Recognition: no theorem link
f-Divergence Regularized RLHF: Two Tales of Sampling and Unified Analyses
Pith reviewed 2026-05-11 01:10 UTC · model grok-4.3
The pith
Two sampling algorithms for general f-divergence regularized RLHF achieve O(log T) regret and O(1/T) sub-optimality in the online setting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the entire family of f-divergences together rather than case by case, the authors derive two distinct sampling-based algorithms whose regret is bounded by O(log T) and whose sub-optimality gap shrinks as O(1/T), establishing the first provable performance bounds for online RLHF under general f-divergence regularization.
What carries the argument
A pair of sampling rules—one extending the optimism principle with a tailored exploration bonus, the other using the sensitivity of the optimal policy to reward perturbations under f-divergence regularization—that together support a single regret analysis across the function class.
If this is right
- Both the optimism-based and sensitivity-based algorithms are provably efficient for any f-divergence satisfying the paper's technical conditions.
- The same analysis supplies the first explicit performance guarantees for online RLHF outside the reverse-KL case.
- Alternative divergences can be substituted into the RLHF objective while retaining logarithmic regret and 1/T convergence.
- The framework unifies previously separate divergence-specific analyses into one set of bounds.
Where Pith is reading between the lines
- Practitioners could test forward KL or chi-squared regularizers in RLHF pipelines with the expectation of comparable theoretical efficiency.
- The sensitivity approach may extend naturally to other regularized RL settings where policy changes can be differentiated with respect to reward shifts.
- If the bounds hold in large-scale language-model training, they would justify exploring a broader menu of f-divergences without sacrificing sample efficiency.
Load-bearing premise
The chosen f-divergences must have well-behaved sensitivity of the optimal policy to reward perturbations, and an exploration bonus must exist that controls regret in the underlying online MDP.
What would settle it
Empirical or theoretical demonstration that, for at least one commonly used f-divergence, either algorithm's regret grows faster than O(log T) or the sub-optimality gap fails to reach O(1/T) under standard bounded-reward assumptions.
Figures


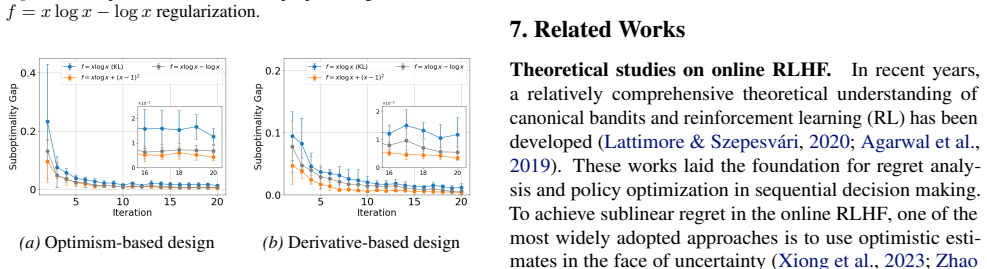
read the original abstract
Reinforcement Learning from Human Feedback (RLHF) has become a cornerstone technique for post-training large language models. While most existing approaches rely on the reverse KL-regularization, recent empirical studies have begun exploring alternative divergences (e.g., forward KL, chi-squared) as regularizers in RLHF. However, a unified theoretical understanding of general $f$-divergence regularization remains under-explored. To fill this gap, this work develops a comprehensive theoretical framework for online RLHF with a general $f$-divergence regularized objective. Rather than treating each possible divergence function individually, we adopt a holistic perspective across the entire function class and propose two algorithms based on distinct sampling principles. The first extends the classical optimism principle with a carefully designed exploration bonus, while the second introduces a new method that exploits the sensitivity of the optimal policy to reward perturbations under $f$-divergence regularization. Theoretical analysis shows that $O(\log T)$ regret and $O(1/T)$ sub-optimality gap are achievable, establishing provable efficiency of both algorithms and, to the best of our knowledge, the first performance bounds for online RLHF under general $f$-divergence regularization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a unified theoretical framework for online RLHF with general f-divergence regularization. It proposes two algorithms—one extending the optimism principle with a designed exploration bonus and the other exploiting the sensitivity of the optimal policy to reward perturbations—and proves that both achieve O(log T) regret and O(1/T) sub-optimality gap, claiming these as the first such performance bounds for online RLHF under general f-divergences.
