Recognition: unknown
Optimizer-Model Consistency: Full Finetuning with the Same Optimizer as Pretraining Forgets Less
Pith reviewed 2026-05-08 11:56 UTC · model grok-4.3
The pith
Full finetuning with the same optimizer as pretraining forgets less while matching or exceeding new-task performance of other choices including LoRA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimizer-model consistency is the observed and analyzed phenomenon that full finetuning with the identical optimizer employed in pretraining produces less forgetting of pretrained knowledge for the same or better performance on the downstream task than either a different optimizer or LoRA. Optimizers regularize activations in optimizer-specific ways, thereby creating different local landscapes around the pretrained weights. In response, the weight updates required to minimize forgetting must follow particular structures that are naturally generated by reusing the same optimizer. Controlled experiments and a synthetic language-modeling task further show that Muon, when used throughout, tends
What carries the argument
Optimizer-model consistency: the alignment of optimizer choice across pretraining and supervised finetuning that supplies weight updates matching the regularization-induced landscape and thereby lowers forgetting.
If this is right
- Full-parameter finetuning that reuses the pretraining optimizer can achieve a better learning-forgetting tradeoff than parameter-efficient methods such as LoRA.
- Each optimizer induces a distinct activation regularization pattern that dictates which update directions preserve pretrained knowledge.
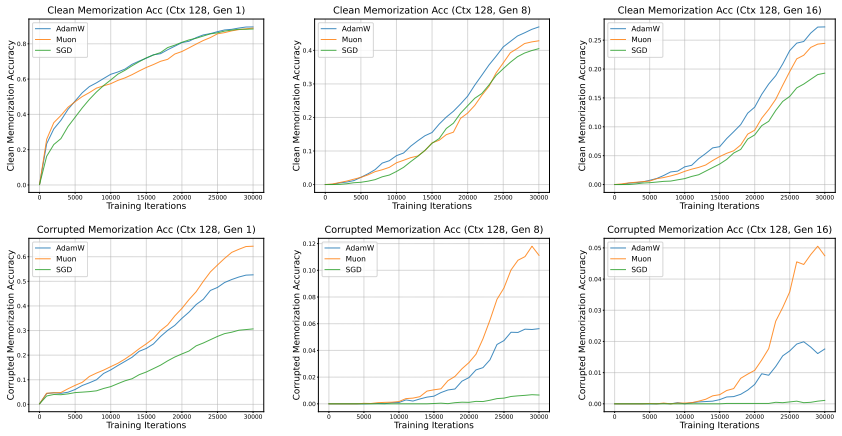
- Muon exhibits a stronger bias toward rote memorization than AdamW, which can impair generalization on reasoning tasks when only limited supervised data are available.
- The structures needed for low-forgetting updates can be obtained simply by continuing with the original optimizer rather than by additional regularization terms.
Where Pith is reading between the lines
- Training pipelines could lock the optimizer choice at the start of pretraining knowing that the same choice will later simplify supervised adaptation.
- The consistency principle may generalize to other sequential training phases such as continued pretraining or instruction tuning on new domains.
- Hybrid strategies that emulate the matching update structure without literal optimizer reuse could be explored when hardware or software constraints prevent exact reuse.
Load-bearing premise
The regularization imposed by each optimizer on activations creates a landscape in which only matching-optimizer updates follow the structures that minimize forgetting of pretraining knowledge.
What would settle it
A controlled ablation that finetunes identical pretrained checkpoints with matched versus deliberately mismatched optimizers under the same data, learning rate, and schedule, then measures retention on held-out pretraining data; a result showing no forgetting reduction or an increase for the matched case would falsify the central claim.
