Recognition: 2 theorem links
· Lean TheoremRegulating Branch Parallelism in LLM Serving
Pith reviewed 2026-05-11 00:57 UTC · model grok-4.3
The pith
A per-step admission controller admits extra LLM output branches only when their predicted externality fits the current slack budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
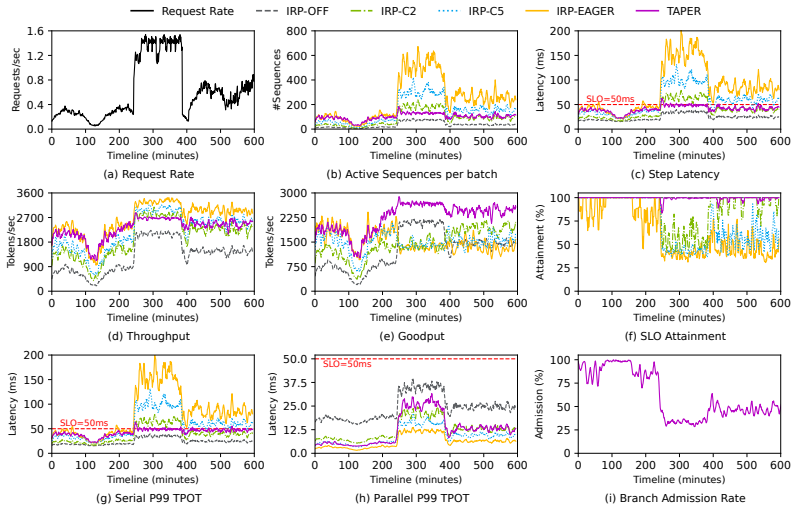
TAPER treats extra branches as opportunistic work, admitted only when the predicted branch externality fits within the batch's current slack budget. Branch-level scheduling decouples compute from memory because branches share the request's prefix KV, so expanding or contracting width requires no memory reclamation.
What carries the argument
TAPER, the per-step admission controller that decides branch admissions by comparing predicted branch externality against the batch's accumulated slack.
If this is right
- On Qwen3-32B, goodput rises 1.77 times over no parallelism and 1.48 times over eager execution.
- SLO attainment remains above 95 percent.
- Dynamic width adjustment is feasible because branches share prefix KV cache.
- Regulation prevents eager admission from inflating shared decode steps for co-batched requests.
Where Pith is reading between the lines
- The same slack-based admission logic could apply to other speculative or tree-structured generation methods.
- Serving frameworks might embed this controller to replace static caps across different parallelism exposures.
- More accurate externality models could further increase admitted branches without SLO risk.
Load-bearing premise
Branch externality can be predicted accurately enough from batch composition, context lengths, and accumulated slack to enable safe per-step admission without unaccounted delays.
What would settle it
A workload trace on which TAPER's externality predictions cause either SLO violations or lower goodput than both the no-parallelism and eager baselines.
Figures

read the original abstract
Recent methods expose intra-request parallelism in LLM outputs, allowing independent branches to decode concurrently. Existing serving systems execute these branches eagerly or under fixed caps. We show that both are brittle: eager admission inflates the shared decode step, degrading co-batched requests in serial stages, while conservative fixed caps forgo the throughput that motivated exposing branches in the first place. We call the excess step latency caused by admitted branches the branch externality and show that the safe width depends on batch composition, context lengths, and accumulated slack, all of which change continuously over a workload trace. We introduce TAPER, a per-step admission controller that treats extra branches as opportunistic work, admitted only when the predicted branch externality fits within the batch's current slack budget. Per-step regulation is practical because branch-level scheduling decouples compute from memory: branches share the request's prefix KV, so expanding or contracting width requires no memory reclamation. On Qwen3-32B, TAPER improves goodput by $1.77\times$ over IRP-Off and by $1.48\times$ over IRP-Eager, while maintaining over $95\%$ SLO attainment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that eager or fixed-cap execution of intra-request branches in LLM serving is brittle because it either inflates shared decode steps or forgoes throughput. It introduces TAPER, a per-step admission controller that treats extra branches as opportunistic work admitted only when the predicted branch externality fits the batch's current slack budget (derived from batch composition, context lengths, and accumulated slack). Branch-level scheduling is enabled by shared prefix KV caches. On Qwen3-32B the system reports 1.77× goodput over IRP-Off and 1.48× over IRP-Eager while maintaining >95% SLO attainment.
Significance. If the central results hold, the work provides a concrete mechanism for dynamically regulating branch parallelism in LLM serving, addressing a practical tension between throughput and latency that existing systems handle poorly. The approach of predicting externality from observable batch state and using shared KV to decouple width changes from memory management is a pragmatic contribution that could be adopted in production serving stacks. The evaluation supplies concrete speedups on a public model against external baselines.
major comments (2)
- [Evaluation] Evaluation section: The reported 1.77× and 1.48× goodput gains at >95% SLO attainment rest on the accuracy of the per-step branch externality predictor, yet no prediction-error metrics, training procedure, or robustness results under workload shift are supplied; without these the speedups cannot be verified as arising from safe admission rather than optimistic prediction.
