding of when and why these sign-based methods outperform vanilla SGD. The core obstacle is that under standard smoothness and finite variance conditions, SGD is known to be minimax optimal for finding stationary points measured by $\ell_2$-norms, thereby fundamentally precluding any complexity gains for sign-based methods in standard settings. To overcome this barrier, we analyze sign-based optimizers leveraging $\ell_1$-norm stationarity, $\ell_\infty$-smoothness, and a separable noise model, which can better capture the coordinate-wise nature of signed updates. Under this distinct problem geometry, we derive matched upper and lower bounds for SignSGD and explicitly characterize the problem class in which SignSGD provably dominates SGD. Specifically, we compare the \emph{upper bound of SignSGD} with the \emph{lower bound of SGD}, illustrating that SignSGD effectively reduces the complexity by a factor of $d$ under \emph{sparse noise}, where $d$ is the problem dimension. Furthermore, we elevate this framework to the matrix domain, providing an equivalent optimal lower bound for the Muon optimizer, proving that extending the sign operator to matrices preserves this optimal scaling with dimensionality. Finally, we bridge our theoretical bounds to practice, demonstrating that the theoretical superiority of SignSGD accurately predicts its faster convergence during the pretraining of a 124M parameter GPT-2 model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a theoretical analysis of sign-based optimizers by replacing standard ℓ₂-smoothness and finite-variance assumptions with ℓ₁-norm stationarity, ℓ∞-smoothness, and a separable (coordinate-wise) noise model. Under this geometry it derives matching upper and lower bounds for SignSGD, constructs hard instances showing that SGD requires Ω(d) more iterations than SignSGD under sparse noise, extends the same lower-bound construction to the matrix sign operator used by Muon, and reports that the predicted advantage appears in the pretraining trajectory of a 124 M-parameter GPT-2 model.
Significance. If the bounds are correct, the work supplies the first explicit characterization of the problem class in which sign-based methods provably improve dimension dependence, together with matching upper/lower bounds and an extension to matrix operators. These elements constitute a substantive contribution to the theory of non-standard first-order methods for high-dimensional, sparse-gradient problems.
minor comments (3)
- [Abstract] Abstract: the statement that SignSGD 'reduces the complexity by a factor of d' should explicitly name the complexity measure (iteration complexity to ε-stationarity in the ℓ₁ norm) and note the dependence on the sparsity parameter.
- The lower-bound construction for SGD (and its matrix analogue for Muon) should be cross-referenced to the precise theorem or proposition number so that readers can immediately locate the hard-instance geometry.
- [Experiments] The GPT-2 experiment is presented as qualitative corroboration; adding a brief quantitative check (e.g., measured gradient sparsity or per-coordinate variance) would strengthen the claimed bridge between theory and practice without altering the paper's scope.
Simulated Author's Rebuttal
We thank the referee for their positive review, accurate summary of our contributions, and recommendation for minor revision. The significance assessment correctly identifies the novelty in providing matching upper and lower bounds under the ℓ1 geometry and the extension to matrix sign operators.