Figures









read the original abstract
Optimizers play an important role in both pretraining and finetuning stages when training large language models (LLMs). In this paper, we present an observation that full finetuning with the same optimizer as in pretraining achieves a better learning-forgetting tradeoff, i.e., forgetting less while achieving the same or better performance on the new task, than other optimizers and, possibly surprisingly, LoRA, during the supervised finetuning (SFT) stage. We term this phenomenon optimizer-model consistency. To better understand it, through controlled experiments and theoretical analysis, we show that: 1) optimizers can shape the models by having regularization effects on the activations, leading to different landscapes around the pretrained checkpoints; 2) in response to this regularization effect, the weight update in SFT should follow some specific structures to lower forgetting of the knowledge learned in pretraining, which can be obtained by using the same optimizer. Moreover, we specifically compare Muon and AdamW when they are employed throughout the pretraining and SFT stages and find that Muon performs worse when finetuned for reasoning tasks. With a synthetic language modeling experiment, we demonstrate that this can come from Muon's strong tendency towards rote memorization, which may hurt pattern acquisition with a small amount of data, as for SFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that full finetuning of LLMs with the same optimizer used in pretraining yields a superior learning-forgetting tradeoff during supervised finetuning (SFT) compared to mismatched optimizers or LoRA; this 'optimizer-model consistency' is supported by controlled experiments and a theoretical analysis arguing that optimizers impose distinct activation regularization, producing different local landscapes around the pretrained checkpoint such that only matching-optimizer updates follow structures minimizing forgetting. A Muon-vs-AdamW comparison shows Muon underperforms on reasoning tasks, attributed via a synthetic language-modeling experiment to Muon's rote-memorization bias in low-data regimes.
Significance. If the empirical observation and mechanistic account hold, the result would have clear practical value for LLM training pipelines by suggesting a low-cost way to mitigate catastrophic forgetting through optimizer matching rather than architectural changes like LoRA. The synthetic experiment is a strength, offering a controlled probe of optimizer-specific inductive biases that goes beyond black-box performance comparisons and could guide future optimizer design.
major comments (3)
- [§4] §4 (mechanistic explanation): the assertion that optimizer-specific activation regularization creates landscapes in which only same-optimizer SFT updates minimize forgetting rests on the unverified premise that this regularization dominates the SFT data distribution; no direct diagnostics (Hessian spectra, activation-norm trajectories, or landscape curvature measurements) are reported to establish causality rather than correlation with optimizer-state carry-over.
- [Experimental sections] Experimental sections (controlled optimizer comparisons): the claim that matching-optimizer full finetuning outperforms LoRA and other optimizers is load-bearing, yet the manuscript provides insufficient detail on whether hyperparameters (learning rate, weight decay, momentum schedules) were matched across conditions or whether optimizer state was reset, leaving open the possibility that observed differences arise from hyperparameter mismatch rather than landscape alignment.
- [Muon/AdamW comparison and synthetic LM experiment] Muon/AdamW comparison and synthetic LM experiment: the post-hoc interpretation that Muon's poorer reasoning performance stems from rote-memorization tendency is plausible but relies on the synthetic setup accurately reflecting the data scale and distribution of real SFT; without ablation on data volume or explicit measurement of memorization vs. generalization metrics, the link to the main forgetting claim remains indirect.
minor comments (2)
- [Abstract] The abstract's phrasing 'possibly surprisingly, LoRA' would benefit from a brief quantitative comparison table in the main text showing LoRA vs. full finetuning under matched optimizer conditions.
- [§4] Notation for optimizer-induced regularization terms is introduced without a summary table; adding one would improve readability when contrasting AdamW and Muon effects.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments help clarify where additional evidence and transparency can strengthen the presentation of optimizer-model consistency. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4] §4 (mechanistic explanation): the assertion that optimizer-specific activation regularization creates landscapes in which only same-optimizer SFT updates minimize forgetting rests on the unverified premise that this regularization dominates the SFT data distribution; no direct diagnostics (Hessian spectra, activation-norm trajectories, or landscape curvature measurements) are reported to establish causality rather than correlation with optimizer-state carry-over.
Authors: We appreciate the referee's emphasis on establishing causality. Section 4 provides a theoretical derivation showing how each optimizer's update rule imposes a distinct regularization on activations, which in turn shapes the local loss landscape around the pretrained checkpoint. The subsequent controlled experiments then demonstrate that only the matching-optimizer trajectory follows the update structure predicted to minimize forgetting. While we agree that direct measurements would further support the mechanistic account, computing full Hessian spectra for LLMs is computationally prohibitive. In the revised manuscript we will add activation-norm trajectories during SFT for both matching and mismatched optimizers; these trajectories directly visualize the regularization effect predicted by the theory and help distinguish it from simple optimizer-state carry-over. revision: partial
-
Referee: [Experimental sections] Experimental sections (controlled optimizer comparisons): the claim that matching-optimizer full finetuning outperforms LoRA and other optimizers is load-bearing, yet the manuscript provides insufficient detail on whether hyperparameters (learning rate, weight decay, momentum schedules) were matched across conditions or whether optimizer state was reset, leaving open the possibility that observed differences arise from hyperparameter mismatch rather than landscape alignment.