- [§3] §3 (Design): The slack-budget calculation and admission rule are described only at the level of 'predicted externality fits within the batch's current slack budget'; no equation, pseudocode, or precise definition of how batch composition, context lengths, and accumulated slack are combined into a numeric budget is given, making the controller non-reproducible from the text.
minor comments (2)
- [Abstract] The abstract states 'over 95% SLO attainment' without defining the exact SLO (e.g., per-token latency threshold) or the measurement window used in the experiments.
- [Evaluation] Figure captions and axis labels in the evaluation would benefit from explicit units and a brief description of the workload trace used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where additional detail will improve verifiability and reproducibility. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported 1.77× and 1.48× goodput gains at >95% SLO attainment rest on the accuracy of the per-step branch externality predictor, yet no prediction-error metrics, training procedure, or robustness results under workload shift are supplied; without these the speedups cannot be verified as arising from safe admission rather than optimistic prediction.
Authors: We agree that the predictor's accuracy is essential to attributing the gains to safe admission. The current evaluation focuses on end-to-end goodput and SLO attainment under the tested traces, but we will add a new subsection in the evaluation that reports the predictor's training procedure (supervised regression on offline execution traces), quantitative error metrics (MAE, over-prediction rate, and calibration plots), and robustness results under workload shifts (different arrival rates, context-length distributions, and model sizes). These additions will allow readers to verify that the observed improvements arise from conservative, accurate externality estimates rather than optimistic predictions. revision: yes
-
Referee: [§3] §3 (Design): The slack-budget calculation and admission rule are described only at the level of 'predicted externality fits within the batch's current slack budget'; no equation, pseudocode, or precise definition of how batch composition, context lengths, and accumulated slack are combined into a numeric budget is given, making the controller non-reproducible from the text.
Authors: We acknowledge that the current prose description in §3 is insufficiently precise for reproducibility. In the revision we will replace the high-level description with explicit equations that define the slack budget as a function of current batch composition (per-request decode costs and KV-cache occupancy), context lengths, and accumulated slack from prior steps. We will also insert pseudocode for the per-step admission decision, showing how the predicted externality is compared to the budget and how width is adjusted. These changes will make the TAPER controller fully reproducible from the text while preserving the original design intent. revision: yes
Circularity Check
No circularity: TAPER controller and reported gains are externally evaluated design choices
full rationale
The paper presents TAPER as a new per-step admission controller that admits branches only when predicted externality fits the current slack budget derived from observable batch state. The central claims are empirical goodput improvements (1.77× over IRP-Off, 1.48× over IRP-Eager at >95% SLO) measured on Qwen3-32B against external baselines. No equations, derivations, or self-citations in the abstract reduce these gains to quantities defined inside the same model or fitted parameters; the predictor is treated as a practical implementation detail whose accuracy is validated by the end-to-end results rather than presupposed by construction. The design is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Branch-level scheduling decouples compute from memory because branches share the request's prefix KV cache
invented entities (1)
-
branch externality
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We call the excess step latency caused by admitted branches the branch externality... TAPER... admits them only when the predicted branch externality fits within the batch's current slack budget.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088
2022
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Xuefei Ning, Zinan Lin, Zixuan Zhou, Zifu Wang, Huazhong Yang, and Yu Wang. Skeleton-of- thought: Prompting llms for efficient parallel generation, 2024. URL https://arxiv.org/ abs/2307.15337
