Recognition: 2 theorem links
· Lean TheoremA Rod Flow Model for Adam at the Edge of Stability
Pith reviewed 2026-05-11 00:46 UTC · model grok-4.3
The pith
Rod flow extended to Adam tracks discrete iterates at the edge of stability more accurately than stable flows by modeling parameters and momentum jointly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Representing consecutive iterates as an extended one-dimensional rod in the joint (w, m) phase space, with the second moment treated as a smooth auxiliary variable, produces a continuous-time model that accurately tracks the discrete trajectories of Adam and seven other momentum-based optimizers even when they operate at the edge of stability.
What carries the argument
The rod, an extended one-dimensional object in the joint parameter-first-moment phase space with the second moment as a smooth auxiliary variable, that carries the dynamics from one discrete step to the next.
If this is right
- Rod flow supplies a more faithful continuous description for analyzing training trajectories of adaptive optimizers at the edge of stability.
- The same rod construction works uniformly for eight different momentum and adaptive methods.
- Empirical evaluations on representative architectures confirm superior tracking accuracy over stable flows.
- The model enables study of how momentum and adaptive scaling interact with sharpness changes during training.
Where Pith is reading between the lines
- The joint-phase-space rod may reveal geometric constraints on how far the loss landscape can sharpen before the optimizer escapes the edge-of-stability regime.
- Extending the rod to include weight decay or other regularizers could produce predictions for generalization behavior that differ from current stable-flow analyses.
- If the smooth-auxiliary treatment succeeds for Adam, it suggests similar simplifications may work for other higher-order moments or preconditioners.
Load-bearing premise
Treating the second moment as a smooth auxiliary variable in the joint phase space preserves the essential dynamics without introducing uncontrolled approximation error when iterates reach the edge of stability.
What would settle it
A direct numerical comparison on a standard architecture where the rod flow trajectory deviates from the discrete Adam iterates by a large margin while the iterates remain at the edge of stability would falsify the accuracy claim.
Figures












read the original abstract
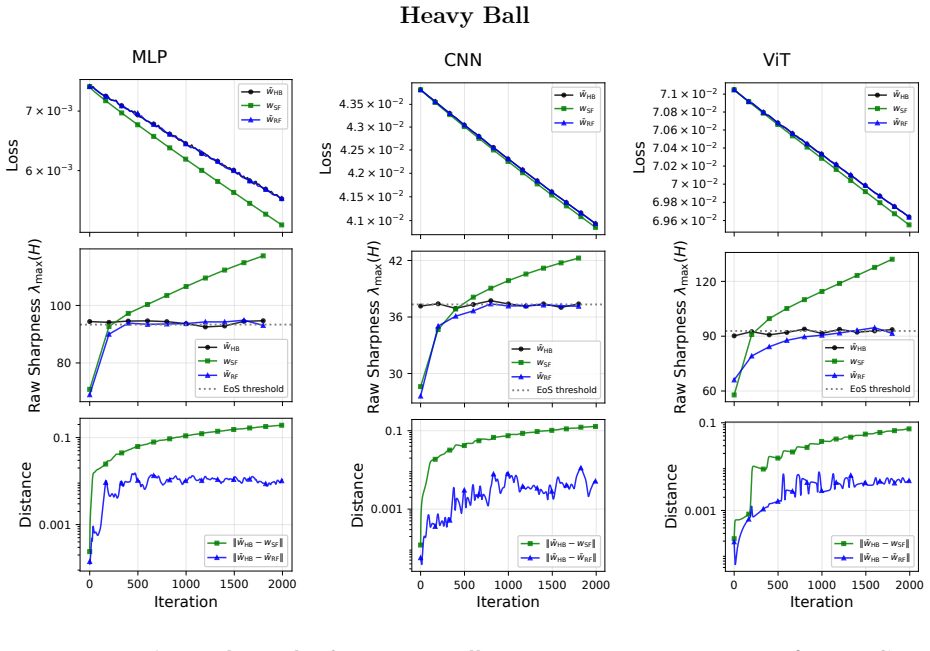
Cohen et al. (arXiv:2207.14484) observed that adaptive gradient methods such as Adam operate at the edge of stability. While there has been significant work on continuous-time modeling of gradient descent at the edge of stability, extending these models to momentum methods remains underdeveloped. In the gradient descent setting, Regis et al. (arXiv:2602.01480) introduced rod flow, which models consecutive iterates as an extended one-dimensional object -- a "rod." Here we extend rod flow to Adam by working in the joint phase space of parameters and first moment $(w, m)$ and treating the second moment $\nu$ as a smooth auxiliary variable. We also develop rod flows for heavy ball momentum, Nesterov momentum, and scalar and per-component versions of RMSProp, Adam, and NAdam. For all eight optimizers, we empirically evaluate rod flow on representative machine learning architectures, where it tracks the discrete iterates through the edge-of-stability regime significantly more accurately than the corresponding stable flow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends the rod-flow continuous model (previously developed for gradient descent at the edge of stability) to Adam and seven related optimizers. It formulates the dynamics in the joint (w, m) phase space while treating the second-moment variable ν as a smooth auxiliary field, derives the corresponding rod flows for heavy-ball momentum, Nesterov momentum, scalar and per-coordinate RMSProp/Adam/NAdam, and reports that these rod flows track discrete iterates through the edge-of-stability regime more accurately than the corresponding stable flows on representative machine-learning architectures.