Authors: We agree that the experimental protocol must be described with greater precision. Hyperparameters were tuned independently for each optimizer (via grid search on a held-out validation split) to ensure each condition reached its best possible new-task performance; the same search ranges were used across optimizers, but the final selected values differ. For the matching-optimizer condition the full optimizer state (momentum buffers, second-moment estimates, etc.) was restored from the pretrained checkpoint; for all mismatched conditions the optimizer state was freshly initialized according to each optimizer's standard protocol. In the revised manuscript we will insert a new subsection (and an accompanying table) that reports the exact hyperparameter values, the search procedure, and explicit confirmation of state handling, thereby removing any ambiguity about whether differences arise from hyperparameter mismatch. revision: yes
-
Referee: [Muon/AdamW comparison and synthetic LM experiment] Muon/AdamW comparison and synthetic LM experiment: the post-hoc interpretation that Muon's poorer reasoning performance stems from rote-memorization tendency is plausible but relies on the synthetic setup accurately reflecting the data scale and distribution of real SFT; without ablation on data volume or explicit measurement of memorization vs. generalization metrics, the link to the main forgetting claim remains indirect.
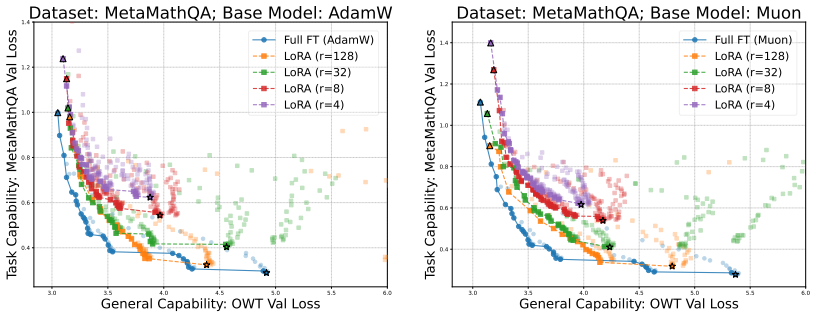
Authors: The synthetic language-modeling experiment was constructed to operate at token counts and sequence lengths comparable to typical SFT corpora, thereby isolating the optimizer's inductive bias under low-data conditions. The observed pattern—Muon rapidly fits exact training tokens while AdamW continues to improve on held-out tokens—directly illustrates the memorization bias we invoke to explain Muon's weaker reasoning performance. We acknowledge that an explicit ablation across data volumes and quantitative memorization metrics (e.g., exact-match rate on training examples versus generalization gap) would make the connection tighter. In the revision we will add these ablations to the appendix and include a short paragraph clarifying the scale alignment between the synthetic setup and the SFT tasks used in the main experiments. revision: partial
Circularity Check
No significant circularity; empirical observation and explanatory analysis remain independent
full rationale
The paper's central claim of optimizer-model consistency is grounded in direct experimental comparisons across optimizers (including Muon vs. AdamW) and finetuning methods (full vs. LoRA) on the learning-forgetting tradeoff. The theoretical analysis in Section 4 posits regularization effects on activations that shape landscapes and require matching-optimizer updates to minimize forgetting, but this is presented as post-hoc explanation derived from the controlled experiments rather than a self-referential derivation. No equations reduce a prediction to a fitted input by construction, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled. The synthetic LM experiment provides separate validation for the Muon memorization observation. The derivation chain is self-contained with falsifiable experimental support.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dion2: A simple method to shrink matrix in muon
Kwangjun Ahn, Noah Amsel, and John Langford. Dion2: A simple method to shrink matrix in muon. arXiv preprint 2512.16928, 2025a. Kwangjun Ahn, Byron Xu, Natalie Abreu, and John Langford. Dion: Distributed orthonormalized updates.arXiv preprint: 2504.05295, 2025b. Kang An, Yuxing Liu, Rui Pan, Yi Ren, Shiqian Ma, Donald Goldfarb, and Tong Zhang. Asgo: Adapt...
