Recognition: 2 theorem links
· Lean TheoremBeyond Reasoning: Reinforcement Learning Unlocks Parametric Knowledge in LLMs
Pith reviewed 2026-05-11 01:23 UTC · model grok-4.3
The pith
Reinforcement learning improves factual recall in LLMs by redistributing probability mass over existing parametric knowledge rather than acquiring new facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
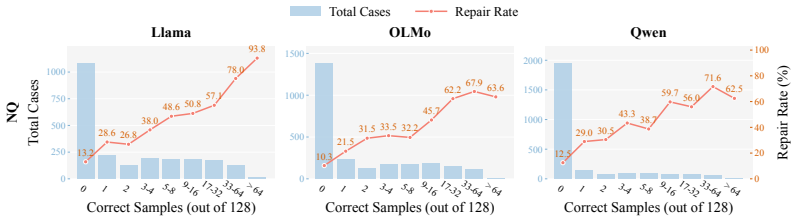
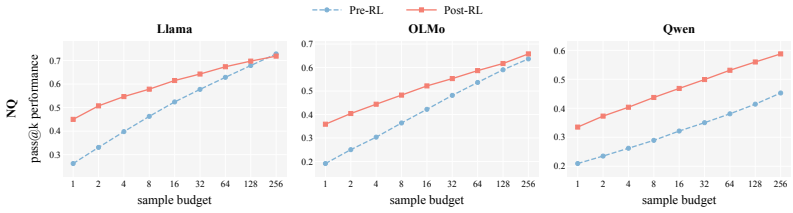
In a zero-shot closed-book factual QA setting with binary rewards and train-test deduplication, RL training produces roughly 27 percent average relative accuracy gains across three model families. These gains exceed those from standard supervised fine-tuning or inference-time methods. Analysis shows the improvement arises from shifting probability mass toward already-present correct answers, elevating them from low-likelihood regions to reliable greedy generations. Attribution further reveals that examples where correct answers never surfaced in 128 pre-RL samples, comprising only about 18 percent of the data, account for approximately 83 percent of the total gain because occasional correct
What carries the argument
Binary-reward reinforcement learning applied to factual QA rollouts, which selectively reinforces rare correct answer sequences to redistribute probability mass within the model's existing parametric knowledge.
Where Pith is reading between the lines
- The same RL redistribution mechanism could be tested on tasks beyond one-hop QA, such as multi-hop retrieval or domain-specific knowledge surfacing, to see if low-probability facts become accessible without new data.
- If the hardest examples drive gains because they still produce occasional correct rollouts, training regimes might be optimized by upweighting examples with the lowest initial success rates.
- This view of RL as a probability reshaper rather than a knowledge injector suggests it could complement rather than replace continued pre-training when the goal is reliable factual generation.
Load-bearing premise
That the zero-shot closed-book setup with fact-level deduplication and binary rewards fully separates improved parametric recall from side effects such as format learning or reduced refusal.
What would settle it
A post-training measurement showing that the model now correctly answers questions whose answers never appeared in any pre-RL generation samples, or that accuracy gains vanish when the model is forced to sample only from pre-RL probability distributions.
Figures















read the original abstract
Reinforcement learning (RL) has achieved remarkable success in LLM reasoning, but whether it can also improve direct recall of parametric knowledge remains an open question. We study this question in a controlled zero-shot, one-hop, closed-book QA setting with no chain-of-thought, training only on binary correctness rewards and applying fact-level train-test deduplication to ensure gains reflect improved recall rather than reasoning or memorization. Across three model families and multiple factual QA benchmarks, RL yields ~27% average relative gains, surpassing both training- and inference-time baselines alike. Mechanistically, RL primarily redistributes probability mass over existing knowledge rather than acquiring new facts, moving correct answers from the low-probability tail into reliable greedy generations. Our data-attribution study reveals that the hardest examples are the most informative: those whose answers never appear in 128 pre-RL samples (only ~18% of training data) drive ~83% of the gain, since rare correct rollouts still emerge during training and get reinforced. Together, these findings broaden the role of RL beyond reasoning, repositioning it as a tool for unlocking rather than acquiring latent parametric knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that RL with binary correctness rewards in a zero-shot closed-book one-hop QA setting (with fact-level deduplication) improves LLM factual recall by ~27% relative on average across three model families and multiple benchmarks. Gains are attributed to redistribution of probability mass over pre-existing parametric knowledge (moving correct answers from low-probability tails to greedy outputs) rather than acquisition of new facts, with a data-attribution analysis showing that the hardest examples (zero correct pre-RL samples, ~18% of data) drive ~83% of the improvement.
