Recognition: unknown
Why Global LLM Leaderboards Are Misleading: Small Portfolios for Heterogeneous Supervised ML
Pith reviewed 2026-05-08 12:01 UTC · model grok-4.3
The pith
Global Bradley-Terry rankings of LLMs are misleading because nearly two-thirds of decisive votes cancel out under structured heterogeneity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
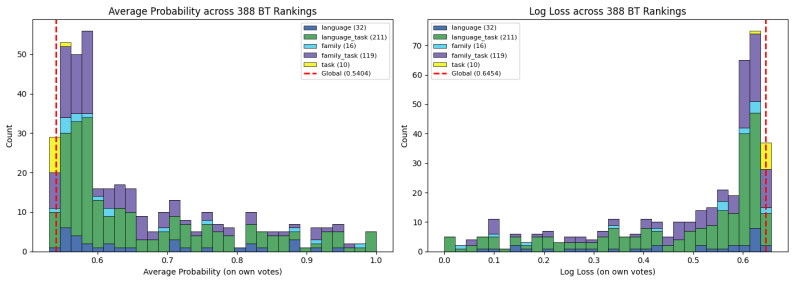
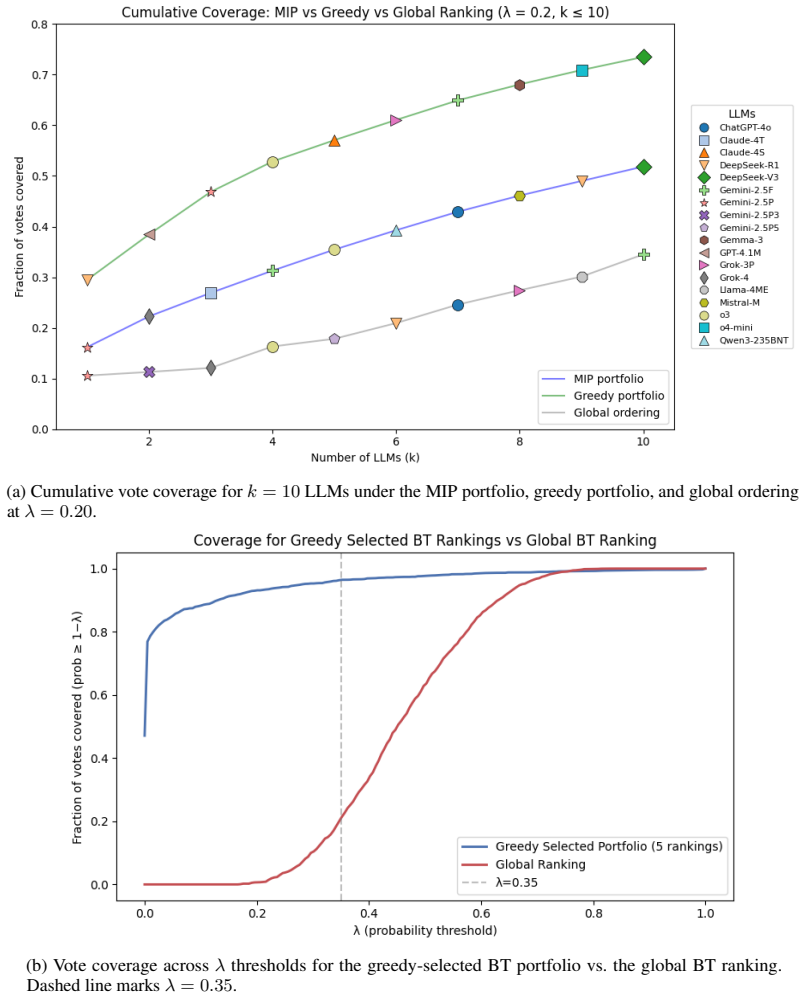
The best-fit global BT ranking is misleading: nearly 2/3 of decisive votes cancel out, top-50 models are statistically indistinguishable with pairwise win probabilities ≤0.53, and language-driven grouping yields two orders of magnitude higher ELO spread. (λ, ν)-portfolios recover five distinct BT rankings covering >96% of votes versus 21% for the global ranking, and a portfolio of six LLMs covers twice as many votes as the global top-six.