Significance. If the modeling assumptions hold, the work supplies a unified continuous-time description for adaptive methods operating at the edge of stability, a regime known to be common in practice. The explicit construction for eight distinct optimizers and the empirical comparison against stable flows constitute a concrete advance over prior rod-flow results limited to plain gradient descent. The absence of fitted parameters in the rod construction itself is a methodological strength.
major comments (2)
- [Section 3.2] Section 3.2 (Adam rod flow derivation): the auxiliary-variable treatment of ν is introduced without a quantitative estimate of its variation under period-2 oscillations. Because ν is updated from squared gradients, the same oscillations that the rod is meant to capture can produce O(1) relative changes in ν on the rod timescale; no bound or empirical diagnostic (e.g., max |Δν|/ν over one rod length) is supplied to show that this approximation error remains smaller than the reported improvement over stable flow.
- [Experimental section] Experimental section (comparison tables/figures): the claim that rod flow tracks discrete iterates 'significantly more accurately' is not accompanied by explicit error metrics (e.g., integrated trajectory distance, per-iteration MSE, or normalized L2 deviation) or by a description of how edge-of-stability regimes were identified and controlled across the eight optimizers. Without these numbers it is impossible to judge whether the improvement is load-bearing or an artifact of the ν interpolation.
minor comments (3)
- [Section 3] Notation for the auxiliary field ν is introduced inconsistently between the Adam derivation and the RMSProp/NAdam variants; a single table collecting the auxiliary variables for all eight methods would improve readability.
- [Section 2] The manuscript cites the original rod-flow paper but does not discuss how the joint (w, m) formulation reduces to the scalar case when momentum is absent; a short remark would clarify continuity with prior work.
- [Figures] Figure captions should state the learning-rate schedule and batch size used for each architecture so that the edge-of-stability regime can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below and commit to incorporating the requested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (Adam rod flow derivation): the auxiliary-variable treatment of ν is introduced without a quantitative estimate of its variation under period-2 oscillations. Because ν is updated from squared gradients, the same oscillations that the rod is meant to capture can produce O(1) relative changes in ν on the rod timescale; no bound or empirical diagnostic (e.g., max |Δν|/ν over one rod length) is supplied to show that this approximation error remains smaller than the reported improvement over stable flow.
Authors: We agree that a quantitative diagnostic for the variation of ν is needed to support the auxiliary-variable approximation. In the revision we will add to Section 3.2 an empirical computation of max |Δν|/ν over one rod length for the observed period-2 oscillations across the tested architectures. This will be presented alongside the existing rod-flow comparisons so that readers can directly evaluate the approximation error relative to the improvement over stable flow. revision: yes
-
Referee: [Experimental section] Experimental section (comparison tables/figures): the claim that rod flow tracks discrete iterates 'significantly more accurately' is not accompanied by explicit error metrics (e.g., integrated trajectory distance, per-iteration MSE, or normalized L2 deviation) or by a description of how edge-of-stability regimes were identified and controlled across the eight optimizers. Without these numbers it is impossible to judge whether the improvement is load-bearing or an artifact of the ν interpolation.