-
[2]
The geometry of sign gradient descent.arXiv preprint arXiv:2002.08056,
Lukas Balles, Fabian Pedregosa, and Nicolas Le Roux. The geometry of sign gradient descent.arXiv preprint arXiv:2002.08056,
-
[3]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325,
-
[4]
Yangyi Chen, Binxuan Huang, Yifan Gao, Zhengyang Wang, Jingfeng Yang, and Heng Ji
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. Lora learns less and forgets less.arXiv preprint arXiv:2405.09673,
-
[5]
Why gradients rapidly increase near the end of training.arXiv preprint arXiv: 2506.02285,
Aaron Defazio. Why gradients rapidly increase near the end of training.arXiv preprint arXiv:2506.02285,
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review arXiv
-
[7]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus).arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review arXiv
-
[8]
arXiv preprint arXiv:2207.00099 , year=
Matthew Jagielski, Om Thakkar, Florian Tramer, Daphne Ippolito, Katherine Lee, Nicholas Carlini, Eric Wallace, Shuang Song, Abhradeep Thakurta, Nicolas Papernot, et al. Measuring forgetting of memorized training examples.arXiv preprint arXiv:2207.00099,
-
[9]
Ruichen Jiang, Devyani Maladkar, and Aryan Mokhtari. Provable complexity improvement of ada- grad over sgd: Upper and lower bounds in stochastic non-convex optimization.arXiv preprint arXiv:2406.04592,
-
[10]
Team Kimi, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
work page internal anchor Pith review arXiv
-
[11]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review arXiv
-
[12]
Frederik Kunstner, Jacques Chen, Jonathan Wilder Lavington, and Mark Schmidt. Noise is not the main factor behind the gap between sgd and adam on transformers, but sign descent might be.arXiv preprint arXiv:2304.13960,
-
[13]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, Weixin Xu, Enzhe Lu, Junjie Yan, et al. Muon is scalable for llm training.arXiv preprint arXiv:2502.16982,
work page internal anchor Pith review arXiv
-
[14]
Adagrad under anisotropic smoothness
Yuxing Liu, Rui Pan, and Tong Zhang. Adagrad under anisotropic smoothness.arXiv preprint arXiv:2406.15244,
-
[15]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983,
work page internal anchor Pith review arXiv
-
[16]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review arXiv
-
[17]
Sculpting subspaces: Constrained full fine-tuning in llms for continual learning, 2025
Nikhil Shivakumar Nayak, Krishnateja Killamsetty, Ligong Han, Abhishek Bhandwaldar, Prateek Chanda, Kai Xu, Hao Wang, Aldo Pareja, Oleg Silkin, Mustafa Eyceoz, et al. Sculpting subspaces: Constrained full fine-tuning in llms for continual learning.arXiv preprint arXiv:2504.07097,
-
[18]
Unbiased gradient low-rank projection
Rui Pan, Yang Luo, Yuxing Liu, Yang You, and Tong Zhang. Unbiased gradient low-rank projection. arXiv preprint arXiv:2510.17802,
-
[19]
Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529, 2025
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training deep learning models with norm-constrained lmos.arXiv preprint arXiv:2502.07529,
-
[20]
icarl: Incre- mental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incre- mental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010,
2001
-
[21]
On the Convergence of Adam and Beyond
Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond.arXiv preprint arXiv:1904.09237,
work page Pith review arXiv 1904
-
[22]
(How) Learning Rates Regulate Catastrophic Overtraining
Mark Rofin, Aditya Varre, and Nicolas Flammarion. (how) learning rates regulate catastrophic over- training.arXiv preprint arXiv:2604.13627,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440, 2025
14 Andrei Semenov, Matteo Pagliardini, and Martin Jaggi. Benchmarking optimizers for large language model pretraining.arXiv preprint arXiv:2509.01440,
-
[24]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202,
work page internal anchor Pith review arXiv 2002
-
[25]
Lora vs full fine-tuning: An illusion of equivalence
ReeceShuttleworth, JacobAndreas, AntonioTorralba, andPratyushaSharma. Loravsfullfine-tuning: An illusion of equivalence.arXiv preprint arXiv:2410.21228,
-
[26]
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov
Jacob Mitchell Springer, Sachin Goyal, Kaiyue Wen, Tanishq Kumar, Xiang Yue, Sadhika Malladi, Graham Neubig, and Aditi Raghunathan. Overtrained language models are harder to fine-tune. arXiv preprint arXiv:2503.19206,
-
[27]
Less regret via online conditioning.arXiv preprint arXiv:1002.4862,
Matthew Streeter and H Brendan McMahan. Less regret via online conditioning.arXiv preprint arXiv:1002.4862,
-
[28]
Weijie Su. Isotropic curvature model for understanding deep learning optimization: Is gradient or- thogonalization optimal?arXiv preprint arXiv:2511.00674,
-
[29]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review arXiv
-
[30]
SOAP: Improving and Stabilizing Shampoo using Adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. Soap: Improving and stabilizing shampoo using adam.arXiv preprint arXiv:2409.11321,
work page internal anchor Pith review arXiv
-
[31]
Muon outperforms Adam in tail-end associative memory learning.arXiv preprint arXiv:2509.26030, 2025
Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, MingyiHong, andVincentYFTan. Muonoutperformsadamintail-endassociativememorylearning. arXiv preprint arXiv:2509.26030,
-
[32]
Magicoder: Empow- ering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empowering code generation with oss-instruct.arXiv preprint arXiv:2312.02120,
-
[33]
Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025
Kaiyue Wen, Xingyu Dang, Kaifeng Lyu, Tengyu Ma, and Percy Liang. Fantastic pretraining opti- mizers and where to find them 2.1: Hyperball optimization, 12 2025a. URLhttps://tinyurl.com/ muonh. Kaiyue Wen, David Hall, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them.arXiv preprint arXiv:2509.02046, 2025b. 15 Martin Wistu...
-
[34]
Shuo Xie, Tianhao Wang, Sashank Reddi, Sanjiv Kumar, and Zhiyuan Li. Structured preconditioners in adaptive optimization: A unified analysis.arXiv preprint arXiv:2503.10537,
-
[35]
Controlled llm training on spectral sphere.arXiv preprint arXiv: 2601.08393,
Tian Xie, Haoming Luo, Haoyu Tang, Yiwen Hu, Jason Klein Liu, Qingnan Ren, Yang Wang, Wayne Xin Zhao, Rui Yan, Bing Su, et al. Controlled llm training on spectral sphere.arXiv preprint arXiv:2601.08393,
-
[36]
Ruihan Xu, Jiajin Li, and Yiping Lu. On the width scaling of neural optimizers under matrix operator norms i: Row/column normalization and hyperparameter transfer.arXiv preprint arXiv:2603.09952,
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review arXiv
-
[38]
A spectral condition for feature learning
Greg Yang, James B Simon, and Jeremy Bernstein. A spectral condition for feature learning.arXiv preprint arXiv:2310.17813,
-
[39]
Yang You, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar, Srinadh Bhojanapalli, Xiaodan Song, James Demmel, Kurt Keutzer, and Cho-Jui Hsieh. Large batch optimization for deep learning: Training bert in 76 minutes.arXiv preprint arXiv:1904.00962,
-
[40]
StoSignSGD: Unbiased Structural Stochasticity Fixes SignSGD for Training Large Language Models
Dingzhi Yu, Rui Pan, Yuxing Liu, and Tong Zhang. Stosignsgd: Unbiased structural stochasticity fixes signsgd for training large language models.arXiv preprint arXiv:2604.15416,
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284,
work page internal anchor Pith review arXiv
-
[42]
Huizhuo Yuan, Yifeng Liu, Shuang Wu, Xun Zhou, and Quanquan Gu. Mars: Unleashing the power of variance reduction for training large models.arXiv preprint arXiv:2411.10438,
-
[43]
Adadelta: an adaptive learning rate method.arXiv preprint arXiv:1212.5701,
Matthew D Zeiler. Adadelta: an adaptive learning rate method.arXiv preprint arXiv:1212.5701,
-
[44]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471,
work page internal anchor Pith review arXiv
-
[45]
Understanding deep learning requires rethinking generalization
Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization.arXiv preprint arXiv:1611.03530,
work page internal anchor Pith review arXiv
-
[46]
Why transform- ers need adam: A hessian perspective.arXiv preprint arXiv:2402.16788, 2024a
Yushun Zhang, Congliang Chen, Tian Ding, Ziniu Li, Ruoyu Sun, and Zhi-Quan Luo. Why transform- ers need adam: A hessian perspective.arXiv preprint arXiv:2402.16788, 2024a. Yushun Zhang, Congliang Chen, Ziniu Li, Tian Ding, Chenwei Wu, Diederik P Kingma, Yinyu Ye, Zhi-Quan Luo, and Ruoyu Sun. Adam-mini: Use fewer learning rates to gain more.arXiv preprint ...
