Recognition: 2 theorem links
· Lean TheoremRandomness is sometimes necessary for coordination
Pith reviewed 2026-05-11 00:55 UTC · model grok-4.3
The pith
Randomness breaks symmetry to allow coordination among identical agents in multi-agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
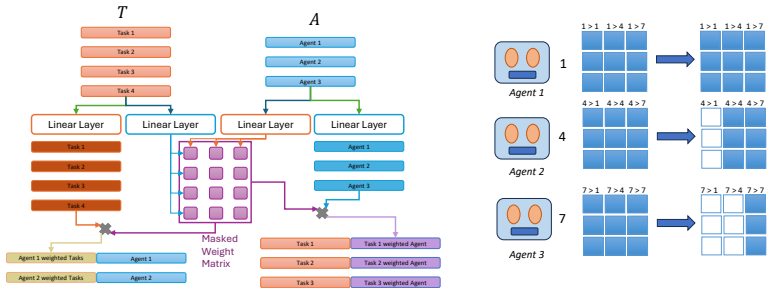
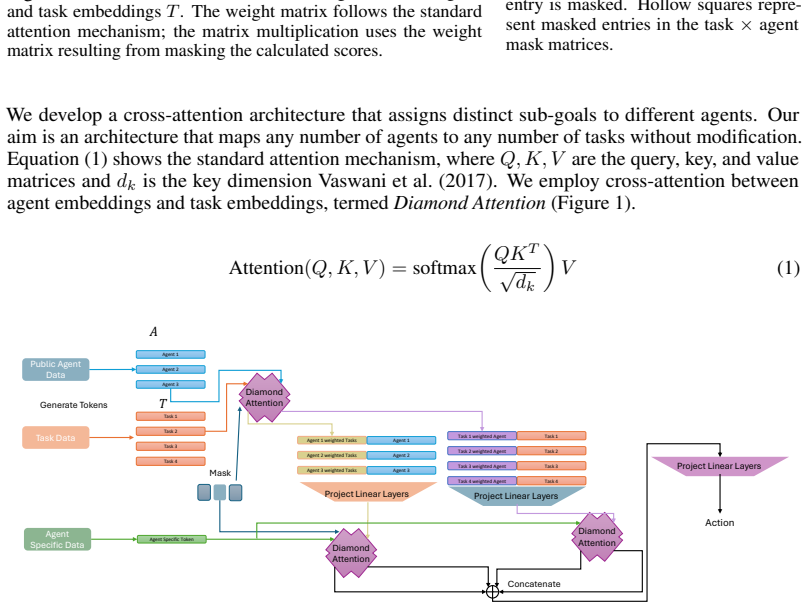
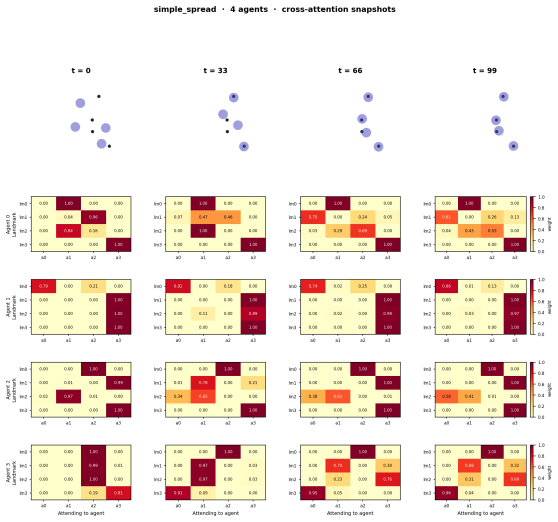
Full parameter sharing combined with permutation-symmetric observations causes deterministic policies to output identical action distributions across agents, which prevents necessary role differentiation in coordination tasks. Diamond Attention addresses this by letting each agent draw an independent random scalar per timestep; these scalars induce a transient ranking used to mask agent-to-agent attention for lower-ranked peers while leaving task-related attention intact, thereby enabling a random-bit coordination protocol.
What carries the argument
Diamond Attention architecture that samples random scalars to induce transient rank orderings for selective masking in cross-attention.
If this is right
- Achieves 1.0 success rate on the perfectly symmetric XOR game, compared to near 0.5 for all deterministic baselines.
