Recognition: 2 theorem links
· Lean TheoremCoupling Models for One-Step Discrete Generation
Pith reviewed 2026-05-11 02:54 UTC · model grok-4.3
The pith
Coupling Models generate discrete sequences in one step by learning to invert a data-noise pairing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
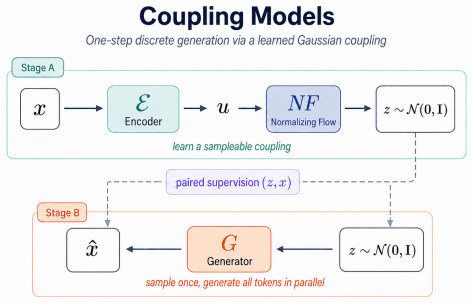
Coupling Models learn a direct coupling between discrete sequences and Gaussian latents. They train a purpose-built decoder to invert this coupling, enabling generation of samples in a single forward pass. The method sidesteps both complex continuous flows over the simplex and hand-specified data-to-noise couplings, achieving better performance than prior one-step baselines.
What carries the argument
The learned coupling between discrete data and Gaussian latents, which the decoder inverts in one step.
If this is right
- Effective one-step generation is possible for discrete structures without multi-step processes.
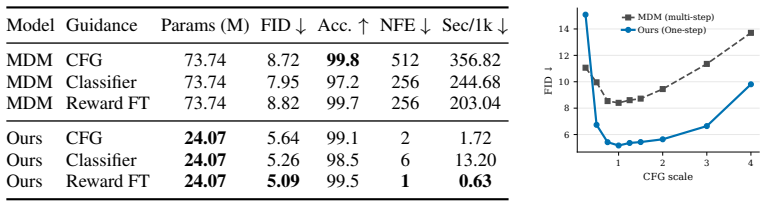
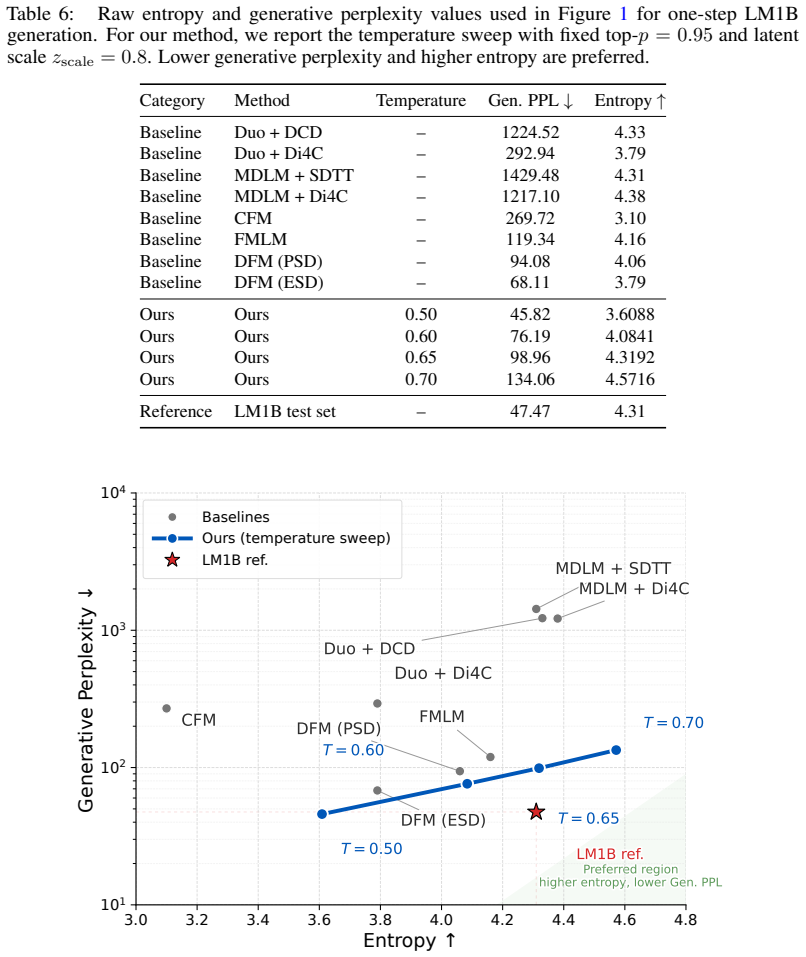
- Performance gains of up to 46% in FID for images, 33% lower perplexity for text, and 18% better FBD for enhancers.