Significance. If the central interpretation holds, the work would meaningfully broaden RL's role from reasoning to efficient elicitation of latent parametric knowledge, with practical value for knowledge-intensive applications and the attribution results providing a useful lens on which examples benefit most. The multi-family, multi-benchmark design and focus on mechanistic redistribution add to its potential impact beyond raw performance numbers.
major comments (2)
- [data-attribution study (results section)] The data-attribution result (hard examples with zero correct pre-RL samples driving ~83% of the gain) does not isolate improved parametric recall from format compliance or refusal suppression. Because the binary reward is only assigned to correctly formatted answers, any concurrent improvement in output conventions would inflate measured gains without changing underlying knowledge; this directly affects the claim that RL 'primarily redistributes probability mass over existing knowledge rather than acquiring new facts.'
- [experimental setup and baselines (methods and results sections)] The experimental controls (zero-shot closed-book framing and fact-level deduplication) prevent overt memorization and leakage but do not include ablations that would rule out format learning, such as a format-only reward baseline or comparison to supervised fine-tuning on answer formatting. Without these, the ~27% relative gains cannot be attributed solely to recall of existing parametric knowledge.
minor comments (2)
- [Abstract] The abstract reports an average relative gain of ~27% but does not specify the exact aggregation method (e.g., macro-average across benchmarks/models) or include error bars/variance; adding these would strengthen the empirical claims.
- [experimental setup] Clarify the precise definition of 'one-hop' factual QA and confirm that all evaluated benchmarks strictly adhere to this criterion without implicit multi-hop elements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. These points help clarify the scope of our claims regarding RL as a mechanism for eliciting latent parametric knowledge. We respond to each major comment below, providing additional context from our experiments and outlining targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [data-attribution study (results section)] The data-attribution result (hard examples with zero correct pre-RL samples driving ~83% of the gain) does not isolate improved parametric recall from format compliance or refusal suppression. Because the binary reward is only assigned to correctly formatted answers, any concurrent improvement in output conventions would inflate measured gains without changing underlying knowledge; this directly affects the claim that RL 'primarily redistributes probability mass over existing knowledge rather than acquiring new facts.'
Authors: We appreciate this concern about potential confounds in the reward signal. Our prompts explicitly instruct models to output direct answers in a fixed format (e.g., 'The answer is X'), and pre-RL sampling across 128 rollouts per example shows format compliance rates exceeding 92% even on incorrect responses. Post-RL, format compliance remains stable at ~94-96% while accuracy rises, indicating that gains are not driven by format acquisition. For refusal suppression, refusals (e.g., 'I don't know') occur in <3% of pre-RL samples and are not systematically reduced by RL; the binary reward penalizes both incorrect and refused outputs equally. The data-attribution result—that examples with zero correct pre-RL samples (~18% of data) account for ~83% of gains—further supports redistribution: these examples only improve when a correct rollout emerges during training and receives reinforcement, consistent with surfacing low-probability parametric knowledge rather than learning new conventions. We will add a dedicated paragraph with these compliance statistics and refusal rates in the revised results section to make this isolation explicit. revision: partial
-
Referee: [experimental setup and baselines (methods and results sections)] The experimental controls (zero-shot closed-book framing and fact-level deduplication) prevent overt memorization and leakage but do not include ablations that would rule out format learning, such as a format-only reward baseline or comparison to supervised fine-tuning on answer formatting. Without these, the ~27% relative gains cannot be attributed solely to recall of existing parametric knowledge.
