Recognition: no theorem link
RRCM: Ranking-Driven Retrieval over Collaborative and Meta Memories for LLM Recommendation
Pith reviewed 2026-05-11 02:32 UTC · model grok-4.3
The pith
RRCM lets LLMs learn dynamic retrieval of collaborative and metadata memories optimized solely by ranking rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
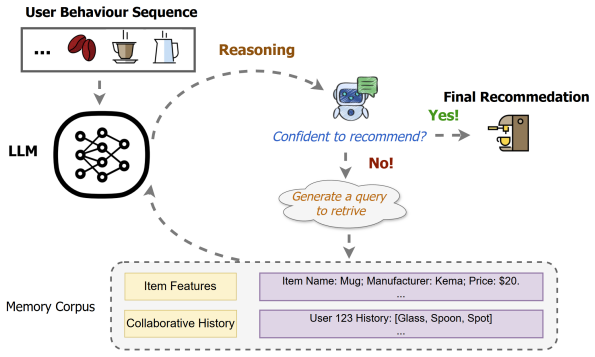
RRCM starts from a lightweight user-history context and learns whether to recommend directly, retrieve collaborative evidence, retrieve item metadata, or interleave both through reasoning, with both memories represented in natural language and accessed through a unified retrieval interface. The memory-reading policy is optimized with an outcome-only ranking reward instantiated using group relative policy optimization so that retrieval decisions are directly driven by final top-k recommendation quality.
What carries the argument
The memory-reading policy over natural-language collaborative and metadata memories, optimized via group relative policy optimization on an outcome-only ranking reward.
Load-bearing premise
The assumption that an outcome-only ranking reward based on final top-k recommendation quality is sufficient to learn an effective retrieval policy without additional supervision.
What would settle it
An experiment showing that a fixed retrieval policy or heuristic achieves equal or higher top-k accuracy than the learned RRCM policy on standard recommendation datasets would falsify the benefit of the ranking-driven optimization.
Figures


read the original abstract
Large Language Models (LLMs) have emerged as a promising paradigm for next-generation recommender systems, offering strong semantic understanding and natural-language reasoning abilities. Despite recent progress, current LLM-based recommenders still face key challenges in constructing decision-relevant contexts from heterogeneous evidence. First, existing methods often rely on fixed context construction strategies: collaborative behavioral evidence and item-side metadata are typically incorporated through predefined prompts, static retrieval pipelines, or handcrafted injection mechanisms, making it difficult to determine what information is truly beneficial for each instance. Second, heterogeneous evidence introduces a severe context-efficiency bottleneck. Rich metadata and collaborative interaction records can quickly overwhelm the context window, while aggressive compression or heuristic filtering may discard fine-grained evidence critical for accurate recommendation. To address these challenges, we propose RRCM, a ranking-driven retrieval-and-reasoning framework over collaborative and metadata memories for LLM-based agentic recommendation. RRCM starts from a lightweight user-history context and learns whether to recommend directly, retrieve collaborative evidence, retrieve item metadata, or interleave both through reasoning. Both memories are represented in natural language and accessed through a unified retrieval interface, enabling flexible evidence acquisition without handcrafted CF injection or fixed retrieval rules. We optimize this memory-reading policy with an outcome-only ranking reward, instantiated using group relative policy optimization, so that retrieval decisions are directly driven by final top-k recommendation quality. Extensive experiments show that RRCM significantly outperforms traditional baselines and diverse LLM-based recommendation approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RRCM, a framework for LLM-based recommendation that represents collaborative interaction histories and item metadata as natural-language memories and learns a policy (via group relative policy optimization) to decide whether to recommend directly, retrieve collaborative evidence, retrieve metadata, or interleave both. Retrieval decisions are optimized end-to-end using only an outcome-only ranking reward derived from final top-k recommendation quality, with the goal of overcoming fixed context-construction strategies and context-window bottlenecks.
Significance. If the claimed outperformance is robustly demonstrated, the work would be significant for LLM recommenders by replacing handcrafted or static retrieval rules with a learned, performance-driven memory-reading policy that operates over unified natural-language memories. This could improve both accuracy and context efficiency in handling heterogeneous evidence.
major comments (2)
- [Abstract] Abstract: the central claim that RRCM 'significantly outperforms traditional baselines and diverse LLM-based recommendation approaches' is unsupported by any visible experimental evidence, datasets, metrics, baselines, statistical tests, or ablation studies, leaving the primary contribution unverified.
