Recognition: 2 theorem links
· Lean TheoremVisually-Guided Policy Optimization for Multimodal Reasoning
Pith reviewed 2026-05-10 17:20 UTC · model grok-4.3
The pith
Visually-guided policy optimization amplifies relevant visual tokens and reweights advantages to counter forgetting in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
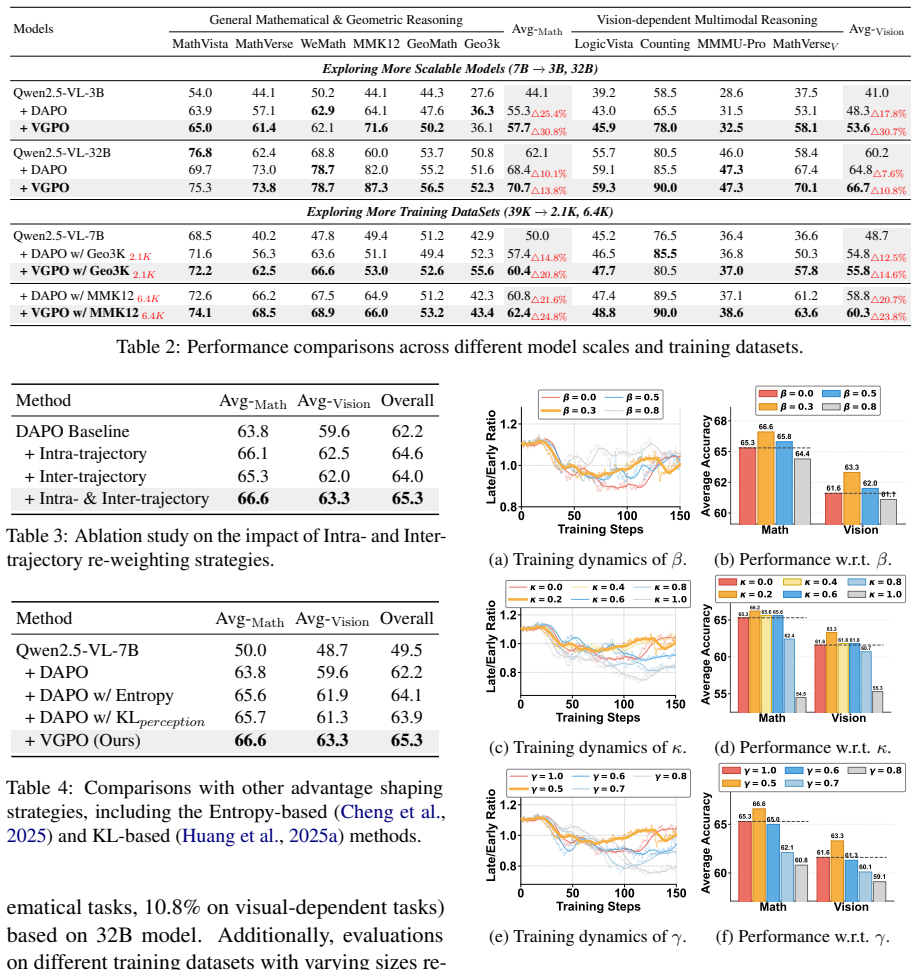
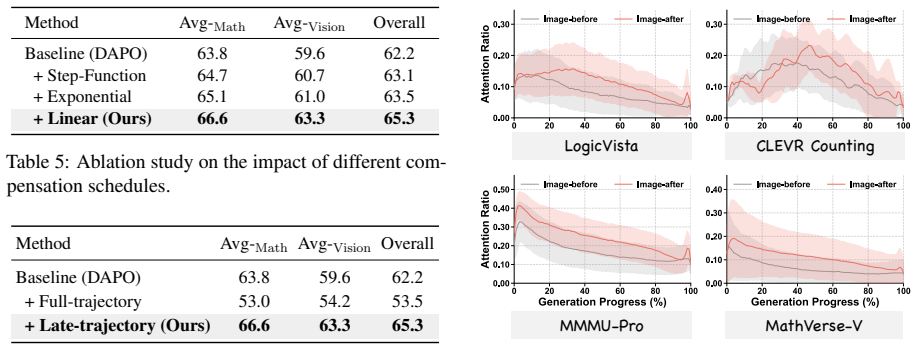
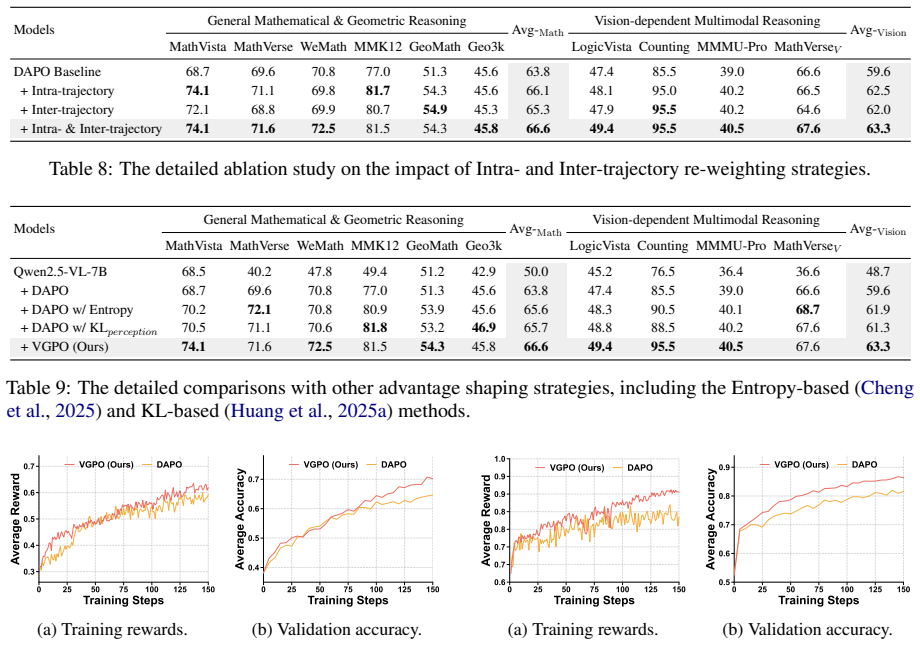
VGPO introduces a Visual Attention Compensation mechanism that localizes and amplifies visual cues through similarity metrics while progressively elevating visual expectations across reasoning steps to counteract temporal forgetting, and pairs it with a dual-grained advantage re-weighting strategy that boosts tokens with high visual activation within each trajectory and entire trajectories that accumulate more visual focus overall, yielding measurably stronger visual activation and higher accuracy on mathematical multimodal reasoning and visual-dependent tasks.
What carries the argument
The Visual Attention Compensation mechanism, which uses visual similarity to localize and amplify cues while raising visual expectations to prevent forgetting, together with dual-grained advantage re-weighting at the intra-trajectory token level and inter-trajectory level.
If this is right
- Superior accuracy on mathematical multimodal reasoning benchmarks compared with standard RLVR.
- Improved results on tasks that require ongoing visual grounding rather than text-only shortcuts.
- Higher measured activation on relevant visual tokens throughout the full reasoning chain.
- Reduced drop-off in visual focus as the number of reasoning steps grows.
- The same compensation and re-weighting logic can be applied on top of existing verifiable-reward training pipelines.
Where Pith is reading between the lines
- The approach may extend to non-reasoning VLM tasks such as detailed visual question answering where sustained image focus is needed.
- Explicit visual guidance during optimization could decrease the frequency of answers that contradict visible image content.
- Varying the strength of the similarity-based amplification across different image types could identify when the compensation is most or least effective.
Load-bearing premise
That amplifying visual cues through similarity metrics and re-weighting advantages according to visual activation levels will reliably reduce forgetting without destabilizing the policy or harming text-based reasoning performance.
What would settle it
Training with VGPO and then measuring that attention maps on visual tokens show no sustained increase or that accuracy on visual-dependent reasoning benchmarks fails to exceed the standard RLVR baseline.