Authors: We agree that dedicated format-learning ablations would provide stronger causal evidence and rule out the alternative interpretation more definitively. Our existing training baselines include full supervised fine-tuning on the QA pairs (which embeds both content and format) as well as inference-time methods like best-of-N sampling; these are outperformed by RL, but they do not isolate format alone. In the revision, we will add two new controls: (1) a format-only reward baseline that assigns reward for any correctly formatted output irrespective of factual correctness, and (2) an SFT baseline trained solely on formatting instructions without content labels. We expect both to yield near-zero accuracy gains, reinforcing that the observed improvements stem from content recall. These will be reported in an expanded 'Ablations' subsection of the results. revision: yes
Circularity Check
No circularity: empirical results rest on controlled experiments and sampling statistics, not self-referential definitions or fitted inputs
full rationale
The paper reports RL training outcomes on factual QA with binary rewards, fact-level deduplication, and pre/post-RL sampling to measure probability redistribution. The ~27% gains and 83% attribution to hard examples are computed directly from observed rollouts and accuracy deltas across independent benchmarks and model families. No equations define a quantity in terms of itself, no parameters are fitted then relabeled as predictions, and no self-citations supply uniqueness theorems or ansatzes. The derivation chain consists of standard RL policy optimization followed by empirical measurement; the controls (zero-shot closed-book, train-test split) are external to the measured quantities and do not reduce the reported gains to tautologies.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesRL primarily redistributes probability mass over existing knowledge rather than acquiring new facts, moving correct answers from the low-probability tail into reliable greedy generations.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearthe hardest examples are the most informative: those whose answers never appear in 128 pre-RL samples ... drive ~83% of the gain
Reference graph
Works this paper leans on
-
[1]
The internal state of an LLM knows when it ' s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it ' s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967--976, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[2]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher R \'e , and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Ask the right questions: Active question reformulation with reinforcement learning
Christian Buck, Jannis Bulian, Massimiliano Ciaramita, Wojciech Gajewski, Andrea Gesmundo, Neil Houlsby, and Wei Wang. Ask the right questions: Active question reformulation with reinforcement learning. In International Conference on Learning Representations, 2018
work page 2018
-
[4]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[5]
Xilun Chen, Ilia Kulikov, Vincent-Pierre Berges, Barlas O g uz, Rulin Shao, Gargi Ghosh, Jason Weston, and Wen-tau Yih. Learning to reason for factuality. arXiv preprint arXiv:2508.05618, 2025
-
[6]
SFT memorizes, RL generalizes: A comparative study of foundation model post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. SFT memorizes, RL generalizes: A comparative study of foundation model post-training. In Forty-second International Conference on Machine Learning, 2025
work page 2025
-
[7]
Measuring and improving consistency in pretrained language models
Yanai Elazar, Nora Kassner, Shauli Ravfogel, Abhilasha Ravichander, Eduard Hovy, Hinrich Sch \"u tze, and Yoav Goldberg. Measuring and improving consistency in pretrained language models. Transactions of the Association for Computational Linguistics, 9: 0 1012--1031, 2021
work page 2021
-
[8]
Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. Does fine-tuning LLM s on new knowledge encourage hallucinations? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7765--7784, Miami, Florida, USA, November 2024. Association for Computational Linguistics
work page 2024
-
[9]
Inside-out: Hidden factual knowledge in LLM s
Zorik Gekhman, Eyal Ben-David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpektor, Jonathan Herzig, and Roi Reichart. Inside-out: Hidden factual knowledge in LLM s. In Second Conference on Language Modeling, 2025
work page 2025
-
[10]
arXiv preprint arXiv:2603.09906 , year=
Zorik Gekhman, Roee Aharoni, Eran Ofek, Mor Geva, Roi Reichart, and Jonathan Herzig. Thinking to recall: How reasoning unlocks parametric knowledge in llms. arXiv preprint arXiv:2603.09906, 2026
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature, 645 0 (8081): 0 633--638, September 2025. ISSN 1476-4687
work page 2025
-
[13]
Xu, Jun Araki, and Graham Neubig
Zhengbao Jiang, Frank F. Xu, Jun Araki, and Graham Neubig. How can we know what language models know? Transactions of the Association for Computational Linguistics, 8: 0 423--438, 2020
work page 2020
-
[14]
T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601--1611, Vancouver, Canada, July 2017. Association for Computational Linguistics
work page 2017
-
[15]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transac...