What carries the argument
(λ, ν)-portfolios: small sets of models that achieve prediction error at most λ while covering at least ν fraction of users, formulated as a set-cover problem with VC-dimension guarantees.
If this is right
- Leaderboards should report multiple small portfolios rather than one global ranking to reflect coherent subpopulations.
- A portfolio of six LLMs covers twice the votes of the global top-six, showing that modest sets suffice for high coverage.
- The same portfolio construction applied to fairness-regularized classifiers on COMPAS data identifies blind spots in the dataset.
- Language families produce internally consistent but mutually conflicting rankings, so global aggregation erases most signal.
- Five recovered rankings together account for over 96 percent of observed votes, demonstrating that the heterogeneity is low-dimensional.
Where Pith is reading between the lines
- If language remains the dominant grouping factor on new tasks, the same five portfolios could be reused across creative writing, coding, and reasoning benchmarks.
- Policymakers could run the portfolio construction on fairness-sensitive datasets to surface which subpopulations are poorly served by any single model.
- The set-cover formulation with VC guarantees may extend directly to other heterogeneous ranking settings such as product recommendations or clinical treatment selection.
- Tracking how the recovered portfolios change when new languages or tasks are added would test the claimed stability without assuming the current five suffice forever.
Load-bearing premise
The heterogeneity in preferences is structured enough, primarily by language, and stable enough that the recovered portfolios remain effective for new users and tasks outside the Arena sample.
What would settle it
Collect a fresh set of pairwise comparisons from a different user population or new tasks and check whether the five portfolios still cover over 90 percent of votes or whether the global ranking covers a comparable fraction.
Figures








read the original abstract
Ranking LLMs via pairwise human feedback underpins current leaderboards for open-ended tasks, such as creative writing and problem-solving. We analyze ~89K comparisons in 116 languages from 52 LLMs from Arena, and show that the best-fit global Bradley-Terry (BT) ranking is misleading. Nearly 2/3 of the decisive votes cancel out, and even the top 50 models according to the global BT ranking are statistically indistinguishable (pairwise win probabilities are at most 0.53 within the top 50 models). We trace this failure to strong, structured heterogeneity of opinions across language, task, and time. Moreover, we find an important characteristic - *language* plays a key role. Grouping by language (and families) increases the agreement of votes massively, resulting in two orders of magnitude higher spread in the ELO scores (i.e., very consistent rankings). What appears as global noise is in fact a mixture of coherent but conflicting subpopulations. To address such heterogeneity in supervised machine learning, we introduce the framework of $(\lambda, \nu)$-portfolios, which are small sets of models that achieve a prediction error at most $\lambda$, "covering" at least a $\nu$ fraction of users. We formulate this as a variant of the set cover problem and provide guarantees using the VC dimension of the underlying set system. On the Arena data, our algorithms recover just 5 distinct BT rankings that cover over 96% of votes at a modest $\lambda$, compared to the 21% coverage by the global ranking. We also provide a portfolio of 6 LLMs that cover twice as many votes as the top-6 LLMs from a global ranking. We further construct portfolios for a classification problem on the COMPAS dataset using an ensemble of fairness-regularized classification models and show that these portfolios can be used to detect blind spots in the data, which might be of independent interest to policymakers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes ~89K pairwise human comparisons from the LMSYS Chatbot Arena across 52 LLMs and 116 languages. It shows that the global Bradley-Terry ranking is misleading because nearly two-thirds of decisive votes cancel out and the top-50 models are statistically indistinguishable (pairwise win probabilities ≤0.53). The authors attribute this to structured heterogeneity, with language playing a key role in increasing ELO spread by two orders of magnitude. They introduce (λ, ν)-portfolios as small sets of models achieving prediction error at most λ while covering at least a ν fraction of users, formulated as a variant of the set-cover problem with VC-dimension guarantees. On the Arena data, 5 such portfolios cover over 96% of votes compared to 21% for the global ranking; a 6-model portfolio covers twice as many votes as the global top-6. The framework is also applied to the COMPAS dataset to detect data blind spots via fairness-regularized ensembles.