- The approach applies across text, biology, and vision domains with the same core mechanism.
- Generation no longer requires hand-crafted couplings or continuous relaxations.
Where Pith is reading between the lines
- Scaling this coupling strategy could reduce inference time in large discrete models like language models.
- The learned couplings might provide insights into the geometry of discrete data distributions.
- Similar ideas could extend to other generative tasks involving structured discrete outputs.
Load-bearing premise
A purpose-built decoder can reliably invert the learned coupling in one step without needing additional refinement or complex transformations.
What would settle it
Observing that samples generated in one step from the decoder on the coupled latents are incoherent or low-quality on a new discrete domain would falsify the claim that the coupling enables reliable one-step generation.
Figures



read the original abstract
Generative modeling over discrete structures underpins applications across deep learning, from biological sequence design and code generation to large language models, yet generation often remains sequential, relying on autoregressive decoding or iterative refinement. In this work, we introduce Coupling Models(Coupling Models), a one-step discrete generative model that learns a direct coupling between discrete sequences and Gaussian latents. Unlike recent distillation methods that compress a pretrained multi-step sampler into a few steps, Coupling Model trains a purpose-built decoder to invert this coupling and generate samples in a single step. The model also avoids complex continuous flows over the simplex and hand-specified data-to-noise couplings. Empirically,Coupling Model improves the strongest one-step baselines in each domain: it reduces LM1B text-generation perplexity by 33% at its lowest-perplexity operating point, Fly Brain enhancer-design FBD by 18%, and MNIST-Binary FID by 46%. These results suggest that effective one-step discrete generation depends strongly on how data and noise are coupled before decoding. Code is available at https://github.com/pengzhangzhi/Coupling-Models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Coupling Models, a one-step discrete generative model that learns a direct coupling between discrete sequences and Gaussian latents. It trains a purpose-built decoder to invert this coupling for single-step sampling, avoiding complex continuous flows over the simplex and hand-specified data-to-noise couplings. Empirical results across domains report improvements over the strongest one-step baselines: 33% perplexity reduction on LM1B text generation at the lowest-perplexity point, 18% FBD reduction on Fly Brain enhancer design, and 46% FID reduction on MNIST-Binary. The work concludes that effective one-step discrete generation depends strongly on the coupling of data and noise before decoding, with code released at https://github.com/pengzhangzhi/Coupling-Models.
Significance. If the reported gains are robust and the interpretation attributing them to the learned coupling is supported, the approach could offer a simpler alternative to multi-step samplers or flow-based methods for discrete generation tasks in language modeling, biological sequence design, and image synthesis. The open availability of code is a positive factor for reproducibility and extension.
major comments (1)
- [Abstract] Abstract: The central interpretive claim that 'effective one-step discrete generation depends strongly on how data and noise are coupled before decoding' is not supported by direct evidence. No ablation experiments are described that isolate the learned coupling (e.g., by holding decoder architecture and training fixed while replacing the learned coupling with additive Gaussian noise on embeddings or a simple random permutation) or that compare against the hand-specified couplings the method claims to avoid. Without such controls, the gains cannot be causally attributed to the coupling rather than decoder capacity or other design choices.
minor comments (2)
- [Abstract] Abstract: The reported metric improvements (perplexity, FBD, FID) are presented without accompanying details on training procedure, hyperparameter selection, decoder architecture, or variance across runs, which limits assessment of whether the gains are robust.
