Recognition: no theorem link
MLAIRE: Multilingual Language-Aware Information Retrieval Evaluation Protocal
Pith reviewed 2026-05-11 02:29 UTC · model grok-4.3
The pith
MLAIRE disentangles semantic relevance from query-language preference in multilingual retrieval using parallel passages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
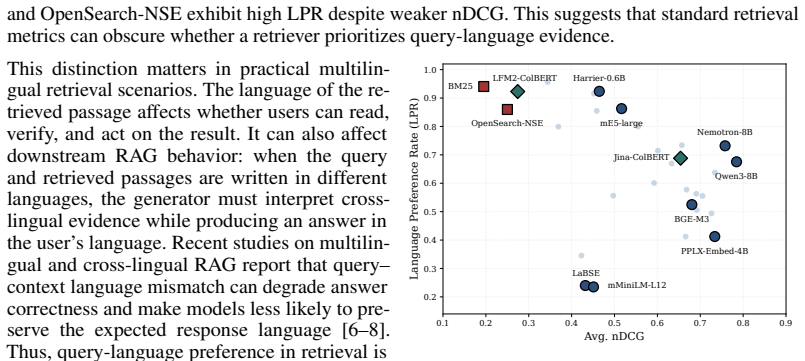
MLAIRE constructs controlled pools with parallel passages across languages, enabling measurement of semantic retrieval accuracy and query-language preference when equivalent translations are available. It proposes language-aware metrics, including Language Preference Rate (LPR) and Lang-nDCG, together with a 4-way decomposition separating semantic and query-language preference failures. Evaluating 31 dense, sparse, and late-interaction retrievers, we show that standard metrics obscure distinct behaviors: semantically strong retrievers may return correct content in a non-query language, while retrievers with stronger query-language preference may retrieve less semantically relevant passages.
What carries the argument
The MLAIRE protocol, which builds controlled pools of parallel passages to separately quantify semantic correctness and query-language preference.
If this is right
- Retriever rankings by conventional metrics can shift once language preference is measured separately.
- Semantically strong models may systematically underperform on query-language output, requiring targeted tuning.
- The four-way decomposition identifies specific failure types that can guide model improvements.
- Language-aware metrics such as LPR and Lang-nDCG provide finer-grained signals for system selection in multilingual settings.
Where Pith is reading between the lines
- In retrieval-augmented generation, higher query-language preference could reduce errors during answer verification even if semantic scores stay the same.
- The protocol could be adapted to measure preference for particular scripts or regional variants within a single language.
- Real-world deployment might require combining MLAIRE-style controlled tests with live user feedback to validate the metrics.
Load-bearing premise
The protocol assumes that parallel passages across languages are semantically equivalent and that controlled pools built from them are feasible to construct and representative of real-world multilingual corpora.
What would settle it
A study showing that retriever rankings by Lang-nDCG on parallel pools fail to predict which models deliver better user utility or lower verification errors when tested on actual mixed-language web corpora without guaranteed translations.
Figures



read the original abstract
Multilingual Information Retrieval is increasingly important in real-world search settings, where users issue queries over mixed-language corpora. Existing evaluations mainly reward language-agnostic semantic relevance, treating relevant passages equally regardless of language. Yet retrieval utility also depends on the language of the retrieved passages: users may prefer results they can read and verify in the query language, and query--passage language mismatch can complicate downstream grounding and answer verification in Retrieval-Augmented Generation systems. To evaluate this language-aware dimension, we introduce MLAIRE, a Multilingual Language-Aware Information Retrieval Evaluation protocol that disentangles cross-lingual semantic retrieval from query-language preference. MLAIRE constructs controlled pools with parallel passages across languages, enabling measurement of semantic retrieval accuracy and query-language preference when equivalent translations are available. We propose language-aware metrics, including Language Preference Rate (LPR) and Lang-nDCG, together with a 4-way decomposition separating semantic and query-language preference failures. Evaluating 31 dense, sparse, and late-interaction retrievers, we show that standard metrics obscure distinct behaviors: semantically strong retrievers may return correct content in a non-query language, while retrievers with stronger query-language preference may retrieve less semantically relevant passages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MLAIRE, a Multilingual Language-Aware Information Retrieval Evaluation protocol that uses controlled pools of parallel passages to disentangle cross-lingual semantic retrieval from query-language preference. It proposes new metrics (Language Preference Rate (LPR) and Lang-nDCG) and a 4-way failure decomposition. Experiments evaluating 31 dense, sparse, and late-interaction retrievers show that standard metrics obscure distinct model behaviors, with some semantically strong retrievers returning correct content in non-query languages while others exhibit stronger query-language preference.