Significance. If the empirical claims on vote cancellation and coverage hold and the VC-dimension analysis is tightened, the work provides a concrete demonstration that global leaderboards obscure coherent subpopulations and offers a set-cover-based framework for constructing small, high-coverage model portfolios in heterogeneous supervised ML. Strengths include the use of large-scale public Arena data, the independent set-cover reduction (not circular with the BT fit), and the dual application to LLM evaluation and fairness auditing on COMPAS. These elements could influence leaderboard design and user-model matching if the language-driven structure generalizes.
major comments (3)
- [§3] §3 (Arena data analysis): The Bradley-Terry fitting procedure is not specified in detail, including the optimization algorithm, tie handling, or any regularization. This is load-bearing for the central claims of ~2/3 vote cancellation and statistical indistinguishability of the top-50 models (pairwise win probabilities ≤0.53), as these quantities depend directly on the fitted parameters.
- [§4.2] §4.2 (set-cover formulation and VC-dimension guarantees): The paper invokes VC-dimension bounds for the (λ, ν)-portfolio set system but does not instantiate or bound the VC dimension for the empirical 89K-vote Arena data (or the COMPAS application). Without this, it is impossible to assess whether the theoretical guarantees support the reported 96% coverage or are merely existential.
- [§5] §5 (portfolio evaluation and generalization): The claim that 5 BT rankings cover >96% of votes (vs. 21% global) and that a 6-model portfolio covers twice as many votes as the global top-6 is purely in-sample. No temporal, task, or user hold-out validation is provided to test whether the recovered portfolios remain effective on new data, which is required to substantiate the utility for new users/tasks stated in the introduction and conclusion.
minor comments (2)
- [§4.1] The definition of the (λ, ν)-portfolio in §4.1 uses 'prediction error at most λ' without clarifying whether this is 0-1 loss, cross-entropy, or another metric, and how it is estimated from the pairwise votes.
- Table or figure reporting the exact λ and ν values used for the 5-portfolio recovery and the 6-model portfolio would improve clarity and allow direct comparison to the global baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications on our methods and indicating where we will revise the manuscript for greater rigor and transparency.
read point-by-point responses
-
Referee: [§3] §3 (Arena data analysis): The Bradley-Terry fitting procedure is not specified in detail, including the optimization algorithm, tie handling, or any regularization. This is load-bearing for the central claims of ~2/3 vote cancellation and statistical indistinguishability of the top-50 models (pairwise win probabilities ≤0.53), as these quantities depend directly on the fitted parameters.
Authors: We agree that the Bradley-Terry fitting details require expansion for reproducibility. In the revised manuscript we will add a dedicated paragraph in §3 specifying that we fit the model via maximum likelihood estimation using the iterative Luce spectral ranking algorithm (equivalent to logistic regression on the pairwise outcomes), that ties are excluded from the likelihood as non-decisive, and that no parameter regularization is applied. These choices directly produce the reported ~2/3 cancellation rate and the pairwise win probabilities ≤0.53 within the top 50. The associated code will be released with the revision. revision: yes
-
Referee: [§4.2] §4.2 (set-cover formulation and VC-dimension guarantees): The paper invokes VC-dimension bounds for the (λ, ν)-portfolio set system but does not instantiate or bound the VC dimension for the empirical 89K-vote Arena data (or the COMPAS application). Without this, it is impossible to assess whether the theoretical guarantees support the reported 96% coverage or are merely existential.
