Recognition: 1 theorem link
· Lean TheoremBridging the Last Mile of Circuit Design: PostEDA-Bench, a Hierarchical Benchmark for PPA Convergence and DRC Fixing
Pith reviewed 2026-05-11 00:57 UTC · model grok-4.3
The pith
LLM agents succeed on simple post-EDA tasks but reach only 37% and 20% success on practical DRC reasoning and multi-objective PPA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
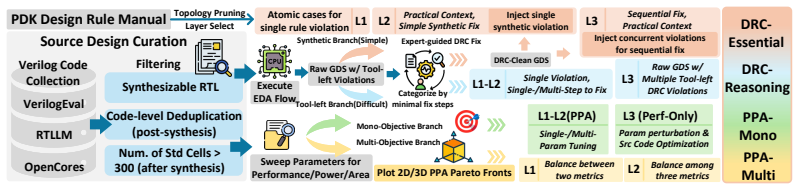
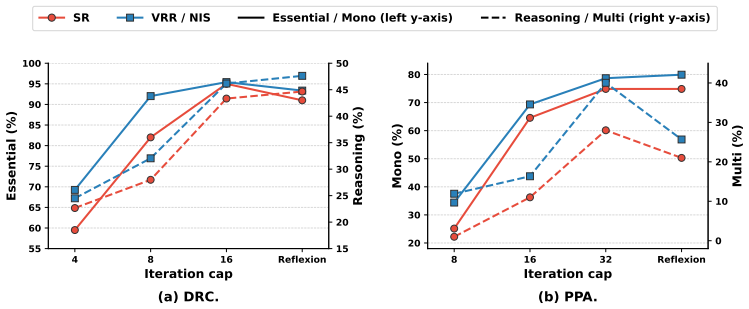
PostEDA-Bench is a hierarchical benchmark with 145 tasks across DRC-Essential, DRC-Reasoning, PPA-Mono, and PPA-Multi, supported by EDA toolchains that provide machine-checkable evaluation. Across eight LLMs and multiple agent scaffolds, agents handle synthetic DRC-Essential and single-objective PPA-Mono reasonably well but degrade sharply on the more practical DRC-Reasoning (best success rate 36.66%) and PPA-Multi (best success rate 20.00%). Vision augmentation consistently enhances DRC-Bench performance, and trade-off reasoning, rather than knob knowledge, is the dominant PPA-Multi bottleneck.
What carries the argument
PostEDA-Bench, the hierarchical benchmark of 145 tasks in four categories with machine-checkable scoring via real EDA toolchains that directly measures agent success on DRC repair and PPA convergence.
If this is right
- Agents must develop stronger contextual reasoning to identify and resolve DRC violations that require understanding design intent.
- Multi-objective PPA work demands explicit mechanisms for weighing competing goals such as power versus timing.
- Vision inputs should be included by default in agent pipelines targeting DRC-related tasks.
- Benchmarks that separate synthetic from practical subtasks can guide targeted improvements in agent design.
Where Pith is reading between the lines
- Agent architectures for hardware design could benefit from dedicated modules that simulate iterative trade-off analysis.
- Extending the benchmark to earlier EDA stages such as placement or routing might expose similar reasoning bottlenecks.
- Fully autonomous last-mile flows may still need hybrid setups that combine agents with classical optimization loops.
- Comparable task hierarchies could be applied to other automated design domains to measure where current models fall short.
Load-bearing premise
The 145 tasks across the four categories in PostEDA-Bench are representative of real-world post-EDA challenges and provide a fair test of agent capabilities.
What would settle it
If a new agent method or model achieves over 70% success rate on both the DRC-Reasoning and PPA-Multi task sets while using the same benchmark and evaluation toolchain, the claimed performance gaps would no longer hold.