work page 2019
-
[16]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th Symposium on Operating Systems Principles, pages 611--626, New York, NY, USA, 2023. Association for Computing Machinery
work page 2023
-
[17]
Coderl: Mastering code generation through pretrained models and deep reinforcement learning
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. Advances in Neural Information Processing Systems, 35: 0 21314--21328, 2022
work page 2022
-
[18]
Junyi Li and Hwee Tou Ng. Reasoning models hallucinate more: Factuality-aware reinforcement learning for large reasoning models. In Advances in Neural Information Processing Systems, 2025
work page 2025
-
[19]
Inference-time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Vi\' e gas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. In Advances in Neural Information Processing Systems, volume 36, pages 41451--41530, 2023
work page 2023
-
[20]
Generated knowledge prompting for commonsense reasoning
Jiacheng Liu, Alisa Liu, Ximing Lu, Sean Welleck, Peter West, Ronan Le Bras, Yejin Choi, and Hannaneh Hajishirzi. Generated knowledge prompting for commonsense reasoning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 3154--3169, Dublin, Ireland, May 2022. Association for Computational Linguistics
work page 2022
-
[21]
RLTF : Reinforcement learning from unit test feedback
Jiate Liu, Yiqin Zhu, Kaiwen Xiao, Qiang Fu, Xiao Han, Yang Wei, and Deheng Ye. RLTF : Reinforcement learning from unit test feedback. Transactions on Machine Learning Research, 2023. ISSN 2835-8856
work page 2023
-
[22]
ProRL : Prolonged reinforcement learning expands reasoning boundaries in large language models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. ProRL : Prolonged reinforcement learning expands reasoning boundaries in large language models. In Advances in Neural Information Processing Systems, volume 38, pages 17998--18031. Curran Associates, Inc., 2025
work page 2025
-
[23]
Improving parametric knowledge access in reasoning language models
Melody Ma and John Hewitt. Improving parametric knowledge access in reasoning language models. arXiv preprint arXiv:2602.22193, 2026
-
[24]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 9802--9822, Toronto, Canada, July 2023. Association for Co...
work page 2023
-
[25]
Teaching language models to support answers with verified quotes.Preprint arXiv:2203.11147,
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147, 2022
-
[26]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand \`e s, and Tatsunori Hashimoto. s1: Simple test-time scaling. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20275--20321, Suzhou, China, November 2025. Association for ...
work page 2025
-
[27]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. WebGPT : Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious. arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review arXiv 2024
-
[29]
LLM s know more than they show: On the intrinsic representation of LLM hallucinations
Hadas Orgad, Michael Toker, Zorik Gekhman, Roi Reichart, Idan Szpektor, Hadas Kotek, and Yonatan Belinkov. LLM s know more than they show: On the intrinsic representation of LLM hallucinations. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[30]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[31]
Qwen:, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, et al. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, volume 36, pages 53728--53741. Curran Associates, Inc., 2023
work page 2023
-
[33]
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Baochang Ren, Shuofei Qiao, Da Zheng, Huajun Chen, and Ningyu Zhang. Knowrl: Exploring knowledgeable reinforcement learning for factuality. arXiv preprint arXiv:2506.19807, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv: 1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279--1297, New York, NY, USA, 2025. Association for Computing Machinery
work page 2025
-
[37]
Logan IV, Eric Wallace, and Sameer Singh
Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. A uto P rompt: E liciting K nowledge from L anguage M odels with A utomatically G enerated P rompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4222--4235, Online, November 2020. Association for Computational Linguistics
work page 2020
-
[38]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[39]
Recitation-augmented language models
Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, and Denny Zhou. Recitation-augmented language models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[40]
R e FT : Reasoning with reinforced fine-tuning
Luong Trung, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. R e FT : Reasoning with reinforced fine-tuning. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 7601--7614, Bangkok, Thailand, August 2024. Association for Computational Linguistics
work page 2024
-
[41]
Retrieve what you need: A mutual learning framework for open-domain question answering
Dingmin Wang, Qiuyuan Huang, Matthew Jackson, and Jianfeng Gao. Retrieve what you need: A mutual learning framework for open-domain question answering. Transactions of the Association for Computational Linguistics, 12: 0 247--263, 2024
work page 2024
-
[42]
Enhancing code LLM s with reinforcement learning in code generation: A survey
Junqiao Wang, Zeng Zhang, Yangfan He, Zihao Zhang, Xinyuan Song, Yuyang Song, Tianyu Shi, Yuchen Li, Hengyuan Xu, Kunyu Wu, Yi Xin, Zhongwei Wan, Xinhang Yuan, Zijun Wang, Kuan Lu, Menghao Huo, Jingqun Tang, Guangwu Qian, Keqin Li, Qiuwu Chen, and Lewei He. Enhancing code LLM s with reinforcement learning in code generation: A survey. In ICLR 2026 Worksho...