Authors: The VC-dimension analysis supplies a general sample-complexity guarantee for the existence of small (λ, ν)-portfolios under the set-cover formulation; it is not intended to predict or bound the observed in-sample coverage. The 96% figure is obtained by direct application of the greedy algorithm to the 89K observed votes. In the revision we will explicitly distinguish these roles in §4.2, state that the hypothesis class has VC dimension at most 52 (the number of distinct LLMs), and note that this loose bound is not used to compute the empirical coverage. The same clarification will be added for the COMPAS application. revision: partial
-
Referee: [§5] §5 (portfolio evaluation and generalization): The claim that 5 BT rankings cover >96% of votes (vs. 21% global) and that a 6-model portfolio covers twice as many votes as the global top-6 is purely in-sample. No temporal, task, or user hold-out validation is provided to test whether the recovered portfolios remain effective on new data, which is required to substantiate the utility for new users/tasks stated in the introduction and conclusion.
Authors: We acknowledge that all reported coverage numbers are in-sample. The manuscript’s central contribution is to exhibit the existence of small, high-coverage portfolios that reveal structured heterogeneity within the given Arena snapshot. We agree that temporal or user-level hold-out validation would strengthen claims about utility for future users. The public Arena release lacks reliable user identifiers and clean temporal splits, precluding straightforward out-of-sample tests without new data collection. In the revision we will add an explicit limitations paragraph in §5 and the conclusion that states this constraint and outlines how streaming Arena data could be used for future temporal validation. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's central results are empirical computations performed on the external Arena dataset (~89K votes) using standard Bradley-Terry fitting, followed by direct measurement of vote coverage percentages (21% global vs. 96% for the recovered 5 rankings). The (λ, ν)-portfolio framework is introduced as a new set-cover formulation whose VC-dimension guarantees are drawn from standard learning theory rather than self-citation or data-specific fitting. No claimed quantity (ELO spreads, coverage figures, or portfolio sizes) is defined in terms of itself or recovered by construction from a fitted parameter; the COMPAS application is likewise an independent empirical demonstration. The analysis therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- λ
- ν
axioms (1)
- domain assumption The collection of user-model sets has finite VC dimension
invented entities (1)
-
(λ, ν)-portfolio
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Constructing. SIAM Journal on Computing , author =. doi:10.1137/16M1061850 , abstract =
-
[2]
Journal of the Operational Research Society , author =
Optimal portfolios using linear programming models , volume =. Journal of the Operational Research Society , author =. 2004 , pages =. doi:10.1057/palgrave.jors.2601765 , abstract =
-
[3]
Zhuo, Zhengjia and Nagarajan, Viswanath , month = may, year =. A. doi:10.48550/arXiv.2505.15641 , abstract =
-
[4]
Probability
Hoeffding, Wassily , editor =. Probability. The. 1994 , doi =
1994
-
[5]
Chen, Violet (Xinying) and Hooker, J. N. , month = feb, year =. A. Proceedings of the. doi:10.1145/3375627.3375844 , abstract =
-
[6]
Journal of Algorithms , author =
Bicriteria. Journal of Algorithms , author =. 1998 , keywords =. doi:10.1006/jagm.1998.0930 , abstract =
-
[7]