Figures





read the original abstract
LLM-based agents are increasingly applied to the "last mile" of Electronic Design Automation (EDA): repairing residual sign-off Design Rule Check (DRC) violations and converging Power-Performance-Area (PPA) targets after tool runs. Existing EDA-LLM benchmarks, however, omit DRC fixing entirely and rely on flat hierarchies tied to a single toolchain. We introduce PostEDA-Bench, a hierarchical benchmark with 145 tasks across DRC-Essential, DRC-Reasoning, PPA-Mono, and PPA-Multi, supported by EDA toolchains with machine-checkable evaluation. Across eight commercial and open-source LLMs under multiple agent scaffolds, we find that agents handle synthetic DRC-Essential and single-objective PPA-Mono reasonably well but degrade sharply on the more practical DRC-Reasoning, where the best success rate is 36.66%, and PPA-Multi, where the best success rate is 20.00%; vision augmentation consistently enhances DRC-Bench; and trade-off reasoning, rather than knob knowledge, is the dominant PPA-Multi bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PostEDA-Bench, a hierarchical benchmark with 145 tasks across four categories (DRC-Essential, DRC-Reasoning, PPA-Mono, PPA-Multi) for evaluating LLM-based agents on post-EDA DRC fixing and PPA convergence. Supported by machine-checkable EDA toolchains, experiments across eight commercial and open-source LLMs and multiple agent scaffolds show agents handling synthetic/easy tasks reasonably well but degrading on practical ones, with best success rates of 36.66% on DRC-Reasoning and 20.00% on PPA-Multi; vision augmentation helps DRC tasks, and trade-off reasoning (not knob knowledge) is the main PPA-Multi bottleneck.
Significance. If the tasks prove representative, this benchmark fills a gap in EDA-LLM evaluation by focusing on the post-tool 'last mile' with objective metrics, highlighting current agent limitations and guiding targeted improvements in reasoning and multi-objective optimization for circuit design automation. The machine-checkable evaluation via EDA toolchains is a clear strength for reproducibility.
major comments (3)
- [§3] §3 (Benchmark Construction): The 145 tasks lack explicit details on sourcing (e.g., extraction from real tape-outs versus synthetic generation), diversity metrics across process nodes or design styles, and expert validation that violation patterns and trade-offs match industrial distributions. This is load-bearing for the central claims, as the reported sharp degradation (36.66% DRC-Reasoning, 20% PPA-Multi) and attribution to reasoning bottlenecks assume the tasks represent practical post-EDA challenges.
- [§4] §4 (Experiments and Results): Success rates are reported as single point estimates without statistical controls such as number of independent runs per task, variance, confidence intervals, or significance testing. This undermines the reliability of the degradation observations and the conclusion that trade-off reasoning is the dominant bottleneck in PPA-Multi.
- [§4.2] §4.2 (Agent Scaffolds and Vision): The description of how vision augmentation is integrated and its consistent enhancement on DRC-Bench lacks ablation details on prompt engineering, image resolution, or failure modes, making it difficult to isolate whether gains stem from visual DRC pattern recognition or other factors.
minor comments (2)
- [Abstract and §1] The abstract and introduction could more explicitly compare PostEDA-Bench to prior EDA-LLM benchmarks (e.g., in terms of hierarchy and machine-checkable metrics) to clarify novelty.
- [Figures and Tables] Figure captions and table headers should include more detail on the exact success-rate definitions (e.g., whether partial fixes count) to aid interpretation without referring to the text.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review of our manuscript. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor while maintaining the integrity of our benchmark and experimental claims.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The 145 tasks lack explicit details on sourcing (e.g., extraction from real tape-outs versus synthetic generation), diversity metrics across process nodes or design styles, and expert validation that violation patterns and trade-offs match industrial distributions. This is load-bearing for the central claims, as the reported sharp degradation (36.66% DRC-Reasoning, 20% PPA-Multi) and attribution to reasoning bottlenecks assume the tasks represent practical post-EDA challenges.