Significance. If the results hold, this work is significant because it addresses a practical gap in multilingual IR evaluation: standard metrics treat relevance as language-agnostic, yet language match affects user utility and downstream tasks like answer verification in RAG. The evaluation of 31 retrievers across model types provides a broad empirical basis for the claimed distinctions, and the protocol offers a concrete way to measure language-aware aspects that existing benchmarks overlook.
major comments (2)
- [§3] §3 (protocol description): The 4-way decomposition separating semantic retrieval failures from query-language preference failures is load-bearing for the central claim that standard metrics obscure distinct behaviors. This decomposition assumes parallel passages are semantically equivalent, yet the manuscript provides no validation step (e.g., human equivalence judgments, semantic similarity thresholds, or inter-annotator agreement) to confirm that translations preserve meaning without systematic drift or artifacts.
- [§5] §5 (experiments): The reported behaviors for the 31 retrievers depend on the controlled pools being representative and correctly constructed. Insufficient detail is given on pool construction (languages covered, sourcing of parallels, pool sizes, or filtering criteria), which prevents assessing whether the observed separation of semantic strength from language preference generalizes or is an artifact of the specific data.
minor comments (2)
- [Title] Title: 'Protocal' is a typo and should read 'Protocol'.
- [Metrics] Metrics definitions: The formulas for LPR and Lang-nDCG should be stated explicitly with all variables defined, ideally in a dedicated subsection or appendix, to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below and will revise the manuscript to incorporate additional details and clarifications where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (protocol description): The 4-way decomposition separating semantic retrieval failures from query-language preference failures is load-bearing for the central claim that standard metrics obscure distinct behaviors. This decomposition assumes parallel passages are semantically equivalent, yet the manuscript provides no validation step (e.g., human equivalence judgments, semantic similarity thresholds, or inter-annotator agreement) to confirm that translations preserve meaning without systematic drift or artifacts.
Authors: We agree that validating the semantic equivalence of parallel passages is essential to support the 4-way decomposition. The protocol in the manuscript draws on established parallel corpora (e.g., from the OPUS collection) whose translations are produced under professional standards, but we did not describe any explicit validation procedure. In the revised version we will add a subsection that specifies the corpora used, reports semantic similarity scores obtained from a multilingual embedding model between each parallel pair, and states the inclusion thresholds applied. We will also note the lack of human equivalence judgments as a limitation of the current evaluation. revision: yes
-
Referee: [§5] §5 (experiments): The reported behaviors for the 31 retrievers depend on the controlled pools being representative and correctly constructed. Insufficient detail is given on pool construction (languages covered, sourcing of parallels, pool sizes, or filtering criteria), which prevents assessing whether the observed separation of semantic strength from language preference generalizes or is an artifact of the specific data.