Byrka, Jarosław and Fleszar, Krzysztof and Rybicki, Bartosz and Spoerhase, Joachim , month = dec, year =. Bi-. Proceedings of the 2015. doi:10.1137/1.9781611973730.49 , pages =
-
[8]
An. Management Science , author =. 1984 , keywords =. doi:10.1287/mnsc.30.11.1268 , abstract =
-
[9]
Operations Research , author =
Diversity. Operations Research , author =. 2008 , keywords =. doi:10.1287/opre.1070.0413 , abstract =
-
[10]
Mathematical Programming , author =
New approaches to multi-objective optimization , volume =. Mathematical Programming , author =. 2014 , keywords =. doi:10.1007/s10107-013-0703-7 , abstract =
-
[11]
Evolutionary. ACM Comput. Surv. , author =. 2021 , pages =. doi:10.1145/3470971 , abstract =
-
[12]
A theory of fairness and social welfare , isbn =
Fleurbaey, Marc and Maniquet, François , month = jan, year =. A theory of fairness and social welfare , isbn =
-
[13]
INFORMS Journal on Computing , author =
Approximation. INFORMS Journal on Computing , author =. 2021 , keywords =. doi:10.1287/ijoc.2020.1028 , abstract =
-
[14]
Glaßer, Christian and Reitwießner, Christian and Schmitz, Heinz and Witek, Maximilian , editor =. Approximability and. Programs,. 2010 , keywords =. doi:10.1007/978-3-642-13962-8_20 , abstract =
-
[15]
Theory of Computing Systems , author =
The. Theory of Computing Systems , author =. 2022 , note =. doi:10.1007/s00224-021-10066-5 , abstract =
-
[16]
Operations Research , author =
Risk-. Operations Research , author =. 2018 , keywords =. doi:10.1287/opre.2018.1729 , abstract =
-
[17]
The Review of Economic Studies , author =
When. The Review of Economic Studies , author =. 2023 , pages =. doi:10.1093/restud/rdac050 , abstract =
-
[18]
INFORMS Journal on Applied Analytics , author =
Bus. INFORMS Journal on Applied Analytics , author =. 2020 , keywords =. doi:10.1287/inte.2019.1015 , abstract =
-
[19]
Proceedings of the National Academy of Sciences , author =
Optimizing schools’ start time and bus routes , volume =. Proceedings of the National Academy of Sciences , author =. 2019 , pages =. doi:10.1073/pnas.1811462116 , abstract =
-
[20]
Operations Research , author =
Reshaping. Operations Research , author =. doi:10.1287/opre.2022.0035 , abstract =
-
[21]
Multi-. Management Science , author =. 1977 , pages =. doi:10.1287/mnsc.23.7.703 , abstract =
-
[22]
Esmaeili, Seyed and Brubach, Brian and Srinivasan, Aravind and Dickerson, John , year =. Fair. Advances in
-
[23]
European Journal of Operational Research , author =
Price of fairness in two-agent single-machine scheduling problems , volume =. European Journal of Operational Research , author =. 2019 , keywords =. doi:10.1016/j.ejor.2018.12.048 , abstract =
-
[24]
Chierichetti, Flavio and Kumar, Ravi and Lattanzi, Silvio and Vassilvitskii, Sergei , year =. Fair. Advances in
-
[25]
, month = jan, year =
Menon, Aditya Krishna and Williamson, Robert C. , month = jan, year =. The cost of fairness in binary classification , url =. Proceedings of the 1st
-
[26]
European Journal of Operational Research , author =
Price of. European Journal of Operational Research , author =. 2017 , keywords =. doi:10.1016/j.ejor.2016.08.013 , abstract =
-
[27]
Theory of Computing Systems , author =
The. Theory of Computing Systems , author =. 2012 , keywords =. doi:10.1007/s00224-011-9359-y , abstract =
-
[28]
Operations Research , author =
The. Operations Research , author =. 2011 , note =. doi:10.1287/opre.1100.0865 , abstract =
-
[29]
The. Found. Trends Theor. Comput. Sci. , author =. 2014 , pages =. doi:10.1561/0400000042 , abstract =
-
[30]
Efficient modality selection in multimodal learning , volume =. J. Mach. Learn. Res. , author =. 2024 , pages =
2024
-
[31]
Unsettling race and language:. Language in Society , author =. 2017 , pages =. doi:10.1017/S0047404517000562 , abstract =