- The manuscript would benefit from explicit statements of the exact functional form of the learned coupling and the inversion objective in the methods description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment regarding the interpretive claim in the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central interpretive claim that 'effective one-step discrete generation depends strongly on how data and noise are coupled before decoding' is not supported by direct evidence. No ablation experiments are described that isolate the learned coupling (e.g., by holding decoder architecture and training fixed while replacing the learned coupling with additive Gaussian noise on embeddings or a simple random permutation) or that compare against the hand-specified couplings the method claims to avoid. Without such controls, the gains cannot be causally attributed to the coupling rather than decoder capacity or other design choices.
Authors: We agree that the abstract's interpretive claim would be strengthened by direct ablations that isolate the effect of the learned coupling. The manuscript reports consistent improvements over the strongest one-step baselines across three domains, where those baselines employ different (often hand-specified or simpler) coupling strategies, but it does not include the precise controls of fixing the decoder while swapping only the coupling mechanism. In the revised manuscript we will add such ablation experiments: we will hold the decoder architecture, training objective, and optimization fixed while replacing the learned coupling with (i) additive Gaussian noise on embeddings and (ii) random permutations of the data-to-noise mapping. These results will be reported in a new subsection and the abstract will be updated to qualify the claim accordingly. revision: yes
Circularity Check
No circularity; empirical claims rest on reported experiments rather than self-referential definitions or fits.
full rationale
The paper introduces Coupling Models as a learned coupling between discrete data and Gaussian latents inverted by a trained decoder. Reported gains (perplexity, FBD, FID) are presented as direct empirical comparisons to baselines. No equations or claims reduce a 'prediction' to a fitted input by construction, no self-citation chain bears the central result, and the interpretive statement about coupling importance is an after-the-fact reading of the numbers rather than a tautology. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Learned coupling between discrete sequences and Gaussian latents
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearCoupling Model learns a direct coupling between discrete sequences and Gaussian latents... trains a purpose-built decoder to invert this coupling... effective one-step discrete generation depends strongly on how data and noise are coupled before decoding.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearStage A objective combines reconstruction, KL, and flow likelihood terms to produce paired (z, x) supervision aligned to N(0,I).
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year =
PairFlow: Closed-Form Source-Target Coupling for Few-Step Generation in Discrete Flow Models , author =. International Conference on Learning Representations (ICLR) , year =. doi:10.48550/arXiv.2512.20063 , url =. 2512.20063 , archivePrefix =
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , year =
ReDi: Rectified Discrete Flow , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2507.15897 , url =. 2507.15897 , archivePrefix =
-
[3]
The diffusion duality.arXiv preprint arXiv:2506.10892, 2025
The Diffusion Duality , author =. International Conference on Machine Learning (ICML) , year =. doi:10.48550/arXiv.2506.10892 , url =. 2506.10892 , archivePrefix =
-
[4]
Categorical flow maps.arXiv preprint arXiv:2602.12233, 2026
Categorical Flow Maps , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.12233 , url =
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Bidirectional Normalizing Flow: From Data to Noise and Back , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[6]
