Recognition: 2 theorem links
· Lean TheoremMemRec: Collaborative Memory-Augmented Agentic Recommender System
Pith reviewed 2026-05-16 14:33 UTC · model grok-4.3
The pith
MemRec improves agentic recommender systems by using a lightweight model to synthesize and distill a dynamic collaborative memory graph for a larger reasoning model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MemRec architecturally decouples memory management from reasoning by introducing a dedicated lightweight language model (LM_Mem) that efficiently builds and synthesizes a dynamic collaborative memory graph from user-item co-engagements and peer relationships, supplying only distilled high-signal contexts to a downstream heavyweight LLM_Rec for recommendation.
What carries the argument
The dedicated lightweight LM_Mem that manages and synthesizes the dynamic collaborative memory graph, providing distilled contexts to the main model.
Load-bearing premise
The lightweight LM_Mem can reliably distill high-signal collaborative contexts from the memory graph without losing critical relational information or introducing noise that harms the downstream LLM_Rec.
What would settle it
Replacing the LM_Mem distillation step with direct unfiltered passage of the full collaborative memory graph to LLM_Rec and measuring whether recommendation accuracy on the four benchmarks stays the same or improves would refute the need for the dedicated synthesis module.
Figures














read the original abstract
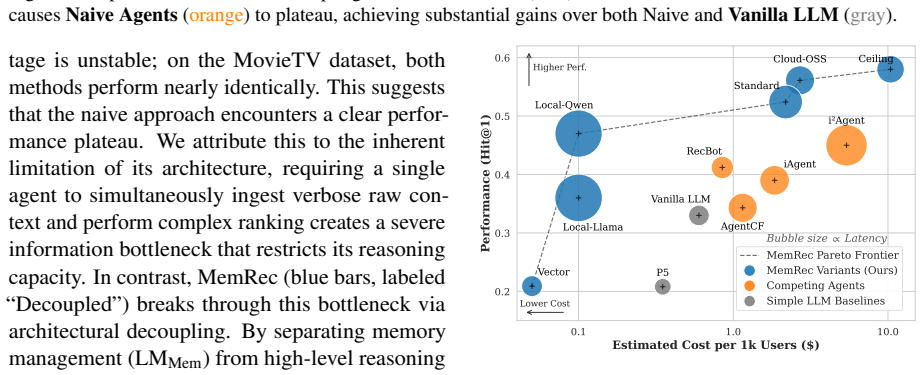
The evolution of recommender systems has shifted from traditional collaborative filtering to LLM-based agentic systems, which rely on semantic user and item memories to make predictions. However, existing agents maintain these memories in isolation. This overlooks crucial collaborative signals, such as user-item co-engagements and peer relationships across the community, which significantly limits their ability to uncover hidden preferences and accurately infer user needs, particularly for data-sparse users. To bridge this gap, we introduce collaborative memory, a paradigm that connects isolated semantics to enable the sharing of relational insights. Yet, naively utilizing collaborative memory causes severe context overload and introduces noise to downstream LLMs, alongside prohibitive computational costs. To resolve this, we propose MemRec, a framework that architecturally decouples memory management from reasoning. MemRec introduces a dedicated, lightweight language model (LM_Mem) to efficiently manage and synthesize a dynamic collaborative memory graph in the background. It provides only distilled, high-signal contexts to a downstream, heavyweight large language model (LLM_Rec) for the final recommendation. Extensive experiments on four benchmarks demonstrate that MemRec achieves state-of-the-art performance. Code: https://github.com/rutgerswiselab/memrec and Homepage: https://memrec.weixinchen.com/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MemRec, an agentic recommender that introduces collaborative memory to connect isolated user and item semantics via user-item co-engagements and peer relations. It decouples memory management from reasoning by employing a lightweight LM_Mem to synthesize and maintain a dynamic collaborative memory graph in the background, distilling only high-signal contexts for a heavyweight LLM_Rec to generate recommendations. The framework is evaluated on four benchmarks where it reports state-of-the-art performance, with code released.
Significance. If the empirical claims hold after addressing the gaps in verification, the work would be significant for LLM-based recommender systems. It offers a practical engineering solution to incorporate community-level collaborative signals without context overload or prohibitive costs, which could particularly benefit data-sparse users and advance agentic architectures beyond isolated memory models.
major comments (2)
- [Abstract] Abstract and experimental section: The manuscript reports SOTA results on four benchmarks but supplies no details on the specific baselines, ablation studies isolating the contribution of the collaborative memory graph versus prompt format or base LLM, or statistical significance testing. This leaves the central empirical claim only moderately supported.