- A policy trained on teams of size 4 generalizes zero-shot to team sizes from 2 to 8 in control tasks.
- Enables zero-shot cross-scenario transfer on SMACLite where standard methods cannot transfer due to structural constraints.
- Structured masking via random ranking outperforms unstructured dropout randomness, which achieves 0% win rate.
Where Pith is reading between the lines
- This approach could be adapted to other decentralized systems requiring implicit role assignment without central coordination.
- The necessity of structured randomness may highlight limitations in purely deterministic models for scalable multi-agent systems.
- Future work might explore how the amount of randomness affects performance in partially symmetric environments.
Load-bearing premise
The observations are fully permutation-symmetric, allowing independent random scalars to be sampled and used for ranking without additional communication.
What would settle it
A deterministic algorithm or policy that achieves a success rate substantially higher than 0.5 on the symmetric XOR game while respecting the single-broadcast constraint and full parameter sharing.
Figures



read the original abstract
Full parameter sharing is standard in cooperative multi-agent reinforcement learning (MARL) for homogeneous agents. Under permutation-symmetric observations, however, a shared deterministic policy outputs identical action distributions for every agent, making role differentiation impossible. This failure can theoretically be resolved using symmetry breaking among anonymous identical processors, which requires randomness. We propose Diamond Attention, a cross-attention architecture in which each agent samples a scalar random number per timestep, inducing a transient rank ordering that masks lower-ranked peers from agent-to-agent attention while leaving task attention fully unmasked. This realizes a random-bit coordination protocol in a single broadcast round, and the set-based attention enables zero-shot deployment to teams of different sizes. We evaluate across three regimes that isolate when structured randomness matters. On the perfectly symmetric XOR game, our method achieves $1.0$ success while all deterministic baselines plateau near $0.5$. On control coordination tasks, a policy trained on $N=4$ generalizes zero-shot to $N \in [2,8]$. On SMACLite cross-scenario transfer, we achieve zero-shot transfer where standard baselines cannot transfer due to structural limitations. Furthermore, replacing the structured mask with standard dropout-based randomness results in a 0\% win rate, confirming that protocol-space structure, not stochastic noise, is the operative ingredient. https://anonymous.4open.science/r/randomness-137A/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that full parameter sharing in cooperative MARL for homogeneous agents under permutation-symmetric observations forces identical action distributions from deterministic policies, preventing role differentiation. It proposes Diamond Attention, a cross-attention architecture in which each agent independently samples a scalar random number per timestep to induce a transient rank ordering; this ordering masks lower-ranked peers in agent-to-agent attention while leaving task-relevant attention unmasked. The design realizes a structured random-bit coordination protocol within a single broadcast round and uses set-based attention to support zero-shot deployment to teams of varying sizes. Experiments show 1.0 success on the symmetric XOR game (versus ~0.5 for deterministic baselines), zero-shot generalization from N=4 training to N in [2,8], successful SMACLite cross-scenario transfer, and a dropout ablation yielding 0% win rate that isolates the benefit of structured masking over unstructured noise.
Significance. If the central results hold, the work supplies concrete empirical support for the theoretical necessity of randomness in symmetry breaking under anonymous identical processors, together with a practical architecture that respects single-round broadcast constraints. The perfect XOR performance, the clean structured-vs-unstructured ablation, and the zero-shot size generalization are notable strengths; the latter in particular demonstrates that the set-based attention mechanism can be deployed without retraining. These elements could inform future MARL designs for homogeneous teams where deterministic parameter sharing is otherwise standard.
major comments (1)
- [Experimental Evaluation on XOR Game] The weakest assumption—that observations are fully permutation-symmetric and that independent per-agent random scalars can be sampled and incorporated without violating the single-broadcast-round constraint—is load-bearing for the protocol claim. The manuscript should explicitly verify in the experimental setup (e.g., §4.1 or the XOR environment description) that no implicit asymmetry is introduced by the observation function and that the random scalar is treated strictly as part of the broadcast message.
minor comments (3)
- [Ablation Study] The dropout ablation reports a 0% win rate but does not state the dropout probability or whether the same random-seed protocol was used; adding these details would strengthen reproducibility of the claim that structure, not noise, is operative.