Authors: We accept that greater transparency on pool construction is required for readers to assess generalizability. Although the protocol description outlines the overall design, the experimental section omitted concrete implementation details. In the revision we will expand §5 to list the languages covered, the precise sources of the parallel passages, the sizes of the controlled pools, and the filtering criteria (length, quality, and deduplication steps) used to assemble them. revision: yes
Circularity Check
No circularity: MLAIRE metrics and protocol are direct constructions from new evaluation setup
full rationale
The paper introduces MLAIRE as a new protocol that constructs controlled pools of parallel passages to define language-aware metrics (LPR, Lang-nDCG) and a 4-way failure decomposition. These quantities are defined explicitly from the controlled pool construction and retrieval outcomes rather than being fitted to data or reduced to prior self-citations. The empirical claims about retriever behaviors emerge from evaluating 31 models on this setup and do not loop back to the inputs by construction. No self-definitional, fitted-prediction, or self-citation load-bearing patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel passages across languages are semantically equivalent
Reference graph
Works this paper leans on
-
[1]
A multilingual approach to multilingual information retrieval
Jian-Yun Nie and Fuman Jin. A multilingual approach to multilingual information retrieval. In Workshop of the Cross-Language Evaluation F orum for European Languages, pages 101–110. Springer, 2002
work page 2002
-
[2]
Carol Peters, Martin Braschler, and Paul Clough.Multilingual information retrieval: From research to practice. Springer, 2012
work page 2012
-
[3]
Eugene Yang, Dawn Lawrie, and James Mayfield. Distillation for multilingual information retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, page 2368–2373. ACM, 2024. doi: 10.1145/3626772.3657955. URLhttp://dx.doi.org/10.1145/3626772.3657955
-
[4]
Language fairness in multilingual information retrieval
Eugene Yang, Thomas Jänich, James Mayfield, and Dawn Lawrie. Language fairness in multilingual information retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2487–2491, 2024
work page 2024
-
[5]
Jinrui Yang, Fan Jiang, and Timothy Baldwin. Language bias in information retrieval: The nature of the beast and mitigation methods.arXiv preprint arXiv:2509.06195, 2025
-
[6]
Investigating language preference of multilingual rag systems
Jeonghyun Park and Hwanhee Lee. Investigating language preference of multilingual rag systems. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5647–5675, 2025
work page 2025
- [7]
-
[8]
Dayeon Ki, Marine Carpuat, Paul McNamee, Daniel Khashabi, Eugene Yang, Dawn Lawrie, and Kevin Duh. Linguistic nepotism: Trading-off quality for language preference in multilingual rag.arXiv preprint arXiv:2509.13930, 2025
-
[9]
Lareqa: Language-agnostic answer retrieval from a multilingual pool
Uma Roy, Noah Constant, Rami Al-Rfou, Aditya Barua, Aaron Phillips, and Yinfei Yang. Lareqa: Language-agnostic answer retrieval from a multilingual pool. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 5919–5930, 2020
work page 2020
-
[10]
Martin Braschler. Clef 2002—overview of results. InWorkshop of the Cross-Language Evaluation F orum for European Languages, pages 9–27. Springer, 2002
work page 2002
-
[11]
Dawn Lawrie, James Mayfield, Eugene Yang, Andrew Yates, Sean MacAvaney, Ronak Pradeep, Scott Miller, Paul McNamee, and Luca Soldani. Neuclirbench: A modern evaluation collec- tion for monolingual, cross-language, and multilingual information retrieval.arXiv preprint arXiv:2511.14758, 2025
-
[12]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. Beir: A heterogenous benchmark for zero-shot evaluation of information retrieval models, 2021. URL https://arxiv.org/abs/2104.08663
work page internal anchor Pith review arXiv 2021
-
[13]
Mteb: Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014–2037, 2023
work page 2014
-
[14]
Monolingual and cross-lingual information retrieval models based on (bilingual) word embeddings
Ivan Vuli´c and Marie-Francine Moens. Monolingual and cross-lingual information retrieval models based on (bilingual) word embeddings. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, pages 363–372, 2015
work page 2015
-
[15]
CLEAR: Cross-Lingual Enhancement in Alignment via Reverse-training
Seungyoon Lee, Minhyuk Kim, Seongtae Hong, Youngjoon Jang, Dongsuk Oh, and Heuiseok Lim. Clear: Cross-lingual enhancement in alignment via reverse-training.arXiv preprint arXiv:2604.05821, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Mmteb: Massive multilingual text embedding bench- mark.arXiv preprint arXiv:2502.13595,
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi ´nski, Genta Indra Winata, et al. Mmteb: Massive multilingual text embedding benchmark.arXiv preprint arXiv:2502.13595, 2025. 10
-
[17]
Improving Semantic Proximity in Information Retrieval through Cross-Lingual Alignment
Seongtae Hong, Youngjoon Jang, Jungseob Lee, Hyeonseok Moon, and Heuiseok Lim. Improv- ing semantic proximity in information retrieval through cross-lingual alignment.arXiv preprint arXiv:2604.05684, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Infoxlm: An information-theoretic framework for cross-lingual language model pre-training
Zewen Chi, Li Dong, Furu Wei, Nan Yang, Saksham Singhal, Wenhui Wang, Xia Song, Xian- Ling Mao, He-Yan Huang, and Ming Zhou. Infoxlm: An information-theoretic framework for cross-lingual language model pre-training. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technolog...