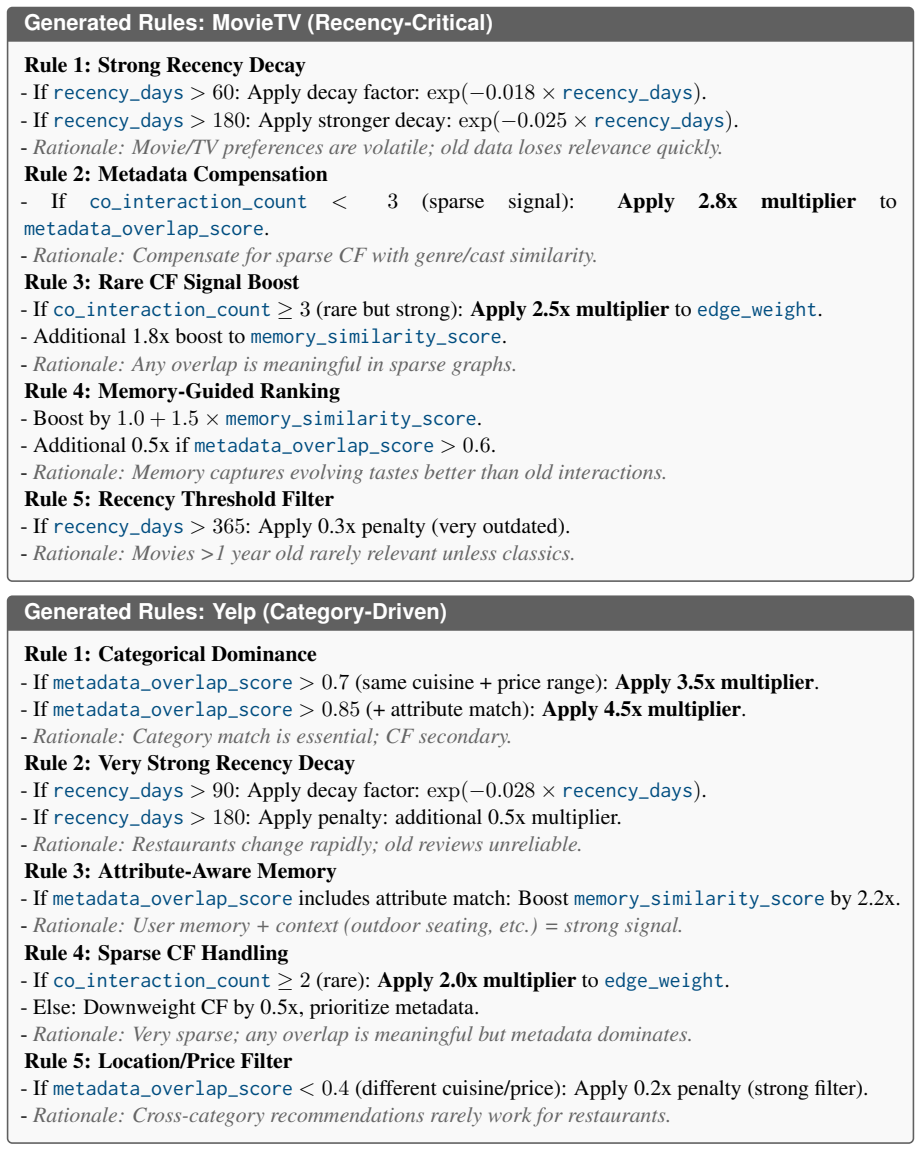
- [Memory synthesis description] Section describing LM_Mem synthesis: The claim that LM_Mem reliably produces distilled high-signal contexts from the collaborative memory graph is load-bearing for the decoupling architecture, yet no intermediate diagnostics (e.g., relation recall, noise injection rate, or graph-edit distance) are reported to confirm preservation of critical triples such as user-item co-engagements. End-to-end metrics alone cannot rule out that gains arise from other unablated factors.
minor comments (1)
- [Code and reproducibility] The code repository link is provided, but the manuscript should include a brief description of the exact experimental setup, data splits, and hyperparameter choices to facilitate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to strengthen the empirical validation of our claims. We address each major point below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: The manuscript reports SOTA results on four benchmarks but supplies no details on the specific baselines, ablation studies isolating the contribution of the collaborative memory graph versus prompt format or base LLM, or statistical significance testing. This leaves the central empirical claim only moderately supported.