-
[32]
1997 , note =
Handbook of autism and pervasive developmental disorders, 2nd ed , isbn =. 1997 , note =
1997
-
[33]
Coates, Jennifer , month = dec, year =. Women,
-
[34]
Assessment of. JAMA Neurology , author =. 2019 , pages =. doi:10.1001/jamaneurol.2018.4249 , abstract =
-
[35]
National Institute on Aging , month = dec, year =
Data shows racial disparities in. National Institute on Aging , month = dec, year =
-
[36]
Symptomatic,. Biomolecules , author =. 2021 , keywords =. doi:10.3390/biom11111635 , abstract =
-
[37]
Autism,. Neurology , author =. 2011 , pages =. doi:10.1212/WNL.0b013e3182166dc7 , abstract =
-
[38]
American Journal of Epidemiology , author =
Is the. American Journal of Epidemiology , author =. 2001 , pages =. doi:10.1093/aje/153.2.132 , abstract =
-
[39]
Journal of Clinical and Experimental Neuropsychology , author =
Greater cognitive deterioration in women than men with. Journal of Clinical and Experimental Neuropsychology , author =. 2012 , pmid =. doi:10.1080/13803395.2012.712676 , abstract =
-
[40]
Psychiatry Research , author =
Speech and language patterns in autism:. Psychiatry Research , author =. 2024 , keywords =. doi:10.1016/j.psychres.2024.116109 , abstract =
-
[41]
Artificial. Diagnostics , author =. 2021 , keywords =. doi:10.3390/diagnostics11081473 , abstract =
-
[42]
Revolutionizing the. Sensors , author =. 2023 , keywords =. doi:10.3390/s23094184 , abstract =
-
[43]
Proceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , author =
Balancing. Proceedings of the 2025 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA) , author =. 2025 , doi =
2025
-
[44]
arXiv preprint arXiv:2502.09724 , year=
Kim, Cheol Woo and Moondra, Jai and Verma, Shresth and Pollack, Madeleine and Kong, Lingkai and Tambe, Milind and Gupta, Swati , month = feb, year =. Navigating the. doi:10.48550/arXiv.2502.09724 , abstract =
-
[45]
Spectral sparsification of graphs: theory and algorithms , volume =. Commun. ACM , author =. 2013 , pages =. doi:10.1145/2492007.2492029 , abstract =
-
[46]
Quantum. Physical Review X , author =. 2020 , pages =. doi:10.1103/PhysRevX.10.021067 , abstract =
-
[47]
Some optimal inapproximability results , volume =. J. ACM , author =. 2001 , pages =. doi:10.1145/502090.502098 , abstract =
-
[48]
On the power of unique 2-prover 1-round games
Khot, Subhash , month = may, year =. On the power of unique 2-prover 1-round games , isbn =. doi:10.1145/509907.510017 , booktitle =
-
[49]
Steinberg, Brooke , month = aug, year =. North
-
[50]
Verma, Shresth and Boehmer, Niclas and Kong, Lingkai and Tambe, Milind , month = sep, year =. Balancing. doi:10.48550/arXiv.2408.12112 , abstract =
-
[51]
Financial Times , author =
Algorithms are deciding who gets organ transplants. Financial Times , author =
-
[52]
Frontiers in Artificial Intelligence , author =
Smart match: revolutionizing organ allocation through artificial intelligence , volume =. Frontiers in Artificial Intelligence , author =. 2024 , pmid =. doi:10.3389/frai.2024.1364149 , abstract =
-
[53]
Group fairness for the allocation of indivisible goods , isbn =
Conitzer, Vincent and Freeman, Rupert and Shah, Nisarg and Vaughan, Jennifer Wormian , month = jan, year =. Group fairness for the allocation of indivisible goods , isbn =. Thirty-. doi:10.1609/aaai.v33i01.33011853 , abstract =
-
[54]
IEEE Transactions on Parallel and Distributed Systems , author =
Multi-. IEEE Transactions on Parallel and Distributed Systems , author =. 2015 , keywords =. doi:10.1109/TPDS.2014.2362139 , abstract =
-
[55]
SIAM Journal on Applied Mathematics , author =
Bounds on. SIAM Journal on Applied Mathematics , author =. 1969 , pages =
1969
-
[56]