Discrete Flow Maps , author =. 2026 , eprint =. doi:10.48550/arXiv.2604.09784 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09784 2026
-
[7]
Simple guidance mechanisms for discrete diffusion models.arXiv preprint arXiv:2412.10193, 2024
Simple Guidance Mechanisms for Discrete Diffusion Models , author =. International Conference on Learning Representations (ICLR) , year =. doi:10.48550/arXiv.2412.10193 , url =. 2412.10193 , archivePrefix =
-
[8]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Categorical Flow Matching on Statistical Manifolds , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2405.16441 , url =. 2405.16441 , archivePrefix =
-
[9]
Dirichlet Flow Matching with Applications to
Dirichlet Flow Matching with Applications to DNA Sequence Design , author =. International Conference on Machine Learning (ICML) , year =. doi:10.48550/arXiv.2402.05841 , url =. 2402.05841 , archivePrefix =
-
[10]
ShortListing Model: A Streamlined Simplex Diffusion for Discrete Variable Generation , author =. 2025 , eprint =. doi:10.48550/arXiv.2508.17345 , url =
-
[11]
Fisher Flow Matching for Generative Modeling over Discrete Data , author =. 2024 , eprint =. doi:10.48550/arXiv.2405.14664 , url =
-
[12]
Candi: Hybrid discrete-continuous diffusion models, 2025
CANDI: Hybrid Discrete-Continuous Diffusion Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.22510 , url =
-
[13]
Flow Map Language Models: One-step Language Modeling via Continuous Denoising
One-step Language Modeling via Continuous Denoising , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.16813 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.16813 2026
-
[14]
Attention Is All You Need , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.1706.03762 , url =. 1706.03762 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.03762
-
[15]
Language Models are Few-Shot Learners
Language Models are Few-Shot Learners , author =. 2020 , eprint =. doi:10.48550/arXiv.2005.14165 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2005.14165 2020
-
[16]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open Foundation and Fine-Tuned Chat Models , author =. 2023 , eprint =. doi:10.48550/arXiv.2307.09288 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[17]
Qwen2 Technical Report , author =. 2024 , eprint =. doi:10.48550/arXiv.2407.10671 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.10671 2024
-
[18]
Large Language Diffusion Models
Large Language Diffusion Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2502.09992 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992 2025
-
[19]
Advances in Neural Information Processing Systems , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , year =
-
[20]
Robust Deep Learning-Based Protein Sequence Design Using ProteinMPNN , author =. Science , volume =. 2022 , doi =
work page 2022
-
[21]
Path Planning for Masked Diffusion Model Sampling , author =. 2025 , eprint =. doi:10.48550/arXiv.2502.03540 , url =
-
[22]
Planner Aware Path Learning in Diffusion Language Models Training , author =. 2025 , eprint =. doi:10.48550/arXiv.2509.23405 , url =
-
[23]
Z., Zhang, Y ., Pan, J., and Chrysos, G
Corrective Diffusion Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2512.15596 , url =
-
[24]
Steering Masked Discrete Diffusion Models via Discrete Denoising Posterior Prediction , author =. 2024 , eprint =. doi:10.48550/arXiv.2410.08134 , url =
-
[25]
EvoFlow-RNA: Generating and Representing non-coding RNA with a Language Model , author =. 2025 , doi =
work page 2025
-
[26]
Proceedings of the 40th International Conference on Machine Learning (ICML) , year =
Dirichlet Diffusion Score Model for Biological Sequence Generation , author =. Proceedings of the 40th International Conference on Machine Learning (ICML) , year =. doi:10.48550/arXiv.2305.10699 , url =. 2305.10699 , archivePrefix =
-
[27]
Structured denoising diffusion models in discrete state-spaces
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. doi:10.48550/arXiv.2107.03006 , url =. 2107.03006 , archivePrefix =
-
[28]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Discrete Flow Matching , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[29]