- [Method Description] The set-based attention mechanism enabling zero-shot transfer to different N is central to the practical contribution; the manuscript would benefit from a short explicit statement of how the attention mask and ranking are defined for variable team sizes (e.g., in the method section or an appendix equation).
- [Results] A brief discussion of training variance or seed sensitivity for the reported 1.0 success rate on XOR would help readers assess robustness, especially given the low baseline performance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation. We address the single major comment below and will incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Experimental Evaluation on XOR Game] The weakest assumption—that observations are fully permutation-symmetric and that independent per-agent random scalars can be sampled and incorporated without violating the single-broadcast-round constraint—is load-bearing for the protocol claim. The manuscript should explicitly verify in the experimental setup (e.g., §4.1 or the XOR environment description) that no implicit asymmetry is introduced by the observation function and that the random scalar is treated strictly as part of the broadcast message.
Authors: We agree that explicit verification is warranted. In the revised manuscript we will add to §4.1 (and the XOR environment description) a direct statement that the observation function is strictly permutation-symmetric: every agent receives an identical observation vector regardless of agent ordering. We will further clarify that each agent samples its scalar locally at the start of the timestep and immediately includes this scalar in the single broadcast message; all agents then receive the full set of scalars, compute the identical global ranking, and apply the structured mask. This construction respects the single-broadcast-round constraint while preserving the protocol semantics. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces Diamond Attention as an independent architectural definition: each agent samples a scalar random number to induce a transient rank ordering that masks lower-ranked peers in cross-attention. This protocol is specified without reference to performance metrics or fitted parameters. Empirical results (1.0 success on XOR game, ablation showing structured mask vs. 0% for dropout) are reported outcomes, not derivations that reduce to inputs by construction. The symmetry-breaking motivation is a standard theoretical point, not a self-citation load-bearing step or ansatz smuggled from prior work. No equations equate predictions to fitted values, and zero-shot generalization claims rest on the architecture's set-based property rather than internal fitting. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Observations are permutation-symmetric across agents
- domain assumption Independent per-agent random scalars can be sampled without communication
invented entities (1)
-
Diamond Attention with transient rank ordering
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability uncleareach agent samples a scalar random number per timestep, inducing a transient rank ordering that masks lower-ranked peers from agent-to-agent attention
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearAngluin (1980) proved that symmetry breaking among anonymous processors is impossible deterministically
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
Revisiting Some Common Practices in Cooperative Multi-Agent Reinforcement Learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[2]
Journal of Computer and System Sciences , volume=
On learning to coordinate: Random bits help, insightful normal forms, and competency isomorphisms , author=. Journal of Computer and System Sciences , volume=. 2005 , publisher=
2005
-
[3]
IEEE Transactions on Robotics , year=
Physics-informed multi-agent reinforcement learning for distributed multi-robot problems , author=. IEEE Transactions on Robotics , year=
-
[4]
International Symposium on Distributed Autonomous Robotic Systems , pages=
Vmas: A vectorized multi-agent simulator for collective robot learning , author=. International Symposium on Distributed Autonomous Robotic Systems , pages=. 2022 , organization=
2022
-
[5]
IEEE transactions on signal processing , volume=
Distributed learning in multi-armed bandit with multiple players , author=. IEEE transactions on signal processing , volume=. 2010 , publisher=
2010
-
[7]
Journal of Machine Learning Research , year =