Figures




read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has significantly advanced the reasoning ability of vision-language models (VLMs). However, the inherent text-dominated nature of VLMs often leads to insufficient visual faithfulness, characterized by sparse attention activation to visual tokens. More importantly, our empirical analysis reveals that temporal visual forgetting along reasoning steps exacerbates this deficiency. To bridge this gap, we propose Visually-Guided Policy Optimization (VGPO), a novel framework to reinforce visual focus during policy optimization. Specifically, VGPO initially introduces a Visual Attention Compensation mechanism that leverages visual similarity to localize and amplify visual cues, while progressively elevating visual expectations in later steps to counteract visual forgetting. Building on this mechanism, we implement a dual-grained advantage re-weighting strategy: the intra-trajectory level highlights tokens exhibiting relatively high visual activation, while the inter-trajectory level prioritizes trajectories demonstrating superior visual accumulation. Extensive experiments demonstrate that VGPO achieves better visual activation and superior performance in mathematical multimodal reasoning and visual-dependent tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Visually-Guided Policy Optimization (VGPO) to address insufficient visual faithfulness and temporal visual forgetting in vision-language models under reinforcement learning with verifiable rewards. VGPO introduces a Visual Attention Compensation mechanism that uses visual similarity to localize and amplify cues while progressively elevating visual expectations across reasoning steps, combined with a dual-grained advantage re-weighting strategy (intra-trajectory highlighting of high visual activation tokens and inter-trajectory prioritization of trajectories with superior visual accumulation). The paper claims this yields improved visual activation and superior performance on mathematical multimodal reasoning and visual-dependent tasks.
Significance. If the empirical results hold under rigorous validation, VGPO could offer a targeted method for improving visual grounding in VLM reasoning pipelines without explicit trade-offs against text-based performance. The progressive elevation of visual expectations and dual-grained re-weighting constitute concrete, potentially reusable techniques for mitigating modality imbalance in sequential policy optimization.
major comments (3)
- Abstract: the assertion that 'extensive experiments demonstrate that VGPO achieves better visual activation and superior performance' supplies no quantitative metrics, baselines, datasets, ablations, or error bars, so the data-to-claim link cannot be evaluated and the central performance claim remains unsupported.
- Abstract: the Visual Attention Compensation mechanism is described only at the level of 'leverages visual similarity to localize and amplify visual cues' and 'progressively elevating visual expectations in later steps,' with no specification of the similarity metric (layer, distance, normalization), elevation schedule, or clipping, which are load-bearing for confirming that the signal captures task-relevant semantic content rather than low-level statistics.
- Abstract: the dual-grained advantage re-weighting is introduced without implementation details or analysis of side effects (e.g., whether intra- or inter-trajectory factors can amplify logically flawed but visually salient trajectories or degrade text-only reasoning), directly undermining assessment of the assumption that the re-weighting reliably counters forgetting without destabilizing the policy.
minor comments (1)
- Abstract: the motivation paragraph would benefit from a single concrete example or statistic illustrating the observed temporal visual forgetting to make the problem statement more tangible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that the abstract would benefit from greater specificity to strengthen the link between claims and evidence, and we will revise it accordingly while preserving its concise nature. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: Abstract: the assertion that 'extensive experiments demonstrate that VGPO achieves better visual activation and superior performance' supplies no quantitative metrics, baselines, datasets, ablations, or error bars, so the data-to-claim link cannot be evaluated and the central performance claim remains unsupported.
Authors: We acknowledge that the current abstract does not include specific quantitative results. The full manuscript presents these details in the Experiments section, including performance on mathematical multimodal reasoning and visual-dependent tasks, comparisons against baselines, ablation studies, and variability measures. We will revise the abstract to incorporate a concise summary of key empirical outcomes and the evaluation setup to better support the central claim. revision: yes
-
Referee: Abstract: the Visual Attention Compensation mechanism is described only at the level of 'leverages visual similarity to localize and amplify visual cues' and 'progressively elevating visual expectations in later steps,' with no specification of the similarity metric (layer, distance, normalization), elevation schedule, or clipping, which are load-bearing for confirming that the signal captures task-relevant semantic content rather than low-level statistics.