-
[5]
Cheng, Zack Ankner, Nikunj Saunshi, Blake M
Tian Jin, Ellie Y . Cheng, Zack Ankner, Nikunj Saunshi, Blake M. Elias, Amir Yazdanbakhsh, Jonathan Ragan-Kelley, Suvinay Subramanian, and Michael Carbin. Learning to keep a promise: Scaling language model decoding parallelism with learned asynchronous decoding, 2025. URL https://arxiv.org/abs/2502.11517
-
[6]
Apar: Llms can do auto-parallel auto-regressive decoding, 2024
Mingdao Liu, Aohan Zeng, Bowen Wang, Peng Zhang, Jie Tang, and Yuxiao Dong. Apar: Llms can do auto-parallel auto-regressive decoding, 2024. URL https://arxiv.org/abs/2401. 06761
2024
-
[7]
Learning adaptive parallel reasoning with language models, 2025
Jiayi Pan, Xiuyu Li, Long Lian, Charlie Snell, Yifei Zhou, Adam Yala, Trevor Darrell, Kurt Keutzer, and Alane Suhr. Learning adaptive parallel reasoning with language models, 2025. URLhttps://arxiv.org/abs/2504.15466
-
[8]
Aspd: Unlocking adaptive serial-parallel decoding by exploring intrinsic parallelism in llms, 2025
Keyu Chen, Zhifeng Shen, Daohai Yu, Haoqian Wu, Wei Wen, Jianfeng He, Ruizhi Qiao, and Xing Sun. Aspd: Unlocking adaptive serial-parallel decoding by exploring intrinsic parallelism in llms, 2025. URLhttps://arxiv.org/abs/2508.08895
-
[9]
Xinyu Yang, Yuwei An, Hongyi Liu, Tianqi Chen, and Beidi Chen. Multiverse: Your language models secretly decide how to parallelize and merge generation, 2025. URL https://arxiv. org/abs/2506.09991
-
[10]
Threadweaver: Adaptive threading for efficient parallel reasoning in language models, 2025
Long Lian, Sida Wang, Felix Juefei-Xu, Tsu-Jui Fu, Xiuyu Li, Adam Yala, Trevor Darrell, Alane Suhr, Yuandong Tian, and Xi Victoria Lin. Threadweaver: Adaptive threading for efficient parallel reasoning in language models, 2025. URLhttps://arxiv.org/abs/2512.07843
-
[11]
Parallelprompt: Extracting parallelism from large language model queries, 2025
Steven Kolawole, Keshav Santhanam, Virginia Smith, and Pratiksha Thaker. Parallelprompt: Extracting parallelism from large language model queries, 2025. URL https://arxiv.org/ abs/2506.18728
-
[12]
Lingzhe Zhang, Liancheng Fang, Chiming Duan, Minghua He, Leyi Pan, Pei Xiao, Shiyu Huang, Yunpeng Zhai, Xuming Hu, Philip S. Yu, and Aiwei Liu. A Survey on Parallel Text Generation: From Parallel Decoding to Diffusion Language Models, 2026. URL https: //arxiv.org/abs/2508.08712. 10
-
[13]
Orca: A distributed serving system for Transformer-Based generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for Transformer-Based generative models. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, Carlsbad, CA, July 2022. USENIX Association. ISBN 978-1-939133-28-1. URL https: //www.usenix.org/conferen...
2022
-
[14]
ServeGen: Workload characterization and generation of large language model serving in production
Yuxing Xiang, Xue Li, Kun Qian, Yan Zhang, Wenyuan Yu, Ennan Zhai, Xin Jin, and Jingren Zhou. ServeGen: Workload characterization and generation of large language model serving in production. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26), pages 1845–1859, Renton, WA, May 2026. USENIX Association. ISBN 978- 1-939133-54-0....
2026
-
[15]
NanoFlow: Towards optimal large language model serving throughput
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. NanoFlow: Towards optimal large language model serving throughput. In 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 749–765, Bo...
2025
-
[16]
Gonzalez, and Ion Stoica
Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E. Gonzalez, and Ion Stoica. Fairness in Serving Large Language Models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 965–988, Santa Clara, CA, July 2024. USENIX Association. ISBN 978-1-939133-40-3. URL https: //www.usenix.org/confere...
2024
-
[17]
Llumnix: Dynamic scheduling for large language model serving
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. Llumnix: Dynamic scheduling for large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 173–191, Santa Clara, CA, July 2024. USENIX Association. ISBN 978-1-939133-40-3. URL https: //www.usenix.org/conference/os...
2024
-
[18]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP ’23, page 611–626, New York, NY , USA, 2023. Association for Computing Machin...
-
[19]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. Sglang: efficient execution of structured language model programs. InProceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, N...