Antonin Raffin and Ashley Hill and Adam Gleave and Anssi Kanervisto and Maximilian Ernestus and Noah Dormann , title =. Journal of Machine Learning Research , year =
-
[8]
Journal of Machine Learning Research , volume=
Benchmarl: Benchmarking multi-agent reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[9]
Mathematics unlimited—2001 and beyond , pages=
The Turing machine paradigm in contemporary computing , author=. Mathematics unlimited—2001 and beyond , pages=. 2001 , publisher=
2001
-
[10]
Conference on Computability in Europe , pages=
On the executability of interactive computation , author=. Conference on Computability in Europe , pages=. 2016 , organization=
2016
-
[11]
Information and computation , volume=
Turing machines, transition systems, and interaction , author=. Information and computation , volume=. 2004 , publisher=
2004
-
[12]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[14]
Journal of Machine Learning Research , volume=
Monotonic value function factorisation for deep multi-agent reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[15]
Applied Intelligence , volume=
A review of cooperative multi-agent deep reinforcement learning , author=. Applied Intelligence , volume=. 2023 , publisher=
2023
-
[16]
Artificial Intelligence Review , volume=
Multi-agent deep reinforcement learning: a survey , author=. Artificial Intelligence Review , volume=. 2022 , publisher=
2022
-
[17]
IEEE Access , volume=
Scaling up multi-agent reinforcement learning: An extensive survey on scalability issues , author=. IEEE Access , volume=. 2024 , publisher=
2024
-
[18]
arXiv preprint arXiv: 220903859 , author=
A survey on large-population systems and scalable multi-agent reinforcement learning. arXiv preprint arXiv: 220903859 , author=
-
[19]
Advances in neural information processing systems , volume=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in neural information processing systems , volume=
-
[20]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Multiagent reinforcement learning with heterogeneous graph attention network , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. 2022 , publisher=
2022
-
[21]
, author=
Multi-Agent Graph-Attention Communication and Teaming. , author=. AAMAS , volume=
-
[22]
2022 5th International Conference on Artificial Intelligence and Big Data (ICAIBD) , pages=
Attention based large scale multi-agent reinforcement learning , author=. 2022 5th International Conference on Artificial Intelligence and Big Data (ICAIBD) , pages=. 2022 , organization=
2022
-
[23]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
-
[24]
Advances in neural information processing systems , volume=
The surprising effectiveness of ppo in cooperative multi-agent games , author=. Advances in neural information processing systems , volume=
-
[27]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[28]
Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages=
The StarCraft Multi-Agent Challenge , author=. Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages=
-
[29]
International conference on machine learning , pages=
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[30]
arXiv preprint arXiv:2002.03939 , year=
Qatten: A general framework for cooperative multiagent reinforcement learning , author=. arXiv preprint arXiv:2002.03939 , year=
-
[31]
International Conference on Learning Representations , year=
QPLEX: Duplex Dueling Multi-Agent Q-Learning , author=. International Conference on Learning Representations , year=
-
[32]
International Conference on Learning Representations , year=
Learning Nearly Decomposable Value Functions Via Communication Minimization , author=. International Conference on Learning Representations , year=
-
[33]
arXiv preprint arXiv:2010.08531 , year=
Multi-agent collaboration via reward attribution decomposition , author=. arXiv preprint arXiv:2010.08531 , year=
-
[34]
Information and control , volume=
Language identification in the limit , author=. Information and control , volume=. 1967 , publisher=
1967
-
[35]
Synthese , volume=
Learning to coordinate; A recursion theoretic perspective , author=. Synthese , volume=. 1999 , publisher=
1999
-
[36]
Information and Computation , volume=
Secretive interaction: Players and strategies , author=. Information and Computation , volume=. 2024 , publisher=
2024
-
[37]
Cryptology ePrint Archive , year=
The IITM model: a simple and expressive model for universal composability , author=. Cryptology ePrint Archive , year=
-
[38]