American Journal of Human Biology , author =
Food deserts and nutritional risk in. American Journal of Human Biology , author =. 2012 , pages =. doi:10.1002/ajhb.22270 , abstract =
-
[57]
Chouldechova, Alexandra , month = jun, year =. Fair. doi:10.1089/big.2016.0047 , abstract =
-
[58]
Symposium on Discrete Algorithms (SODA) , author =
Algorithms for facility location problems with outliers , issn =. Symposium on Discrete Algorithms (SODA) , author =. 2001 , keywords =
2001
-
[59]
SIAM Journal on Computing , author =
Worst-. SIAM Journal on Computing , author =. 1975 , pages =. doi:10.1137/0204021 , abstract =
-
[60]
and Shmoys, David B
Williamson, David P. and Shmoys, David B. , year =. The
-
[61]
, month = apr, year =
Johnson, David S. , month = apr, year =. Approximation algorithms for combinatorial problems , url =. Symposium on
-
[62]
Mathematical Programming , author =
An improved approximation ratio for the minimum latency problem , volume =. Mathematical Programming , author =. 1998 , keywords =
1998
-
[63]
and Lenstra, Jan Karel and Rinnooy Kan, Alexander H
Lawler, E.L. and Lenstra, Jan Karel and Rinnooy Kan, Alexander H. G. and Shmoys, David B. , year =. The
-
[64]
Hardy, G. H. and Littlewood, J. E. and Pólya, George , year =. Inequalities , url =
-
[65]
Boyd, Stephen and Vandenberghe, Lieven , year =. Convex
-
[66]
Mathematical Programming , author =
An approximation algorithm for the generalized assignment problem , volume =. Mathematical Programming , author =. 1993 , keywords =
1993
-
[67]
Algorithmica , author =
Approximating. Algorithmica , author =. 2004 , keywords =
2004
-
[68]
The Bell System Technical Journal , author =
Bounds for certain multiprocessing anomalies , volume =. The Bell System Technical Journal , author =. 1966 , pages =. doi:10.1002/j.1538-7305.1966.tb01709.x , abstract =
-
[69]
Journal of the ACM , author =
A threshold of ln n for approximating set cover , volume =. Journal of the ACM , author =. 1998 , keywords =
1998
-
[70]
The minimum latency problem , isbn =
Blum, Avrim and Chalasani, Prasad and Coppersmith, Don and Pulleyblank, Bill and Raghavan, Prabhakar and Sudan, Madhu , year =. The minimum latency problem , isbn =. Symposium on. doi:10.1145/195058.195125 , language =
-
[71]
Farhadi, Majid and Toriello, Alejandro and Tetali, Prasad , year =. The. Applied and. doi:10.1137/1.9781611976830.19 , pages =
-
[72]
Manshadi, Vahideh and Rodilitz, Scott , month = jul, year =. Online. Economics and
-
[73]
Nikolić, Goran S. and Dimitrijević, Bojan R. and Nikolić, Tatjana R. and Stojcev, Mile K. , month = jun, year =. A. doi:10.1109/ICEST55168.2022.9828625 , abstract =
-
[74]
Interpolating between k-
Chakrabarty, Deeparnab and Swamy, Chaitanya , year =. Interpolating between k-. International
-
[75]
Azar, Yossi and Taub, Shai , year =. All-. Algorithm. doi:10.1007/978-3-540-27810-8_26 , abstract =
-
[76]
Fairness measures for resource allocation , doi =
Kumar, Amit and Kleinberg, Jon , month = nov, year =. Fairness measures for resource allocation , doi =. Symposium on
-
[77]
Unconstrained submodular maximization with constant adaptive complexity , booktitle =
Chakrabarty, Deeparnab and Swamy, Chaitanya , month = jun, year =. Approximation algorithms for minimum norm and ordered optimization problems , isbn =. Symposium on. doi:10.1145/3313276.3316322 , abstract =
-
[78]
Gupta, Swati and Moondra, Jai and Singh, Mohit , month = jul, year =. Which. Economics and
-
[79]
Kleinberg, Jon , month = jun, year =. Inherent. 2018. doi:10.1145/3219617.3219634 , abstract =
-
[80]
Equality of
Hardt, Moritz and Price, Eric and Price, Eric and Srebro, Nati , year =. Equality of. Advances in
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.