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces ℓ1-norm stationarity, ℓ∞-smoothness, and separable noise as explicit modeling choices to analyze coordinate-wise sign updates, then derives matched upper bounds for SignSGD and lower bounds for SGD directly from these assumptions. The comparison establishing a d-factor improvement under sparse noise follows from the constructed hard instances and bound expressions rather than presupposing the result. No self-citations are load-bearing for the central claims, no parameters are fitted and relabeled as predictions, and the GPT-2 run is presented only as qualitative corroboration outside the formal derivation. The analysis is therefore self-contained against the stated problem geometry.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gradient noise is separable across coordinates
- domain assumption The objective is ℓ∞-smooth
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
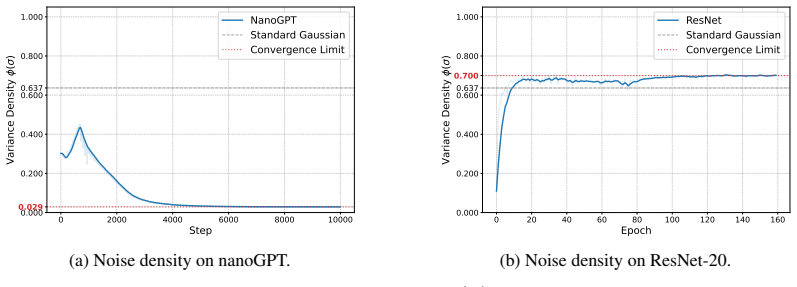
work page internal anchor Pith review arXiv
-
[2]
The geometry of sign gradient descent.arXiv preprint arXiv:2002.08056,
Lukas Balles, Fabian Pedregosa, and Nicolas Le Roux. The geometry of sign gradient descent.arXiv preprint arXiv:2002.08056,
-
[3]
Old optimizer, new norm: An anthology
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology. InOPT 2024: Optimization for Machine Learning,
2024
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
1901
-
[5]
On the Convergence of Muon and Beyond
Da Chang, Yongxiang Liu, and Ganzhao Yuan. On the convergence of Muon and beyond.arXiv preprint arXiv:2509.15816,
work page internal anchor Pith review arXiv
-
[6]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints.arXiv preprint arXiv:2506.15054,
- [7]
-
[8]
SignSVRG: fixing SignSGD via variance reduction.arXiv preprint arXiv:2305.13187,
Evgenii Chzhen and Sholom Schechtman. SignSVRG: fixing SignSGD via variance reduction.arXiv preprint arXiv:2305.13187,
-
[9]
Michael Crawshaw, Chirag Modi, Mingrui Liu, and Robert M Gower. An exploration of non- Euclidean gradient descent: Muon and its many variants.arXiv preprint arXiv:2510.09827,
-
[10]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186,
2019
-
[11]
12 Yiming Dong, Huan Li, and Zhouchen Lin. Convergence rate analysis of LION.arXiv preprint arXiv:2411.07724,
-
[12]
arXiv preprint arXiv:2604.01472 , year=
Zhehang Du and Weijie Su. The newton-muon optimizer.arXiv preprint arXiv:2604.01472,
-
[13]
What really matters in matrix-whitening optimizers? arXiv preprint arXiv:2510.25000,
Kevin Frans, Pieter Abbeel, and Sergey Levine. What really matters in matrix-whitening optimizers? arXiv preprint arXiv:2510.25000,
-
[14]
Limuon: Light and fast muon optimizer for large models.arXiv preprint arXiv:2509.14562, 2025
Feihu Huang, Yuning Luo, and Songcan Chen. LiMuon: Light and fast Muon optimizer for large models.arXiv preprint arXiv:2509.14562,
-
[15]
Ruichen Jiang, Devyani Maladkar, and Aryan Mokhtari. Provable complexity improvement of Ada- Grad over SGD: Upper and lower bounds in stochastic non-convex optimization. InProceedings of the 38th Conference on Learning Theory (COLT), pages 3124–3158, 2025a. Wei Jiang and Lijun Zhang. Convergence analysis of the Lion optimizer in centralized and distribute...