work page 2026
-
[43]
R3: Reinforced ranker-reader for open-domain question answering
Shuohang Wang, Mo Yu, Xiaoxiao Guo, Zhiguo Wang, Tim Klinger, Wei Zhang, Shiyu Chang, Gerry Tesauro, Bowen Zhou, and Jing Jiang. R3: Reinforced ranker-reader for open-domain question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, pages 5981--5988, 2018
work page 2018
-
[44]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[45]
Reinforcement learning for reasoning in large language models with one training example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, Weizhu Chen, Shuohang Wang, Simon Du, and Yelong Shen. Reinforcement learning for reasoning in large language models with one training example. In Advances in Neural Information Processing Systems, volume 38, pages 122721--122764. Cur...
work page 2025
-
[46]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, volume 35, pages 24824--24837. Curran Associates, Inc., 2022
work page 2022
-
[47]
Measuring short-form factuality in large language models
Jason Wei, Nguyen Karina, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368, 2024
-
[48]
Truthrl: Incentivizing truthful llms via reinforcement learning
Zhepei Wei, Xiao Yang, Kai Sun, Jiaqi Wang, Rulin Shao, Sean Chen, Mohammad Kachuee, Teja Gollapudi, Tony Liao, Nicolas Scheffer, et al. Truthrl: Incentivizing truthful llms via reinforcement learning. arXiv preprint arXiv:2509.25760, 2025
-
[49]
Xumeng Wen, Zihan Liu, Shun Zheng, Shengyu Ye, Zhirong Wu, Yang Wang, Zhijian Xu, Xiao Liang, Junjie Li, Ziming Miao, Jiang Bian, and Mao Yang. Reinforcement learning with verifiable rewards implicitly incentivizes correct reasoning in base LLM s. In The Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[50]
C-pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-pack: Packed resources for general chinese embeddings. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 641--649, New York, NY, USA, 2024. Association for Computing Machinery
work page 2024
-
[51]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen3 technical report. arXiv preprint arXiv: 2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO : An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Zheng Yuan, Hongyi Yuan, Chengpeng Li, Guanting Dong, Keming Lu, Chuanqi Tan, Chang Zhou, and Jingren Zhou. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825, 2023
-
[54]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? In Advances in Neural Information Processing Systems, volume 38, pages 57654--57689. Curran Associates, Inc., 2025
work page 2025
-
[55]
Charlie Zhang, Graham Neubig, and Xiang Yue. On the interplay of pre-training, mid-training, and rl on reasoning language models. arXiv preprint arXiv:2512.07783, 2025
-
[56]
From system 1 to system 2: A survey of reasoning large language models
Duzhen Zhang, Zhong-Zhi Li, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhijiang Guo, Le Song, and Cheng-Lin Liu. From system 1 to system 2: A survey of reasoning large language models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 48 0 (3): 0 3335--...
work page 2026
-
[57]
L lama F actory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. L lama F actory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400--410, Bangkok, Thailand, August 2024. Association for Computational Linguistics
work page 2024
-
[58]
Factual probing is [ MASK ]: Learning vs
Zexuan Zhong, Dan Friedman, and Danqi Chen. Factual probing is [ MASK ]: Learning vs. learning to recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5017--5033, Online, June 2021. Association for Computational Linguistics
work page 2021
-
[59]
Fine-Tuning Language Models from Human Preferences
Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.