Recognition: no theorem link
Structured Role-Aware Policy Optimization for Multimodal Reasoning
Pith reviewed 2026-05-11 01:20 UTC · model grok-4.3
The pith
SRPO refines group relative policy optimization by giving perception and reasoning tokens separate advantages derived from self-distilled contrasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
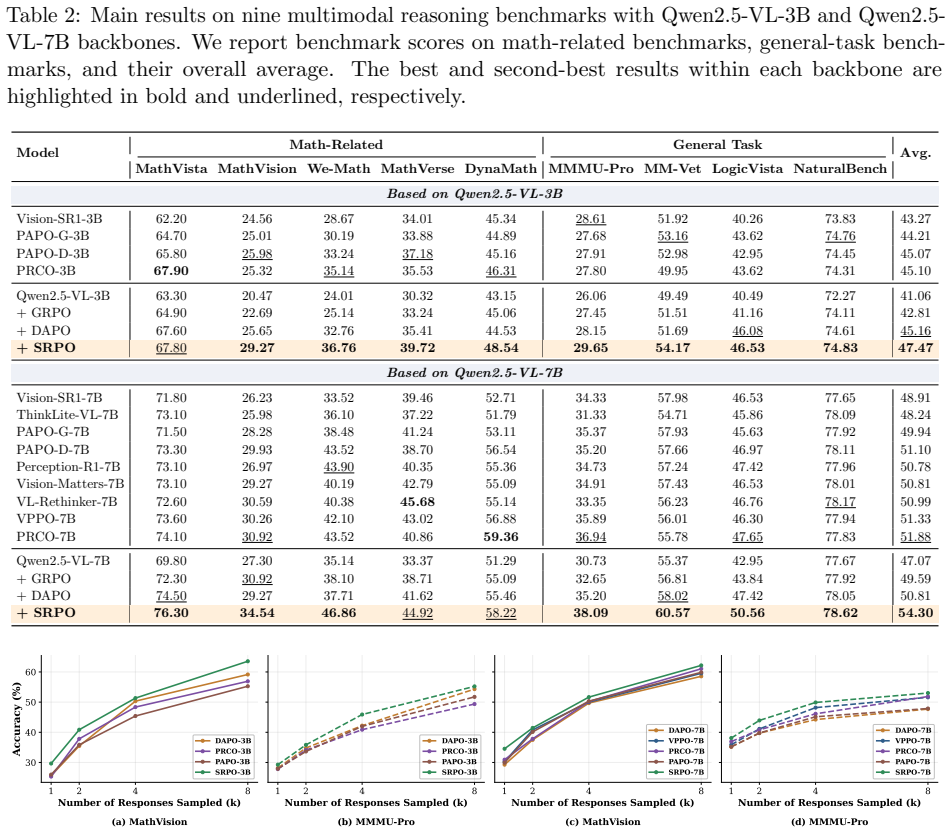
The paper claims that SRPO refines the sequence-level GRPO advantage into role-aware token-level advantages by employing self-distilled on-policy contrasts: perception tokens receive emphasis based on their dependency on original versus corrupted visual inputs, while reasoning tokens are weighted by their consistency with the generated perception. These signals are combined through a shared trajectory-level baseline to produce positive token weights that modulate update magnitudes without altering the GRPO reward or direction, and without needing external models.
What carries the argument
Role-aware token-level advantages computed from self-distilled on-policy contrasts on visual dependency for perception tokens and consistency for reasoning tokens, unified by a shared trajectory-level baseline.
If this is right
- SRPO improves evidence-grounded reasoning across diverse multimodal reasoning benchmarks.
- The method preserves the original GRPO reward function and optimization direction.
- Positive token weights adjust relative update magnitudes while requiring no external reward models or separate teachers.
- Moving beyond uniform sequence-level credit assignment supports more reliable multimodal reasoning.
Where Pith is reading between the lines
- The same contrast-based role separation could apply to other sequential reasoning domains where tokens serve distinct functional purposes.
- Self-distillation may allow credit assignment to scale without manual role annotations or additional supervision.
- Evaluating the method on tasks with ambiguous boundaries between perception and reasoning would test how far the decomposition assumption holds.
Load-bearing premise
Responses can be cleanly decomposed into perception and reasoning tokens whose functional roles are accurately captured by self-distilled contrasts on visual dependency and consistency without introducing bias.
What would settle it
An experiment in which perception-token weights do not rise when visual features are demonstrably required for the correct answer, or where SRPO shows no gain over GRPO on metrics that measure use of visual evidence.