Bulletin of the American Mathematical Society , volume=
Some aspects of the sequential design of experiments , author=. Bulletin of the American Mathematical Society , volume=
-
[39]
2019 International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOPT) , pages=
Distributed algorithms for efficient learning and coordination in ad hoc networks , author=. 2019 International Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOPT) , pages=. 2019 , organization=
2019
-
[40]
IEEE/ACM Transactions on Networking , volume=
Multi-user communication networks: A coordinated multi-armed bandit approach , author=. IEEE/ACM Transactions on Networking , volume=. 2019 , publisher=
2019
-
[41]
IEEE Transactions on Signal Processing , volume=
Multi-player multi-armed bandits with collision-dependent reward distributions , author=. IEEE Transactions on Signal Processing , volume=. 2021 , publisher=
2021
-
[42]
Proceedings of the twelfth annual ACM symposium on Theory of computing , pages=
Local and global properties in networks of processors , author=. Proceedings of the twelfth annual ACM symposium on Theory of computing , pages=
-
[43]
Journal of the ACM (JACM) , volume=
Impossibility of distributed consensus with one faulty process , author=. Journal of the ACM (JACM) , volume=. 1985 , publisher=
1985
-
[44]
The American Economic Review , volume=
The electronic mail game: Strategic behavior under ``almost common knowledge'' , author=. The American Economic Review , volume=. 1989 , publisher=
1989
-
[45]
Autonomous Agents and Multi-Agent Systems , pages=
Cooperative multi-agent control using deep reinforcement learning , author=. Autonomous Agents and Multi-Agent Systems , pages=. 2017 , publisher=
2017
-
[47]
Advances in Neural Information Processing Systems , year=
Kaleidoscope: Learnable Masks for Heterogeneous Multi-agent Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[48]
Forty-second International Conference on Machine Learning , year=
GradPS: Resolving Futile Neurons in Parameter Sharing Network for Multi-Agent Reinforcement Learning , author=. Forty-second International Conference on Machine Learning , year=
-
[49]
AAAI Conference on Artificial Intelligence , volume=
From few to more: Large-scale dynamic multiagent curriculum learning , author=. AAAI Conference on Artificial Intelligence , volume=
-
[50]
International Conference on Learning Representations , year=
UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers , author=. International Conference on Learning Representations , year=
-
[52]
arXiv preprint arXiv:2501.13200 , year=
SRMT: shared memory for multi-agent lifelong pathfinding , author=. arXiv preprint arXiv:2501.13200 , year=
-
[53]
Heterogeneous Multi-Agent Reinforcement Learning for Zero-Shot Scalable Collaboration , author=. arXiv preprint arXiv:2404.03869 , year=
-
[54]
Advances in Neural Information Processing Systems , volume=
Multi-Agent Transformer , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
IEEE transactions on robotics , volume=
Consensus-based decentralized auctions for robust task allocation , author=. IEEE transactions on robotics , volume=. 2009 , publisher=
2009
-
[56]
Scientific Reports , volume=
Decentralized adaptive task allocation for dynamic multi-agent systems , author=. Scientific Reports , volume=. 2025 , publisher=
2025
-
[57]
Leslie Lamport , title =
-
[58]
The Knowledge Engineering Review , volume =
Intelligent Agents: Theory and Practice , author =. The Knowledge Engineering Review , volume =
-
[59]
Artificial Intelligence , volume =
Collaborative Plans for Complex Group Action , author =. Artificial Intelligence , volume =
-
[60]
Logics of programs: axiomatics and descriptive power
David Harel. Logics of programs: axiomatics and descriptive power. 1978
1978
-
[61]
Clarkson
Kenneth L. Clarkson. Algorithms for Closest-Point Problems (Computational Geometry). 1985
1985
-
[62]
A More Perfect Union
Barack Obama. A More Perfect Union. 2008
2008
-
[63]
The fountain of youth
Joseph Scientist. The fountain of youth. 2009
2009
-
[64]
Sam Anzaroot and Andrew McCallum , title =
-
[65]
Proceedings of the 20th International Colloquium on Automata, Languages and Programming , series =
Maintaining Discrete Probability Distributions Optimally , author =. Proceedings of the 20th International Colloquium on Automata, Languages and Programming , series =. 1993 , publisher =
1993
-
[66]
Donald E. Knuth. The Art of Computer Programming, Vol. 1: Fundamental Algorithms. 1997
1997
-
[67]
Anisi , title =
David A. Anisi , title =