Authors: We acknowledge that the original submission lacked explicit numerical error metrics and a precise protocol for identifying edge-of-stability regimes. In the revised experimental section we will include tables reporting integrated trajectory distance, per-iteration MSE, and normalized L2 deviation for rod flow versus stable flow against the discrete iterates for all eight optimizers. We will also add a subsection describing the criteria used to detect and control the edge-of-stability regime (period-2 cycling detection, hyperparameter ranges, and initialization) across architectures. revision: yes
Circularity Check
No significant circularity; empirical tracking claim is independent of modeling assumptions
full rationale
The provided abstract and context describe an extension of prior rod flow to Adam and other optimizers via joint phase space with ν as auxiliary variable, followed by empirical evaluation on ML architectures showing better tracking than stable flow. No equations or claims reduce a 'prediction' or accuracy metric to a fitted parameter or self-referential definition by construction. The self-citation to Regis et al. (arXiv:2602.01480) introduces the base rod flow but does not bear the load of the new accuracy claim, which rests on external discrete-vs-continuous comparisons. This satisfies the criteria for a self-contained derivation against benchmarks, warranting score 0 with no circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The continuous-time rod-flow limit remains a faithful approximation to discrete Adam iterates even when the system sits at the edge of stability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend rod flow to Adam by working in the joint phase space of parameters and first moment (w, m) and treating the second moment ν as a smooth auxiliary variable.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the iterates oscillate every step about their running center... period-doubling bifurcations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2602.01480 , year=
Rod flow: a continuous-time model for gradient descent at the edge of stability , author=. arXiv preprint arXiv:2602.01480 , year=
-
[2]
International Conference on Learning Representations , year=
Gradient descent on neural networks typically occurs at the edge of stability , author=. International Conference on Learning Representations , year=
-
[3]
The Thirteenth International Conference on Learning Representations , year=
Understanding optimization in deep learning with central flows , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
The Eleventh International Conference on Learning Representations , year=
Self-stabilization: the implicit bias of gradient descent at the edge of stability , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
International Conference on Machine Learning , pages=
Understanding Gradient Descent on the Edge of Stability in Deep Learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[6]
Advances in Neural Information Processing Systems , volume=
Learning Threshold Neurons via Edge of Stability , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Agarwala, Atish and Pedregosa, Fabian and Pennington, Jeffrey , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[8]
International Conference on Learning Representations , year=
Implicit gradient regularization , author=. International Conference on Learning Representations , year=
-
[9]
International Conference on Machine Learning , pages=
Beyond the Edge of Stability via Two-step Gradient Updates , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[10]
Adaptive gradient methods at the edge of stability , author=. arXiv preprint arXiv:2207.14484 , year=
-
[11]
The Large Learning Rate Phase of Deep Learning: the Catapult Mechanism , author=. arXiv preprint arXiv:2003.02218 , year=
-
[12]
Transactions on Machine Learning Research , year=
On a Continuous Time Model of Gradient Descent Dynamics and Instability in Deep Learning , author=. Transactions on Machine Learning Research , year=
-
[13]
International Conference on Learning Representations , year=
On the Origin of Implicit Regularization in Stochastic Gradient Descent , author=. International Conference on Learning Representations , year=
-
[14]
International Conference on Learning Representations , year=
Understanding Edge-of-Stability Training Dynamics with a Minimalist Example , author=. International Conference on Learning Representations , year=
-
[15]
International Conference on Machine Learning , pages=
Understanding the Unstable Convergence of Gradient Descent , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[16]
2006 , publisher=
Geometric numerical integration: structure-preserving algorithms for ordinary differential equations , author=. 2006 , publisher=
2006
-
[17]
Journal of Computational Dynamics , year=
Backward error analysis and the qualitative behaviour of stochastic optimization algorithms: application to stochastic coordinate descent , author=. Journal of Computational Dynamics , year=
-
[18]
Journal of Machine Learning Research , volume=