- [Abstract] Abstract: the memory-reading policy is optimized solely via GRPO with an outcome-only ranking reward based on final top-k quality; this sparse, delayed signal risks ineffective credit assignment across the multi-step retrieval decisions (direct recommend vs. collaborative vs. metadata vs. interleave), and no analysis is provided to show that the learned policy discovers instance-specific benefits rather than converging to suboptimal fixed behaviors.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our work. We address each major comment point by point below, providing clarifications from the full manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that RRCM 'significantly outperforms traditional baselines and diverse LLM-based recommendation approaches' is unsupported by any visible experimental evidence, datasets, metrics, baselines, statistical tests, or ablation studies, leaving the primary contribution unverified.
Authors: The abstract is intended as a concise summary; the full manuscript (Sections 4 and 5) reports the supporting experiments. We evaluate on three standard datasets (MovieLens-1M, Amazon Beauty, Yelp), against traditional baselines (BPR, NCF, LightGCN) and LLM-based methods (P5, TALLRec, InstructRec), using HR@K and NDCG@K with paired t-tests for significance (p < 0.05 reported). Ablations on policy components, memory types, and retrieval decisions appear in Section 5.3. To improve visibility of this evidence, we will revise the abstract to include a brief statement of the key quantitative gains. revision: yes
-
Referee: [Abstract] Abstract: the memory-reading policy is optimized solely via GRPO with an outcome-only ranking reward based on final top-k quality; this sparse, delayed signal risks ineffective credit assignment across the multi-step retrieval decisions (direct recommend vs. collaborative vs. metadata vs. interleave), and no analysis is provided to show that the learned policy discovers instance-specific benefits rather than converging to suboptimal fixed behaviors.
Authors: GRPO's group-relative comparisons provide a denser learning signal than pure outcome-only RL by ranking multiple trajectories per prompt, which helps with credit assignment across the four decision types. The manuscript already includes policy analysis in Section 5.4 showing non-uniform retrieval patterns across users. We agree, however, that more explicit evidence against convergence to fixed behaviors would be valuable; we will add policy-distribution histograms, per-instance case studies, and an ablation contrasting GRPO against a fixed-rule baseline in the revision. revision: partial
Circularity Check
No significant circularity; derivation relies on external outcome reward
full rationale
The paper's core derivation optimizes a memory-reading policy via GRPO using an outcome-only ranking reward derived from final top-k recommendation quality. This reward signal is defined externally from recommendation performance rather than from any fitted internal parameters or self-referential quantities. No equations, self-citations, or ansatzes in the abstract reduce the claimed policy learning or performance gains to tautological inputs by construction. The approach applies standard RL techniques to retrieval decisions over natural-language memories without self-definitional loops or renaming of known results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can reliably reason about when to retrieve from natural-language memories to improve recommendation quality.