Authors: The abstract summarizes the mechanism at a conceptual level. The full manuscript specifies the similarity computation, layer selection, normalization, elevation schedule, and any clipping in the method description. We will revise the abstract to include a brief, precise characterization of the similarity metric and elevation process. revision: yes
-
Referee: Abstract: the dual-grained advantage re-weighting is introduced without implementation details or analysis of side effects (e.g., whether intra- or inter-trajectory factors can amplify logically flawed but visually salient trajectories or degrade text-only reasoning), directly undermining assessment of the assumption that the re-weighting reliably counters forgetting without destabilizing the policy.
Authors: The abstract introduces the strategy at a high level. The manuscript provides the implementation formulas, hyperparameters, and ablation analysis examining effects on visual focus versus text reasoning stability. We will revise the abstract to note the dual-grained structure and its observed balance in policy optimization. revision: yes
Circularity Check
No significant circularity; framework presented as novel construction without reductions to inputs or self-citations.
full rationale
The provided abstract and context contain no equations, derivations, or self-citations. VGPO is introduced as a new framework with Visual Attention Compensation and dual-grained re-weighting to address empirically observed temporal visual forgetting. No load-bearing step reduces a prediction or result to a fitted parameter or prior self-citation by construction. The central claims rest on the proposed mechanisms and experimental outcomes rather than definitional equivalence or renamed inputs. This is the expected non-finding for a methods paper describing a new RLVR variant.
Axiom & Free-Parameter Ledger
free parameters (2)
- visual similarity amplification factor
- visual expectation elevation schedule
axioms (1)
- domain assumption Visual attention in VLMs can be reliably quantified and compensated using similarity metrics between visual tokens.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe introduce an intrinsic metric based on hidden state similarity... S(h_i,t, mu_v) = (h_i,t)^T mu_v / (||h_i,t|| ||mu_v||) ... rho_i,t = 1/2 (S + 1)
Forward citations
Cited by 1 Pith paper
-
Structured Role-Aware Policy Optimization for Multimodal Reasoning
SRPO refines GRPO into role-aware token-level advantages by emphasizing perception tokens based on visual dependency (original vs. corrupted inputs) and reasoning tokens based on consistency with perception, unified v...
Reference graph
Works this paper leans on
-
[1]
Hallucination of Multimodal Large Language Models: A Survey
Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930. Dongping Chen, Ruoxi Chen, Shilin Zhang, Yaochen Wang, Yinuo Liu, Huichi Zhou, Qihui Zhang, Yao Wan, Pan Zhou, and Lichao Sun. 2024a. Mllm-as- a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. InForty-first Interna- tional Conference on ...
work page internal anchor Pith review arXiv
-
[2]
Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
Reasoning with exploration: An entropy per- spective.arXiv preprint arXiv:2506.14758. Xiangxiang Chu, Hailang Huang, Xiao Zhang, Fei Wei, and Yong Wang. 2025. Gpg: A simple and strong reinforcement learning baseline for model reasoning. arXiv preprint arXiv:2504.02546. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderj...
-
[3]
Ssl4rl: Revisiting self-supervised learning as intrinsic reward for visual-language reasoning
Multi-modal hallucination control by vi- sual information grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 14303–14312. Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei- Chiu Ma, and Ranjay Krishna. 2024. Blink: Multi- modal large language models can see ...
-
[4]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, and 1 oth- ers. 2025. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2503.07365. Runqi...
work page Pith review arXiv 2025
-
[5]
Logicvista: Multimodal llm logical reason- ing benchmark in visual contexts.arXiv preprint arXiv:2407.04973. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025a. Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shuo Yang, Yuwei Niu, Yuyang Liu, Yang Ye, Bin Lin, ...
-
[6]
By visually inspecting the image, it appears there are at least 10 vertical bars
Count the vertical bars: The image shows a series of vertical bars that form a fence. By visually inspecting the image, it appears there are at least 10 vertical bars. (visual counting error)
-
[7]
There are 10 vertical bars
Count the elements: There is one cow visible in the image. There are 10 vertical bars
-
[8]
Therefore, the total number of elements is: \boxed{11}
Calculate the total number of elements: Total elements = 10 + 1 = 11. Therefore, the total number of elements is: \boxed{11}. Failure Analysis: The model’s prediction fails due to an Object Counting Error. It correctly identifies the task of counting bars and adding the cow, but falters on the initial visual perception step, incorrectly counting 10 vertic...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.