2025
-
[20]
P Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023
2023
-
[21]
Retrieval-Augmented Generation (RAG) Dataset 12000
Neural Bridge. Retrieval-Augmented Generation (RAG) Dataset 12000. https:// huggingface.co/datasets/neural-bridge/rag-dataset-12000, 2023
2023
-
[22]
OpenR1-Math-220k
Open-R1. OpenR1-Math-220k. https://huggingface.co/datasets/open-r1/ OpenR1-Math-220k, 2025
2025
-
[23]
Azure LLM inference trace 2023
Microsoft. Azure LLM inference trace 2023. https://github.com/Azure/ AzurePublicDataset/blob/master/AzureLLMInferenceDataset2023.md, 2024
2023
-
[24]
Routledge, 2017
Arthur Pigou.The economics of welfare. Routledge, 2017
2017
-
[25]
Sprint: Enabling interleaved planning and parallelized execution in reasoning models, 2025
Emil Biju, Shayan Talaei, Zhemin Huang, Mohammadreza Pourreza, Azalia Mirhoseini, and Amin Saberi. Sprint: Enabling interleaved planning and parallelized execution in reasoning models, 2025. URLhttps://arxiv.org/abs/2506.05745. 11
-
[26]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling, 2024. URLhttps://arxiv.org/abs/2407.21787
work page internal anchor Pith review arXiv 2024
-
[29]
Efficient beam search for large language models using trie-based decoding, 2025
Brian J Chan, MaoXun Huang, Jui-Hung Cheng, Chao-Ting Chen, and Hen-Hsen Huang. Efficient beam search for large language models using trie-based decoding, 2025. URL https: //arxiv.org/abs/2502.00085
-
[30]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models, 2023. URLhttps://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Universal self-consistency for large language model generation.arXiv preprint arXiv:2311.17311, 2023
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language model generation, 2023. URLhttps://arxiv.org/abs/2311.17311
-
[32]
Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, 2024. URLhttps://arxiv.org/abs/2406.07394
-
[33]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: deliberate problem solving with large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[34]
Gleb Rodionov, Roman Garipov, Alina Shutova, George Yakushev, Erik Schultheis, Vage Egiazarian, Anton Sinitsin, Denis Kuznedelev, and Dan Alistarh. Hogwild! inference: Parallel llm generation via concurrent attention, 2025. URL https://arxiv.org/abs/2504.06261
-
[35]
Parallel-r1: Towards parallel thinking via reinforcement learning
Tong Zheng, Hongming Zhang, Wenhao Yu, Xiaoyang Wang, Runpeng Dai, Rui Liu, Huiwen Bao, Chengsong Huang, Heng Huang, and Dong Yu. Parallel-r1: Towards parallel thinking via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2509.07980
-
[36]
Fairbatching: Fairness-aware batch formation for llm inference, 2025
Hongtao Lyu, Boyue Liu, Mingyu Wu, and Haibo Chen. Fairbatching: Fairness-aware batch formation for llm inference, 2025. URLhttps://arxiv.org/abs/2510.14392
-
[37]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[38]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. MEDUSA: Simple LLM inference acceleration framework with multiple decoding heads. InProceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024
2024
-
[39]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test. InAnnual Conference on Neural Information Processing Systems, 2025. 12
2025
-
[40]
Optimizing speculative decoding for serving large language models using goodput,
Xiaoxuan Liu, Jongseok Park, Langxiang Hu, Woosuk Kwon, Zhuohan Li, Chen Zhang, Kuntai Du, Xiangxi Mo, Kaichao You, Alvin Cheung, Zhijie Deng, Ion Stoica, and Hao Zhang. Turbospec: Closed-loop speculation control system for optimizing llm serving goodput, 2025. URLhttps://arxiv.org/abs/2406.14066
-
[41]
Adaspec: Adap- tive speculative decoding for fast, slo-aware large language model serving
Kaiyu Huang, Hao Wu, Zhubo Shi, Han Zou, Minchen Yu, and Qingjiang Shi. Adaspec: Adap- tive speculative decoding for fast, slo-aware large language model serving. InProceedings of the 2025 ACM Symposium on Cloud Computing, SoCC ’25, page 361–374. ACM, November 2025. doi: 10.1145/3772052.3772239. URLhttp://dx.doi.org/10.1145/3772052.3772239
-
[42]
Zikun Li, Zhuofu Chen, Remi Delacourt, Gabriele Oliaro, Zeyu Wang, Qinghan Chen, Shuhuai Lin, April Yang, Zhihao Zhang, Zhuoming Chen, Sean Lai, Xinhao Cheng, Xupeng Miao, and Zhihao Jia. Adaserve: Accelerating multi-slo llm serving with slo-customized speculative decoding, 2025. URLhttps://arxiv.org/abs/2501.12162
-
[43]
Nightjar: Dynamic adaptive speculative decoding for large language models serving, 2026
Rui Li, Zhaoning Zhang, Libo Zhang, Huaimin Wang, Xiang Fu, and Zhiquan Lai. Nightjar: Dynamic adaptive speculative decoding for large language models serving, 2026. URL https: //arxiv.org/abs/2512.22420
-
[44]
Andes: Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services,
Jiachen Liu, Jae-Won Chung, Zhiyu Wu, Fan Lai, Myungjin Lee, and Mosharaf Chowdhury. Andes: Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services,
- [45]
-
[46]
A predictive and synergistic two-layer scheduling framework for llm serving, 2025
Yue Zhang, Yuansheng Chen, Xuan Mo, Alex Xi, Jialun Li, and WeiGang Wu. A predictive and synergistic two-layer scheduling framework for llm serving, 2025. URL https://arxiv. org/abs/2509.23384. A Proof of Schedule Invariance Lemma A.1(Schedule invariance).The output of a parallel phase is independent of the order and timing in which its branches are sched...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.