Figures












read the original abstract
Reinforcement learning from verifiable rewards (RLVR), especially with Group Relative Policy Optimization (GRPO), has shown strong potential for improving the reasoning capabilities of large vision-language models (LVLMs). However, in multimodal reasoning, final-answer rewards are typically assigned at the sequence level and do not distinguish the functional roles of different tokens, making it difficult to determine whether a correct answer is supported by task-relevant visual evidence. In this paper, we revisit multimodal RLVR from the perspective of role-aware token-level credit assignment, where structured responses are decomposed into perception tokens for extracting visual evidence and reasoning tokens for deriving answers from that evidence. Based on this perspective, we propose Structured Role-aware Policy Optimization (SRPO), which refines the sequence-level GRPO advantage into role-aware token-level advantages without changing the reward function. Specifically, SRPO assigns role-specific credit by using self-distilled on-policy contrasts: perception tokens are emphasized according to their visual dependency under original versus corrupted visual inputs, while reasoning tokens are emphasized according to their consistency with the generated perception. These role-specific signals are further unified through a shared trajectory-level baseline, yielding positive token weights that adjust relative update magnitudes while preserving the original GRPO reward and optimization direction, without requiring external reward models or separate teachers. Experiments across diverse multimodal reasoning benchmarks show that SRPO improves evidence-grounded reasoning, highlighting the importance of moving beyond uniform sequence-level credit toward role-aware optimization for reliable multimodal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Structured Role-Aware Policy Optimization (SRPO) as an extension of Group Relative Policy Optimization (GRPO) for reinforcement learning from verifiable rewards in large vision-language models. Structured responses are decomposed into perception tokens (extracting visual evidence) and reasoning tokens (deriving answers), with role-specific token-level advantages computed via self-distilled on-policy contrasts: visual-dependency contrast under original vs. corrupted inputs for perception tokens, and consistency with the generated perception for reasoning tokens. These signals are unified under a shared trajectory-level baseline to produce positive token weights that modulate update magnitudes while preserving the original GRPO reward function and optimization direction, without external reward models or teachers. Experiments on diverse multimodal reasoning benchmarks are reported to improve evidence-grounded reasoning.
Significance. If the role-aware credit assignment is shown to be robust, the work could meaningfully advance reliable multimodal reasoning by moving beyond uniform sequence-level rewards to distinguish functional token roles. The self-distilled, on-policy nature of the contrasts (no external supervision) is a potential strength for practical deployment in LVLMs, provided the decomposition and bias concerns are addressed.
major comments (2)
- [Abstract, §4] Abstract and §4 (Experiments): The central claim that SRPO improves evidence-grounded reasoning rests on experimental results, yet the text provides no details on experimental setup, baselines, statistical significance testing, ablation studies on the perception/reasoning decomposition, or controls for post-hoc analysis choices. This makes the magnitude and reliability of reported gains unverifiable from the manuscript.
- [§3.2] §3.2 (Role-aware advantage construction): The self-distilled contrast for reasoning tokens uses consistency with the model's own generated perception as reference. Because perception tokens are produced by the same policy under optimization, any hallucination or incompleteness in visual evidence will systematically bias the advantage signal for downstream reasoning tokens. The manuscript provides no formal analysis, proof of unbiasedness, or empirical ablation demonstrating that this propagation does not violate the assumption of clean role separation.
minor comments (2)
- [§3] Notation for the unified token weights and the shared baseline could be made more explicit with numbered equations to improve traceability from the GRPO advantage to the role-aware version.
- [Abstract] The abstract contains several long compound sentences that reduce readability; splitting them would clarify the distinction between perception and reasoning signals.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, providing clarifications and indicating the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): The central claim that SRPO improves evidence-grounded reasoning rests on experimental results, yet the text provides no details on experimental setup, baselines, statistical significance testing, ablation studies on the perception/reasoning decomposition, or controls for post-hoc analysis choices. This makes the magnitude and reliability of reported gains unverifiable from the manuscript.
Authors: We appreciate the referee highlighting this presentation issue. The full experimental details were originally placed in the appendix for brevity. In the revision, we have substantially expanded Section 4 to include: (i) complete experimental setup with hyperparameters, datasets, and evaluation protocols; (ii) explicit list of all baselines with implementation references; (iii) statistical significance testing via multiple random seeds, reporting means, standard deviations, and p-values; (iv) comprehensive ablations isolating the perception/reasoning decomposition; and (v) controls for post-hoc choices such as token classification thresholds. Updated tables now include error bars. These changes render the reported gains fully verifiable. revision: yes
-
Referee: [§3.2] §3.2 (Role-aware advantage construction): The self-distilled contrast for reasoning tokens uses consistency with the model's own generated perception as reference. Because perception tokens are produced by the same policy under optimization, any hallucination or incompleteness in visual evidence will systematically bias the advantage signal for downstream reasoning tokens. The manuscript provides no formal analysis, proof of unbiasedness, or empirical ablation demonstrating that this propagation does not violate the assumption of clean role separation.