Reference graph
Works this paper leans on
-
[1]
A survey on large language models for recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al. A survey on large language models for recommendation. World Wide Web, 27(5):60, 2024
work page 2024
-
[2]
Large language models for recommendation with deliberative user preference alignment
Yi Fang, Wenjie Wang, Yang Zhang, Fengbin Zhu, Qifan Wang, Fuli Feng, and Xiangnan He. Reason4rec: Large language models for recommendation with deliberative user preference alignment.arXiv preprint arXiv:2502.02061, 2025
-
[3]
Matrix factorization techniques for recom- mender systems.Computer, 42(8):30–37, 2009
Yehuda Koren, Robert Bell, and Chris V olinsky. Matrix factorization techniques for recom- mender systems.Computer, 42(8):30–37, 2009
work page 2009
-
[4]
Steffen Rendle. Factorization machines. In2010 IEEE International conference on data mining, pages 995–1000. IEEE, 2010
work page 2010
-
[5]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE, 2018
work page 2018
-
[6]
Yang Zhang, Keqin Bao, Ming Yan, Wenjie Wang, Fuli Feng, and Xiangnan He. Text-like encoding of collaborative information in large language models for recommendation.arXiv preprint arXiv:2406.03210, 2024
-
[7]
Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He. Collm: Integrating collaborative embeddings into large language models for recommendation.IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[8]
arXiv preprint arXiv:2409.12740 , year=
Junyi Chen, Lu Chi, Bingyue Peng, and Zehuan Yuan. Hllm: Enhancing sequential recom- mendations via hierarchical large language models for item and user modeling.arXiv preprint arXiv:2409.12740, 2024
-
[9]
Recgpt technical report.arXiv preprint arXiv:2507.22879, 2025
Chao Yi, Dian Chen, Gaoyang Guo, Jiakai Tang, Jian Wu, Jing Yu, Mao Zhang, Sunhao Dai, Wen Chen, Wenjun Yang, et al. Recgpt technical report.arXiv preprint arXiv:2507.22879, 2025
-
[10]
Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. Cognitive mirage: A review of hallucinations in large language models.arXiv preprint arXiv:2309.06794, 2023
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems, pages 299–315, 2022
work page 2022
-
[13]
Improving llm-powered recommendations with personalized information
Jiahao Liu, Xueshuo Yan, Dongsheng Li, Guangping Zhang, Hansu Gu, Peng Zhang, Tun Lu, Li Shang, and Ning Gu. Improving llm-powered recommendations with personalized information. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2560–2565, 2025
work page 2025
-
[14]
Hymirec: A hybrid multi-interest learning framework for llm-based sequential recommendation
Jingyi Zhou, Cheng Chen, Kai Zuo, Manjie Xu, Zhendong Fu, Yibo Chen, Xu Tang, and Yao Hu. Hymirec: A hybrid multi-interest learning framework for llm-based sequential recommendation. arXiv preprint arXiv:2510.13738, 2025
-
[15]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[16]
Knowledge graph retrieval-augmented generation for llm-based recommendation
Shijie Wang, Wenqi Fan, Yue Feng, Lin Shanru, Xinyu Ma, Shuaiqiang Wang, and Dawei Yin. Knowledge graph retrieval-augmented generation for llm-based recommendation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 27152–27168, 2025. 10
work page 2025
-
[17]
Knowledge graph self- supervised rationalization for recommendation
Yuhao Yang, Chao Huang, Lianghao Xia, and Chunzhen Huang. Knowledge graph self- supervised rationalization for recommendation. InProceedings of the 29th ACM SIGKDD conference on knowledge discovery and data mining, pages 3046–3056, 2023
work page 2023
-
[18]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2023
work page 2023
-
[19]
Self-rag: Learning to retrieve, generate, and critique through self-reflection.ICLR, 2024
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection.ICLR, 2024
work page 2024
-
[20]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36: 68539–68551, 2023
work page 2023
-
[21]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page Pith review arXiv 2025
-
[22]
Sprec: Self-play to debias llm-based recommendation
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. Sprec: Self-play to debias llm-based recommendation. InProceedings of the ACM on Web Conference 2025, pages 5075–5084, 2025
work page 2025
-
[23]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems, 3(4):1–27, 2025
work page 2025
-
[24]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019. URL https://arxiv.org/ abs/1908.10084
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[25]
Item recommendation on monotonic behavior chains
Mengting Wan and Julian McAuley. Item recommendation on monotonic behavior chains. In Proceedings of the 12th ACM conference on recommender systems, pages 86–94, 2018
work page 2018
-
[26]
F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis), 5(4):1–19, 2015
work page 2015
-
[27]
Ruining He and Julian McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. Inproceedings of the 25th international conference on world wide web, pages 507–517, 2016