A Continuous-Time Analysis of Momentum Methods , author=. Journal of Machine Learning Research , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Trajectory alignment: understanding the edge of stability phenomenon via bifurcation theory , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
International Conference on Machine Learning , pages=
Stochastic Modified Equations and Adaptive Stochastic Gradient Algorithms , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[21]
Journal of Machine Learning , year=
Beyond the quadratic approximation: the multiscale structure of neural network loss landscapes , volume=. Journal of Machine Learning , year=
-
[22]
Transactions on Machine Learning Research , year=
From stability to chaos: analyzing gradient descent dynamics in quadratic regression , author=. Transactions on Machine Learning Research , year=
-
[23]
The Thirty-Ninth Annual Conference on Neural Information Processing Systems , year=
Understanding the evolution of the neural tangent kernel at the edge of stability , author=. The Thirty-Ninth Annual Conference on Neural Information Processing Systems , year=
-
[24]
1963 , publisher=
Rounding errors in algebraic processes , author=. 1963 , publisher=
1963
-
[25]
1965 , publisher=
The algebraic eigenvalue problem , author=. 1965 , publisher=
1965
-
[26]
International Conference on Learning Representations , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , year=
-
[27]
Incorporating
Dozat, Timothy , booktitle=. Incorporating
-
[28]
and Kale, Satyen and Kumar, Sanjiv , booktitle=
Reddi, Sashank J. and Kale, Satyen and Kumar, Sanjiv , booktitle=. On the Convergence of
-
[29]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[30]
Journal of Machine Learning Research , year =
Yuqing Wang and Zhenghao Xu and Tuo Zhao and Molei Tao , title =. Journal of Machine Learning Research , year =
-
[31]
and Klusowski, Jason Matthew and Shigida, Boris , booktitle =
Cattaneo, Matias D. and Klusowski, Jason Matthew and Shigida, Boris , booktitle =. On the implicit bias of. 2024 , editor =
2024
- [32]
-
[33]
Malladi, Sadhika and Lyu, Kaifeng and Panigrahi, Abhishek and Arora, Sanjeev , booktitle=. On the
-
[34]
International Conference on Learning Representations , year=
Implicit Regularization in Heavy-Ball Momentum Accelerated Stochastic Gradient Descent , author=. International Conference on Learning Representations , year=
-
[35]
USSR Computational Mathematics and Mathematical Physics , volume=
Some methods of speeding up the convergence of iteration methods , author=. USSR Computational Mathematics and Mathematical Physics , volume=
-
[36]
Advances in Neural Information Processing Systems 33 , year=
Stochasticity of Deterministic Gradient Descent: Large Learning Rate for Multiscale Objective Function , author=. Advances in Neural Information Processing Systems 33 , year=
-
[37]
, journal=
Nesterov, Yurii E. , journal=. A method for solving the convex programming problem with convergence rate
-
[38]
Convergence and Dynamical Behavior of the
Barakat, Anas and Bianchi, Pascal , journal=. Convergence and Dynamical Behavior of the. 2021 , publisher=
2021
-
[39]
Journal of Machine Learning Research , volume=
A General System of Differential Equations to Model First-Order Adaptive Algorithms , author=. Journal of Machine Learning Research , volume=
-
[40]
Li, Xinghan and Wen, Haodong and Lyu, Kaifeng , booktitle=
-
[41]
International Conference on Machine Learning , pages=
The Implicit Bias for Adaptive Optimization Algorithms on Homogeneous Neural Networks , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[42]
Dereich, Steffen and Jentzen, Arnulf and Kassing, Sebastian , journal=
-
[43]
and Sarshar, Arash and Sandu, Adrian , journal=
Bhattacharjee, Abhinab and Popov, Andrey A. and Sarshar, Arash and Sandu, Adrian , journal=. Improving the adaptive moment estimation (
-
[44]
Modeling
Heredia, Carlos , journal=. Modeling
-
[45]
Automatica , volume=
A Control Theoretic Framework for Adaptive Gradient Optimizers , author=. Automatica , volume=. 2024 , publisher=
2024
-
[46]
Adaptive preconditioners trigger loss spikes in
Zhiwei Bai and Zhangchen Zhou and Jiajie Zhao and Xiaolong Li and Zhiyu Li and Feiyu Xiong and Hongkang Yang and Yaoyu Zhang and Zhi-Qin John Xu , year=. Adaptive preconditioners trigger loss spikes in
-
[47]
Gradient descent with
Prin Phunyaphibarn and Junghyun Lee and Bohan Wang and Huishuai Zhang and Chulhee Yun , year=. Gradient descent with
-
[48]
Learning multiple layers of features from tiny images , author =
-
[49]
International Conference on Learning Representations , year=
An image is worth 16x16 words: transformers for image recognition at scale , author=. International Conference on Learning Representations , year=
-
[50]
Proceedings of the 35th International Conference on Machine Learning , pages =
Shampoo: preconditioned stochastic tensor optimization , author =. Proceedings of the 35th International Conference on Machine Learning , pages =. 2018 , editor =
2018
-
[51]
, booktitle =
Chen, Xiangning and Liang, Chen and Huang, Da and Real, Esteban and Wang, Kaiyuan and Pham, Hieu and Dong, Xuanyi and Luong, Thang and Hsieh, Cho-Jui and Lu, Yifeng and Le, Quoc V. , booktitle =. Symbolic discovery of optimization algorithms , volume =
-
[52]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.