Authors: We agree that additional transparency on benchmark construction would strengthen the paper. The tasks are synthetically generated using open-source PDKs and EDA toolchains to ensure full machine-checkability and reproducibility, with DRC-Essential tasks using basic single-violation patterns and DRC-Reasoning tasks incorporating multi-violation contextual patterns drawn from common post-EDA scenarios. In the revised manuscript, we will expand §3 with: explicit sourcing details (synthetic generation based on standard rule patterns rather than direct real tape-out extraction due to IP constraints); diversity metrics (coverage across process nodes via 7nm/14nm/45nm open PDK equivalents and design styles including combinational logic, sequential circuits, and arithmetic units); and validation notes (patterns curated to align with industrial distributions via internal EDA expert review). This supports our claims, as performance degradation tracks increasing task complexity rather than artificial simplicity. revision: yes
-
Referee: [§4] §4 (Experiments and Results): Success rates are reported as single point estimates without statistical controls such as number of independent runs per task, variance, confidence intervals, or significance testing. This undermines the reliability of the degradation observations and the conclusion that trade-off reasoning is the dominant bottleneck in PPA-Multi.
Authors: The referee correctly notes the absence of statistical controls in the reported results. Each task-LLM-scaffold combination was evaluated once owing to the substantial compute required for LLM calls and full EDA tool flows. The degradation trends remain consistent across all eight models and scaffolds, and the trade-off reasoning bottleneck is evidenced by targeted ablations (separating knob selection from multi-objective optimization). In revision, we will add a limitations subsection discussing this and include variance estimates plus confidence intervals from three independent runs on a 20% random subset of tasks to quantify reliability without prohibitive cost. revision: partial
-
Referee: [§4.2] §4.2 (Agent Scaffolds and Vision): The description of how vision augmentation is integrated and its consistent enhancement on DRC-Bench lacks ablation details on prompt engineering, image resolution, or failure modes, making it difficult to isolate whether gains stem from visual DRC pattern recognition or other factors.
Authors: We will revise §4.2 to provide the requested details. Vision augmentation is integrated by rendering DRC violation maps as images and appending them to the agent prompt with a fixed template instructing the model to analyze spatial patterns. In the update, we will include ablations on prompt variants, image resolutions (tested at 256x256 and 512x512), and explicit failure mode analysis (e.g., vision aids detection of dense local violations but offers limited help on global routing conflicts). These additions will clarify that gains primarily arise from improved visual pattern recognition rather than ancillary prompt effects. revision: yes
Circularity Check
No circularity: pure empirical benchmark with direct experimental results
full rationale
The paper creates PostEDA-Bench (145 tasks across four categories) and reports LLM/agent success rates from direct runs on commercial/open-source toolchains with machine-checkable evaluation. No equations, derivations, fitted parameters, predictions, or first-principles claims exist. Performance numbers (e.g., 36.66% on DRC-Reasoning, 20% on PPA-Multi) are measured outcomes, not reductions of prior definitions or self-citations. Representativeness of tasks is an external validity concern but does not create circularity in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The tasks defined in PostEDA-Bench are representative of real-world post-EDA DRC and PPA challenges
invented entities (1)
-
PostEDA-Bench hierarchical benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce POSTEDA-BENCH, a hierarchical benchmark with 145 tasks across DRC-Essential, DRC-Reasoning, PPA-Mono, and PPA-Multi, supported by EDA toolchains with machine-checkable evaluation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
X. Chen, M. Lin, N. Schärli, and D. Zhou. Teaching large language models to self-debug. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=KuPixIqPiq
2024
-
[2]
T. Clark, L., V . Vashishtha, L. Shifren, A. Gujja, S. Sinha, B. Cline, C. Ramamurthy, and G. Yeric. Asap7: A 7-nm finfet predictive process design kit.Microelectronics Journal, 53(—): 105–115, 2016. doi: 10.1016/j.mejo.2016.04.006
-
[3]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. Palm-e: an embodied multimodal language model. InProceedings of the 40th International Confere...
2023
-
[4]
Y . Fu, Y . Zhang, Z. Yu, S. Li, Z. Ye, C. Li, C. Wan, and Y . C. Lin. Gpt4aigchip: Towards next-generation AI accelerator design automation via large language models. InIEEE/ACM International Conference on Computer Aided Design, ICCAD 2023, San Francisco, CA, USA, October 28 - Nov. 2, 2023, pages 1–9. IEEE, 2023. doi: 10.1109/ICCAD57390.2023.10323953. UR...