Advances in Neural Information Processing Systems , year =
Diffusion Models Beat GANs on Image Synthesis , author =. Advances in Neural Information Processing Systems , year =
-
[30]
Classifier-Free Diffusion Guidance
Classifier-Free Diffusion Guidance , author =. arXiv preprint arXiv:2207.12598 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Advances in Neural Information Processing Systems , year =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[32]
International Conference on Learning Representations , year =
Simple Guidance Mechanisms for Discrete Diffusion Models , author =. International Conference on Learning Representations , year =
-
[33]
International Conference on Learning Representations , year =
Unlocking Guidance for Discrete State-Space Diffusion and Flow Models , author =. International Conference on Learning Representations , year =
-
[34]
International Conference on Learning Representations , year =
Fine-Tuning Discrete Diffusion Models via Reward Optimization with Applications to DNA and Protein Design , author =. International Conference on Learning Representations , year =
-
[35]
International Conference on Learning Representations , year =
Categorical Reparameterization with Gumbel-Softmax , author =. International Conference on Learning Representations , year =
-
[36]
International Conference on Learning Representations , year =
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables , author =. International Conference on Learning Representations , year =
-
[37]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. Proceedings of the 41st International Conference on Machine Learning , year =. doi:10.48550/arXiv.2310.16834 , url =. 2310.16834 , archivePrefix =
work page internal anchor Pith review doi:10.48550/arxiv.2310.16834
-
[38]
A reparameterized discrete diffusion model for text generation.arXiv preprint arXiv:2302.05737,
A Reparameterized Discrete Diffusion Model for Text Generation , author =. First Conference on Language Modeling , year =. doi:10.48550/arXiv.2302.05737 , url =. 2302.05737 , archivePrefix =
-
[39]
Scaling up masked diffusion models on text.arXiv preprint arXiv:2410.18514, 2024
Scaling up Masked Diffusion Models on Text , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2410.18514 , url =. 2410.18514 , archivePrefix =
-
[40]
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2410.17891 , url =. 2410.17891 , archivePrefix =
-
[41]
Deschenaux, Justin and Gulcehre, Caglar , booktitle =. Beyond Autoregression: Fast. 2025 , eprint =. doi:10.48550/arXiv.2410.21035 , url =
-
[42]
Dlm-one: Diffusion language models for one-step sequence generation
Chen, Tianqi and Zhang, Shujian and Zhou, Mingyuan , year =. doi:10.48550/arXiv.2506.00290 , url =. 2506.00290 , archivePrefix =
-
[43]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Zhu, Yuanzhi and Wang, Xi and Lathuili. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =. doi:10.48550/arXiv.2503.15457 , url =. 2503.15457 , archivePrefix =
-
[44]
FS-DFM: Fast and Accurate Long Text Generation with Few-Step Diffusion Language Models
Monsefi, Amin Karimi and Bhendawade, Nikhil and Ciosici, Manuel Rafael and Culver, Dominic and Zhang, Yizhe and Belousova, Irina , year =. doi:10.48550/arXiv.2509.20624 , url =. 2509.20624 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.20624
-
[45]
International Conference on Learning Representations , year =
Ultra-Fast Language Generation via Discrete Diffusion Divergence Instruct , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2509.25035 , url =. 2509.25035 , archivePrefix =
-
[46]
Zhang, Tunyu and Zhang, Xinxi and Han, Ligong and Shi, Haizhou and He, Xiaoxiao and Li, Zhuowei and Wang, Hao and Xu, Kai and Srivastava, Akash and Wang, Hao and Pavlovic, Vladimir and Metaxas, Dimitris N. , year =. doi:10.48550/arXiv.2602.12262 , url =. 2602.12262 , archivePrefix =
-
[47]
International Conference on Learning Representations , year =
Forward-Learned Discrete Diffusion: Learning how to noise to denoise faster , author =. International Conference on Learning Representations , year =
-
[48]
Gong, Shansan and Li, Mukai and Feng, Jiangtao and Wu, Zhiyong and Kong, Lingpeng , booktitle =. 2023 , eprint =. doi:10.48550/arXiv.2210.08933 , url =
