Recognition: no theorem link
How Does Attention Help? Insights from Random Matrices on Signal Recovery from Sequence Models
Pith reviewed 2026-05-11 00:47 UTC · model grok-4.3
The pith
Attention weights maximizing signal recovery are the normalized top eigenvector of the positional correlation matrix.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
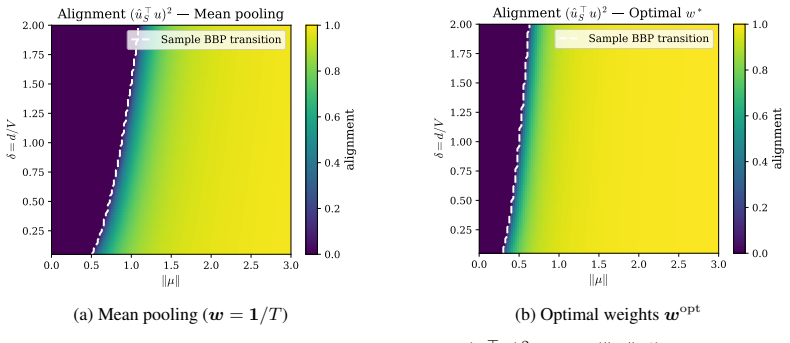
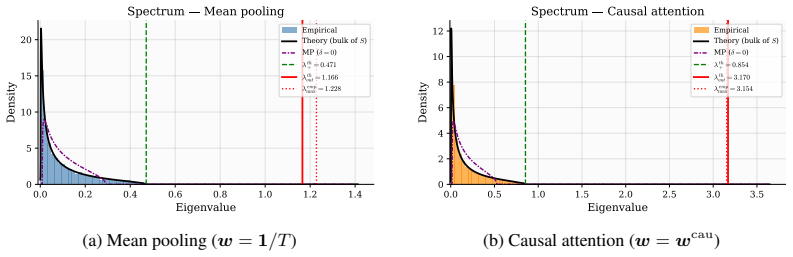
Working with pooled representations in the limit d, V, N to infinity with d/V to delta and d/N to gamma, the limiting bulk spectrum of the sample covariance is the free multiplicative convolution of two Marchenko-Pastur laws scaled by the attention parameters. Signal recovery exhibits two successive phase transitions governed by the scalars delta, gamma, alpha equal to w transpose R w, and kappa equal to the squared norm of w, where w are the attention weights and R is the positional correlation matrix. The optimal weights that maximize the signal-to-noise ratio alpha over kappa are the normalized top eigenvector of R; as a direct consequence, parameter-free causal self-attention with tau/d,
What carries the argument
The attention pooling vector w and the positional correlation matrix R, whose quadratic forms alpha = w^T R w and kappa = ||w||^2 set the effective signal-to-noise ratio that controls detectability of the hidden signal.
If this is right
- The bulk spectrum follows the non-Marchenko-Pastur law given by the free multiplicative convolution kappa(MP_delta box MP_gamma).
- Signal recovery undergoes two BBP-type phase transitions whose locations depend on delta, gamma, alpha, and kappa.
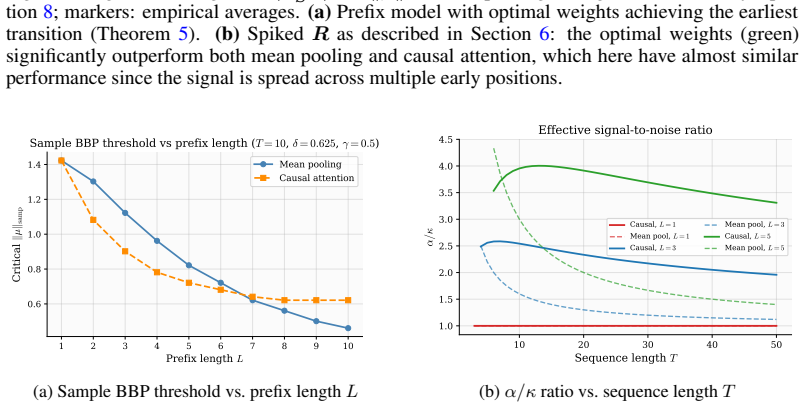
- Causal self-attention with tau/d score scaling produces deterministic harmonic weights that improve recovery over mean pooling when early tokens carry more signal.