-
[5]
L. Gao, A. Madaan, S. Zhou, U. Alon, P. Liu, Y . Yang, J. Callan, and G. Neubig. Pal: program- aided language models. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023
2023
-
[6]
ORFS-agent: Tool-Using Agents for Chip Design Optimization
A. Ghose, A. B. Kahng, S. Kundu, and Z. Wang. Orfs-agent: Tool-using agents for chip design optimization, 2025. URLhttps://arxiv.org/abs/2506.08332
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=VtmBAGCN7o
2024
-
[8]
Jiang, Q
Z. Jiang, Q. Zhang, C. Liu, L. Cheng, H. Li, and X. Li. Iicpilot: An intelligent integrated circuit backend design framework using open eda, 2024. URL https://arxiv.org/abs/2407.1 2576
2024
-
[9]
M. Liu, N. Pinckney, B. Khailany, and H. Ren. VerilogEval: evaluating large language models for verilog code generation. In2023 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), 2023
2023
-
[10]
Chipnemo: Domain- adapted llms for chip design,
M. Liu, T.-D. Ene, R. Kirby, C. Cheng, N. Pinckney, R. Liang, J. Alben, H. Anand, S. Banerjee, I. Bayraktaroglu, B. Bhaskaran, B. Catanzaro, A. Chaudhuri, S. Clay, B. Dally, L. Dang, P. Deshpande, S. Dhodhi, S. Halepete, E. Hill, J. Hu, S. Jain, A. Jindal, B. Khailany, G. Kokai, K. Kunal, X. Li, C. Lind, H. Liu, S. Oberman, S. Omar, G. Pasandi, S. Pratty,...
-
[11]
Y . Lu, S. Liu, Q. Zhang, and Z. Xie. Rtllm: An open-source benchmark for design rtl generation with large language model. In2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), pages 722–727. IEEE, 2024. 10
2024
- [12]
-
[13]
Madaan, N
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[14]
Opencores: Home, 2026
OpenCores.org. Opencores: Home, 2026. URLhttps://opencores.org/
2026
-
[15]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessí, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: language models can teach themselves to use tools. InProceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY , USA, 2023. Curran Associates Inc
2023
-
[16]
Shinn, F
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
- [17]
-
[18]
H. Wu, Z. He, X. Zhang, X. Yao, S. Zheng, H. Zheng, and B. Yu. ChatEDA: A Large Language Model Powered Autonomous Agent for EDA.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2024
2024
-
[19]
H. Wu, H. Zheng, Z. He, and B. Yu. Divergent Thoughts toward One Goal: LLM-based Multi-Agent Collaboration System for Electronic Design Automation. InAnnual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics, 2025
2025
-
[20]
S. Yao, D. Yu, J. Zhao, I. Shafran, T. L. Griffiths, Y . Cao, and K. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[21]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. ReAct: Synergizing rea- soning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[22]
K. Zhang, J. Li, G. Li, X. Shi, and Z. Jin. CodeAgent: Enhancing code generation with tool- integrated agent systems for real-world repo-level coding challenges. In L.-W. Ku, A. Martins, and V . Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13643–13658, Bangkok, Tha...
-
[23]
The engineer loads the violation in KLayout and inspects the offending geometry alongside its surrounding layers
-
[24]
The engineer manually constructs the shortest fix sequence using only the editing operations exposed to the agent (add_shape,change_shape,move_cell); inspection-only tool calls are not counted
-
[25]
The integer count of editing tool calls is recorded as the case’s step count
-
[26]
The protocol does not produce inter-annotator agreement scores; it is a within-annotator self- consistency procedure
After a one-week delay the engineer re-labels the same case without access to the prior label; cases with disagreeing labels are re-evaluated under the protocol until convergence, and any case that still admits competing minimal fixes is retained at the smaller step count. The protocol does not produce inter-annotator agreement scores; it is a within-anno...
2012
-
[27]
Limitations
over the same tool surface as the ReAct PPA agent. At each tree node the agent samples PARALLEL_NODE candidate next actions in parallel, an LLM judge scores them, the highest-scored candidate is executed, and the resulting state becomes a new node. Un-executed candidates from every previously-expanded node remain in a global priority queue, so when the cu...
2024
-
[28]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.