Authors: We acknowledge the valid concern about bias propagation from imperfect perception tokens. A fully general formal proof of unbiasedness is difficult given the on-policy setting. However, we have added a theoretical subsection in §3.2 showing that the shared trajectory-level baseline and on-policy contrast computation preserve directional consistency with the original GRPO objective, as correlated errors in perception and reasoning do not invert relative advantages. We also include new empirical ablations that inject controlled perception noise and quantify the impact on final performance, demonstrating that SRPO retains advantages over GRPO. A limitations paragraph discussing residual bias risks has been added. revision: partial
Circularity Check
No significant circularity in SRPO derivation chain
full rationale
The paper defines SRPO by explicitly constructing role-aware token advantages from two independent on-policy contrast signals (visual dependency for perception tokens via original vs. corrupted inputs; consistency for reasoning tokens with the generated perception) and then unifying them under a shared trajectory baseline. These constructions are presented as new mechanisms that refine GRPO advantages without altering the underlying reward function or optimization direction. No equation or step reduces the claimed token weights, advantages, or performance gains to quantities fitted from the target data, self-referential definitions, or prior self-citations that would make the result tautological. The derivation remains self-contained against external benchmarks, with empirical claims resting on experiments rather than by-construction equivalence.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal responses can be decomposed into perception tokens (visual evidence extraction) and reasoning tokens (answer derivation) with distinct functional roles.
- ad hoc to paper Self-distilled on-policy contrasts (original vs. corrupted visual inputs for perception; consistency with perception for reasoning) provide unbiased signals for token-level advantages.
Reference graph
Works this paper leans on
-
[1]
The Fourteenth International Conference on Learning Representations , year=
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[2]
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization , author=. arXiv preprint arXiv:2503.12937 , year=
-
[3]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
R1-ShareVL: Incentivizing Reasoning Capabilities of Multimodal Large Language Models via Share-GRPO , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[4]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
NoisyRollout: Reinforcing Visual Reasoning with Data Augmentation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[5]
Haozhe Wang and Chao Qu and Zuming Huang and Wei Chu and Fangzhen Lin and Wenhu Chen , booktitle=
-
[6]
arXiv preprint arXiv:2504.16656 , year=
Skywork r1v2: Multimodal hybrid reinforcement learning for reasoning , author=. arXiv preprint arXiv:2504.16656 , year=
-
[7]
Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning , author=. arXiv preprint arXiv:2505.14677 , year=
-
[8]
Perception-R1: Advancing Multimodal Reasoning Capabilities of MLLMs via Visual Perception Reward , author=. arXiv preprint arXiv:2506.07218 , year=
-
[9]
Ground-r1: Incentivizing grounded visual reasoning via reinforcement learning , author=. arXiv preprint arXiv:2505.20272 , year=
-
[10]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Grounded Reinforcement Learning for Visual Reasoning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[11]
The Fourteenth International Conference on Learning Representations , year=
Perception-Aware Policy Optimization for Multimodal Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[12]
Zongxia Li and Wenhao Yu and Chengsong Huang and Zhenwen Liang and Rui Liu and Fuxiao Liu and Jingxi Chen and Dian Yu and Jordan Lee Boyd-Graber and Haitao Mi and Dong Yu , booktitle=. Vision-
-
[13]
Seeing with You: Perception-Reasoning Coevolution for Multimodal Reasoning
Seeing with You: Perception-Reasoning Coevolution for Multimodal Reasoning , author=. arXiv preprint arXiv:2603.28618 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Visually-Guided Policy Optimization for Multimodal Reasoning
Visually-Guided Policy Optimization for Multimodal Reasoning , author=. arXiv preprint arXiv:2604.09349 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Segment Policy Optimization: Effective Segment-Level Credit Assignment in
Yiran Guo and Lijie Xu and Jie Liu and Ye Dan and Shuang Qiu , booktitle=. Segment Policy Optimization: Effective Segment-Level Credit Assignment in
-
[16]
Exploiting tree structure for credit assignment in rl training of llms , author=. arXiv preprint arXiv:2509.18314 , year=
-
[17]
Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for
Shenzhi Wang and Le Yu and Chang Gao and Chujie Zheng and Shixuan Liu and Rui Lu and Kai Dang and Xiong-Hui Chen and Jianxin Yang and Zhenru Zhang and Yuqiong Liu and An Yang and Andrew Zhao and Yang Yue and Shiji Song and Bowen Yu and Gao Huang and Junyang Lin , booktitle=. Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement...