work page 2021
-
[19]
Language- agnostic bert sentence embedding
Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. Language- agnostic bert sentence embedding. InProceedings of the 60th annual meeting of the association for computational linguistics (volume 1: Long papers), pages 878–891, 2022
work page 2022
-
[20]
Michael Buckland and Fredric Gey. The relationship between recall and precision.Journal of the American society for information science, 45(1):12–19, 1994
work page 1994
-
[21]
Hamed Valizadegan, Rong Jin, Ruofei Zhang, and Jianchang Mao. Learning to rank by optimizing ndcg measure.Advances in neural information processing systems, 22, 2009
work page 2009
-
[22]
Consumers prefer their own language, 2020
CSA Research. Consumers prefer their own language, 2020. URL https://csa-research. com/l/media/Consumers-Prefer-their-Own-Language. Accessed: 2026-04-12
work page 2020
-
[23]
Punam Singh, Carly Wight, Olcan Sercinoglu, David Wilson, Artem Boytsov, and Manish Raizada. Language preferences on websites and in google searches for human health and food information.Journal of medical Internet research, 9(2):e625, 2007
work page 2007
-
[24]
Chenjun Ling, Ben Steichen, and Alexander G. Choulos. A comparative user study of interactive multilingual search interfaces. InProceedings of the 2018 Conference on Human Information Interaction & Retrieval, CHIIR ’18, page 211–220, New York, NY , USA, 2018. Association for Computing Machinery. ISBN 9781450349253. doi: 10.1145/3176349.3176383. URL https:...
-
[25]
Ben Steichen and Ryan Lowe. How do multilingual users search? an investigation of query and result list language choices.Journal of the Association for Information Science and Technology, 72(6):759–776, 2021. doi: https://doi.org/10.1002/asi.24443. URL https:// asistdl.onlinelibrary.wiley.com/doi/abs/10.1002/asi.24443
-
[26]
How google search handles multilingual searches, September 2023
Sunny Nahar, Ali Tawfiq, and Danny Sullivan. How google search handles multilingual searches, September 2023. URL https://developers.google.com/search/blog/2023/ 09/multilingual-searches
work page 2023
-
[27]
On the cross-lingual transferability of monolingual representations
Mikel Artetxe, Sebastian Ruder, and Dani Yogatama. On the cross-lingual transferability of monolingual representations. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4623–4637, 2020
work page 2020
-
[28]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
The belebele benchmark: a parallel reading comprehension dataset in 122 language variants
Lucas Bandarkar, Davis Liang, Benjamin Muller, Mikel Artetxe, Satya Narayan Shukla, Donald Husa, Naman Goyal, Abhinandan Krishnan, Luke Zettlemoyer, and Madian Khabsa. The belebele benchmark: a parallel reading comprehension dataset in 122 language variants. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olum...