work page 2016
-
[28]
Keqin Bao, Jizhi Zhang, Yang Zhang, Xinyue Huo, Chong Chen, and Fuli Feng. Decoding matters: Addressing amplification bias and homogeneity issue for llm-based recommendation. arXiv preprint arXiv:2406.14900, 2024
-
[29]
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, and Tat-Seng Chua. On softmax direct preference optimization for recommendation.Advances in Neural Information Processing Systems, 37:27463–27489, 2024
work page 2024
-
[30]
Session-based Recommendations with Recurrent Neural Networks
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939, 2015
work page internal anchor Pith review arXiv 2015
-
[31]
Aligning large language model with direct multi-preference optimization for recommendation
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, and Yun Xiong. Aligning large language model with direct multi-preference optimization for recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 76–86, 2024
work page 2024
-
[32]
Leveraging llm reasoning enhances personalized recommender systems
Alicia Tsai, Adam Kraft, Long Jin, Chenwei Cai, Anahita Hosseini, Taibai Xu, Zemin Zhang, Lichan Hong, Ed H Chi, and Xinyang Yi. Leveraging llm reasoning enhances personalized recommender systems. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13176–13188, 2024. 11
work page 2024
-
[33]
Reinforced latent reasoning for llm-based recommendation,
Yang Zhang, Wenxin Xu, Xiaoyan Zhao, Wenjie Wang, Fuli Feng, Xiangnan He, and Tat- Seng Chua. Reinforced latent reasoning for llm-based recommendation.arXiv preprint arXiv:2505.19092, 2025
-
[34]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
work page 2024
-
[35]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review arXiv 2022
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[37]
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering.Advances in Neural Information Processing Systems, 37:132876–132907, 2024
work page 2024
-
[38]
Recmind: Large language model powered agent for recommendation
Yancheng Wang, Ziyan Jiang, Zheng Chen, Fan Yang, Yingxue Zhou, Eunah Cho, Xing Fan, Yanbin Lu, Xiaojiang Huang, and Yingzhen Yang. Recmind: Large language model powered agent for recommendation. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 4351–4364, 2024
work page 2024
-
[39]
Star: A simple training- free approach for recommendations using large language models,
Dong-Ho Lee, Adam Kraft, Long Jin, Nikhil Mehta, Taibai Xu, Lichan Hong, Ed H Chi, and Xinyang Yi. Star: A simple training-free approach for recommendations using large language models.arXiv preprint arXiv:2410.16458, 2024
-
[40]
MemRec: Collaborative Memory-Augmented Agentic Recommender System
Weixin Chen, Yuhan Zhao, Jingyuan Huang, Zihe Ye, Clark Mingxuan Ju, Tong Zhao, Neil Shah, Li Chen, and Yongfeng Zhang. Memrec: Collaborative memory-augmented agentic recommender system.arXiv preprint arXiv:2601.08816, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Donghee Han, Hwanjun Song, and Mun Yong Yi. Rethinking llm-based recommendations: A query generation-based, training-free approach.arXiv e-prints, pages arXiv–2504, 2025
work page 2025
-
[42]
Collaborative retrieval for large language model-based conversational recommender systems
Yaochen Zhu, Chao Wan, Harald Steck, Dawen Liang, Yesu Feng, Nathan Kallus, and Jundong Li. Collaborative retrieval for large language model-based conversational recommender systems. InProceedings of the ACM on Web Conference 2025, pages 3323–3334, 2025
work page 2025
-
[43]
Llm- based conversational recommendation agents with collaborative verbalized experience
Yaochen Zhu, Harald Steck, Dawen Liang, Yinhan He, Nathan Kallus, and Jundong Li. Llm- based conversational recommendation agents with collaborative verbalized experience. Associ- ation for Computational Linguistics, 2025
work page 2025
-
[44]
arXiv preprint arXiv:2503.24289 , year=
Jiacheng Lin, Tian Wang, and Kun Qian. Rec-r1: Bridging generative large language mod- els and user-centric recommendation systems via reinforcement learning.arXiv preprint arXiv:2503.24289, 2025
-
[45]
Bowen Zheng, Xiaolei Wang, Enze Liu, Xi Wang, Lu Hongyu, Yu Chen, Wayne Xin Zhao, and Ji-Rong Wen. Deeprec: Towards a deep dive into the item space with large language model based recommendation.arXiv preprint arXiv:2505.16810, 2025
-
[46]
Rank-grpo: Training llm-based conversational recommender systems with reinforcement learning, 2026
Yaochen Zhu, Harald Steck, Dawen Liang, Yinhan He, Vito Ostuni, Jundong Li, and Nathan Kallus. Rank-grpo: Training llm-based conversational recommender systems with reinforcement learning.arXiv preprint arXiv:2510.20150, 2025
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 12 A Experiment Details We conduct all experiments on a dedicated NVIDIA GH200 superchip equipped with an H100 GPU. Specifica...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.