Significance. If the derivations hold, this provides the first provable efficiency guarantees for RLHF beyond reverse KL regularization, unifying analysis across the f-divergence class and offering two distinct sampling approaches with matching bounds. This is a meaningful advance for theoretical understanding of alternative regularizers (e.g., forward KL, chi-squared) in LLM post-training, with potential to inform practical choices if the sensitivity and bonus constructions generalize.
minor comments (2)
- [Abstract and §1] The abstract and introduction would benefit from a short explicit comparison table or paragraph contrasting the new bounds with existing O(log T) results for reverse-KL RLHF to better highlight the generalization.
- [§2] Notation for the f-divergence class and the sensitivity condition should be introduced with a brief reminder of the definition of f (e.g., convexity, f(1)=0) to aid readers unfamiliar with the full class.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work and the recommendation for minor revision. The referee accurately captures the paper's contributions in developing a unified framework for online RLHF under general f-divergence regularization, along with the two proposed algorithms and their performance guarantees.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper develops a unified theoretical framework for online RLHF under general f-divergence regularization by proposing two distinct sampling algorithms (optimism-based with exploration bonus and sensitivity-based) and deriving O(log T) regret plus O(1/T) sub-optimality bounds directly from the constructed bonuses and policy sensitivity controls. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the bounds follow from standard MDP regret techniques applied to the stated f-divergence class assumptions without renaming known results or smuggling ansatzes. The analysis is internally consistent and independent of the target bounds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The underlying problem is modeled as a finite-horizon MDP with bounded rewards and the f-divergence satisfies standard convexity and differentiability properties.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https: //arxiv.org/abs/2502.01203. Bai, Y ., Jones, A., Ndousse, K., Askell, A., Chen, A., Das- Sarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al. Training a helpful and harmless assistant with rein- forcement learning from human feedback.arXiv preprint arXiv:2204.05862,
-
[3]
URL https://arxiv.org/ abs/1801.00056. Bradley, R. A. and Terry, M. E. Rank analysis of incom- plete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345,
-
[4]
arXiv preprint arXiv:2010.10182 , year=
URL https: //arxiv.org/abs/2010.10182. Dong, H., Xiong, W., Goyal, D., Zhang, Y ., Chow, W., Pan, R., Diao, S., Zhang, J., Shum, K., and Zhang, T. Raft: Re- ward ranked finetuning for generative foundation model alignment.arXiv preprint arXiv:2304.06767,
-
[5]
Go, D., Korbak, T., Kruszewski, G., Rozen, J., Ryu, N., and Dymetman, M
URL https://arxiv.org/abs/ 2502.04270. Go, D., Korbak, T., Kruszewski, G., Rozen, J., Ryu, N., and Dymetman, M. Aligning language models with prefer- ences through f-divergence minimization,
-
[6]
arXiv preprint arXiv:2302.08215 , year=
URL https://arxiv.org/abs/2302.08215. Han, J., Jiang, M., Song, Y ., Ermon, S., and Xu, M.f-po: Generalizing preference optimization with f-divergence minimization,
-
[7]
URL https://arxiv.org/ abs/2410.21662. 9 f-Divergence Regularized RLHF: Two Tales of Sampling and Unified Analyses Huang, A., Zhan, W., Xie, T., Lee, J. D., Sun, W., Krishna- murthy, A., and Foster, D. J. Correcting the mythos of kl-regularization: Direct alignment without overoptimiza- tion via chi-squared preference optimization,
-
[8]
arXiv preprint arXiv:2407.13399v3 , year=
URL https://arxiv.org/abs/2407.13399. Lattimore, T. and Szepesv´ari, C.Bandit algorithms. Cam- bridge University Press,
-
[9]
arXiv preprint arXiv:2406.02900 , year=
URL https://arxiv.org/abs/ 2406.02900. Shan, Z., Fan, C., Qiu, S., Shi, J., and Bai, C. Forward kl regularized preference optimization for aligning diffusion policies,
-
[10]
Sun, H., Xia, B., Chang, Y ., and Wang, X
URL https://arxiv.org/abs/ 2409.05622. Sun, H., Xia, B., Chang, Y ., and Wang, X. Generalizing alignment paradigm of text-to-image generation with pref- erences through f-divergence minimization,
- [11]
-
[12]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2309.16240 , year=
URL https: //arxiv.org/abs/2309.16240. Wu, D., Shi, C., Yang, J., and Shen, C. Greedy sampling is provably efficient for rlhf. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[16]
Gibbs sampling from human feedback: A provable kl-constrained framework for rlhf
Xiong, W., Dong, H., Ye, C., Wang, Z., Zhong, H., Ji, H., Jiang, N., and Zhang, T. Iterative preference learning from human feedback: Bridging theory and practice for rlhf under kl-constraint, 2024a. URLhttps://arxiv. org/abs/2312.11456. Xiong, W., Shi, C., Shen, J., Rosenberg, A., Qin, Z., Ca- landriello, D., Khalman, M., Joshi, R., Piot, B., Saleh, M., ...