work page 2024
-
[30]
No Language Left Behind: Scaling Human-Centered Machine Translation
Marta R Costa-Jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, et al. No language left behind: Scaling human-centered machine translation.arXiv preprint arXiv:2207.04672, 2022. 11
work page internal anchor Pith review arXiv 2022
-
[31]
Mlqa: Evaluating cross-lingual extractive question answering
Patrick Lewis, Barlas Oguz, Ruty Rinott, Sebastian Riedel, and Holger Schwenk. Mlqa: Evaluating cross-lingual extractive question answering. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 7315–7330, 2020
work page 2020
-
[32]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self- knowledge distillation.arXiv preprint arXiv:2402.03216, 4(5), 2024
work page internal anchor Pith review arXiv 2024
-
[34]
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, et al. mgte: Generalized long-context text representation and reranking models for multilingual text retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1393–1412, 2024
work page 2024
-
[35]
Arctic-embed 2.0: Multilingual retrieval without compromise.arXiv preprint arXiv:2412.04506, 2024
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. Arctic-embed 2.0: Multilingual retrieval without compromise.arXiv preprint arXiv:2412.04506, 2024
-
[36]
Zach Nussbaum, John X Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder.arXiv preprint arXiv:2402.01613, 2024
-
[37]
arXiv preprint arXiv:2509.20354 (2025) 6
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, et al. Embeddinggemma: Powerful and lightweight text representations.arXiv preprint arXiv:2509.20354, 2025
-
[38]
jina- embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173, 2024
Saba Sturua, Isabelle Mohr, Mohammad Kalim Akram, Michael Günther, Bo Wang, Markus Krimmel, Feng Wang, Georgios Mastrapas, Andreas Koukounas, Nan Wang, et al. jina- embeddings-v3: Multilingual embeddings with task lora.arXiv preprint arXiv:2409.10173, 2024
-
[39]
jina-embeddings-v5-text: Task-Targeted Embedding Distillation
Mohammad Kalim Akram, Saba Sturua, Nastia Havriushenko, Quentin Herreros, Michael Günther, Maximilian Werk, and Han Xiao. jina-embeddings-v5-text: Task-targeted embedding distillation.arXiv preprint arXiv:2602.15547, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
NV-Retriever: Improving text embedding models with effective hard-negative mining
Gabriel de Souza P Moreira, Radek Osmulski, Mengyao Xu, Ronay Ak, Benedikt Schifferer, and Even Oldridge. Nv-retriever: Improving text embedding models with effective hard-negative mining.arXiv preprint arXiv:2407.15831, 2024
-
[42]
Diffusion-pretrained dense and contextual embeddings.arXiv preprint arXiv:2602.11151, 2026
Sedigheh Eslami, Maksim Gaiduk, Markus Krimmel, Louis Milliken, Bo Wang, and Denis Bykov. Diffusion-pretrained dense and contextual embeddings.arXiv preprint arXiv:2602.11151, 2026
-
[43]
Un- supervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Un- supervised cross-lingual representation learning at scale. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 8440–8451, 2020
work page 2020
-
[44]
Andrzej Białecki, Robert Muir, Grant Ingersoll, and Lucid Imagination. Apache Lucene 4. In SIGIR 2012 Workshop on Open Source Information Retrieval, page 17. sn, 2012
work page 2012
-
[45]
Towards competitive search relevance for inference-free learned sparse retrievers, 2025
Zhichao Geng, Yiwen Wang, Dongyu Ru, and Yang Yang. Towards competitive search relevance for inference-free learned sparse retrievers, 2025. URL https://arxiv.org/abs/2411. 04403
work page 2025
-
[46]
Jina-ColBERT-v2: A general-purpose multilingual late interaction retriever
Rohan Jha, Bo Wang, Michael Günther, Georgios Mastrapas, Saba Sturua, Isabelle Mohr, Andreas Koukounas, Mohammad Kalim Wang, Nan Wang, and Han Xiao. Jina-ColBERT-v2: A general-purpose multilingual late interaction retriever. In Jonne Sälevä and Abraham Owodunni, editors,Proceedings of the F ourth Workshop on Multilingual Representation Learning (MRL 12 20...
-
[47]
Lfm2 technical report.arXiv preprint arXiv:2511.23404, 2025
Alexander Amini, Anna Banaszak, Harold Benoit, Arthur Böök, Tarek Dakhran, Song Duong, Alfred Eng, Fernando Fernandes, Marc Härkönen, Anne Harrington, et al. Lfm2 technical report.arXiv preprint arXiv:2511.23404, 2025
-
[48]
Colbert: Efficient and effective passage search via contextual- ized late interaction over bert
Omar Khattab and Matei Zaharia. Colbert: Efficient and effective passage search via contextual- ized late interaction over bert. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pages 39–48, 2020
work page 2020
-
[49]
Plaid: an efficient engine for late interaction retrieval
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. Plaid: an efficient engine for late interaction retrieval. InProceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 1747–1756, 2022
work page 2022
-
[50]
Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. Llama-embed-nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks, 2025. URLhttps://arxiv.org/abs/2511. 07025
work page 2025
-
[51]
David Ifeoluwa Adelani, Hannah Liu, Xiaoyu Shen, Nikita Vassilyev, Jesujoba Alabi, Yanke Mao, Haonan Gao, and En-Shiun Annie Lee. Sib-200: A simple, inclusive, and big evaluation dataset for topic classification in 200+ languages and dialects. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (V ...
-
[52]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.