-
[16]
Wei Jiang, Dingzhi Yu, Sifan Yang, Wenhao Yang, and Lijun Zhang. Improved analysis for sign-based methods with momentum updates.arXiv preprint arXiv:2507.12091, 2025b. Richeng Jin, Yufan Huang, Xiaofan He, Huaiyu Dai, and Tianfu Wu. Stochastic-Sign SGD for federated learning with theoretical guarantees.arXiv preprint arXiv:2002.10940,
-
[17]
13 Nikita Kornilov, Philip Zmushko, Andrei Semenov, Mark Ikonnikov, Alexander Gasnikov, and Alexander Beznosikov. Sign operator for coping with heavy-tailed noise in non-convex optimiza- tion: High probability bounds under (L0, L1)-smoothness.arXiv preprint arXiv:2502.07923,
-
[18]
Learning multiple layers of features from tiny images.(2009),
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images.(2009),
2009
-
[19]
Huan Li, Yiming Dong, and Zhouchen Lin. On the O( √ d/T 1/4) convergence rate of rmsprop and its momentum extension measured by ℓ1 norm.Journal of Machine Learning Research (JMLR), 26(131):1–25, 2025a. Jiaxiang Li and Mingyi Hong. A note on the convergence of Muon and further.arXiv preprint arXiv:2502.02900,
-
[20]
Normuon: Making muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025
Zichong Li, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. NorMuon: Making Muon more efficient and scalable.arXiv preprint arXiv:2510.05491, 2025b. Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982,
-
[21]
Preconditioning benefits of spectral orthogonalization in Muon.arXiv preprint arXiv:2601.13474, 2026
Jianhao Ma, Yu Huang, Yuejie Chi, and Yuxin Chen. Preconditioning benefits of spectral orthogonal- ization in Muon.arXiv preprint arXiv:2601.13474,
-
[22]
Muon: Training and trade-offs with latent attention and MoE.arXiv preprint arXiv:2509.24406,
Sushant Mehta, Raj Dandekar, Rajat Dandekar, and Sreedath Panat. Muon: Training and trade-offs with latent attention and moe.arXiv preprint arXiv:2509.24406,
-
[23]
Saurabh Page, Advait Joshi, and SS Sonawane. Muonall: Muon variant for efficient finetuning of large language models.arXiv preprint arXiv:2511.06086,
-
[24]
Unbiased gradient low-rank projection
Rui Pan, Yang Luo, Yuxing Liu, Yang You, and Tong Zhang. Unbiased gradient low-rank projection. arXiv preprint arXiv:2510.17802,
-
[25]
Hanyang Peng, Shuang Qin, Yue Yu, Fangqing Jiang, Hui Wang, and Zhouchen Lin. Simple convergence proof of Adam from a sign-like descent perspective.arXiv preprint arXiv:2507.05966,
-
[26]
Muon is provably faster with momentum variance reduction.arXiv preprint arXiv:2512.16598, 2025
Xun Qian, Hussein Rammal, Dmitry Kovalev, and Peter Richtarik. Muon is provably faster with momentum variance reduction.arXiv preprint arXiv:2512.16598,
-
[27]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V Ugur Guney, Yann Dauphin, and Leon Bottou. Empirical analysis of the Hessian of over-parametrized neural networks.arXiv preprint arXiv:1706.04454,
-
[28]
arXiv preprint arXiv:2507.01598 , year =
Naoki Sato, Hiroki Naganuma, and Hideaki Iiduka. Convergence bound and critical batch size of Muon optimizer.arXiv preprint arXiv:2507.01598,
-
[29]
Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440, 2025
Andrei Semenov, Matteo Pagliardini, and Martin Jaggi. Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440,
-
[30]
Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
Maria-Eleni Sfyraki and Jun-Kun Wang. Lions and Muons: Optimization via stochastic frank-wolfe. arXiv preprint arXiv:2506.04192,
-
[31]
Practical efficiency of muon for pretraining.arXiv preprint arXiv:2505.02222, 2025
Ishaan Shah, Anthony M Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J Shah, et al. Practical efficiency of Muon for pretraining.arXiv preprint arXiv:2505.02222,
-
[32]
On the Convergence Analysis of Muon
Wei Shen, Ruichuan Huang, Minhui Huang, Cong Shen, and Jiawei Zhang. On the convergence analysis of Muon.arXiv preprint arXiv:2505.23737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
AdaMuon: Adaptive Muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive Muon optimizer.arXiv preprint arXiv:2507.11005,
-
[34]
Weijie Su. Isotropic curvature model for understanding deep learning optimization: Is gradient orthogonalization optimal?arXiv preprint arXiv:2511.00674,
-
[35]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review arXiv
-
[36]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi K2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review arXiv
-
[37]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi K2.5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review arXiv
-
[38]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review arXiv
-
[39]
Muon optimizer accelerates grokking.arXiv preprint arXiv:2504.16041,
Amund Tveit, Bjørn Remseth, and Arve Skogvold. Muon optimizer accelerates grokking.arXiv preprint arXiv:2504.16041,
-
[40]
15 Bhavya Vasudeva, Puneesh Deora, Yize Zhao, Vatsal Sharan, and Christos Thrampoulidis. How Muon’s spectral design benefits generalization: A study on imbalanced data.arXiv preprint arXiv:2510.22980, 2025a. Bhavya Vasudeva, Jung Whan Lee, Vatsal Sharan, and Mahdi Soltanolkotabi. The rich and the simple: On the implicit bias of Adam and SGD. InAdvances in...