-
[68]
Local and global properties in networks of processors
Angluin, D. Local and global properties in networks of processors. In Proceedings of the twelfth annual ACM symposium on Theory of computing, pp.\ 82--93, 1980
1980
-
[69]
Vmas: A vectorized multi-agent simulator for collective robot learning
Bettini, M., Kortvelesy, R., Blumenkamp, J., and Prorok, A. Vmas: A vectorized multi-agent simulator for collective robot learning. In International Symposium on Distributed Autonomous Robotic Systems, pp.\ 42--56. Springer, 2022
2022
-
[70]
Benchmarl: Benchmarking multi-agent reinforcement learning
Bettini, M., Prorok, A., and Moens, V. Benchmarl: Benchmarking multi-agent reinforcement learning. Journal of Machine Learning Research, 25 0 (217): 0 1--10, 2024
2024
-
[71]
On learning to coordinate: Random bits help, insightful normal forms, and competency isomorphisms
Case, J., Jain, S., Montagna, F., Simi, G., and Sorbi, A. On learning to coordinate: Random bits help, insightful normal forms, and competency isomorphisms. Journal of Computer and System Sciences, 71 0 (3): 0 308--332, 2005
2005
-
[72]
De Witt, C. S., Gupta, T., Makoviichuk, D., Makoviychuk, V., Torr, P. H., Sun, M., and Whiteson, S. Is independent learning all you need in the starcraft multi-agent challenge? arXiv preprint arXiv:2011.09533, 2020
-
[73]
J., Lynch, N
Fischer, M. J., Lynch, N. A., and Paterson, M. S. Impossibility of distributed consensus with one faulty process. Journal of the ACM (JACM), 32 0 (2): 0 374--382, 1985
1985
-
[74]
Revisiting some common practices in cooperative multi-agent reinforcement learning
Fu, W., Yu, C., Xu, Z., Yang, J., and Wu, Y. Revisiting some common practices in cooperative multi-agent reinforcement learning. In International Conference on Machine Learning, pp.\ 6863--6877. PMLR, 2022
2022
-
[75]
and Diepold, K
Gronauer, S. and Diepold, K. Multi-agent deep reinforcement learning: a survey. Artificial Intelligence Review, 55 0 (2): 0 895--943, 2022
2022
-
[76]
K., Egorov, M., and Kochenderfer, M
Gupta, J. K., Egorov, M., and Kochenderfer, M. Cooperative multi-agent control using deep reinforcement learning. Autonomous Agents and Multi-Agent Systems, pp.\ 66--83, 2017
2017
-
[77]
Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers
Hu, S., Zhu, F., Chang, X., and Liang, X. Updet: Universal multi-agent reinforcement learning via policy decoupling with transformers. In International Conference on Learning Representations, 2021
2021
-
[78]
The iitm model: a simple and expressive model for universal composability
K \"u sters, R., Tuengerthal, M., and Rausch, D. The iitm model: a simple and expressive model for universal composability. Cryptology ePrint Archive, 2013
2013
-
[79]
Kaleidoscope: Learnable masks for heterogeneous multi-agent reinforcement learning
Li, X., Pan, L., and Zhang, J. Kaleidoscope: Learnable masks for heterogeneous multi-agent reinforcement learning. In Advances in Neural Information Processing Systems, 2024
2024
-
[80]
Scaling up multi-agent reinforcement learning: An extensive survey on scalability issues
Liu, D., Ren, F., Yan, J., Su, G., Gu, W., and Kato, S. Scaling up multi-agent reinforcement learning: An extensive survey on scalability issues. IEEE Access, 12: 0 94610--94631, 2024
2024
-
[81]
and Zhao, Q
Liu, K. and Zhao, Q. Distributed learning in multi-armed bandit with multiple players. IEEE transactions on signal processing, 58 0 (11): 0 5667--5681, 2010
2010
-
[82]
I., Tamar, A., Harb, J., Pieter Abbeel, O., and Mordatch, I
Lowe, R., Wu, Y. I., Tamar, A., Harb, J., Pieter Abbeel, O., and Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in neural information processing systems, 30, 2017
2017
-
[83]
Mahjoub, O., Abramowitz, S., de Kock, R., Khlifi, W., Toit, S. d., Daniel, J., Nessir, L. B., Beyers, L., Formanek, C., Clark, L., et al. Sable: a performant, efficient and scalable sequence model for marl. arXiv preprint arXiv:2410.01706, 2024
- [84]
-
[85]
and Hajinezhad, D
Oroojlooy, A. and Hajinezhad, D. A review of cooperative multi-agent deep reinforcement learning. Applied Intelligence, 53 0 (11): 0 13677--13722, 2023
2023
-
[86]
Gradps: Resolving futile neurons in parameter sharing network for multi-agent reinforcement learning
Qin, H., Liu, Z., Lin, C., Ma, C., Mei, S., Shen, S., and Wang, C. Gradps: Resolving futile neurons in parameter sharing network for multi-agent reinforcement learning. In Forty-second International Conference on Machine Learning, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.