-
[49]
Gong, Shansan and Li, Mukai and Feng, Jiangtao and Wu, Zhiyong and Kong, Lingpeng , booktitle =. 2023 , pages =. doi:10.18653/v1/2023.findings-emnlp.660 , eprint =
-
[50]
Diffusion-lm improves controllable text generation
Li, Xiang Lisa and Thickstun, John and Gulrajani, Ishaan and Liang, Percy and Hashimoto, Tatsunori B. , booktitle =. Diffusion-. 2022 , eprint =. doi:10.48550/arXiv.2205.14217 , url =
-
[51]
Han, Xiaochuang and Kumar, Sachin and Tsvetkov, Yulia , booktitle =. 2023 , pages =. doi:10.18653/v1/2023.acl-long.647 , eprint =
-
[52]
Advances in Neural Information Processing Systems , year =
Latent Diffusion for Language Generation , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2212.09462 , url =. 2212.09462 , archivePrefix =
-
[53]
doi:10.48550/arXiv.2305.04044 , url =
Zhou, Kun and Li, Yifan and Zhao, Wayne Xin and Wen, Ji-Rong , year =. doi:10.48550/arXiv.2305.04044 , url =. 2305.04044 , archivePrefix =
-
[54]
Argmax flows and multinomial diffusion: Learning categorical distributions, 2021
Argmax Flows and Multinomial Diffusion: Learning Categorical Distributions , author =. Advances in Neural Information Processing Systems , year =. doi:10.48550/arXiv.2102.05379 , url =. 2102.05379 , archivePrefix =
-
[55]
Autoregressive diffusion models.arXiv preprint arXiv:2110.02037, 2021
Autoregressive Diffusion Models , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2110.02037 , url =. 2110.02037 , archivePrefix =
-
[56]
Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning , author =. 2022 , eprint =. doi:10.48550/arXiv.2208.04202 , url =
-
[57]
Vector quantized diffusion model for text-to-image synthesis
Vector Quantized Diffusion Model for Text-to-Image Synthesis , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =. doi:10.48550/arXiv.2111.14822 , url =. 2111.14822 , archivePrefix =
-
[58]
MaskGIT: Masked Generative Image Transformer,
Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T. , booktitle =. 2022 , eprint =. doi:10.48550/arXiv.2202.04200 , url =
-
[59]
Muse: Text-to-image generation via masked generative transformers
Muse: Text-To-Image Generation via Masked Generative Transformers , author =. Proceedings of the 40th International Conference on Machine Learning , year =. doi:10.48550/arXiv.2301.00704 , url =. 2301.00704 , archivePrefix =
-
[60]
Hu, Vincent Tao and Ommer, Bj. [. 2024 , eprint =. doi:10.48550/arXiv.2412.06787 , url =
-
[61]
International Conference on Learning Representations , year =
Non-Autoregressive Neural Machine Translation , author =. International Conference on Learning Representations , year =
-
[62]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =
Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year =. doi:10.18653/v1/D18-1149 , url =
-
[63]
Mask-Predict: Parallel Decoding of Conditional Masked Language Models , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , year =. doi:10.18653/v1/D19-1633 , url =
-
[64]
Proceedings of the 36th International Conference on Machine Learning , year =
Insertion Transformer: Flexible Sequence Generation via Insertion Operations , author =. Proceedings of the 36th International Conference on Machine Learning , year =
-
[65]
Diffusion language models are versatile protein learners.arXiv preprint arXiv:2402.18567, 2024
Diffusion Language Models Are Versatile Protein Learners , author =. International Conference on Machine Learning , year =. doi:10.48550/arXiv.2402.18567 , url =. 2402.18567 , archivePrefix =
-
[66]
Dplm-2: A multimodal diffusion protein language model.arXiv preprint arXiv:2410.13782, 2024
Wang, Xinyou and Zheng, Zaixiang and Ye, Fei and Xue, Dongyu and Huang, Shujian and Gu, Quanquan , booktitle =. 2025 , eprint =. doi:10.48550/arXiv.2410.13782 , url =
-
[67]
arXiv preprint arXiv:1810.09136 , year=
Do deep generative models know what they don't know? , author=. arXiv preprint arXiv:1810.09136 , year=
-
[68]
A note on the evaluation of generative models, 2016
A note on the evaluation of generative models , author=. arXiv preprint arXiv:1511.01844 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.