-
[47]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Association for Computational Linguistics. URL http://arxiv.org/abs/2403.13372. 16 A Experiment Settings A.1 Experiment Settings in Section 2 The GPT-2 pretraining experiments are done with 4 NVIDIA RTX A6000 GPUs with 48 GB of memory, GPT-2 SFT experiments with 1 A6000 GPU, and Llama-2-7B finetuning experiments with 4 A6000 GPUs. All experiments are cond...
work page internal anchor Pith review arXiv 2022
-
[48]
20 Algorithm 2Column Max Descent (A∞,∞) 1:Input:W 0 ∈R m×n, the number of iterationsT, schedule{ηt}T−1 t=0 , momentumβ 2:InitializeM −1 = 0∈R m×n 3:fort= 0toT−1do 4:Obtain gradientG t atW t 5:M t =βM t−1 + (1−β)G t 6:ComputeU t by[U t]i,j = ( R kj ,if|[M t]i,j|= max l∈[m] |[Mt]l,j|, 0,else. , wherek j denotes the number ofM t entries such that|[Mt]i,j|= m...
2024
-
[49]
Here, LoRA rank 64 shows a greater forgetting compared to rank 256, mainly because rank 256 diverges for lr=5e-4, and a smaller learning rate leads to less forgetting
with our Llama results, as presented in Figure 8, where we can observe in the left figure that LoRA learns less (lower math score) and forgets less (higher general score) if we all choose the learning rates leading to the best math performance. Here, LoRA rank 64 shows a greater forgetting compared to rank 256, mainly because rank 256 diverges for lr=5e-4...
2024
-
[50]
0 500 1000 1500 2000 2500 3000 3500 4000 Training Iterations 0.40 0.45 0.50 0.55 0.60 0.65 0.70 0.75 0.80Activation Sparsity attn.qkv Average Input Sparsity 1, (AdamW) 1, (SignSGD) 2, 2 , 1, 1 0 500 1000 1500 2000 2500 3000 3500 4000 Training Iterations 0.60 0.65 0.70 0.75 0.80Activation Sparsity attn.proj Average Input Sparsity 1, (AdamW) 1, (SignSGD) 2,...
2000
-
[51]
B.2 More Detailed Activation Plots In Figures 10 and 11, we present the average activation sparsity of detailed modules and specific ac- tivation splits
We consider 2 linear layers for attention modules: the QKV projection (attn.qkv) and attention output projection (attn.proj); 2 linear layers for FFN modules: the up projection (mlp.fc_1) and down projection (mlp.fc_2). B.2 More Detailed Activation Plots In Figures 10 and 11, we present the average activation sparsity of detailed modules and specific ac- ...
2000
-
[52]
23 •Ifα∈(α 1,∞], based on Lemma 2 and Assumption 4, it holds that ∥∆W∥ α1,β∗ ≤ ∥∆W∥ α,β∗ andE h ∥x∥2 α1 i = Θ E h ∥x∥2 α i
We then discuss the best value ofα, i.e.,α∗, in this case. 23 •Ifα∈(α 1,∞], based on Lemma 2 and Assumption 4, it holds that ∥∆W∥ α1,β∗ ≤ ∥∆W∥ α,β∗ andE h ∥x∥2 α1 i = Θ E h ∥x∥2 α i . Thus, we have ∥∆W∥ 2 α1,β∗ E h ∥x∥2 α1 i =O ∥∆W∥ 2 α,β∗ E h ∥x∥2 α i •Ifα∈[1, α 1), based on Lemma 2 and Assumption 4, it holds that ∥∆W∥ α1,β∗ ≤n 1 α − 1 α1 ∥∆W∥ α,β∗ andE ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.