-
[17]
Sharp analysis for kl-regularized contextual bandits and rlhf.arXiv preprint arXiv:2411.04625,
Zhao, H., Ye, C., Gu, Q., and Zhang, T. Sharp analysis for kl-regularized contextual bandits and rlhf.arXiv preprint arXiv:2411.04625,
-
[18]
Log- arithmic regret for online kl-regularized reinforcement learning, 2025a
Zhao, H., Ye, C., Xiong, W., Gu, Q., and Zhang, T. Log- arithmic regret for online kl-regularized reinforcement learning, 2025a. URL https://arxiv.org/abs/ 2502.07460. Zhao, Q., Ji, K., Zhao, H., Zhang, T., and Gu, Q. Towards a sharp analysis of offline policy learning for f-divergence- regularized contextual bandits, 2025b. URL https: //arxiv.org/abs/250...
-
[19]
Fine-Tuning Language Models from Human Preferences
10 f-Divergence Regularized RLHF: Two Tales of Sampling and Unified Analyses Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[20]
Due to the convexity off, thef-divergence is always non-negative. Lemma B.1.For any convexf, we have Df(p||q)≥0, Moreover, iffis strictly convex at1, thenD f(p||q) = 0only whenp=q. Proof.Sincefis convex, Jensen’s inequality suggests Df(p||q) =E q(x) f p(x) q(x) ≥f Eq(x) p(x) q(x) =f(1) = 0, which concludes the proof. Furthermore, thef-divergence is jointl...
work page 2023
-
[21]
∂U(x;γ) ∂γ = X a∈A " πr′(a|x)(r∗(x, a)−r(x, a)) 2 + ∂πr′(a|x) ∂γ γ(r ∗(x, a)−r(x, a)) 2 # , and ∂πr′(a|x) ∂γ = X a′ ∂πr′(a|x) ∂r ′(x, a′) ∂r ′(x, a′) ∂γ = X a′ " π0(a|x)h′(η(r′(x, a)−λ r′(x)))η(1{a′ =a} − ∂λr′(x) ∂r ′(x, a′)) # (r(x, a′)−r ∗(x, a′)) =η " π0(a|x)h′(η(r′(x, a)−λ r′(x))) # (r(x, a)−r ∗(x, a))−E a′∼π′ r′ [r(x, a′)−r ∗(x, a′)] ! . Thus, we hav...
work page 2023
-
[22]
Lemma D.4(Objective Decomposition).Fort∈[T], conditioning on the uniform optimism event thatE t holds, we have Jf(π∗ f)−J f(πt)≤4ηC(f,R Θ, η)Ea1∼πt,a2∼πt−1[(bt−1(x, a1, a2))2]. Proof.Denote ˜rt(x, a) = ˆrt(x, a)−E a′∼πt(·|x)[r(x, a′)−r ∗(x, a′)] =r θt(x, a) +E a′∼πt(·|x)[bt(x, a, a′)]−E a′∼πt(·|x)[r(x, a′)−r ∗(x, a′)]. By Lemma C.4,J f(πˆrt) =J f(π˜tt). N...
work page 2025
-
[23]
= 1 2(ˆθ−θ ∗)⊤(ηΣ1 ∗)(ˆθ−θ ∗) +o(||( ˆθ−θ ∗)||2 2).(17) By Theorem E.1, we have T· {J f(π∗)−J f(ˆπ)} d − →1 2 z⊤Ω 1 2 HΩ 1 2 z:=X, wherez∼ N(0, I),H=ηΣ 1 ∗ and this asymptotic result will be rigorously proved in Lemma E.3.Ωsatisfies Ω⪯C Z θ||ω||∞ ·(Σ 1 ∗)−1, and the matrixΩ 1 2 HΩ 1 2 can be bounded by Ω 1 2 HΩ 1 2 ⪯C Z θ||ω||∞ ·(Σ 1 ∗)− 1 2 H(Σ1 ∗)− 1 2 ...
work page 2025
-
[24]
For a general f, the above equation does not admit an explicit solution for λθ(x). We chose to solve this equation in Python using the “numpy.nsolve()” function to find a numerical solution forλθ(x), and use it to compute the numerical optimal policyπ θ(a|x) =π 0(a|x)h(η(rθ(x, a)− ˆλθ)). G.2. Experiment Setup We limit the scope to the linear case and assu...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.