-
[41]
Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025
Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046,
-
[42]
arXiv preprint arXiv:2307.10053 , year=
Nachuan Xiao, Xiaoyin Hu, and Kim-Chuan Toh. Stochastic subgradient methods with guaranteed global stability in nonsmooth nonconvex optimization.arXiv preprint arXiv:2307.10053,
-
[43]
A tale of two geometries: Adaptive optimizers and non-euclidean descent
Shuo Xie, Mohamad Amin Mohamadi, and Zhiyuan Li. Adam exploitsℓ∞-geometry of loss landscape via coordinate-wise adaptivity. InInternational Conference on Learning Representations (ICLR), pages 7937–7965, 2025a. Shuo Xie, Tianhao Wang, Beining Wu, and Zhiyuan Li. A tale of two geometries: Adaptive optimizers and non-Euclidean descent.arXiv preprint arXiv:2...
-
[44]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. GLM-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review arXiv
-
[45]
AdaGrad meets Muon: Adaptive stepsizes for orthogonal updates
Minxin Zhang, Yuxuan Liu, and Hayden Schaeffer. Adagrad meets Muon: Adaptive stepsizes for orthogonal updates.arXiv preprint arXiv:2509.02981,
-
[46]
On provable benefits of Muon in federated learning.arXiv preprint arXiv:2510.03866,
Xinwen Zhang and Hongchang Gao. On provable benefits of Muon in federated learning.arXiv preprint arXiv:2510.03866,
-
[47]
For the first term, let’s consider a case whereL∞ =∥L∥ 1 is imbalanced and dominated by a certain coordinate, for example, we have L1 > 1 2 ∥L∥1,∥L∥ ∞ =L 1 ≥ 1 2 ∥L∥1 = 1 2 L∞
So we can properly set Li to maximize (24) to get the lower bound of SGD under Assumption 3a. For the first term, let’s consider a case whereL∞ =∥L∥ 1 is imbalanced and dominated by a certain coordinate, for example, we have L1 > 1 2 ∥L∥1,∥L∥ ∞ =L 1 ≥ 1 2 ∥L∥1 = 1 2 L∞. So under this case, E h min t ∥∇f(x t)∥1 i = Ω r d∥L∥∞∆ T ! = Ω r dL∞∆ T ! .(25) Then,...
2025
-
[48]
Because orthogonal transfor- mations preserve singular values, the singular values of ∇F(W t) are exactly the absolute values of the components of ∇f(x t)
Finally, observe the true gradient ∇F(W t) =Q ⊤ diag(∇f(x t))P. Because orthogonal transfor- mations preserve singular values, the singular values of ∇F(W t) are exactly the absolute values of the components of ∇f(x t). Thus, the nuclear norm of the matrix gradient equals the ℓ1-norm of the vector gradient: ∥∇F(W t)∥∗ =∥∇f(x t)∥1. Because the optimization...
2025
-
[49]
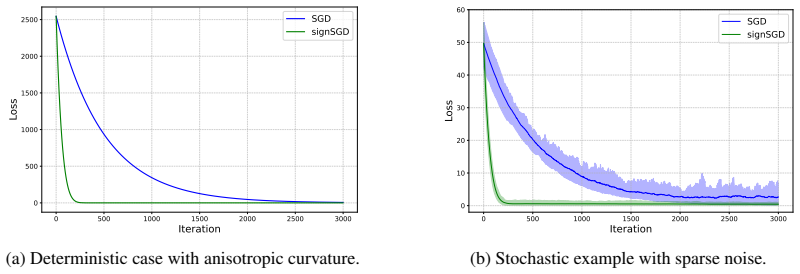
E.2 Experimental Details for CNNs Here, we present the omitted details for the experiments on Figure 2b
exclusively into the first gradient component to simulate extreme noise sparsity. E.2 Experimental Details for CNNs Here, we present the omitted details for the experiments on Figure 2b. We followed the codebase in Bernstein et al. [2018], which can be found athttps://github.com/jxbz/signSGD. To ensure a fully standard and exact mathematical comparison wi...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.