- Extensive simulations match the predicted spectra and phase transitions in finite dimensions.
Where Pith is reading between the lines
- In practice, gradient descent on attention parameters may converge toward weights that approximate the top eigenvector of observed positional correlations.
- The same random-matrix framework could be used to compare other pooling schemes such as learned softmax attention or convolutional pooling.
- When signal strength varies across positions, the harmonic weights from causal attention offer a parameter-free alternative to learned attention for tasks with temporal decay.
- The analysis supplies concrete thresholds that could guide the design of embedding dimensions or sequence lengths needed for reliable signal recovery.
Load-bearing premise
The derivation assumes attention weights are fixed in advance rather than learned, token vectors are drawn exactly from a two-class Gaussian mixture, and the high-dimensional scaling limits hold exactly.
What would settle it
Measure the eigenvalue distribution of pooled covariances from finite-dimensional Gaussian-mixture sequences and check whether the bulk edge and any outlier eigenvalue appear at the locations predicted by the free convolution formula and the alpha/kappa thresholds.
Figures


read the original abstract
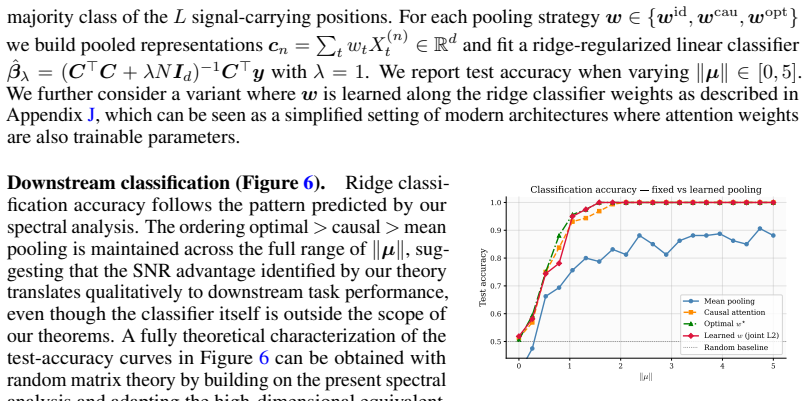
We study the spectral properties of sample covariance matrices constructed from pooled sequence representations, where token embeddings are drawn from a fixed two-class Gaussian mixture table and pooled via (fixed) attention weights. Working in the high-dimensional regime $d,V,N\to\infty$ with $d/V\to\delta$ and $d/N\to\gamma$, we derive exact characterizations of the limiting eigenvalue distribution, outlier eigenvalues, and eigenvector alignment with the hidden signal. The bulk spectrum follows a non-Marchenko--Pastur law given by the free multiplicative convolution $\kappa(MP_\delta\boxtimes MP_\gamma)$, reflecting the finite vocabulary structure. Signal recovery undergoes two successive BBP-type phase transitions characterized by the scalars: $\delta,\gamma,\alpha=w^{\top} R w$ and $\kappa=\|w\|^2$, where $w$ denotes the attention pooling weights and $R$ the positional correlation matrix. An aftermath of our analysis demonstrates that the optimal attention weights maximizing the signal-to-noise ratio $\alpha/\kappa$ are given by the (normalized) top eigenvector of $R$, and we show (as a particular case of our analysis) that parameter-free causal self-attention with $\tau/d$ score scaling yields deterministic harmonic weights that improve signal recovery over mean pooling whenever early tokens carry more signal. Extensive simulations confirm sharp agreement between theory and finite-dimensional experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the spectral properties of sample covariance matrices constructed from attention-pooled sequence representations, where token embeddings follow a fixed two-class Gaussian mixture model and pooling uses fixed attention weights w. In the high-dimensional regime d/V → δ, d/N → γ, it derives the limiting eigenvalue distribution of the bulk as the free multiplicative convolution κ(MP_δ ⊠ MP_γ), characterizes two successive BBP-type phase transitions for outlier eigenvalues and eigenvector-signal alignment in terms of δ, γ, α = w^T R w and κ = ||w||^2 (with R the positional correlation matrix), shows that α/κ is maximized by the normalized top eigenvector of R, and demonstrates that parameter-free causal self-attention with τ/d scaling produces deterministic harmonic weights that improve signal recovery over mean pooling when early tokens carry more signal. Finite-d simulations are reported to match the predictions sharply.