-
[18]
arXiv preprint arXiv:2603.25077 , year=
Bridging Perception and Reasoning: Token Reweighting for RLVR in Multimodal LLMs , author=. arXiv preprint arXiv:2603.25077 , year=
-
[19]
Not All Tokens See Equally: Perception-Grounded Policy Optimization for Large Vision-Language Models
Not All Tokens See Equally: Perception-Grounded Policy Optimization for Large Vision-Language Models , author=. arXiv preprint arXiv:2604.01840 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
VTPerception-R1: Enhancing Multimodal Reasoning via Explicit Visual and Textual Perceptual Grounding , author=. arXiv preprint arXiv:2509.24776 , year=
-
[21]
The Fourteenth International Conference on Learning Representations , year=
Spotlight on Token Perception for Multimodal Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[22]
arXiv preprint arXiv:2509.13031 , year=
Perception before reasoning: Two-stage reinforcement learning for visual reasoning in vision-language models , author=. arXiv preprint arXiv:2509.13031 , year=
-
[23]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Vision-G1: Towards General Reasoning Vision-Language Models via Reinforcement Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[24]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Perception-R1: Pioneering Perception Policy with Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[25]
arXiv preprint arXiv:2506.02208 , year =
Kdrl: Post-training reasoning llms via unified knowledge distillation and reinforcement learning , author=. arXiv preprint arXiv:2506.02208 , year=
-
[26]
Reinforcement-aware Knowledge Distillation for LLM Reasoning
Reinforcement-aware knowledge distillation for LLM reasoning , author=. arXiv preprint arXiv:2602.22495 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Pixel Reasoner: Incentivizing Pixel Space Reasoning via Curiosity-Driven Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[28]
The Fourteenth International Conference on Learning Representations , year=
RegionReasoner: Region-Grounded Multi-Round Visual Reasoning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[29]
Self-Distilled RLVR , author=. arXiv preprint arXiv:2604.03128 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
The Fourteenth International Conference on Learning Representations , year=
VisionReasoner: Unified Reasoning-Integrated Visual Perception via Reinforcement Learning , author=. The Fourteenth International Conference on Learning Representations , year=
-
[31]
Visplay: Self-evolving vision-language models from images,
Visplay: Self-evolving vision-language models from images , author=. arXiv preprint arXiv:2511.15661 , year=
-
[32]
Qwen2.5-VL Technical Report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
-
[34]
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
-
[35]
arXiv preprint arXiv:2506.09736 , year=
Vision Matters: Simple Visual Perturbations Can Boost Multimodal Math Reasoning , author=. arXiv preprint arXiv:2506.09736 , year=
-
[36]
EasyR1: An Efficient, Scalable, Multi-Modality RL Training Framework , author =
-
[37]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
-
[39]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning? , author=. arXiv preprint arXiv:2407.01284 , year=
-
[40]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts , author=. 2024 , eprint=
work page 2024
-
[41]
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[42]
arXiv preprint arXiv:2403.14624 , year=
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems? , author=. arXiv preprint arXiv:2403.14624 , year=
-
[43]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[44]
The Thirteenth International Conference on Learning Representations , year=
DynaMath: A Dynamic Visual Benchmark for Evaluating Mathematical Reasoning Robustness of Vision Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[45]
Inter-GPS: Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning , author =. The Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2021) , year =
work page 2021
-
[46]
International conference on machine learning , year=
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. International conference on machine learning , year=
-
[47]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Visual Description Grounding Reduces Hallucinations and Boosts Reasoning in
Sreyan Ghosh and Chandra Kiran Reddy Evuru and Sonal Kumar and Utkarsh Tyagi and Oriol Nieto and Zeyu Jin and Dinesh Manocha , booktitle=. Visual Description Grounding Reduces Hallucinations and Boosts Reasoning in
-
[49]
Hao Fang and Changle Zhou and Jiawei Kong and Kuofeng Gao and Bin Chen and Tao Liang and Guojun Ma and Shu-Tao Xia , booktitle=. Grounding Language with Vision: A Conditional Mutual Information Calibrated Decoding Strategy for Reducing Hallucinations in
-
[50]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , year=
See, think, learn: A self-taught multimodal reasoner , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , year=
-
[51]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
PROREASON: Multi-Modal Proactive Reasoning with Decoupled Eyesight and Wisdom , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year=
work page 2025
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Multi-modal hallucination control by visual information grounding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[53]
Probing Visual Language Priors in
Tiange Luo and Ang Cao and Gunhee Lee and Justin Johnson and Honglak Lee , booktitle=. Probing Visual Language Priors in. 2025 , url=
work page 2025
-
[54]
NaturalBench: Evaluating Vision-Language Models on Natural Adversarial Samples , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[55]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv e-prints , year =
-
[56]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
International Conference on Learning Representations (ICLR) , year=
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts , author=. International Conference on Learning Representations (ICLR) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.