Authors: We agree that additional details are required to robustly support the SOTA claims. While Section 4 and Table 1 present comparisons to multiple baselines (including both traditional collaborative filtering and recent LLM-based methods), we will expand the experimental section to explicitly enumerate all baseline configurations, introduce targeted ablations that isolate the collaborative memory graph (e.g., variants without the graph and prompt-only controls), and report statistical significance via paired t-tests with p-values across repeated runs. These changes will be included in the revision. revision: yes
-
Referee: [Memory synthesis description] Section describing LM_Mem synthesis: The claim that LM_Mem reliably produces distilled high-signal contexts from the collaborative memory graph is load-bearing for the decoupling architecture, yet no intermediate diagnostics (e.g., relation recall, noise injection rate, or graph-edit distance) are reported to confirm preservation of critical triples such as user-item co-engagements. End-to-end metrics alone cannot rule out that gains arise from other unablated factors.
Authors: We acknowledge that intermediate diagnostics would provide stronger evidence for the reliability of LM_Mem. The current evaluation relies on end-to-end recommendation metrics, which do not directly verify triple preservation. In the revision we will add quantitative diagnostics including relation recall for user-item co-engagements and peer relations, noise injection rates in the distilled contexts, and selected graph-edit distance measurements, together with qualitative examples of preserved triples. This will help confirm that performance gains stem from the collaborative memory component. revision: yes
Circularity Check
No significant circularity detected; claims rest on empirical validation rather than self-referential definitions or fitted predictions.
full rationale
The paper introduces an architectural framework (LM_Mem for graph synthesis feeding distilled contexts to LLM_Rec) and supports its SOTA claims solely through end-to-end benchmark results on four external datasets. No equations, parameter-fitting steps, or derivations appear that reduce any performance prediction to a fitted input or self-citation chain by construction. The central decoupling argument is presented as an engineering choice whose value is measured externally, with no load-bearing uniqueness theorem or ansatz imported from prior self-work. This is the common honest case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Collaborative signals such as user-item co-engagements and peer relationships improve preference inference beyond isolated semantic memories
invented entities (1)
-
collaborative memory graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MemRec introduces a dedicated, lightweight language model (LM_Mem) to efficiently manage and synthesize a dynamic collaborative memory graph... provides only distilled, high-signal contexts to a downstream, heavyweight large language model (LLM_Rec)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Curate-then-Synthesize strategy... LLM-Guided Context Curation... Collaborative Memory Synthesis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
Agentic Recommender System with Hierarchical Belief-State Memory
MARS uses hierarchical memory and LLM planning to achieve 26.4% higher HR@1 on InstructRec benchmarks compared to prior methods.
-
SAGER: Self-Evolving User Policy Skills for Recommendation Agent
SAGER equips LLM recommendation agents with per-user evolving policy skills via two-representation architecture, contrastive CoT diagnosis, and skill-augmented listwise reasoning, yielding SOTA gains orthogonal to mem...
-
RRCM: Ranking-Driven Retrieval over Collaborative and Meta Memories for LLM Recommendation
RRCM trains an LLM to dynamically retrieve from collaborative and meta memories using group relative policy optimization driven by final top-k recommendation quality.
-
TimeMM: Time-as-Operator Spectral Filtering for Dynamic Multimodal Recommendation
TimeMM proposes a time-as-operator spectral filtering framework with adaptive mixing and modality routing to model non-stationary multimodal user preferences in recommendation systems.
-
Self-Distilled Reinforcement Learning for Co-Evolving Agentic Recommender Systems
CoARS enables co-evolving recommender and user agents by using interaction-derived rewards and self-distilled credit assignment to internalize multi-turn feedback into model parameters, outperforming prior agentic baselines.
-
AgenticRecTune: Multi-Agent with Self-Evolving Skillhub for Recommendation System Optimization
AgenticRecTune deploys five LLM agents (Actor, Critic, Insight, Skill, Online) and a self-evolving Skillhub to handle end-to-end configuration optimization for multi-stage recommendation systems.
-
AgenticRecTune: Multi-Agent with Self-Evolving Skillhub for Recommendation System Optimization
AgenticRecTune deploys Actor, Critic, Insight, Skill, and Online agents plus a self-evolving Skillhub to propose, filter, test, and learn from recommendation system configurations using Gemini LLMs.
Reference graph
Works this paper leans on
-
[1]
Llm as gnn: Graph vocabulary learning for text-attributed graph foundation models.arXiv preprint arXiv:2503.03313. Xiaojin Zhu and Zoubin Ghahramani. 2002. Learn- ing from labeled and unlabeled data with label prop- agation. Technical Report CMU-CALD-02-107, Carnegie Mellon University. Contents 1 Introduction . . . . . . . . . . . . . . . . . . . . . . . ...