Significance. If the derivations hold, the work supplies a precise RMT-based explanation for the benefit of attention pooling in signal recovery tasks, including explicit formulas for phase transitions, optimal weights, and a concrete improvement from causal attention over mean pooling. The parameter-free nature of the optimal-weight and harmonic-weight results, together with the simulation agreement, strengthens the contribution to theoretical understanding of attention mechanisms.
minor comments (2)
- [§2] The abstract and introduction state the high-dimensional regime and model assumptions clearly, but the main text should include an explicit statement (perhaps in §2 or §3) confirming that all derivations treat w as fixed and non-learned, as this is load-bearing for the optimality claim.
- The free multiplicative convolution is invoked for the bulk law; adding a one-sentence reference to the precise free-probability result (e.g., the multiplicative convolution of two Marchenko-Pastur laws) would improve readability without altering the technical content.
Simulated Author's Rebuttal
We thank the referee for the thorough summary, positive assessment of the significance, and recommendation of minor revision. We are pleased that the core contributions—particularly the free-multiplicative-convolution characterization of the bulk, the two BBP-type phase transitions, the optimality of the top eigenvector of R, and the improvement from causal self-attention—are viewed as strengthening the theoretical understanding of attention mechanisms.
Circularity Check
No significant circularity
full rationale
The paper applies standard free-probability and BBP-type RMT results to an explicitly defined two-class GMM token model with fixed attention weights w and positional matrix R. The limiting bulk law is the free multiplicative convolution of two Marchenko-Pastur laws, a direct consequence of the model dimensions and the convolution property. The SNR scalars α = wᵀ R w and κ = ||w||² are explicit functions of the inputs; the claim that the top eigenvector of R maximizes α/κ is the Rayleigh-quotient theorem applied to this quadratic form and does not rely on the spectral derivation. The deterministic harmonic weights under τ/d causal scaling follow immediately from the high-dimensional limit of the softmax under the stated assumptions. No load-bearing self-citation, self-definition, or fitted quantity renamed as prediction appears in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (4)
- δ
- γ
- α = w^T R w
- κ = ||w||^2
axioms (3)
- domain assumption High-dimensional limits d, V, N → ∞ with d/V → δ and d/N → γ
- domain assumption Token embeddings drawn from a fixed two-class Gaussian mixture
- domain assumption Attention weights w are fixed (non-learned)
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2509.24914. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901,
-
[2]
Samet Demir and Zafer Dogan. Asymptotic analysis of two-layer neural networks after one gradient step under gaussian mixtures data with structure.arXiv preprint arXiv:2503.00856,
-
[3]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pp. 4171–4186,
2019
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Odilon Duranthon, Pierre Marion, Claire Boyer, Bruno Loureiro, and Lenka Zdeborová. Statis- tical advantage of softmax attention: insights from single-location regression.arXiv preprint arXiv:2509.21936,
-
[6]
How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pp. 55–65,
2019
-
[7]
High-dimensional learning with noisy labels
10 Aymane El Firdoussi and Mohamed El Amine Seddik. High-dimensional learning with noisy labels. arXiv preprint arXiv:2405.14088,
-
[8]
Representation degeneration problem in training natural language generation models, 2019
Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. Representation degeneration problem in training natural language generation models.arXiv preprint arXiv:1907.12009,
-
[9]
Nandan Kumar Jha and Brandon Reagen. A random matrix theory perspective on the learning dynamics of multi-head latent attention.arXiv preprint arXiv:2507.09394,
-
[10]
Jiaqi Mu, Suma Bhat, and Pramod Viswanath. All-but-the-top: Simple and effective postprocessing for word representations.arXiv preprint arXiv:1702.01417,
-
[11]
Chulhee Yun, Srinadh Bhojanapalli, Ankit Singh Rawat, Sashank J Reddi, and Sanjiv Kumar. Are transformers universal approximators of sequence-to-sequence functions?arXiv preprint arXiv:1912.10077,
-
[12]
Step 0: Pooled representation and bulk reduction.Recall that each pooled row of C can be written as cn = TX t=1 wt X(n) t = TX t=1 wtξn,t µ+ TX t=1 wt zxn,t
We derive equation 5 using theS-transform formalism from free probability (Nica & Speicher, 2006), and then extract the right bulk edgeλ + in closed form. Step 0: Pooled representation and bulk reduction.Recall that each pooled row of C can be written as cn = TX t=1 wt X(n) t = TX t=1 wtξn,t µ+ TX t=1 wt zxn,t . Using independence of (ξn) and (zv) and the...