-
[2]
User/Item Memory Update: Updating the narrative memories of the interacting user and item nodes to reflect the new interaction
-
[3]
In 2050, civilization has become sterile, controlled... boring. A dystopian setting
Collaborative Propagation: Identifying relevant neighboring nodes and propagating insights from the interaction to update their memories, thereby enriching the graph’s collaborative signals for future retrievals. Figure 15 shows the comprehensive prompt that handles these updates concurrently. F.6 Rationale Quality Evaluation Protocol We evaluate the qual...
work page 2014
-
[4]
Fan of Y A fantasy, adventurous themes, and strong world-building
User Memory Update (User 2057): •[OLD]: "Fan of Y A fantasy, adventurous themes, and strong world-building." • [NEW]: "Fan of Y A fantasy anddystopian fiction. Confirmed strong interest in the’graphic novel format’combined withcomplex, emotional storytelling."
work page 2057
-
[5]
graphic novel, spin-off series
Target Item Memory Update (Attack on Titan): •[OLD]: "...graphic novel, spin-off series..." • [NEW]: "...graphic novel known for stunning visuals.Validated appeal for YA fantasy readers seeking immersive dystopian worlds and complex narratives." Rationale: "The item’s memory is updated to reflect its appeal to the specific user profile that engaged with it."
-
[6]
Interested in humorous young adult novels... explores teenage experiences
Neighbor Propagation Update (User-4023): •[OLD]: "Interested in humorous young adult novels... explores teenage experiences..." • [NEW]: "...appreciatesstrong character development and emotional depth. May enjoy narratives that blend humor with serious, complex themes." Rationale: "Insights on ’strong character development’ from the interaction are propag...
work page 2057
-
[7]
Basedonlyon the domain context provided, generate 3-5 high-priority, interpretable ranking rules
-
[8]
The rules should explain how tocombineorprioritizethe available features to find the best neighbors forthis specific domain
-
[9]
Be specific about thresholds and weights. For example: - Good: "Prioritize users with ‘co_interaction_count‘ > 3 AND apply a 2.0x multiplier to ‘metadata_overlap_score‘" - Bad: "Use metadata when relevant"
-
[10]
I love fantasy novels with strong female protagonists
Consider that book recommendations are highly content-driven (genre, author, themes) and users often have stable long-term preferences. OUTPUT FORMAT: Rule 1: [Your rule here] Rule 2: [Your rule here] Rule 3: [Your rule here] ... Figure 9: The generic meta-prompt template used by LMMem to generate domain-specific curation rules. Context: InstructRec-Books...
-
[11]
interest in mystery novels with strong female protagonists
A concise natural language description of the preference (e.g., "interest in mystery novels with strong female protagonists")
-
[12]
A confidence score between 0 and 1 indicating how strongly this facet is supported by the evidence
-
[13]
facets": An array of facet objects, each containing: *
A list of supporting neighbors (user IDs or item IDs) that provide evidence for this facet Additionally, identify the collaborative edges between neighboring users/items and the target user, with edge weights (0-1) indicating the strength of collaborative signal. Expected Output Format:Your response should be a JSON object with two fields: - "facets": An ...
-
[14]
A summary of the target User’s interests
-
[15]
The recommended Item name
-
[16]
Rationale A (generated by Model A)
-
[17]
Rationale B (generated by Model B)
-
[18]
You must evaluate each rationale independently on three distinct criteria using a 1-5 Likert scale
Rationale C (generated by Model C). You must evaluate each rationale independently on three distinct criteria using a 1-5 Likert scale. Evaluation Criteria & Scoring Rubric:
-
[19]
Specificity (1-5 Points)Measure how concrete and detailed the rationale is regarding the recom- mended item. - 1 (Vague): Very generic; could apply to many items in the category (e.g., "It’s a good book"). - 3 (Moderate): Mentions general themes or genre traits but lacks specific details. - 5 (Highly Specific): Richly detailed; mentions specific plot elem...
-
[20]
- 1 (Irrelevant): A generic recommendation unrelated to the user’s known interests
Relevance (1-5 Points)Measure how well the rationale explains *why* this item suits this specific user based on their profile. - 1 (Irrelevant): A generic recommendation unrelated to the user’s known interests. - 3 (Acceptable): Makes a basic connection to user genre preferences. - 5 (Highly Personalized): explicitly ties specific item features to specifi...
-
[21]
Factuality (1-5 Points)Measure the accuracy of the claims made about the item. - 1 (Hallucinated): Contains major factual errors or describes a different item entirely. - 5 (Accurate): All claims about the item’s content and characteristics are factually correct. Output Format:You must output strictly valid JSON immediately, without any additional text. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.