2006
-
[13]
The population covariance equation 12 is the rank-one additive deformation Σ=κΣ Z +α∥µ∥ 2 uu⊤
Throughout this section let H denote the LSD of κΣZ, namely H=κMP δ, and mH its Stieltjes transform. The population covariance equation 12 is the rank-one additive deformation Σ=κΣ Z +α∥µ∥ 2 uu⊤. 13 Outlier equation.By Benaych-Georges & Nadakuditi (2011), if an outlier eigenvalue β of Σ lies outside the support ofH, it must satisfy 1 +α∥µ∥ 2 mH(β) = 0⇐ ⇒m...
2011
-
[14]
Clearing the denominator (for ρ > δ ) and expanding gives ρ2 −(δ+ 2 √ δ)ρ−( √ δ)(δ+ √ δ)>0 , which factors as(ρ−(δ+ √ δ))(ρ+ √ δ)>0
ρ−δ >(1 + √ δ)2. Clearing the denominator (for ρ > δ ) and expanding gives ρ2 −(δ+ 2 √ δ)ρ−( √ δ)(δ+ √ δ)>0 , which factors as(ρ−(δ+ √ δ))(ρ+ √ δ)>0. Sinceρ >0the BBP condition reduces to ρ > δ+ √ δ. Eigenvector overlap.The general formula of Benaych-Georges & Nadakuditi (2011) reads |ˆu⊤ Σu|2 = 1 α2∥µ∥4 m′ H(βout) .(22) We compute m′ H by differentiating...
2011
-
[15]
Assume we are in the supercritical regime, so that Σ has an outlier eigenvalue β:=β out separated from the bulk. Viewing Σ as a rank-one deformation of its bulk component, the standard theory of spiked sample covariance matrices (Silverstein & Bai, 1995; Bai et al., 2010; Benaych-Georges & Nadakuditi,
1995
-
[16]
In this limit, the companion transform admits a closed form and the outlier location simplifies to λout =β(1 +γ/(β−1))
16 D.4 Consistency check:δ→0reduces to Paul’s formula When δ→0 (infinite vocabulary), ΣZ →I d and the bulk reduces to the scaled MP law κMP γ. In this limit, the companion transform admits a closed form and the outlier location simplifies to λout =β(1 +γ/(β−1)) . A direct substitution into equation 27 recovers the classical formula of Paul (2007): |ˆu⊤ S ...
2007
-
[17]
top-r plus isotropic noise
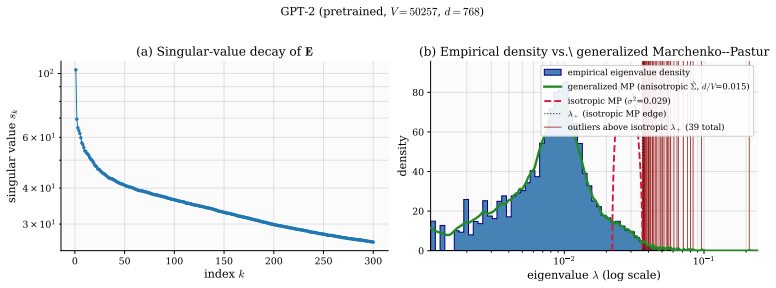
with covariance matrix estimated from the raw embedding table. The empirical bulk follows its theoretical counterpart closely; the residual outlier eigenvalues above the right bulk edgeλ + are the spectral footprint of the low-rank signal. Takeaway.The separation observed in Figure 7(a), together with the near-exact agreement between the empirical bulk an...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.